文章目錄
- 一,GAN(對抗式生成網絡)
- 二,Auto-Encoder(AE) 和 Denoising Auto-Encoder (DAE)
- 三,VAE
- 四,VQ-VAE (Vector Quantized Variational Autoencoder)
- VQ-VAE 2
- 小總結:
- 五,DALL-E (OpenAI) (2021.02)
一,GAN(對抗式生成網絡)
- 生成器: 給定一個隨機噪聲,生成比較真實的圖像
- 判別器:給一個生成的圖像和真實的圖像,讓判別器去判斷,哪個是真圖片,哪個是假圖片
- 判別器和生成器會不斷提升自身的能力,互相較量。 DEEP FAKE 火爆 大家可以試一試這個基于GAN的應用。
- 缺點:
- GAN的 訓練不夠穩定,因為他要同時訓練兩個網絡,所以就有一個平衡的問題。訓練不好的話,模型就坍塌 了
- GAN 主要的目標就是“真實”, 所以他的 創造性不好。他的多樣性來自于剛開始的隨機噪聲。他 不是一個概率模型,他的生成是隱式的,是通過一個網絡去完成的,所以你不知道他做了什么,遵循什么分布,在數學上不優雅。

二,Auto-Encoder(AE) 和 Denoising Auto-Encoder (DAE)
-
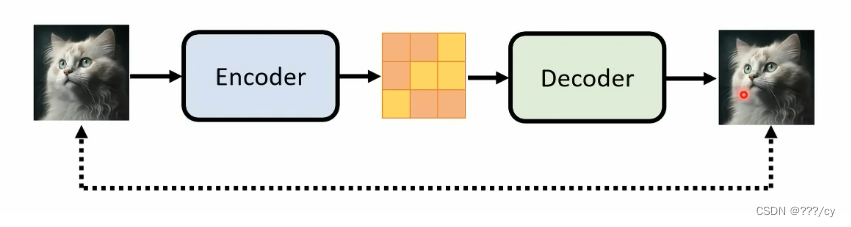
自己重建自己:給定一個圖片, 輸入到一個Encoder 里面, 然后得到一個維度小很多的 特征,然后過一個 Decoder 解碼器,最后得到一個圖像。我們的目標函數呢,就是重建這個圖像,所以是自己重建自己,自回歸模型
-
中間那個特征維度很小,所以也叫bottleneck
-
主要目的是學習bottleneck特征的,把這個特征去做分類,分割,檢測這些任務。并不是用來做生成的,他這里學到的不是一個概率分布。我們沒法對他進行采樣。
-
Denoising Auto-Encoder: 把輸入的原始圖片進行打亂 ,重建原始的圖片。會讓訓練的模型更加的穩健。
AE 和 DAE 主要的目的是去學bottlenck的特征,用這個特征去做 下游任務,并不是用來做生成的。
| Encoder- Decoder這個結構很好,如何用這個結構做圖像生成呢? VAE來了。 |
三,VAE
VAE 學習的不是 特征了,而是一個分布, 作者假設這個 分布是一個高斯分布,這個分布就可以用 (均值,方差) 來表示。
具體來說:當我們從編碼器得到特征之后,我們在后面加 FC 層,用它去預測 均值 和 方差 , 然后就可以用下面的公式,采樣一個 z 出來,這樣VAE就可以做生成了,這個 z 就是一個可以從高斯分布中隨機抽樣出的一個樣本。
從貝葉斯概率的角度來看, VAE 學的是一個概率分布,他從分布里去抽樣,所以他生成圖片的多樣性 比GAN好很多
缺點: VAE 不好把圖片的尺寸做大,而且 z 的分布也不是很好學
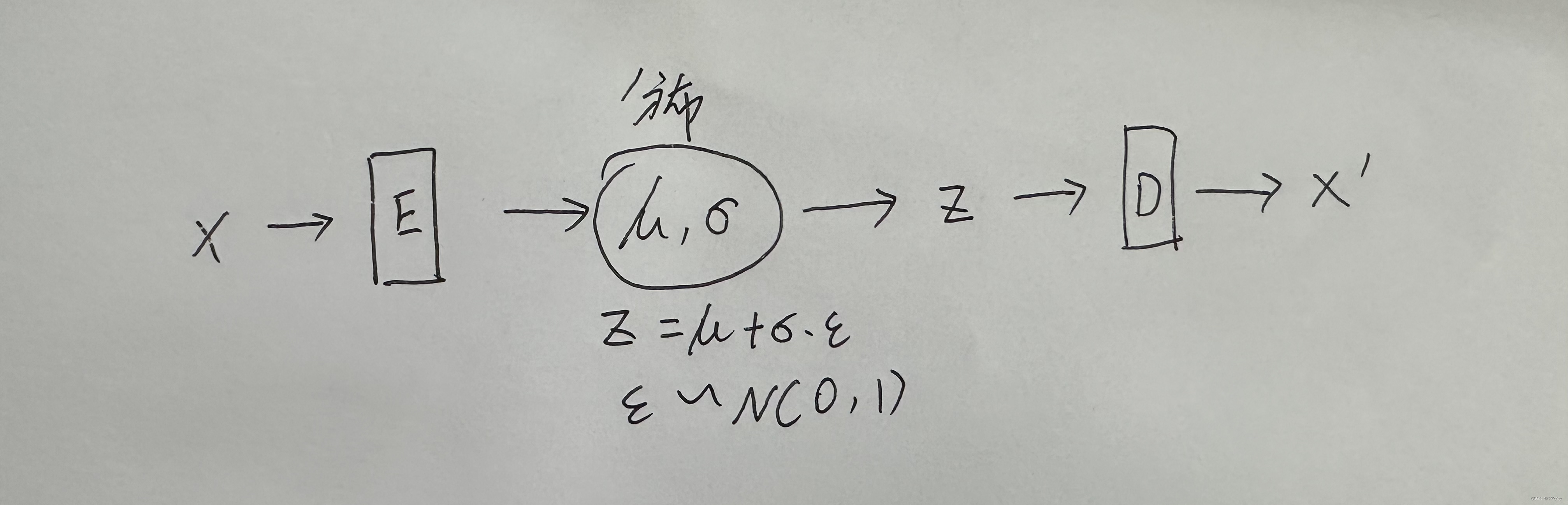

四,VQ-VAE (Vector Quantized Variational Autoencoder)
DALL-E的第一版模型就是 在VQ-VAE的基礎上做的.
把VAE量化 離散 了。
- 為什么離散VAE呢? VAE 不好把圖片的尺寸做大,而且 z 的分布也不是很好學
- 取而代之的是,不去做分布的推測,而是 用一個codebook去代替了。
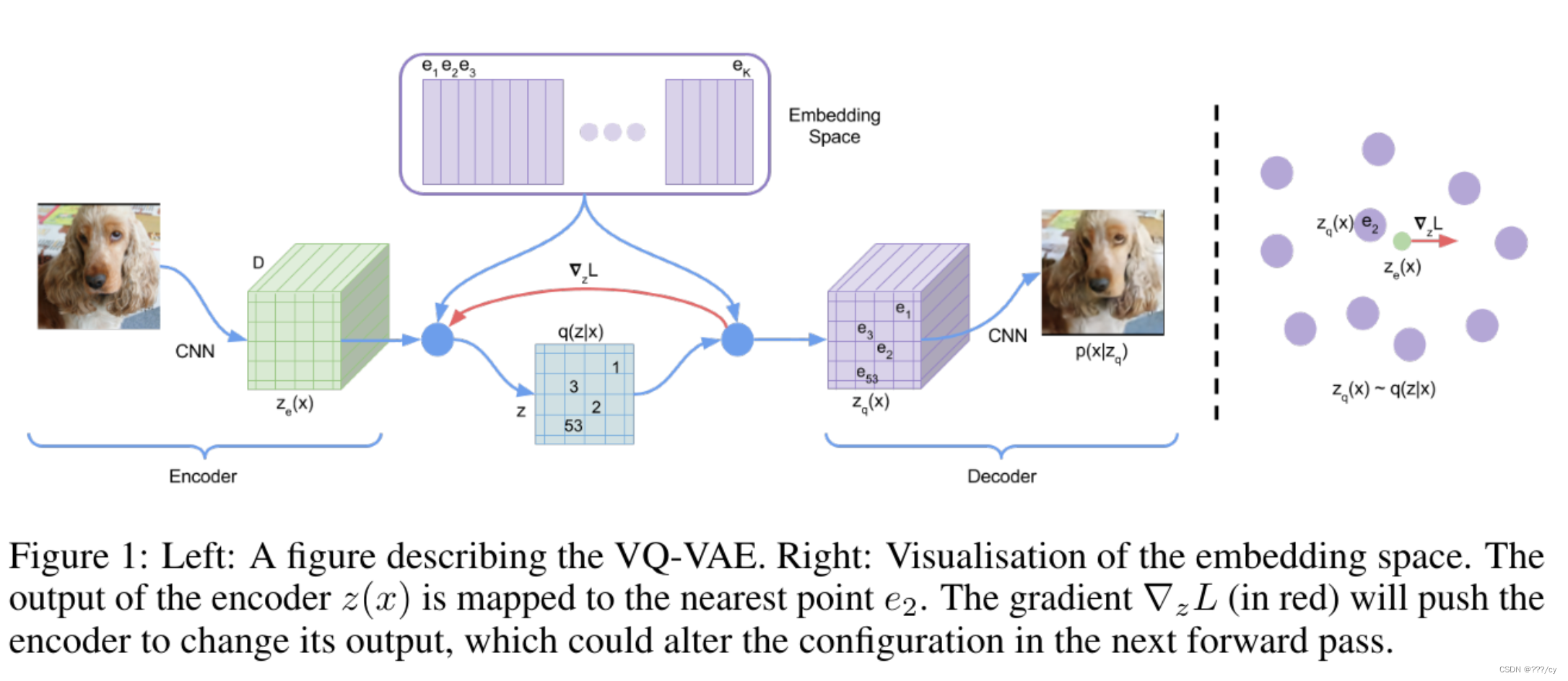
- codebook可以理解為聚類的中心,codebook的大小一般為KXD(8192x512), 也就是8192個聚類中心
- codebook可以理解為聚類的中心,codebook的大小一般為KXD(8192x512), 也就是8192個聚類中心
- 輸入一個圖片進入編碼器得到一個特征圖,把特征圖里面的向量 和 codebook 里面的向量做對比,看他和哪個聚類中心最接近,然后就把聚類中心這個編碼 存到 Z 這個矩陣里, 一旦做好了聚類的分配,我們就不需要之前的特征圖了,取而代之的是,把Z 中index 對應的codebook的特征拿出來,變成一個新的特征圖 ,也就是一個量化后的特征 (quantized feature), 這個量化后的特征就非常可控了,他是從codebook里面來的,而不是一個隨機的東西。所以優化起來相對容易。
- 然后通過解碼器重構一張圖片。
| 這里的codebook有點像 AE 里面的 bottlenet那塊的特征,是拿去做high level 的任務的,也就是做分類,檢測。 如果想讓他做生成,我們還需要單獨 再 訓練一個prior 網絡。 |
在視覺這邊 BEIT 把 DALL-E訓練好的 codebook 拿過去,然后把圖片全都量化成這樣子的特征圖,拿這個去做Ground Truth,自監督的訓練一個視覺網絡。
- 缺點:VQ-VAE 學習的是一個固定的codebook,就意味著他沒有辦法像 VAE 這樣隨機采樣,生成對應的圖片
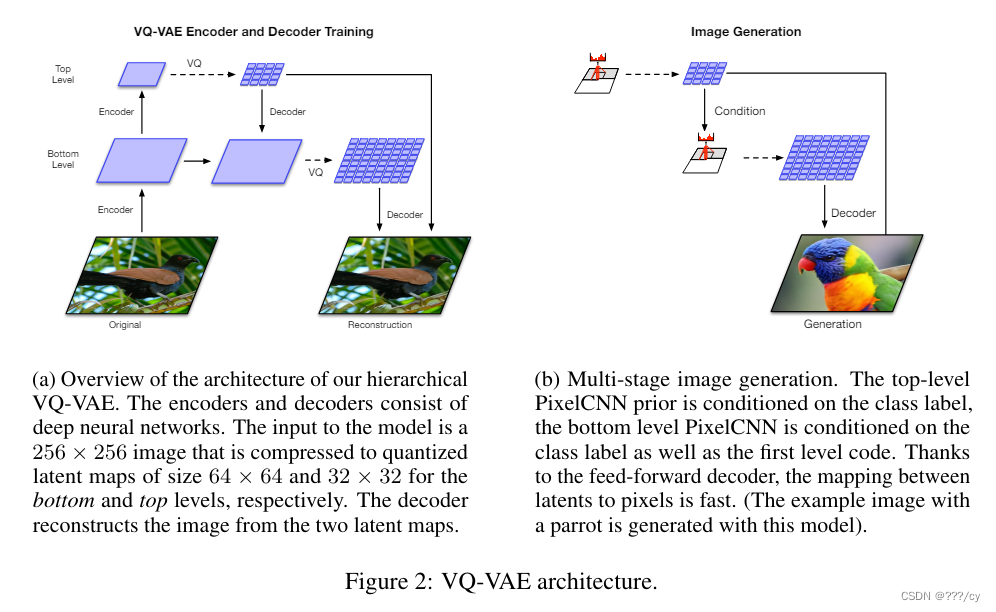
VQ-VAE 2
- 把模型變成層級式的,不僅做局部的建模,也做了全局的建模,還加上了attention,模型表達能力變強了
- 同時,他還根據codebook 又去學了一個prior,
- 作者這里訓練了一個 pixelCNN 當作這個 prior 網絡, 從而能夠利用這個訓練好的codebook來做圖像的生成。 pixcelCNN 是一個自回歸模型
小總結:
對于VQ-VAE來說,先訓練了一個codebook, 然后又訓練一個pixcelCNN去做生成。
pixcelCNN 是一個自回歸模型,還有什么模型是自回歸模型嗎? GPT
五,DALL-E (OpenAI) (2021.02)
- OpenAI 把pixcelCNN 換成了GPT。既然 language 那邊做的又那么好,為什么不想個辦法,用文本來引導圖像生成呢?所以就有了DALL-E
- 把文本特征和圖像特征直接連接起來,就變成了一個有1280token的序列
- 然后把序列給到GPT,隨機把token做一下mask,然后GPT去自回歸的還原這個mask token
- 推理的時候,提供text,變成text embedding, 然后GPT 把文本特征 用自回歸的方式 把圖片生成出來




















