把detection和phrase ground(對于給定的sentence,要定位其中提到的全部物體)這兩個任務合起來變成統一框架,從而擴展數據來源,因為文本圖像對的數據還是很好收集的
目標檢測的loss是分類loss+定位loss,它與phrase ground的定位loss差不多,但是二者分類loss不同,因為對于目標檢測,它的標簽是一個或者兩個單詞,是one-hot標簽,但是對于vision grounding它的標簽是一個句子
目標檢測的分類loss:分類頭預測bonding box類別,nms排序,跟ground truth算交叉熵
vision grounding的分類loss:先計算匹配分數s,看看圖像中的區域和句子中的單詞是怎么匹配的。圖像經過image backbone得到一些region feature,但是接下來不用分類頭,而是一個文本編碼器生成的文本特征做相似度計算,得到s
改動:判斷什么時候算是一個positive match,什么時候算是negative match。當這些sub-words的phrase與目標region匹配時,每個positive sub-word都與目標region所匹配。例如,吹風機的phrase是“Hair dryer”,那么吹風機的region就會與“Hair”和“dryer”這兩個詞都匹配
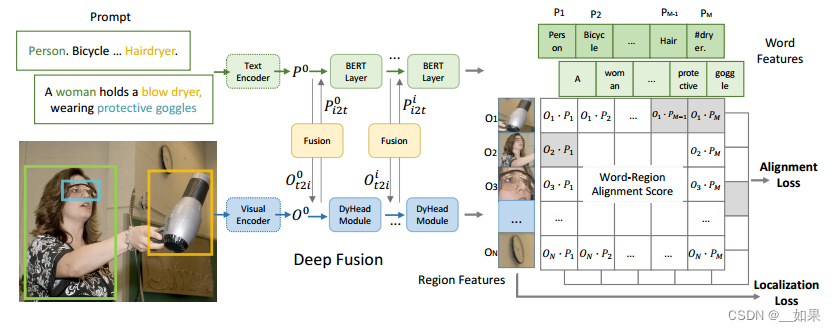
中間的deep fusion是加幾個層讓文本和圖像的模態信息融合得更好一點?
)













抽象類與接口【求個關注!】)



)
