反射是一種編程語言能力,允許程序在運行時查詢和操縱對象的類型信息。它廣泛應用于對象序列化、遠程過程調用、測試框架、和依賴注入等場景。
由于C++語言本身的反射能力比較弱,因此C++生態種出現了許多有趣的反射庫和實現思路。我們在本文一起探討其中的奧秘。
反射實現類型
高級反射的兩種實現思路分別是編譯時反射和運行時反射。
編譯時反射
編譯時反射 (Compile-time Reflection) 在C++中通常依賴模板元編程來實現。這種反射在編譯時確定類型信息,不需要動態類型識別 (RTTI)。這種方法的優點在于可以生成性能更優的代碼,減小二進制文件的大小,因為所有的類型信息在編譯時都已確定,不需要在運行時查詢。
優點
- 性能:由于類型信息在編譯時就已確定,可以避免運行時查找,從而提高性能。
- 二進制大小:不需要存儲額外的類型信息,可以減小最終二進制文件的大小。
- 確定性:編譯時反射的結果在編譯完成后就已確定,這給程序的行為帶來了確定性。
缺點
- 維護成本:需要手動注冊每個需要反射的類型和成員,增加了代碼的維護難度。
- 靈活性較差:程序一旦編譯完成,無法改變其反射的行為。
實現原理
在C++中,編譯時反射通常利用模板特化和宏定義來實現類型注冊。
https://github.com/Ubpa/USRefl/tree/master庫就是一個典型的編譯時反射的庫。
編譯時反射庫的使用往往需要入侵源碼,下面是一個簡單的使用TypeInfo特化來注冊類型信息的示例:
struct Point {float x, y;
};template<>
struct TypeInfo<Point> : TypeInfoBase<Point> {static constexpr FieldList fields = {Field { "x", &Point::x },Field { "y", &Point::y }};
};
在這個例子中,我們為Point類型特化了TypeInfo模板類,定義了一個靜態的fields字段列表,其中包含了Point結構體的成員變量。
下面是上面的編譯時反射的使用示例,它演示了如何遍歷Point結構體的字段:
TypeInfo<Point>::fields.ForEach([](const auto& field) {std::cout << field.name << std::endl;
});
如果需要不入侵源碼,還有一種做法是通過代碼預處理技術實現生成反射的類型信息,使用這種技術實現反射最著名的莫過于Qt的元反射機制和元對象編譯器MOC。
Qt的反射機制
代碼預處理技術通過預處理步驟生成或修改源代碼,從而實現反射。
Qt框架通過一個稱為Meta-Object Compiler (MOC)的元對象編譯器來提供反射能力。MOC是一個代碼預處理器,它在C++編譯之前運行,掃描源代碼中的特殊宏(如Q_OBJECT、signals、slots),并生成額外的C++代碼,這些代碼包含了類型信息和用于信號與槽機制的元信息。
例如,如果一個類需要使用Qt的信號和槽機制,則必須在類定義中包含Q_OBJECT宏:
#include <QObject>class MyClass : public QObject {Q_OBJECT
public:MyClass(QObject* parent = nullptr);virtual ~MyClass();signals:void mySignal();public slots:void mySlot();
};
MOC會識別Q_OBJECT宏,并為MyClass生成額外的C++代碼文件,這個文件包含了反射需要的元信息。這些信息允許在運行時查詢類的信號和槽,以及進行信號和槽之間的連接。
使用Qt的MOC技術,開發者可以在運行時執行類似如下的動態操作:
MyClass myObject;
QMetaObject::invokeMethod(&myObject, "mySlot");
上述代碼將在運行時調用mySlot槽函數,而不需要在編譯時知道該槽的存在。
代碼預處理的優勢和挑戰
代碼預處理技術的優勢在于它能夠在不改變C++語言本身的情況下實現反射。這種方法靈活且與編譯器無關,可以跨平臺使用。
然而,這種技術也有其挑戰和缺點:
- 額外的構建步驟:需要在編譯前運行預處理器,這使得構建過程更復雜。
- 開發工具的兼容性:一些集成開發環境(IDE)和代碼編輯器可能需要特殊配置或插件來支持這種預處理步驟。
- 額外的學習成本:開發者需要學習額外的宏和注解方式,這增加了學習和使用框架的難度。
雖然C++標準不直接支持反射,但通過編譯器擴展和代碼預處理技術,開發者們仍然能夠在C++中實現類似反射的功能。這些技術在實踐中證明了其有效性,并在許多項目中得到了成功的應用。
運行時反射
運行時反射 (Runtime Reflection) 是許多動態語言(如Python、Java和C#)的標準功能。C++的RTTI提供了有限的運行時反射能力,例如通過typeid和dynamic_cast獲取類型信息和進行類型轉換。
優點
- 靈活性:可以在程序運行時查詢和操縱類型信息,為動態行為提供了可能。
- 自動化:大多數支持運行時反射的語言會自動處理類型信息的注冊和管理。
缺點
- 性能開銷:運行時查詢類型信息需要時間,可能會影響性能。
- 二進制大小:需要存儲額外的類型信息,增加了二進制文件的大小。
實現原理
運行時反射依靠語言運行時系統在內存中維護類型信息。在C++中,RTTI提供了typeid操作符來獲取對象的類型信息:
Point p;
std::cout << typeid(p).name() << std::endl;
使用示例
在Java中,運行時反射的使用示例可能如下所示:
Class<?> clazz = Class.forName("java.lang.String");
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {System.out.println(method.getName());
}
C++為什么不直接支持一流的反射
C++作為一種靜態類型語言,它的設計哲學強調性能和內存控制。直接支持運行時反射將違背這種設計哲學,因為運行時反射需要在內存中維護類型信息的數據結構,這會增加額外的內存和性能開銷。
此外,C++的編譯模型和鏈接模型也不適合直接支持反射。C++程序通常由多個翻譯單元組成,它們在鏈接時才最終形成一個程序。這使得在編譯時跨翻譯單元維護類型信息變得困難。
C++的未來發展趨勢
C++社區和標準委員會正在探索如何在未來的標準中增加反射的支持。最新的C++標準已經包含了一些反射相關的提案,比如靜態反射,這表明C++正逐步朝著增強其反射能力的方向發展。
最后,一起實現一個最簡單的C++編譯時反射功能吧
編寫一個最簡單的C++編譯時反射庫涉及到模板元編程和一些宏定義。下面是一個非常基礎的版本,這個反射庫僅支持遍歷字段名稱和獲取字段值。
#include <iostream>
#include <tuple>
#include <stdexcept>
#include <assert.h>
#include <string_view>// 這個宏用于創建字段信息
#define REFLECTABLE(...) \static constexpr auto properties() { return std::make_tuple(__VA_ARGS__); }
// 這個宏用于創建屬性信息,并自動將字段名轉換為字符串
#define PROPERTY(Type, Name) Property<decltype(&Type::Name), &Type::Name>(#Name)// 定義一個屬性結構體,存儲字段名稱和值的指針
template <typename T, T Value>
struct Property {const char* name;constexpr Property(const char* name) : name(name) {}constexpr T get_value() const { return Value; }
};// 用于獲取特定成員的值的函數,如果找不到名稱,則返回默認值
template <typename T, typename Tuple, size_t N = 0, size_t RetTypeSize = 0>
constexpr void* get_field_value_impl(T& obj, const char* name, const Tuple& tp) {if constexpr (N >= std::tuple_size_v<Tuple>) {return nullptr;}else {const auto& prop = std::get<N>(tp);if (std::string_view(prop.name) == name) {assert(RetTypeSize == sizeof(prop.get_value()));// 返回值類型傳錯了return (void*) & (obj.*(prop.get_value()));}else {return get_field_value_impl<T, Tuple, N + 1, RetTypeSize>(obj, name, tp);}}
}template <typename RetType, typename T, typename Tuple, size_t N = 0>
constexpr RetType* get_field_value(T& obj, const char* name, const Tuple& tp) {return (RetType*)get_field_value_impl<T, Tuple, N, sizeof(RetType)>(obj, name, tp);
}// 定義一個類型特征模板,用于獲取屬性信息
template <typename T>
struct Reflector {static_assert(std::is_class_v<T>, "Reflector requires a class type.");// 遍歷所有字段名稱template <typename Func>static void for_each_name(Func&& func) {constexpr auto props = T::properties();std::apply([&](auto... x) {((func(x.name)), ...);}, props);}// 遍歷所有字段值template <typename Func>static void for_each_value(T& obj, Func&& func) {constexpr auto props = T::properties();std::apply([&](auto... x) {((func(x.name, obj.*(x.get_value()))), ...);}, props);}
};// =========================一下為使用示例代碼====================================// 用戶自定義的結構體,需要反射的字段使用REFLECTABLE宏來定義
struct MyStruct {int x{ 10 };float y{ 20.5f };REFLECTABLE(PROPERTY(MyStruct, x),PROPERTY(MyStruct, y))
};int main() {MyStruct obj;// 打印所有字段名稱Reflector<MyStruct>::for_each_name([](const char* name) {std::cout << "Field name: " << name << std::endl;});// 打印所有字段值Reflector<MyStruct>::for_each_value(obj, [](const char* name, auto&& value) {std::cout << "Field " << name << " has value: " << value << std::endl;});// 獲取特定成員的值,如果找不到成員,則返回默認值auto x_value = get_field_value<int>(obj, "x", MyStruct::properties());std::cout << "Field x has value: " << *x_value << std::endl;auto y_value = get_field_value<float>(obj, "y", MyStruct::properties());std::cout << "Field y has value: " << *y_value << std::endl;auto z_value = get_field_value<int>(obj, "z", MyStruct::properties()); // "z" 不存在std::cout << "Field z has value: " << z_value << std::endl;return 0;
}
這個反射庫的工作方式如下:
-
REFLECTABLE宏:用于在用戶自定義的結構體中聲明需要反射的字段。它將這些字段封裝到一個元組中,每個字段都是一個Property實例。 -
Property結構體:用于存儲字段的名稱和指向其值的指針。 -
Reflector類型特征:用于執行反射操作,比如遍歷所有字段的名稱和值。
由于用到了折疊表達式,因此需要支持C++17的編譯器才能正常編譯。運行后,可以看到結構體的名稱被正確的顯示出來:
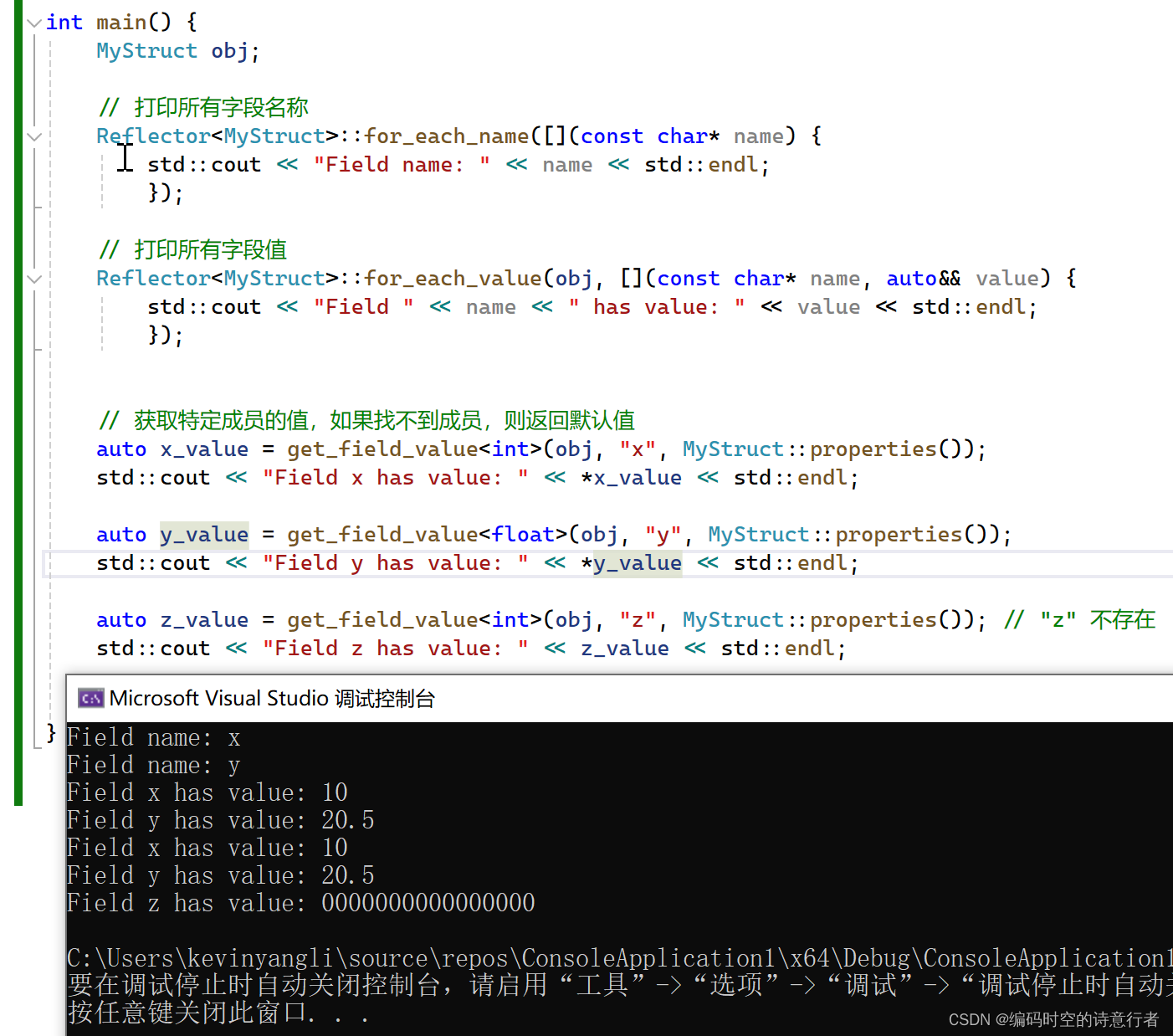
這個編譯時反射庫非常基礎,只支持非靜態數據成員,并且每個字段必須手動注冊。在實際應用中,一個成熟的編譯時反射庫會更復雜,支持更多功能,如方法調用、類型信息查詢、繼承關系處理等。但是,我們通過這個例子,可以更久深入地理解C++的編譯時反射的實現原理和技術細節,非常有趣。
擴展知識:關于C++的折疊表達式
我們前面提到,由于用到了折疊表達式,需要支持C++17的編譯器才能正常編譯。那么什么折疊表達式呢?
C++的折疊表達式(Fold Expression)是C++17標準引入的一種新特性,它允許對一個包含了所有參數的參數包進行一個二元操作的展開。折疊表達式可以簡化有關變參模板函數的編寫,例如上面我們需要對所有的變參執行某項操作時。
折疊表達式有兩種形式:一元右折疊和一元左折疊。它們分別用 (... op pack) 和 (pack op ...) 表示,其中 op 是一個二元運算符,pack 是一個參數包。C++17也支持二元折疊表達式 (init op ... op pack) 和 (pack op ... op init)。
以下是一些折疊表達式的例子:
template<typename... Args>
auto sum(Args... args) {return (... + args); // 一元右折疊,將參數包中所有元素求和
}template<typename... Args>
auto logical_and(Args... args) {return (true && ... && args); // 二元左折疊,邏輯與操作
}template<typename... Args>
bool all_positive(Args... args) {return ((args > 0) && ...); // 一元右折疊,判斷所有參數是否都大于0
}
在第一個例子中,(... + args) 是一種右折疊表達式。如果傳給 sum 函數的參數是 (1, 2, 3),折疊表達式的展開將是 1 + (2 + 3)。
在第二個例子中,true && ... && args 是一種左折疊表達式。如果傳的參數是 (a, b, c),那么展開將是 true && a && b && c。
第三個例子是一種右折疊表達式,它檢查所有參數是否都大于0。如果傳的參數是 (1, 2, 3),那么展開將是 1 > 0 && 2 > 0 && 3 > 0。
折疊表達式極大簡化了變參模板代碼的編寫,使得對參數包的操作更加直接和清晰。在C++17之前,要對參數包中的所有元素進行操作通常涉及到遞歸模板實例化或使用初始化列表的技巧來實現,這相對來說更加復雜且代碼可讀性較差。
結語
如果你耐心的讀到這里,相信你對C++的編譯時反射的原理和實現都有了更深入的認識,以后再做C++反射相關的事情,也會更加游刃有余了。

- 多元線性回歸)


注解)








原理詳解及Python代碼示例)


vue2)


