SelfReg-UNet:解決UNet語義損失,增強特征一致性與減少冗余的優化模型
- 提出背景
- 拆解
- 類比:整理書架
- 語義一致性正則化
- 內部特征蒸餾
- 為什么 UNet 會有語義損失?
?
提出背景
論文:https://arxiv.org/pdf/2406.14896
代碼:https://github.com/ChongQingNoSubway/SelfReg-UNet
-
UNet架構的核心優勢:UNet通過編碼器和解碼器的結合,有效地將圖像中的語義信息轉化為精細的分割掩模,這對醫學圖像分割至關重要。
-
引入視覺變換器(ViT):為了克服傳統卷積神經網絡(CNN)在處理圖像長距離依賴性方面的局限,研究者開始使用ViT。ViT通過自我關注機制提升了模型對遠程信息的處理能力,但在處理局部細節上存在不足。
-
混合模型的發展:為了結合CNN和ViT的優點,研究者開發了混合UNet模型,這些模型既能捕獲廣泛的依賴關系,也能關注局部細節,但增加了計算復雜性和模型參數。
-
跳躍連接的創新:如Att-Unet和Unet++等變體通過改進跳躍連接來優化信息流,例如引入注意力機制或使用新的連接方式,以期過濾掉不相關的特征并提高分割精度。
-
監督不對稱和特征冗余問題:研究發現,現有UNet模型中存在的監督不對稱和特征冗余問題可能導致語義信息的損失。為此,我們提出了語義一致性正則化和內部特征蒸餾策略,旨在通過更精確的監督和特征信息的有效傳遞來解決這些問題。
UNet語義損失主要指在醫學圖像分割任務中,網絡由于訓練或結構限制而未能正確理解或保留圖像中的重要語義信息,導致分割結果與真實情況存在偏差。
具體來說,這種損失通常表現為分割精度低下,錯分和漏分現象,尤其是在圖像中具有相似紋理或密集重疊的結構時更為明顯。
例如,在進行腫瘤分割的任務中,UNet可能因為語義損失而將腫瘤周圍的正常組織錯誤地識別為腫瘤組織(錯分),或者沒有完全覆蓋實際的腫瘤邊界(漏分)。
這種情況往往是由于網絡在編碼過程中丟失了部分重要的局部信息,或者解碼過程中未能正確重建這些關鍵信息導致的。

這張圖展示了醫學圖像分割領域中UNet架構的應用和分析。圖中包括三個部分:
- UNet架構(圖a):
- 展示了UNet的整體結構,包括輸入圖像、通過多個編碼器層的處理,中間的瓶頸層,隨后是解碼器層和最終的輸出分割圖像。
- 這種架構特別強調了編碼器和解碼器之間的跳躍連接,這有助于保留重要的空間信息,以提高分割的準確性。
UNet結構組成:
- 輸入:展示了一個輸入的醫學圖像示例。
- 編碼器部分:由四個編碼器塊(E1, E2, E3, E4)構成,每個塊包含兩個CNN/Transformer層。這些塊負責逐步降低圖像的空間分辨率,同時增加特征維度,以提取越來越抽象的特征。
- 瓶頸部分(B):位于編碼器和解碼器之間,通常是特征提取和變換的核心部分,負責進一步處理特征。
- 解碼器部分:包括四個解碼器塊(D1, D2, D3, D4),功能與編碼器相反,逐步恢復圖像的空間分辨率并減少特征維度,以重構圖像。
- 跳躍連接:跳躍連接將編碼器中的特征直接連接到解碼器的相應層,這有助于恢復圖像的精細結構,因為它允許網絡利用淺層特征來精確地分割圖像。
- 輸出分割:最終的輸出示例,顯示了分割后的圖像,其中不同的顏色代表不同的組織或結構。
雖然每個塊理論上包含兩層,但圖示中只顯示了每個塊的最后一層,以簡化視覺表示。這有助于清晰地理解UNet的高層結構和數據流動方式,而不混淆過多的層級細節。
這樣的結構設計使UNet特別適用于各種圖像分割任務,特別是在醫學圖像處理領域,其中精確的分割至關重要。
-
注意力圖(圖b):
- 展示了在不同編碼器和解碼器層中,使用ViT和CNN結合的UNet模型產生的注意力圖。這些圖顯示了模型在處理輸入圖像時如何聚焦于圖像的關鍵區域。
- 注意力機制幫助模型更有效地處理圖像中的信息,尤其是在重要的特征上,以提高分割的準確度。
-
特征相似性矩陣(圖c):
- 比較了在淺層(左側矩陣)和較深層(右側矩陣)特征之間的相似性。深層特征展示了更加集中和一致的自相似性,說明模型在深層提取的特征更加專注于主要的圖像內容。
- 這種分析有助于了解不同層次上特征的表達和重要性,對優化模型結構和改進算法性能至關重要。
總體而言,這張圖說明了UNet模型在處理醫學圖像分割任務時如何聚焦和提取關鍵特征,以及通過不同方法(如ViT和CNN結合使用)改進信息處理。
拆解
這部分論文介紹了UNet在醫學圖像分割中學習特征的方法及其面臨的問題,并提出了兩種解決策略。
類比:整理書架
有一個書架滿載著各種書籍,這些書籍代表不同的數據或特征。你的目標是整理這個書架,使得相關的書籍靠近彼此,而不相關的書籍被適當地隔開。同時,你還想去掉那些重復的或者幾乎不被閱讀的書籍,以便為更有用的書籍騰出空間。
增強特征一致性 對應于將相似主題或內容的書籍放在一起。在UNet中,這意味著保證網絡學習到的特征在不同層次和位置上保持一致性,從而確保在圖像分割中能夠正確識別和標記圖像的各個部分。
減少冗余 對應于去除重復的書籍或很少被查看的書籍。在UNet中,這意味著減少不必要的、重復的特征表示,這些表示可能不會為最終的任務(如圖像分割)增加任何額外的信息價值。通過去除這些冗余特征,模型能夠更加高效地運作,同時避免過擬合,并提升處理速度和性能。
通過這種方式,優化后的模型(如SelfReg-UNet)就像是一個被精心整理過的書架,不僅容易找到所需的信息,而且還有效地利用了空間,去除了不必要的元素。
這樣的系統不僅能更快地找到所需信息,還提高了整體的功能性和效率。
改善UNet在處理醫學圖像分割時出現的語義丟失和特征冗余問題。
語義一致性正則化
- 語義一致性正則化 (Semantic Consistency Regularization, SCR)
- 目的: 解決UNet中編碼器和解碼器之間的監督不對稱問題。
- 方法: 使用具有最多語義信息的特征圖(例如D1層觀察到的)對其他所有層提供額外的監督。
- 邏輯: 由于解碼器中的D1層對地面真實分割區域有準確的理解,利用這一層的特征來增強其他層的學習,減少語義丟失。
- 技術細節: 使用平均池化和隨機通道選擇操作對特征進行對齊,并通過L2范數作為距離度量。
內部特征蒸餾
- 內部特征蒸餾 (Internal Feature Distillation, IFD)
- 目的: 解決深層特征中的冗余問題。
- 方法: 從淺層特征向深層特征傳遞信息,使用Lp范數懲罰來引導更深層特征學習有用的上下文信息。
- 邏輯: 通過增強深層特征對上下文信息的敏感度,來提高模型的整體性能和精確度。
- 技術細節: 將通道劃分為上半部和下半部,以此劃分作為邊界來確保淺層和深層具有相同數量的特征。
- 將SCR和IFD的損失與交叉熵和Dice損失相結合,通過調整平衡參數λ1和λ2來優化模型性能。
這些解決策略形成了一個鏈條,從監督不對稱和特征冗余兩個角度出發,通過SCR和IFD兩種技術相結合來優化UNet模型的性能。
每種策略針對UNet在醫學圖像分割中面臨的具體問題提出了針對性的解決方案,互為補充,共同提升模型的準確性和效率。
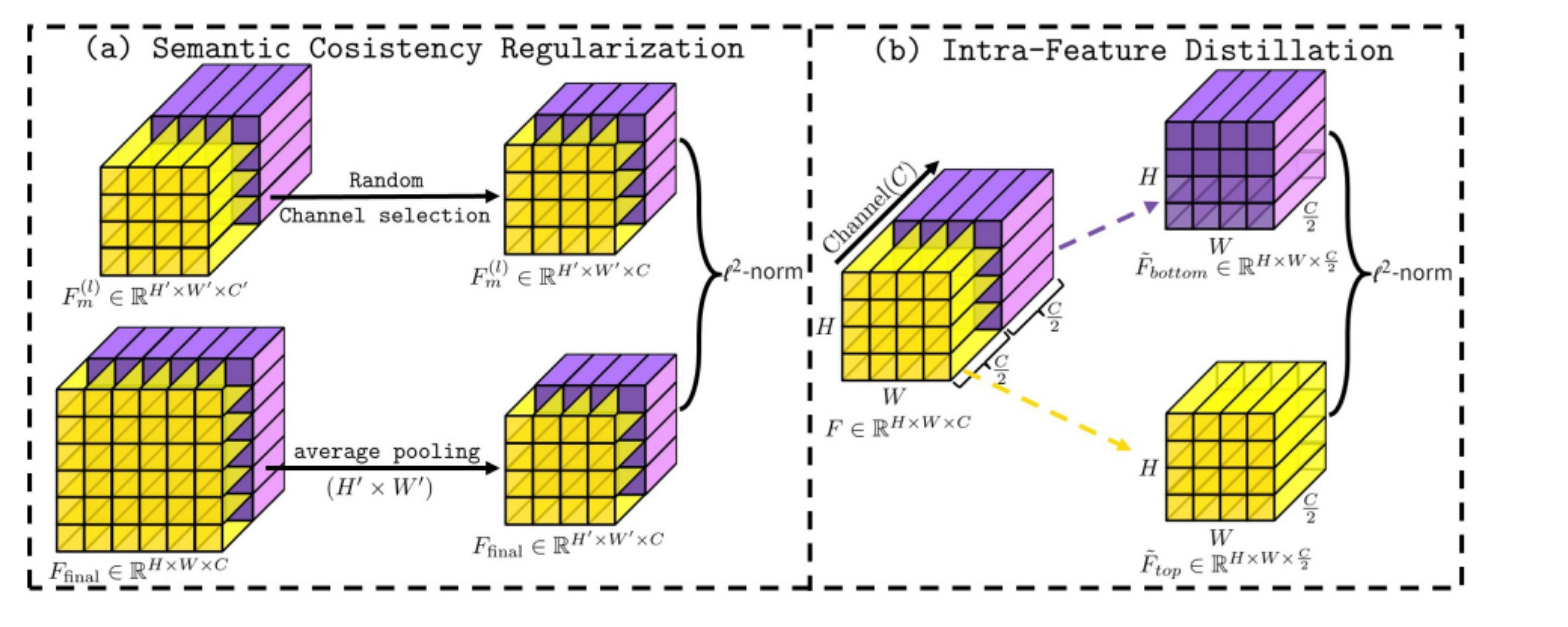
這張圖展示了論文中提到的兩種操作方法:語義一致性正則化(Semantic Consistency Regularization, SCR)和內部特征蒸餾(Intra-Feature Distillation, IFD)。
這兩種方法都是為了優化UNet在處理醫學圖像分割時的特征表示。具體說明如下:
(a) 語義一致性正則化 (SCR)
-
操作步驟:
- 隨機通道選擇:從輸入的特征圖 ( F m ( l ) ) ( F^{(l)}_m ) (Fm(l)?) 中隨機選擇特定通道。
- 平均池化:對選擇的特征圖進行空間維度的平均池化,從而減少特征圖的空間維度。
- L2-范數:對處理后的特征圖進行L2范數計算,以獲得最終的特征表示 ( F f i n a l ) ( F_{final} ) (Ffinal?)。
-
目的:這一步驟通過隨機選擇通道并進行平均池化,從而提取最具代表性和語義一致的特征,用于增強整個網絡的語義一致性。
(b) 內部特征蒸餾 (IFD)
-
操作步驟:
- 通道劃分:將輸入的特征圖 ( F ) 在通道維度上均等分為上半部 ( F t o p ) ( F_{top} ) (Ftop?) 和下半部 ( F b o t t o m ) ( F_{bottom} ) (Fbottom?)。
- L2-范數:分別對上半部和下半部的特征圖進行L2范數處理,以提取和強化特征。
-
目的:通過將特征圖分割為兩部分并獨立處理,這種方法旨在減少特征冗余,并通過蒸餾技術從淺層特征向深層特征傳遞有價值的信息,促進模型學習更為精確和有用的特征表示。
這兩種方法都是針對UNet架構中存在的特征冗余和監督不對稱問題提出的解決方案,旨在通過改進特征處理和優化信息流,提高模型對醫學圖像的分割精度和效率。
為什么 UNet 會有語義損失?
UNet架構在處理醫學圖像分割時面臨特征一致性和冗余的兩大問題,主要由以下幾個方面引起:
- 網絡深度和特征抽象
- 深度與抽象:UNet通過其多層編碼器和解碼器結構進行深度特征抽象。在向下采樣過程中,盡管模型可以捕獲廣泛的上下文信息,但同時可能會丟失關鍵的局部信息,如邊緣和紋理細節。這種信息的丟失在編碼器到解碼器的信息重建過程中可能導致不一致性。
- 信息重建的挑戰:在解碼器階段,模型試圖重建圖像的細節,依賴于編碼器階段提取的特征。如果這些特征已經丟失了必要的信息,解碼器重建的圖像可能與原始圖像在語義上不一致。
- 跳躍連接和特征利用
- 跳躍連接的局限:雖然跳躍連接旨在改善特征一致性,通過將編碼器中的高分辨率特征直接與解碼器中的對應特征相連接,但這種方法也存在局限。如果跳躍連接傳遞的特征本身包含冗余或不相關的信息,那么這些問題將直接影響到最終的分割結果。
- 特征冗余:隨著網絡深度的增加,許多高級特征可能會開始表現出相似性,尤其是在處理大量相似圖像或圖像區域時。這種高級特征的相似性可能導致特征冗余,即多個通道或特征圖可能包含重復的信息,從而增加了計算負擔且沒有提供額外的洞察力。
- 訓練數據和標簽質量
- 數據和標簽的質量:UNet的性能高度依賴于訓練數據的質量和標簽的準確性。如果訓練數據中存在標簽錯誤或質量不一,可能導致模型學習到錯誤或不一致的特征表示,進而影響模型的泛化能力和實際應用的準確性。
- 網絡設計和優化
- 設計選擇和優化策略:UNet的架構設計和訓練策略,如損失函數的選擇、正則化方法以及優化算法,都會對特征的一致性和冗余有顯著影響。不當的設計選擇可能導致模型對某些特征過度依賴,而忽略了其他重要特征。
解決這些問題通常需要在模型設計時考慮更精細的特征管理策略,例如通過改進的跳躍連接設計、引入注意力機制或使用先進的正則化技術來提高特征的有效性和減少不必要的冗余。







:鏈表)



)


習題講解)




