前言
在Redis的眾多數據結構中,Hash(哈希)類型占據著至關重要的地位。Redis本身就是一個高性能的鍵值(Key-Value)數據庫,其底層的鍵值對便是通過哈希方式組織的。而Hash數據類型則更進一步,它允許在Value層級再構建一個鍵值對集合,形成一種“域-值”(Field-Value)的映射關系。這種結構使得Hash特別適合用來存儲對象信息,您可以將一個對象的多個屬性高效地聚合在一個Redis鍵中
之前學過的所有數據結構中,最最重要的
redis自身已經是鍵值對的結構了
redis自身的鍵值對就是通過哈希的方式來組織的額
把key這一層組織完成之后,到了value這一層,value的其中一種類型還可以是哈希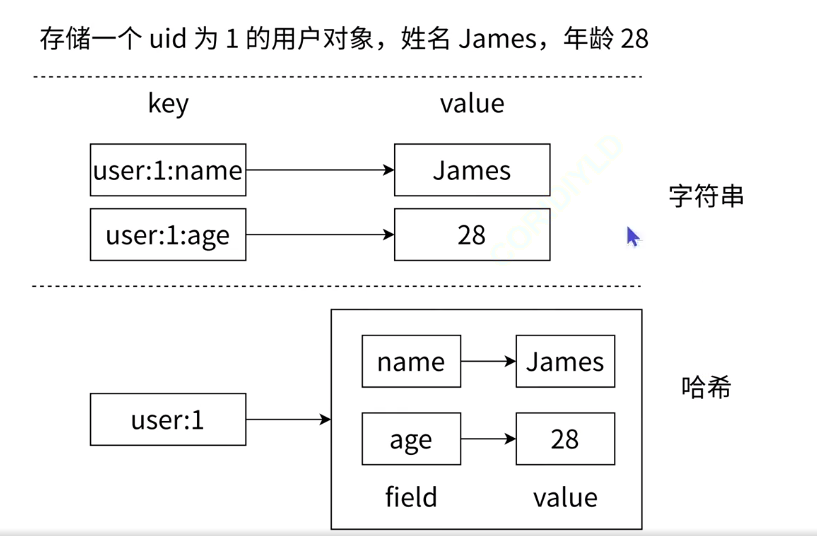
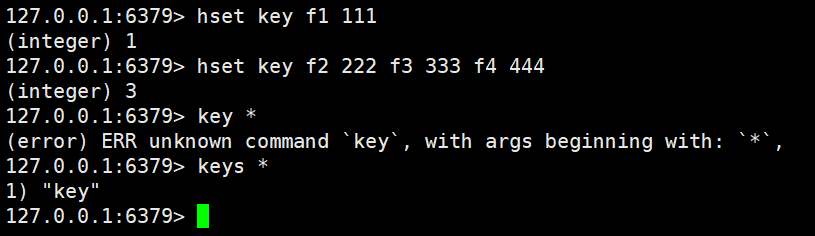
hset、hget
hset就是設置鍵值對
field->value
返回值是設置成功的鍵值對(field–value)
hset key field value [field value...]
然后我們使用hget進行key里面鍵值對的獲取
hget key field
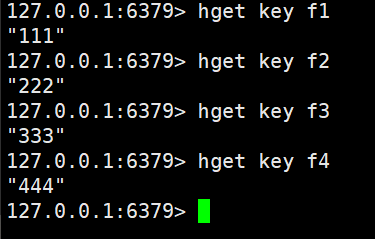
如果要查詢的內容不存在的話就返回nil
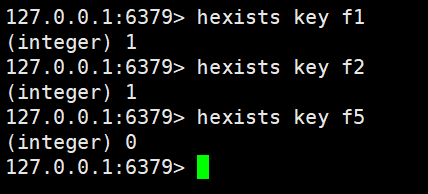
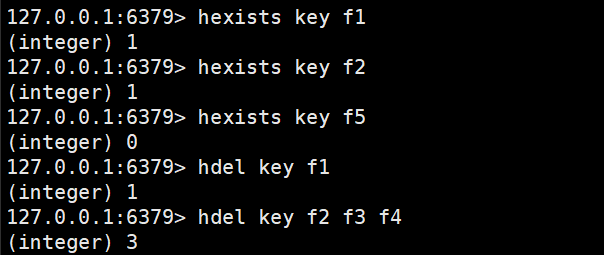
hexists
判斷hash中是否有指定的字段
hexists key field
返回1就是存在,返回0就是不存在
hdel
刪除hash中指定的字段
del刪除的是key
hdel刪除的是field
hdel key field [field]
都是先指定key,再來指定一個或者多個field
返回值就是本次操作刪除的字段個數
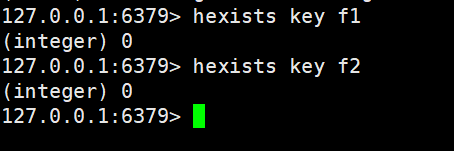
查看是否存在我們是查不到的,因為已經刪除了
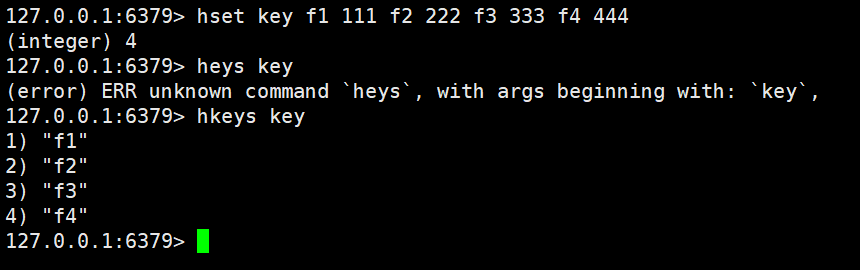
hkeys 、hvals
獲取hash中的所有字段
hkeys key
返回值:字段列表
時間復雜度:O(N)
原理就是根據Key找到對應的hash O(1)
然后遍歷hash O(N)這個N是hash的元素個數
這個查詢到的就是我們當前hash中的所有的Key了
這個操作也是存在一定風險的,類似于之前介紹的keys *
主要是我們也不知道某個hash鐘是否存在大量的field
可能會造成阻塞
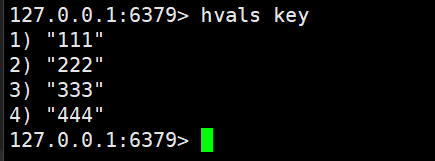
hvals key
能夠獲取hash中所有的value
h系列的命令必須保證key對應的value得是哈希類型的
hgetall 、hmget
hegtall獲取hash中的所有字段以及對應的值
hgetall key
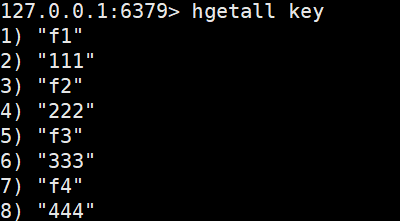
hmget類似于之前的mget,可以一次查詢多個field
hget只能查詢一個field,但是hmget可以查詢多個field
hmget key
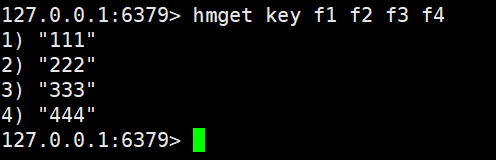
多個value的順序和value是匹配的
有沒有hmset,一次設置多個field和value呢?
有,但是并不需要,因為hset已經支持一次設置多個field和value了
hkeys,hvals,hgetall都是存在一定風險的,hash的元素個數太多了,執行的耗時會比較長,從而阻塞redis
hscan遍歷redis的hash,但是他是屬于漸進式遍歷,就是敲一次命令,遍歷一小部分,再敲一次,再遍歷一小部分
連續執行多次,就可以完成整個的遍歷過程了
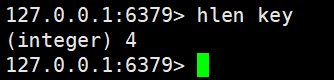
hlen、hsetnx
hlen獲取hash中的所有字段的個數
hlen key
這個獲取hash中的某個字段的個數我們是不需要進行遍歷的
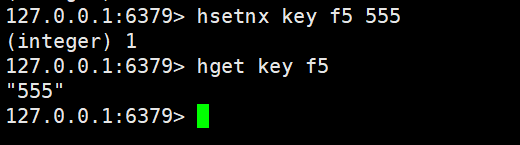
hsetnx
在字段不存在的情況下,設置hash中的字段和值,和之前的setnx很相似的
hsetnx key field value
hincrby 、hincrbyfloat
hash這里的value,也可以當做數字來處理
hincrby就可以加減整數,返回計算后的結果
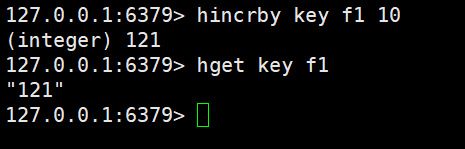
hincrbyfloat可以加減小數
好的,這是根據圖片內容生成的表格:
命令小結
| 命令 | 執行效果 | 時間復雜度 |
|---|---|---|
| hset key field value | 設置值 | O(1) |
| hget key field | 獲取值 | O(1) |
| hdel key field [field …] | 刪除 field | O(k), k 是 field 個數 |
| hlen key | 計算 field 個數 | O(1) |
| hgetall key | 獲取所有的 field-value | O(k), k 是 field 個數 |
| hmget field [field …] | 批量獲取 field-value | O(k), k 是 field 個數 |
| hmset field value [field value …] | 批量獲取 field-value | O(k), k 是 field 個數 |
| hexists key field | 判斷 field 是否存在 | O(1) |
| hkeys key | 獲取所有的 field | O(k), k 是 field 個數 |
| hvals key | 獲取所有的 value | O(k), k 是 field 個數 |
| hsetnx key field value | 設置值,但必須在 field 不存在時才能設置成功 | O(1) |
| hincrby key field n | 對應 field-value +n | O(1) |
| hincrbyfloat key field n | 對應 field-value +n | O(1) |
| hstrlen key field | 計算 value 的字符串長度 | O(1) |
hash內部編碼
哈希的內部編碼有兩種:
- ziplist(壓縮列表):當哈希類型元素個數?于 hash-max-ziplist-entries 配置(默認 512 個)、同時所有值都?于 hash-max-ziplist-value 配置(默認 64 字節)時,Redis 會使? ziplist 作為哈希的內部實現,ziplist 使?更加緊湊的結構實現多個元素的連續存儲,所以在節省內存???hashtable 更加優秀。
- hashtable(哈希表):當哈希類型?法滿? ziplist 的條件時,Redis 會使? hashtable 作為哈希的內部實現,因為此時 ziplist 的讀寫效率會下降,? hashtable 的讀寫時間復雜度為 O(1)。
壓縮的本質是針對數據進行重新編碼
ziplist付出的代價,進行讀寫元素,速度是比較慢的
哈希中的元素比較少,使用ziplist,元素多的話就使用hashtable
每個value的長度比較短,使用ziplist
如果太長了的話,也會轉換成hashtable
使用場景
關系型數據表保存用戶信息
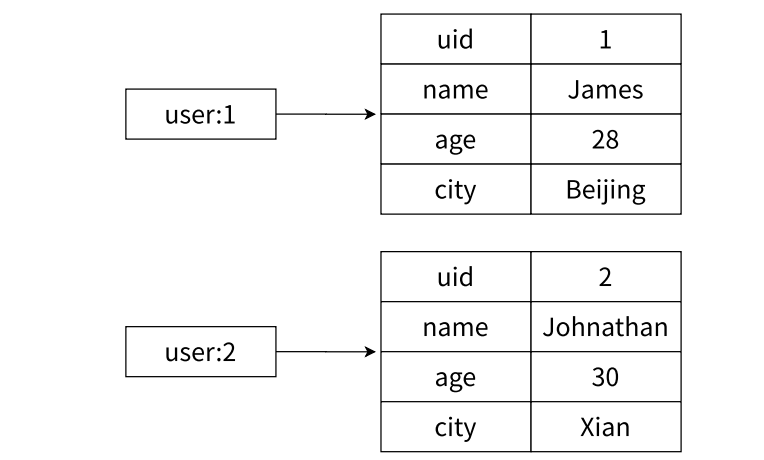
高內聚低耦合
Redis Hash因其結構化的數據存儲方式和高效的字段訪問能力,在實際應用中非常廣泛。
-
緩存對象信息:這是最經典的使用場景。例如,用戶信息、商品信息、會話數據等都可以存儲在Hash中。 相比于將整個對象序列化為JSON字符串再存入Redis,使用Hash可以讓您獨立地更新或獲取對象的某個屬性,而無需讀取和重寫整個對象,這在并發更新時能避免數據覆蓋問題并提升性能。
- 示例: 一個用戶對象可以這樣存儲:HSET user:1001 name “Alice” age 30 email "
-
購物車:電商應用中的購物車功能與Hash結構完美契合。可以用用戶ID作為鍵(key),商品ID作為域(field),商品數量作為值(value)。
- 示例:?HSET cart:1001 product:558 2?表示用戶1001的購物車中有2件ID為558的商品。通過HINCRBY可以方便地增減商品數量。
-
計數器聚合:當需要對一個對象的多個指標進行計數時,Hash非常有用。例如,記錄一篇文章的點贊數、評論數、分享數。
- 示例:?HINCRBY article:998 likes 1,HINCRBY article:998 comments 1。
- 、
總結
Redis的Hash數據類型提供了一種在單個鍵下存儲多個鍵值對的高效方式,是模擬和存儲對象數據的理想選擇。它通過提供豐富的命令,實現了對對象屬性的靈活、高效操作。相比于使用JSON字符串存儲,Hash在更新部分字段時性能優勢明顯,且更加節省網絡帶寬。理解并善用ziplist和hashtable兩種內部編碼的特點,可以在內存效率和執行性能之間找到最佳平衡點,從而更好地發揮Redis的強大能力。

——模板初階)
)



)

![[筆記] 系統分析師 第十二章 軟件架構設計(分析師主要工作)](http://pic.xiahunao.cn/[筆記] 系統分析師 第十二章 軟件架構設計(分析師主要工作))










