?目錄
一、InnoDB 行格式數據準備
二、COMPACT行格式整體說明
三、記錄的額外信息
(一)變長字段長度列表
數據結構
存儲過程
讀取過程
變長字段長度列表存儲示例
(二)NULL 值位圖
數據結構
存儲過程
讀取過程
NULL 值位圖示例說明
(三)行頭信息
基本定義分析
案例分析
四、隱藏列
(一)基本說明
(二)主鍵的選擇順序說明
(三)案例分析
五、記錄真實數據
主要參考和學習來源
干貨分享,感謝您的閱讀!
先分享一個真實的案例:某大型電商平臺在一次促銷活動中遭遇了數據庫性能瓶頸,通過優化 InnoDB 的行格式,他們將查詢性能提升了30%,存儲成本降低了20%。這不僅幫助他們順利度過了高峰期,還大大提升了用戶體驗。
- 查詢性能提升:通過選擇適當的行格式(如 Compact 或 Dynamic),可以減少存儲開銷和提升數據訪問速度,從而加快查詢響應時間。
- 存儲成本降低:壓縮行格式(如 Compressed)可以顯著減少磁盤空間的使用,特別是在處理大量冗長字符串或重復數據時。
想象一下,你正在設計一個需要處理海量數據的應用,從用戶信息到交易記錄,每一行數據的存儲方式都會直接影響到你的系統響應速度和存儲成本。那么,如何選擇最合適的行格式來最大化性能和效率呢?
本次我們聚焦 InnoDB 行格式,理解它們是如何在幕后悄悄發揮作用的。行格式的設計反映了數據庫設計者在權衡性能、存儲和兼容性時的決策。到現在為止一共設計了4種不同類型的行格式 ,分別是 Compact 、 Redundant 、Dynamic 和 Compressed 行格式,隨著時間的推移,他們可能會設計出更多的行格式,但是不管怎么變,在原理上大體都是相同的。
我們本次主要針對Compact? InnoDB 行格式進行分析理解。
一、InnoDB 行格式數據準備
在 MySQL 中,數據是以記錄為單位插入到表中的,而這些記錄在磁盤上的存放方式,就是我們所說的“行格式”或者“記錄格式”。
首先,我們來看一下如何在創建或修改表時指定行格式。我們可以使用 CREATE TABLE 或 ALTER TABLE 語句來指定行格式。其語法如下:
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名稱;
ALTER TABLE 表名 ROW_FORMAT=行格式名稱;
假設我們在名為 xiaohaizi 的數據庫中創建一個名為 record_format_demo 的表,并指定它的行格式為 Compact,同時設置字符集為 ASCII(ASCII 字符集只包括空格、標點符號、數字、大小寫字母和一些不可見字符,所以我們的漢字是不能存到這個表里的)。如下所示:
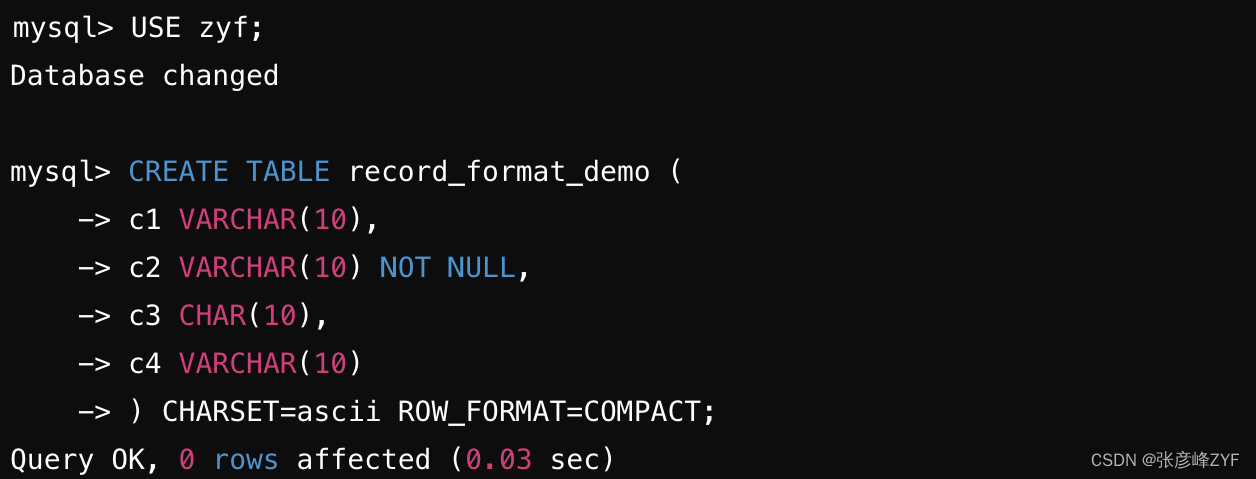
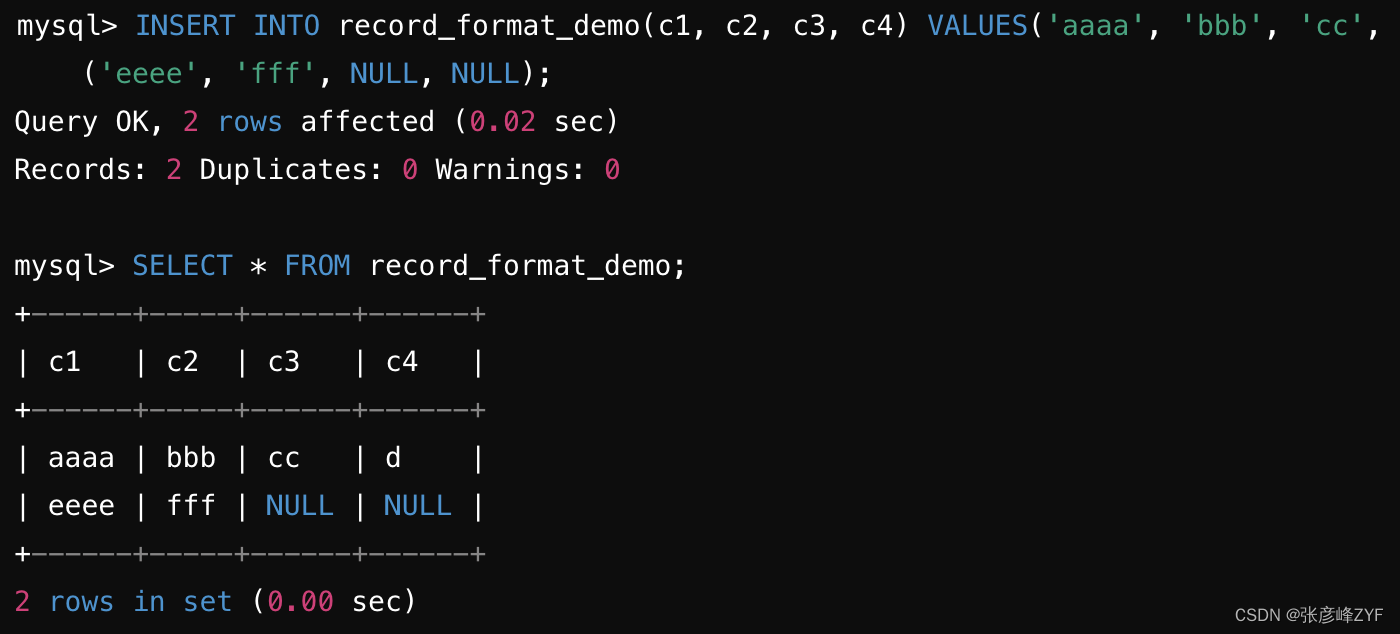
向這個表中插入兩條記錄,并查看插入結果:
在實際應用中,選擇合適的行格式可以顯著提升數據庫的性能和存儲效率。例如,對于讀多寫少的場景,Compressed 行格式可能是一個不錯的選擇,而對于寫操作頻繁的場景,Compact 行格式可能會更合適。因各原理上大體都是相同,所以我們下面針對Compact進行理解。
二、COMPACT行格式整體說明
Compact 行格式適用于大多數通用場景,尤其是需要高效存儲和讀取的小型至中型表。它提供了良好的性能和平衡的存儲效率,是 InnoDB 存儲引擎中的默認選擇。
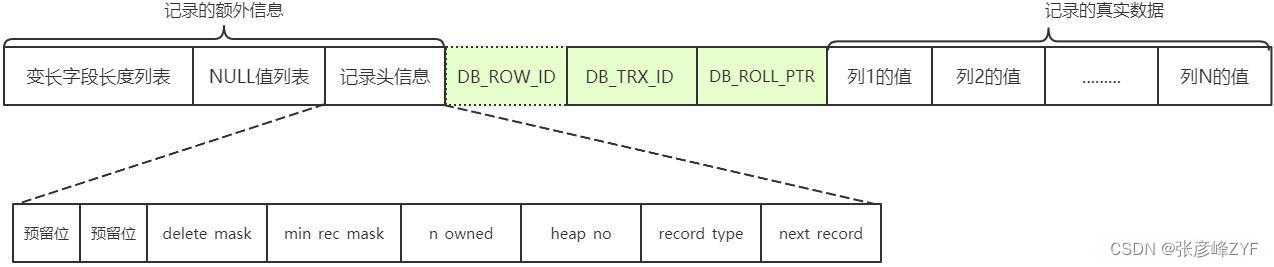
Compact 行格式在物理存儲上采用以下結構:
- 行頭信息:用于存儲事務信息和回滾指針,占用 5 個字節。
- NULL 值位圖:用于標識哪些列是 NULL 值,每個列對應 1 個 bit。
- 變長字段長度列表:緊跟在 NULL 值位圖之后,記錄變長字段的長度信息。
- 隱藏列:每行有 6 個字節用于兩個隱藏的系統列,包括事務 ID 和回滾指針。
- 實際數據:存儲實際的數據值,緊湊排列。
三、記錄的額外信息
(一)變長字段長度列表
在 InnoDB 存儲引擎的 Compact 行格式中,變長字段長度列表用于存儲變長字段的長度信息,比如VARCHAR(M) 、 VARBINARY(M) 、各種 TEXT 類型,各種 BLOB 類 型。通過這種方式,Compact 行格式能夠高效地管理和存儲變長字段的數據。
由于變長字段的長度是不固定的,InnoDB 需要一種方式來記錄和讀取這些字段的實際長度,以便正確地存取數據。
數據結構
每個變長字段占用 1 到 2 個字節:長度小于 255 字節的字段使用 1 個字節來存儲長度信息,而長度等于或大于 255 字節的字段使用 2 個字節來存儲長度信息。
具體來說:
如果字段的長度小于 255 字節,則使用 1 個字節表示其長度。
如果字段的長度大于或等于 255 字節,則使用 2 個字節表示其長度。
存儲過程
- 計算每個變長字段的實際長度:對于每個變長字段,計算其實際長度。
- 根據長度決定字節數:如果長度小于 255,則使用 1 個字節存儲長度;否則,使用 2 個字節存儲長度。
- 存儲長度信息:將長度信息按順序存儲在變長字段長度列表中。
- 存儲實際數據:緊跟在變長字段長度列表之后存儲實際的數據值。
讀取過程
- 讀取變長字段長度列表:首先讀取變長字段長度列表,獲取每個變長字段的長度信息。
- 根據長度信息讀取數據:根據變長字段長度列表中的長度信息,準確定位和讀取每個變長字段的實際數據值。
變長字段長度列表存儲示例
針對之前創建的 compact_format_demo 表和插入的數據進行分析:
- 針對第一條插入的數據 'aaaa', 'bbb', 'cc', 'd':
c1字段值為 'aaaa',長度為 4(占用 1 個字節表示長度)。c2字段值為 'bbb',長度為 3(占用 1 個字節表示長度)。c3字段值為 'cc',長度為 2(占用 1 個字節表示長度)。c4字段值為 'd',長度為 1(占用 1 個字節表示長度)。
- 針對第二條插入的數據 'eeee', 'fff', NULL, NULL':
c1字段值為 'eeee',長度為 4(占用 1 個字節表示長度)。c2字段值為 'fff',長度為 3(占用 1 個字節表示長度)。c3字段為 NULL,不需要額外的長度信息。c4字段為 NULL,不需要額外的長度信息。
變長字段長度列表是按照字段順序緊跟在 NULL 值位圖之后存儲的。
- 對于第一條記錄,長度列表為 [4][3][2][1],占用了 4 個字節。
- 對于第二條記錄,長度列表為 [4][3],占用了 2 個字節。
總的長度列表占用了 6 個字節。
(二)NULL 值位圖
在 InnoDB 存儲引擎的 Compact 行格式中,NULL 值位圖用于標識每個字段是否為 NULL 值。在 InnoDB 存儲引擎中,NULL 值不占用實際的存儲空間,因此需要一種方式來標識哪些字段是 NULL,以便在讀取數據時正確處理這些字段。
數據結構
- 每個字段占用 1 個 bit:位圖中的每個 bit 對應一列,用于標識該列是否為 NULL 值。
- 位圖中的 bit 排列順序:按照字段在表中的順序依次排列,從左到右。
存儲過程
- 遍歷每個字段:對于每個字段,檢查其是否為 NULL 值。
- 設置對應位圖中的 bit:如果字段為 NULL 值,則將對應位圖中的 bit 設置為 1;否則,將其設置為 0。
- 位圖的實際存儲:位圖中的 bit 按照字段的順序依次存儲,每個 bit 占用 1 位。
讀取過程
- 讀取 NULL 值位圖:首先讀取 NULL 值位圖,獲取每個字段是否為 NULL 值的信息。
- 根據位圖讀取數據:根據位圖中的信息,準確讀取每個字段的數據值。如果對應位圖中的 bit 為 1,則表示該字段為 NULL 值;否則,讀取實際的數據值。
NULL 值位圖示例說明
還是針對之前創建的 compact_format_demo 表和插入的數據進行分析:
-
對于第一條插入的數據 ('aaaa', 'bbb', 'cc', 'd'):
c1字段的值為 'aaaa',不是 NULL 值。c2字段的值為 'bbb',不是 NULL 值。c3字段的值為 'cc',不是 NULL 值。c4字段的值為 'd',不是 NULL 值。- NULL 值位圖為 [0][0][0][0],表示所有字段均不為 NULL。
-
對于第二條插入的數據 ('eeee', 'fff', NULL, NULL):
c1字段的值為 'eeee',不是 NULL 值。c2字段的值為 'fff',不是 NULL 值。c3字段的值為 NULL,是 NULL 值。c4字段的值為 NULL,是 NULL 值。- NULL 值位圖為 [0][0][1][1],表示
c3和c4字段為 NULL,而c1和c2字段不為 NULL。
(三)行頭信息
在 InnoDB 存儲引擎中,每個記錄都有一個記錄頭信息,它由固定的 5 個字節(40 個二進制位)組成。這 5 個字節中的每一位都有特定的含義,描述了記錄的一些重要信息。

基本定義分析
每個記錄的開頭有一個記錄頭信息,這些信息包含了對記錄的描述和控制。以下是每個二進制位代表的詳細信息:
-
預留位1(1 bit):該位暫時未被使用。
-
預留位2(1 bit):該位暫時未被使用。
-
delete_mask(1 bit):標記該記錄是否被刪除。如果被刪除,則該位為 1;否則為 0。
-
min_rec_mask(1 bit):B+樹的每層非葉子節點中的最小記錄都會添加該標記。如果是最小記錄,則該位為 1;否則為 0。
-
n_owned(4 bits):表示當前記錄擁有的記錄數。使用 4 個 bits 來表示,可以表示的最大值為 15。
-
heap_no(13 bits):表示當前記錄在記錄堆中的位置信息。使用 13 個 bits 來表示,可以表示的最大值為 8191。
-
record_type(3 bits):表示當前記錄的類型。0:普通記錄。1:B+樹非葉子節點記錄。2:最小記錄。3:最大記錄。
-
next_record(16 bits):表示下一條記錄相對于當前記錄的位置。使用 16 個 bits 來表示,可以表示的最大值為 65535。
這些記錄頭信息的二進制位提供了有關記錄的詳細描述,包括了是否被刪除、記錄的擁有數量、位置信息等。理解這些信息有助于更好地理解 InnoDB 存儲引擎中記錄的存儲和組織方式,以及對數據庫的性能和功能的影響。
案例分析
我們來分析一下 compact_format_demo 表中插入的第二條記錄 ('eeee', 'fff', NULL, NULL)的記錄頭信息分析:
先整理理論依據:
- delete_mask:用于標記記錄是否被刪除。
- min_rec_mask:用于標記是否是 B+ 樹非葉子節點中的最小記錄。
- n_owned:表示當前記錄擁有的記錄數。
- heap_no:表示當前記錄在記錄堆中的位置信息。
- record_type:表示當前記錄的類型,包括普通記錄、B+ 樹非葉子節點記錄、最小記錄和最大記錄。
- next_record:表示下一條記錄相對于當前記錄的位置。
現在可以進行如下推斷:
- 對于
delete_mask和min_rec_mask,根據描述,如果滿足描述條件則為 1,否則為 0。 - 對于
n_owned,在這個例子中沒有其他相關的記錄,所以這個值應該是 0。 - 對于
heap_no,插入的第二條記錄應該在記錄堆的第二個位置,因此其二進制表示應該是 00000000000010。 - 對于
record_type,根據描述,這是一個普通記錄,所以這個值應該是 0。 - 對于
next_record,因為這是最后一條記錄,所以下一條記錄的相對位置應該是 0。
綜上所述,我們可以得出插入的第二條記錄的記錄頭信息應該是:
delete_mask: 0
min_rec_mask: 0
n_owned: 0
heap_no: 2
record_type: 0
next_record: 0
四、隱藏列
(一)基本說明
了解記錄的真實數據以外,還有一些隱藏列由MySQL自動添加到每個記錄中,這些列包括:
-
row_id:行ID,用于唯一標識一條記錄。在InnoDB表中,如果用戶沒有定義主鍵,也沒有定義Unique鍵,則InnoDB會為表默認添加一個名為row_id的隱藏列作為主鍵。這個列的存在意味著即使沒有顯式定義主鍵,每條記錄仍然有一個唯一的標識符。
-
transaction_id:事務ID,用于標識執行此次數據操作的事務。每個事務都有一個唯一的事務ID,這有助于數據庫跟蹤和管理事務的執行順序,以及處理并發事務之間的沖突。
-
roll_pointer:回滾指針,用于實現多版本并發控制(MVCC)機制。回滾指針記錄了事務開始時行的舊版本的位置,以便在需要時回滾事務或查詢歷史數據。
(二)主鍵的選擇順序說明
提及row_id涉及到主鍵的生成策略時,InnoDB表遵循一定的規則來確定主鍵的選擇順序。具體如下:
-
用戶自定義主鍵:首先,InnoDB會優先選擇用戶自定義的主鍵作為表的主鍵。如果用戶已經顯式地定義了一個列作為主鍵,那么這個列將被用作表的主鍵。
-
Unique鍵作為主鍵:如果用戶沒有定義主鍵,但定義了一個Unique鍵(唯一索引),那么InnoDB會將這個Unique鍵作為表的主鍵。這樣做是為了確保每條記錄都有一個唯一的標識符。
-
默認主鍵(row_id):如果表中既沒有用戶自定義的主鍵,也沒有定義Unique鍵,那么InnoDB會為表默認添加一個名為row_id的隱藏列作為主鍵。這個列是InnoDB內部生成的,用于確保每條記錄都有一個唯一的標識符。
(三)案例分析
對于第二條插入的數據 ('eeee', 'fff', NULL, NULL):
-
事務ID:每個事務都有一個唯一的事務ID,表示執行此次數據操作的事務。對于第二條插入的記錄,我們假設事務ID為 T2。
-
回滾指針:回滾指針用于實現多版本并發控制(MVCC)機制,記錄了事務開始時行的舊版本的位置。對于第二條插入的記錄,我們假設回滾指針為 RP2。
因此,插入的第二條記錄的隱藏列值可能如下所示:
- 事務ID:T2(占用 6 個字節)
- 回滾指針:RP2(占用 6 個字節)
這些隱藏列的值是由InnoDB存儲引擎自動生成的,對于用戶來說是不可見的,支持事務管理和并發控制。
五、記錄真實數據
記錄的真實數據是指用戶自定義的列數據,即在表中定義的可見列的值。
在 compact_format_demo 表中,可見列包括 c1、c2、c3 和 c4。對于第二條插入的記錄 ('eeee', 'fff', NULL, NULL),其真實數據如下:
c1:'eeee'c2:'fff'c3:NULLc4:NULL
這些值是用戶插入的數據,它們對于數據庫來說是可見的,可以通過查詢操作檢索到。與隱藏列不同,這些數據由用戶直接提供,并且在數據庫中占據著特定的列位置。
因為表 record_format_demo 并沒有定義主鍵,所以 MySQL 服務器會為每條記錄增加上述的3個列。現在看一下加上 記錄的真實數據 的兩個記錄長什么樣吧:
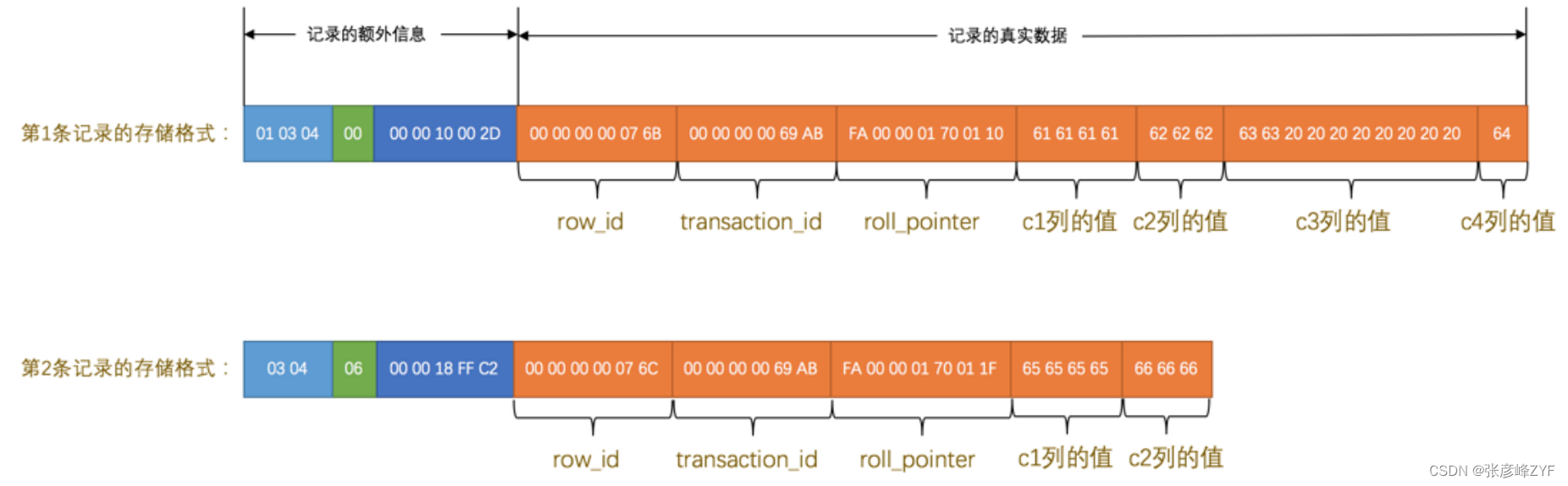
看這個圖的時候我們需要注意幾點:
- 表 record_format_demo 使用的是 ascii 字符集,所以 0x61616161 就表示字符串 'aaaa' , 0x626262 就表 示字符串 'bbb' ,以此類推。
- 注意第1條記錄中 c3 列的值,它是 CHAR(10) 類型的,它實際存儲的字符串是: 'cc' ,而 ascii 字符集中 的字節表示是 '0x6363' ,雖然表示這個字符串只占用了2個字節,但整個 c3 列仍然占用了10個字節的空 間,除真實數據以外的8個字節的統統都用空格字符填充,空格字符在 ascii 字符集的表示就是 0x20 。
- 注意第2條記錄中 c3 和 c4 列的值都為 NULL ,它們被存儲在了前邊的 NULL值列表 處,在記錄的真實數據處 就不再冗余存儲,從而節省存儲空間。
主要參考和學習來源
《MySQL 是怎樣運行的:從根兒上理解 MySQL》
https://dev.mysql.com/doc/refman/5.7/en/
https://dev.mysql.com/doc/internals/en/?
http://www.orczhou.com/
https://blog.jcole.us/innodb/



)

)






內容 5 元數據)





)
