
🎩 歡迎來到技術探索的奇幻世界👨?💻
📜 個人主頁:@一倫明悅-CSDN博客
?🏻 作者簡介:?C++軟件開發、Python機器學習愛好者
🗣??互動與支持:💬評論?? ? ?👍🏻點贊?? ? ?📂收藏?? ? 👀關注+
如果文章有所幫助,歡迎留下您寶貴的評論,
點贊加收藏支持我,點擊關注,一起進步!
前言 ? ? ? ? ? ? ? ? ? ?? ? ?
???????支持向量機(Support Vector Machine, SVM)是一種強大且靈活的監督學習算法,用于分類和回歸分析。它特別適用于小樣本數據集上的分類問題,同時也能有效地處理高維空間數據。以下是支持向量機的詳細分析和解釋:
原理和工作方式:
基本概念:
- SVM 的基本目標是找到一個超平面(在二維空間中即為一條直線,在更高維空間中為一個超平面),能夠將不同類別的數據點盡可能分開,同時具有最大的間隔(margin)。
間隔和支持向量:
- 間隔是指超平面與離它最近的訓練樣本點之間的距離。支持向量則是離超平面最近的那些點。在優化過程中,SVM 將尋找最大化間隔的超平面,并且只有支持向量對超平面的位置起決定性作用。
數學形式:
- SVM 的數學形式可以用凸優化理論來描述,主要包括最小化正則化的損失函數和約束條件。常見的損失函數包括 Hinge Loss,正則化項可以是 L1 或 L2 范數。
主要優點:
- 高效處理高維空間數據:由于其核函數技巧,SVM 在高維空間中處理數據效果顯著。
- 泛化能力強:在小樣本數據上表現良好,并且能夠有效避免過擬合。
- 可以解決非線性問題:通過選擇合適的核函數(如多項式核、高斯核等),SVM 可以處理非線性分類問題。
主要缺點:
- 計算效率低下:對于大規模數據集和特征數量較多的情況,訓練時間較長且消耗資源。
- 對參數調節和核函數的選擇敏感:選擇不當可能導致性能下降。
應用領域:
- 文本分類:如情感分析、垃圾郵件過濾等。
- 圖像分類:例如人臉識別、物體識別等。
- 生物信息學:如蛋白質分類、基因分類等。
SVM 的工作流程:
- 數據準備:選擇合適的特征和標簽。
- 選擇核函數:根據問題選擇合適的核函數或者直接使用線性核。
- 訓練模型:通過優化算法找到最優的超平面。
- 預測:使用訓練好的模型對新數據進行分類或回歸預測。
正文? ?
01-使用帶有RBF核的非線性SVC執行二分類任務??? ? ? ? ? ? ? ? ??
????????使用帶有RBF核的非線性支持向量機(SVM)執行二分類任務是一種常見且強大的方法。RBF核(徑向基函數核)允許SVM處理非線性可分的數據集,通過將數據映射到高維空間來構建一個非線性的決策邊界。
1. RBF核的基本概念
RBF核是SVM中最常用的核函數之一,其數學形式為:
其中,
是一個控制RBF核函數衰減速度的參數,(
) 和 (
) 是數據點。
2. 非線性SVM的工作原理
特征映射:RBF核通過將輸入數據映射到一個高維特征空間,使得原始的非線性可分問題在這個空間中變得線性可分或更容易分割。
最大化間隔:與線性SVM類似,非線性SVM也尋求一個最大化間隔的超平面來分割不同類別的數據點。這個超平面在高維特征空間中對應于一個非線性的決策邊界。
支持向量:在優化過程中,只有位于間隔邊界上的支持向量對構建決策邊界起作用。它們決定了最終模型的形狀和位置。
3. 實施步驟
數據準備
????????首先,準備包含特征和標簽的訓練數據集。
選擇核函數
????????針對非線性問題,選擇RBF核函數是常見且有效的選擇。通過調節 ( \gamma ) 參數可以控制決策邊界的復雜度,過高或過低的 ( \gamma ) 值都可能導致性能下降。
訓練模型
????????使用訓練數據集訓練非線性SVM模型。訓練過程包括優化SVM的損失函數和間隔最大化的目標。
模型預測
????????使用訓練好的模型對新的數據進行分類預測。模型將根據學習到的決策邊界將新數據點分配給各個類別。
4. 優缺點
- 優點:能夠有效處理非線性問題,具有良好的泛化能力,適用于各種復雜的數據分布。
- 缺點:依然對參數 ( \gamma ) 和 ( C ) (正則化參數)敏感,需要仔細調參以達到最佳性能。
5. 應用領域
????????非線性SVM在各種領域都有廣泛的應用,特別是在圖像識別、文本分類、生物信息學等需要處理復雜數據結構的任務中表現出色。
????????通過以上步驟和理解,可以詳細分析和解釋使用帶有RBF核的非線性SVM執行二分類任務的過程及其在實際應用中的意義和影響。
這段代碼演示了如何使用支持向量機(SVM)進行二分類,并使用?NuSVC?模型擬合一個 XOR 數據集,并可視化決策邊界。
代碼解釋
-
數據生成:
xx, yy = np.meshgrid(np.linspace(-3, 3, 500),np.linspace(-3, 3, 500)) np.random.seed(0) X = np.random.randn(300, 2) Y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)meshgrid?創建了一個二維網格?xx?和?yy,用于繪制決策邊界。np.random.randn(300, 2)?生成一個包含300個樣本的二維隨機數據集?X。logical_xor?創建了標簽?Y,其為?True?當且僅當?X[:, 0] > 0?與?X[:, 1] > 0?中有一個成立時。
-
模型擬合:
clf = svm.NuSVC(gamma='auto') clf.fit(X, Y)- 使用?
NuSVC?模型初始化一個支持向量機分類器,gamma='auto'?表示自動選擇核函數的參數。 - 使用?
fit?方法擬合模型到數據集?(X, Y)?上。
- 使用?
-
決策函數計算:
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape)decision_function?計算網格上每個點的決策函數值,這些值用于繪制決策邊界。np.c_[xx.ravel(), yy.ravel()]?將網格點展平并連接成二維數組,以便作為輸入進行預測。Z?被重塑為與網格?xx?相同的形狀,以便用于繪制。
-
可視化:
plt.imshow(Z, interpolation='nearest',extent=(xx.min(), xx.max(), yy.min(), yy.max()), aspect='auto',origin='lower', cmap=plt.cm.PuOr_r) contours = plt.contour(xx, yy, Z, levels=[0], linewidths=2,linestyles='dashed') plt.scatter(X[:, 0], X[:, 1], s=30, c=Y, cmap=plt.cm.Paired,edgecolors='k') plt.xticks(()) plt.yticks(()) plt.axis([-3, 3, -3, 3]) plt.show()imshow?顯示決策函數?Z?的值作為背景色彩圖,extent?確定顯示范圍,cmap?為顏色映射。contour?繪制決策邊界,使用?levels=[0]?表示繪制決策函數為0的等高線。scatter?繪制樣本數據點?X,根據標簽?Y?的不同類別使用不同的顏色。- 其他繪圖設置用于美化圖像和刪除坐標軸標簽。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svmxx, yy = np.meshgrid(np.linspace(-3, 3, 500),np.linspace(-3, 3, 500))
np.random.seed(0)
X = np.random.randn(300, 2)
Y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)#(譯者注:可以在這里通過顯示Y來查看什么是XOR數據)# 擬合模型
clf = svm.NuSVC(gamma='auto')
clf.fit(X, Y)# 在網格上為每個數據點繪制決策函數
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.imshow(Z, interpolation='nearest',extent=(xx.min(), xx.max(), yy.min(), yy.max()), aspect='auto',origin='lower', cmap=plt.cm.PuOr_r)
contours = plt.contour(xx, yy, Z, levels=[0], linewidths=2,linestyles='dashed')
plt.scatter(X[:, 0], X[:, 1], s=30, c=Y, cmap=plt.cm.Paired,edgecolors='k')
plt.xticks(())
plt.yticks(())
plt.axis([-3, 3, -3, 3])
plt.savefig("../5.png", dpi=500)
plt.show()結果如下圖所示:
圖像顯示了使用非線性 SVM(使用 RBF 核)在 XOR 數據集上學習的決策邊界。這個數據集在原始空間中是線性不可分的,但在高維特征空間中可能是線性可分的。關鍵點包括:
- 背景色彩圖:顯示了決策函數的值,越接近0的區域表示決策邊界附近。
- 虛線等高線:標記了決策函數為0的等高線,即決策邊界。
- 散點圖:顯示了原始數據點,根據其標簽用不同顏色表示不同類別。
這種圖像演示了 SVM 如何利用 RBF 核處理非線性問題,并展示了如何在二維空間中繪制決策邊界和樣本點。
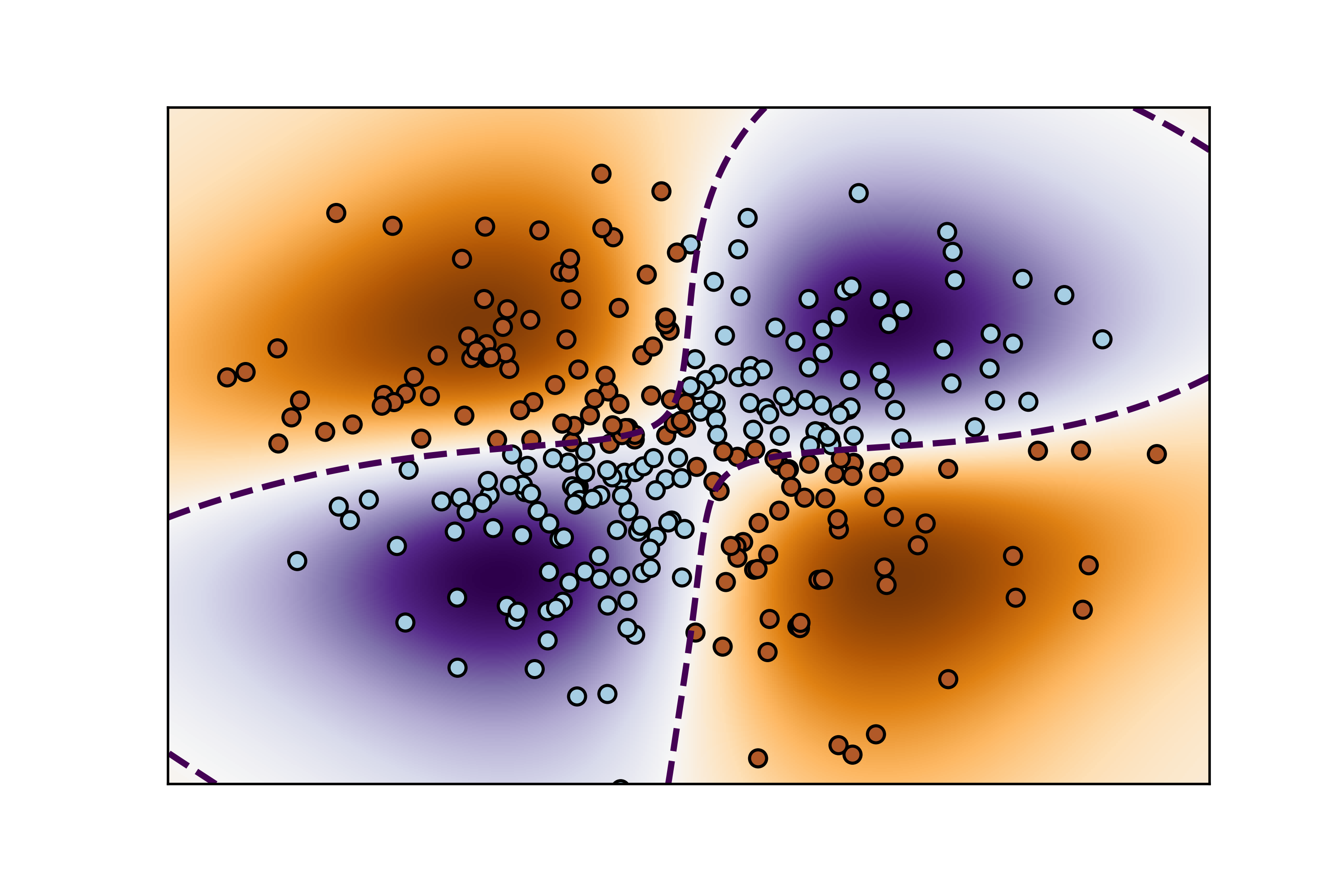
02-支持向量機:最大邊際分割超平面? ? ? ? ??
????????支持向量機(SVM)中的最大邊際分割超平面是指通過優化過程找到的能夠將不同類別數據點分開并且具有最大間隔(margin)的超平面。以下是對這個概念的詳細解釋:
基本概念
超平面:
- 在二維空間中,超平面是一條直線;在更高維空間中,它是一個線性決策邊界。超平面能夠將特征空間劃分為兩個部分,每個部分包含一個類別的數據點。
間隔(Margin):
- 間隔是指超平面與離它最近的訓練樣本點之間的距離。在 SVM 中,優化的目標是找到最大化間隔的超平面,這使得模型對未見過的數據具有更好的泛化能力。
支持向量(Support Vectors):
- 支持向量是離超平面最近的那些數據點。它們是在優化問題中決定超平面位置和方向的關鍵元素。支持向量的位置對于定義決策邊界和最大化間隔至關重要。
工作原理
SVM 的優化過程旨在找到一個超平面,使得:
- 所有的正樣本點(屬于一個類別的數據點)距離超平面的距離大于等于一個正常數,表示為 ( \gamma );
- 所有的負樣本點(屬于另一個類別的數據點)距離超平面的距離小于等于一個負常數,表示為 -( \gamma )。
這可以表達為以下約束條件:
[ y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq \gamma \quad \text{對于正樣本} ]
[ y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \leq -\gamma \quad \text{對于負樣本} ]其中,( \mathbf{w} ) 是超平面的法向量,( b ) 是偏置項,( y_i ) 是樣本 ( \mathbf{x}_i ) 的類別標簽。
數學形式
SVM 的目標函數可以形式化為一個凸優化問題,通常包括:
- 最小化損失函數(如 Hinge Loss)和/或
- 正則化項(如 ( L1 ) 或 ( L2 ) 范數)
這些組成部分一起用來確保找到一個最大邊際的超平面,并在優化過程中保持其對訓練數據的泛化能力。
總結
最大邊際分割超平面是支持向量機中核心的概念之一,它通過最大化類別之間的間隔來優化模型的泛化能力。這種方法使得 SVM 在處理小樣本數據和高維特征空間中表現出色,但也需要仔細調參和處理核函數選擇等問題,以達到最佳性能。
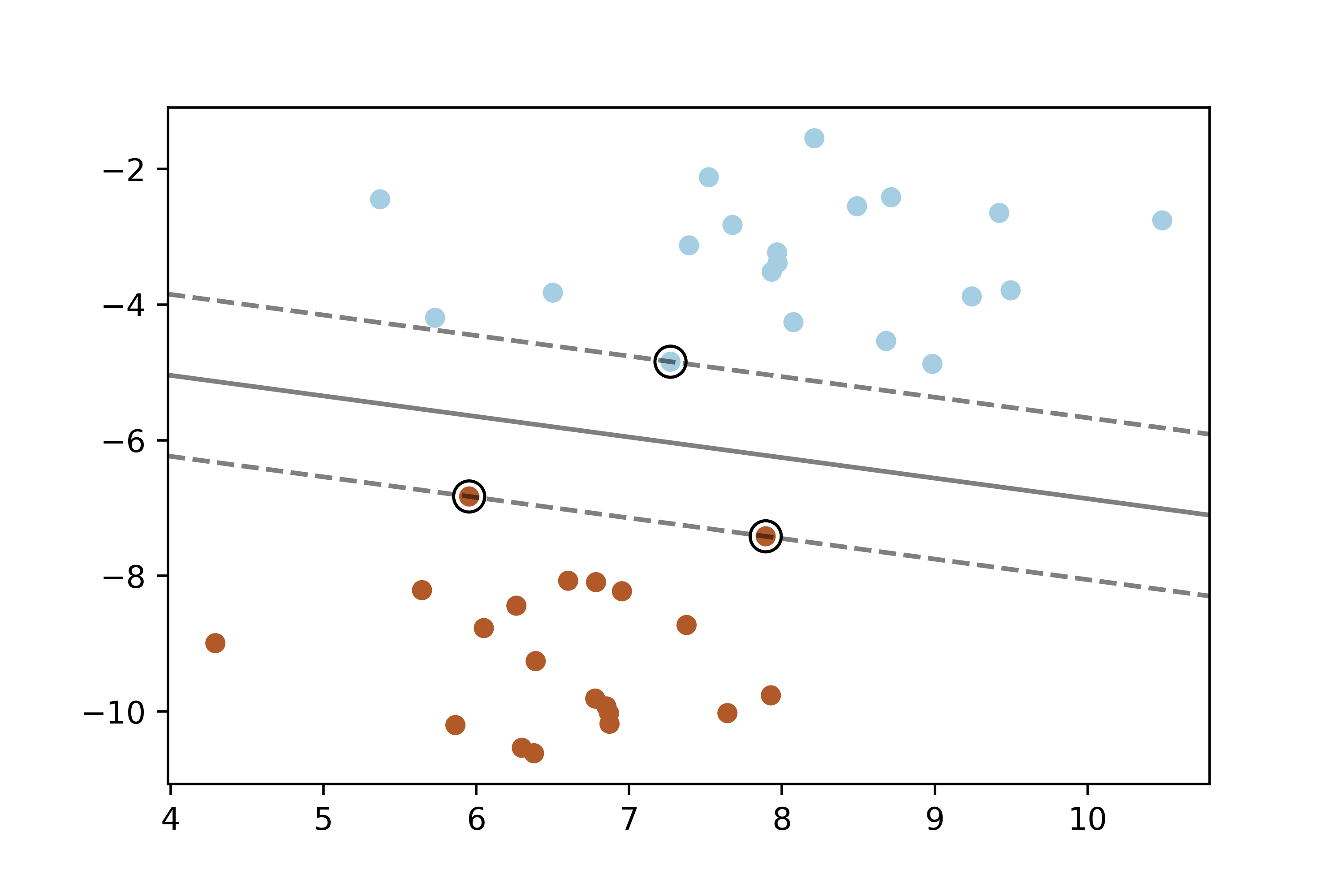
這段代碼演示了如何使用支持向量機(SVM)進行二分類,并在二維空間中繪制決策邊界、支持向量以及間隔。讓我們逐步解釋和分析代碼:
代碼解釋
-
生成數據集:
X, y = make_blobs(n_samples=40, centers=2, random_state=6)- 使用?
make_blobs?生成一個包含40個樣本的二維數據集?X,每個樣本屬于兩個中心之一,由?centers=2?指定,random_state?用于復現結果。
- 使用?
-
模型擬合:
clf = svm.SVC(kernel='linear', C=1000) clf.fit(X, y)- 使用?
SVC?初始化一個線性核的支持向量機分類器,C=1000?表示正則化參數的倒數,控制間隔的硬度。 - 使用?
fit?方法將模型擬合到數據集?(X, y)?上。
- 使用?
-
繪制數據點:
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)- 使用?
scatter?繪制數據點?X,不同的類別用不同的顏色標識,顏色映射為?Paired。
- 使用?
-
繪制決策函數結果:
ax = plt.gca() xlim = ax.get_xlim() ylim = ax.get_ylim()xx = np.linspace(xlim[0], xlim[1], 30) yy = np.linspace(ylim[0], ylim[1], 30) YY, XX = np.meshgrid(yy, xx) xy = np.vstack([XX.ravel(), YY.ravel()]).T Z = clf.decision_function(xy).reshape(XX.shape)ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])- 獲取當前圖形對象?
ax?并獲取當前的 x 和 y 軸限制。 - 創建一個網格?
xx?和?yy,并用?meshgrid?將它們組合成?XX,?YY。 decision_function?計算網格上每個點的決策函數值,并將結果繪制為等高線?contour。levels=[-1, 0, 1]?表示繪制決策函數為?-1,?0,?1?的等高線,分別對應于間隔的邊界和決策邊界。
- 獲取當前圖形對象?
-
繪制支持向量:
ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100,linewidth=1, facecolors='none', edgecolors='k')- 使用?
scatter?繪制支持向量,這些向量是決策邊界上最靠近數據點的樣本。 clf.support_vectors_?包含支持向量的坐標,s=100?控制支持向量的大小,facecolors='none'?表示使用空心圓點,edgecolors='k'?表示邊框顏色為黑色。
- 使用?
-
保存和顯示圖像:
plt.savefig("../5.png", dpi=500) plt.show()- 使用?
savefig?保存圖像為?5.png,分辨率為?500?dpi。 plt.show()?顯示生成的圖像。
- 使用?
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs# 我們創建40個用來分割的數據點
X, y = make_blobs(n_samples=40, centers=2, random_state=6)# 擬合模型,并且為了展示作用,并不進行標準化
clf = svm.SVC(kernel='linear', C=1000)
clf.fit(X, y)plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)# 繪制decision function的結果
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()# 創造網格來評估模型
xx = np.linspace(xlim[0], xlim[1], 30)
yy = np.linspace(ylim[0], ylim[1], 30)
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
Z = clf.decision_function(xy).reshape(XX.shape)# 繪制決策邊界和邊際
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])
# 繪制支持向量
ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100,linewidth=1, facecolors='none', edgecolors='k')
plt.savefig("../5.png", dpi=500)
plt.show()這幅圖展示了線性核支持向量機在二維空間中的工作效果:
- 散點圖:顯示了生成的二維數據集,每個類別用不同顏色表示。
- 等高線:展示了決策函數的值,黑色虛線表示決策邊界,而實線則表示間隔的邊界。
- 支持向量:用大圓圈表示的支持向量,它們是決策邊界上距離最近的數據點。
03-帶有自定義核函數的支持向量機? ? ? ? ??
????????帶有自定義核函數的支持向量機(SVM)允許在非線性可分的情況下進行分類,通過將數據映射到高維特征空間來實現線性分離。以下是對帶有自定義核函數的SVM的詳細解釋:
基本概念
核函數:
- 核函數是SVM中的關鍵概念,它定義了數據如何從輸入空間映射到特征空間。在線性不可分的情況下,通過核函數可以在高維空間中找到線性分割超平面,而無需顯式計算高維特征空間的數據表示。
支持向量機:
- SVM是一種監督學習算法,其目標是找到一個超平面來最大化不同類別數據點之間的間隔。對于線性不可分的情況,引入核函數使得SVM可以處理復雜的數據結構,如曲線或高度非線性分布的數據。
工作原理
帶有自定義核函數的SVM的工作原理如下:
核方法:
- SVM使用核方法計算數據點之間的相似性,而不是直接操作高維空間中的數據。核函數可以是多種類型,如線性、多項式、高斯(徑向基函數)等。
非線性映射:
- 核函數將輸入空間中的數據映射到高維特征空間,使得在高維空間中可能是線性可分的。例如,徑向基函數(RBF)核會將數據映射到無限維的特征空間,在此空間中,數據點更有可能是線性可分的。
決策邊界:
- 在高維特征空間中,SVM尋找一個最優超平面來分割數據。這個超平面可以被視為在原始輸入空間中復雜邊界的映射。
數學形式
使用核函數的SVM的數學形式如下:
給定一個核函數 ( K(\mathbf{x}_i, \mathbf{x}_j) ),它可以通過內積計算兩個數據點 ( \mathbf{x}_i ) 和 ( \mathbf{x}_j ) 在特征空間中的相似度。
優化目標仍然是找到一個超平面 ( \mathbf{w} \cdot \Phi(\mathbf{x}) + b = 0 ),其中 ( \Phi(\mathbf{x}) ) 是特征空間中的映射函數。
實現和應用
在實際應用中,選擇合適的核函數非常重要,它直接影響了模型的性能和泛化能力。常見的核函數有:
- 線性核函數:
- 多項式核函數:
,其中 ( \gamma )、 ( r ) 和 ( d ) 是參數。
- 徑向基函數(RBF)核:
,其中 ( \gamma ) 是參數。
總結
帶有自定義核函數的支持向量機通過核方法將非線性問題映射到高維空間中進行處理,從而實現了在復雜數據結構中的高效分類。選擇合適的核函數和調整其參數對于模型的性能和泛化能力至關重要,這需要根據具體問題進行實驗和優化。
這段代碼演示了如何使用帶有自定義核函數的支持向量機(SVM)對鳶尾花數據集進行分類,并繪制分類結果的決策邊界。
代碼解釋
-
導入庫和數據集
import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets這里導入了需要使用的庫,包括NumPy用于數據處理,Matplotlib用于繪圖,以及sklearn中的svm和datasets模塊。
-
加載數據
iris = datasets.load_iris() X = iris.data[:, :2] # 僅使用前兩個特征,這里使用了切片操作 Y = iris.target從鳶尾花數據集中加載數據,僅使用前兩個特征(萼片長度和寬度),目標變量為類別標簽。
-
定義自定義核函數
def my_kernel(X, Y):"""我們創建一個自定義的核函數:(2 0)k(X, Y) = X ( ) Y.T(0 1)"""M = np.array([[2, 0], [0, 1.0]])return np.dot(np.dot(X, M), Y.T)這里定義了一個簡單的自定義核函數,它是一個線性核函數的變體,通過矩陣M對輸入數據進行線性變換。
-
創建SVM實例并擬合數據
clf = svm.SVC(kernel=my_kernel) clf.fit(X, Y)使用
svm.SVC創建了一個支持向量機實例,指定了自定義核函數my_kernel,并對數據進行擬合。 -
生成網格并預測
h = .02 # 設置網格中的步長 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])創建了一個網格來覆蓋輸入空間的范圍,并使用訓練好的SVM模型對每個網格點進行分類預測。
-
繪制決策邊界和數據點
Z = Z.reshape(xx.shape) plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)# 繪制訓練點 plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired, edgecolors='k')使用
pcolormesh繪制網格中每個點的預測結果,使用scatter繪制原始數據點,其中不同顏色表示不同的類別。 -
圖像設置和顯示
plt.title('3-Class classification using Support Vector Machine with custom kernel') plt.axis('tight') plt.show()設置標題和坐標軸,然后顯示繪制的圖像。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets# 導入數據以便處理
iris = datasets.load_iris()
X = iris.data[:, :2]
# 我們僅僅使用前兩個特征,我們可以通過使用二維數據集來避免復雜的切片
Y = iris.targetdef my_kernel(X, Y):"""我們創建一個自定義的核函數:(2 0)k(X, Y) = X ( ) Y.T(0 1)"""M = np.array([[2, 0], [0, 1.0]])return np.dot(np.dot(X, M), Y.T)h = .02 # 設置網格中的步長# 我們創建一個SVM實例并擬合數據。
clf = svm.SVC(kernel=my_kernel)
clf.fit(X, Y)# 繪制決策邊界。為此,我們將為網格[x_min,x_max] x [y_min,y_max]中的每個點分配顏色。
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])# 將結果放入顏色圖
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)# 繪制訓練點
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired, edgecolors='k')
plt.title('3-Class classification using Support Vector Machine with custom'' kernel')
plt.axis('tight')
plt.savefig("../5.png", dpi=500)
plt.show()-
背景色塊和決策邊界:
- 背景色塊通過顏色區分了不同類別的預測區域,每個顏色塊表示SVM預測該區域內的所有點屬于同一類別。
- 決策邊界是分類器在特征空間中的決策界限,分隔不同類別的區域。
-
數據點:
- 數據點在圖中以散點的形式顯示,每種類別使用不同的顏色表示,有助于可視化各個類別在特征空間中的分布。
這樣,通過自定義核函數,支持向量機能夠有效地處理非線性問題,并提供清晰的分類決策邊界。

04-繪制線性支持向量機(基于liblinear)的支持向量
????????
繪制線性支持向量機(Linear SVM)基于liblinear的支持向量,需要了解以下幾個關鍵點:
線性支持向量機(Linear SVM)
核心概念:
- 線性支持向量機是通過一個線性超平面來分割數據空間,使得不同類別的數據點能夠盡可能遠離超平面,從而構建最優的分類邊界。
支持向量:
- 支持向量是離超平面最近的數據點,它們決定了超平面的位置。在線性情況下,支持向量通常位于分類邊界附近,是決策邊界的主要構成部分。
繪制支持向量的步驟解釋
使用
LinearSVC初始化模型:from sklearn.svm import LinearSVC model = LinearSVC() model.fit(X, Y)
LinearSVC是scikit-learn中專門用于線性SVM分類的模型。通過fit方法訓練模型,其中X是特征數據,Y是對應的類別標簽。獲取支持向量:
support_vectors = model.support_vectors_
support_vectors_屬性可以獲取模型中找到的支持向量的數據點。繪制支持向量和決策邊界:
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired, edgecolors='k') plt.scatter(support_vectors[:, 0], support_vectors[:, 1], s=100, facecolors='none', edgecolors='k')
- 使用
scatter方法繪制所有數據點,其中不同顏色代表不同類別。- 使用
scatter方法再次繪制支持向量,通常使用圓圈標識,以突出顯示它們。設置圖像屬性:
plt.title('Support Vectors of Linear SVM (liblinear)') plt.xlabel('Feature 1') plt.ylabel('Feature 2') plt.show()
- 添加標題和坐標軸標簽,最后使用
show方法展示繪制的圖像。圖像解釋
數據點:
- 所有數據點通過散點圖顯示,顏色表示它們的類別。這些點包括訓練集中的所有數據。
支持向量:
- 通過繪制大圓圈(只有邊界沒有填充)標識出模型確定的支持向量。這些點是模型決策邊界最接近的數據點,對模型的決策起到關鍵作用。
決策邊界:
- 在線性SVM中,決策邊界是一個直線,它在特征空間中分隔不同類別的數據點。
通過這種方式,可以清晰地展示線性支持向量機的工作原理及其在數據集上的表現,特別是如何通過支持向量確定最優的分類邊界。
這段代碼演示了如何使用Scikit-Learn的LinearSVC繪制線性支持向量機(Linear SVM)的決策邊界和支持向量。
代碼解釋
-
數據生成與初始化模型
X, y = make_blobs(n_samples=40, centers=2, random_state=0)- 使用
make_blobs生成一個二分類的數據集,共40個樣本,用于模擬實際數據。
- 使用
-
模型訓練與決策邊界繪制
for i, C in enumerate([1, 100]):clf = LinearSVC(C=C, loss="hinge", random_state=42).fit(X, y)decision_function = clf.decision_function(X)support_vector_indices = np.where((2 * y - 1) * decision_function <= 1)[0]support_vectors = X[support_vector_indices]- 對每個參數C(正則化參數)分別訓練一個LinearSVC模型。
loss="hinge"指定了線性SVM所使用的損失函數。 decision_function計算決策函數的值,支持向量的索引通過條件(2 * y - 1) * decision_function <= 1確定。- 支持向量通過這些索引從數據集X中獲取。
- 對每個參數C(正則化參數)分別訓練一個LinearSVC模型。
-
繪制圖像
plt.subplot(1, 2, i + 1) plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired) ax = plt.gca() xlim = ax.get_xlim() ylim = ax.get_ylim() xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50),np.linspace(ylim[0], ylim[1], 50)) Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--']) plt.scatter(support_vectors[:, 0], support_vectors[:, 1], s=100,linewidth=1, facecolors='none', edgecolors='k') plt.title("C=" + str(C))- 使用
subplot在一行兩列中創建子圖,分別展示不同參數C的結果。 - 通過
scatter方法繪制所有數據點,根據類別用不同顏色標示。 - 使用
contour函數繪制決策邊界,其中levels=[-1, 0, 1]繪制了決策函數為-1、0、1的等高線,代表不同的決策邊界。 - 通過
scatter繪制支持向量,使用大圓圈表示,以突出顯示它們。
- 使用
-
圖像屬性設置與展示
plt.tight_layout() plt.savefig("../5.png", dpi=500) plt.show()- 使用
tight_layout確保圖像布局合適。 savefig保存圖像為高分辨率PNG格式。show展示生成的圖像。
- 使用
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.svm import LinearSVCX, y = make_blobs(n_samples=40, centers=2, random_state=0)plt.figure(figsize=(10, 5))
for i, C in enumerate([1, 100]):# "hinge"是支持向量機慣例使用的損失函數clf = LinearSVC(C=C, loss="hinge", random_state=42).fit(X, y)# 通過決策函數獲得支持向量decision_function = clf.decision_function(X)# 我們也可以手動計算決策函數# decision_function = np.dot(X, clf.coef_[0]) + clf.intercept_[0]support_vector_indices = np.where((2 * y - 1) * decision_function <= 1)[0]support_vectors = X[support_vector_indices]plt.subplot(1, 2, i + 1)plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)ax = plt.gca()xlim = ax.get_xlim()ylim = ax.get_ylim()xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50),np.linspace(ylim[0], ylim[1], 50))Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])plt.scatter(support_vectors[:, 0], support_vectors[:, 1], s=100,linewidth=1, facecolors='none', edgecolors='k')plt.title("C=" + str(C))
plt.tight_layout()
plt.savefig("../5.png", dpi=500)
plt.show()- 左圖(C=1):較小的正則化參數C,決策邊界可以更接近一些數據點,支持向量的數量較多。
- 右圖(C=100):較大的正則化參數C,決策邊界更嚴格,支持向量的數量較少。
在每幅圖中,數據點用不同顏色表示不同的類別,決策邊界用黑色實線(0值)、虛線(-1和1值)表示,支持向量用大圓圈標出。這種可視化方式清晰地展示了線性支持向量機在不同正則化參數下的決策邊界和支持向量位置。

總結? ? ? ? ? ? ? ? ? ? ? ??
????????總之,支持向量機因其在解決小樣本問題和處理高維數據時的優秀表現而受到廣泛關注,盡管需要注意的是在大數據集和復雜問題上可能面臨一些挑戰。



-使用參數化模型投影點)



4門1453元最熱門證書限時免費考)
)










