學習率
學習率是訓練神經網絡的重要超參數之一,它代表在每一次迭代中梯度向損失函數最優解移動的步長。它的大小決定網絡學習速度的快慢。在網絡訓練過程中,模型通過樣本數據給出預測值,計算代價函數并通過反向傳播來調整參數。重復上述過程,使得模型參數逐步趨于最優解從而獲得最優模型。在這個過程中,學習率負責控制每一步參數更新的步長。合適的學習率可以使代價函數以合適的速度收斂到最小值。
lr?即?stride (步長)?,即反向傳播算法中的?η :
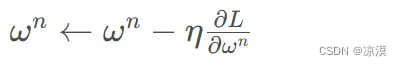
學習率大小

學習率對網絡的影響
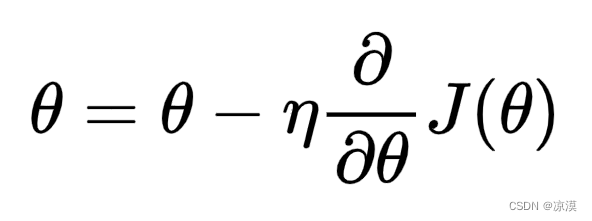
根據上述公式我們可以看到
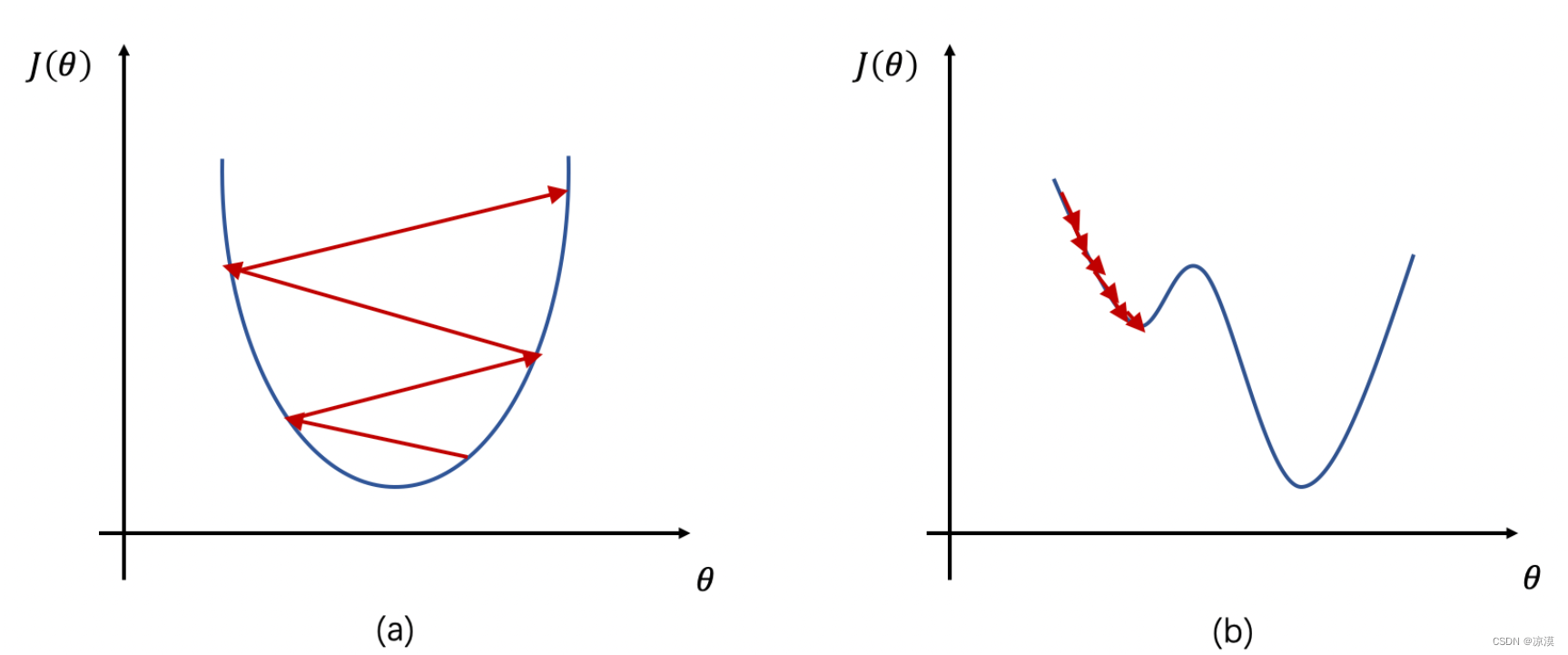
- 如果學習率?η 較大,那么參數的更新速度就會很快,可以加快網絡的收斂速度,但如果學習率過大,可能會導致參數在最優解附近震蕩,代價函數難以收斂,甚至可能會錯過最優解,導致參數向錯誤的方向更新,代價函數不僅不收斂反而可能爆炸(如圖1a所示)。
- 如果學習率?η 較小,網絡可能不會錯過最優點,但是網絡學習速度會變慢。同時,如果學習率過小,則很可能會陷入局部最優點(如圖1b所示)。因此,只有找到合適的學習率,才能保證代價函數以較快的速度逼近全局最優解。
學習率設置
在訓練過程中,一般根據訓練輪數設置動態變化的學習率。
- 剛開始訓練時:學習率以 0.01 ~ 0.001 為宜。
- 一定輪數過后:逐漸減緩。
- 接近訓練結束:學習速率的衰減應該在100倍以上。
隨機梯度下降算法
目前深度學習模型多采用批量隨機梯度下降算法進行優化,隨機梯度下降算法的原理如下,
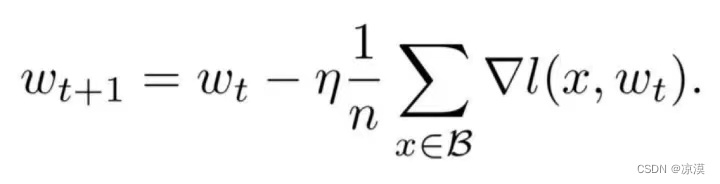
n是批量大小(batchsize),η是學習率(learning rate)。可知道除了梯度本身,這兩個因子直接決定了模型的權重更新,從優化本身來看它們是影響模型性能收斂最重要的參數。
學習率直接影響模型的收斂狀態,batchsize則影響模型的泛化性能,兩者又是分子分母的直接關系,相互也可影響,因此這一次來詳述它們對模型性能的影響。
參考:
深度學習基礎入門篇[六]:模型調優,學習率設置(Warm Up、loss自適應衰減等),batch size調優技巧,基于方差放縮初始化方法。-騰訊云開發者社區-騰訊云 (tencent.com)
【深度學習】學習率 (learning rate)_深度學習中學習率-CSDN博客?
深度學習中學習率(lr:learn rate)和batchsize如何影響模型性能?_batchsize和learning rate關系-CSDN博客
機器學習——學習率(Learning Rate)_learningrate一般設多少-CSDN博客






內容 5 元數據)





)






