
【摘要】檢索增強生成(RAG)通過檢索相關知識來增強大語言模型(LLM),在減輕 LLM 幻覺和提高響應質量方面顯示出巨大的潛力,從而促進 LLM 在實踐中的廣泛采用。然而,我們發現現有的 RAG 系統不足以回答多跳查詢,這需要對多個支持證據進行檢索和推理。此外,據我們所知,現有的 RAG 基準測試數據集還沒有關注多跳查詢。在本文中,我們開發了一個新穎的數據集 MultiHop-RAG,它由知識庫、大量多跳查詢、其真實答案以及相關的支持證據組成。我們詳細介紹了構建數據集的過程,利用英語新聞文章數據集作為底層 RAG 知識庫。我們在兩個實驗中展示了 MultiHop-RAG 的基準測試實用性。第一個實驗比較了用于檢索多跳查詢證據的不同嵌入模型。在第二個實驗中,我們檢查了各種最先進的 LLM(包括 GPT-4、PaLM 和 Llama2-70B)在給定證據的情況下推理和回答多跳查詢的能力。這兩個實驗都表明,現有的 RAG 方法在檢索和回答多跳查詢方面的表現并不令人滿意。我們希望 MultiHop-RAG 能夠成為社區開發有效 RAG 系統的寶貴資源,從而促進法學碩士在實踐中得到更多采用。
原文:MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
地址:https://arxiv.org/abs/2401.15391v1
代碼:https://github.com/yixuantt/MultiHop-RAG/
出版:未知
機構: Hong Kong University of Science and Technology
1 研究問題
本文研究的核心問題是: 如何針對需要檢索和推理多個證據片段的多跳問題,構建一個檢索增強生成(RAG)評測數據集。
在金融分析場景下,用戶可能會提出類似"對比2023年三季報中谷歌、蘋果和英偉達的毛利率,誰的最高?"這樣的多跳問題。它需要從各公司財報中檢索相關證據,并進行比較推理得出最終答案。現有的RAG評測數據集主要聚焦單跳問題,缺乏對多跳問題的系統研究。
本文研究問題的特點和現有方法面臨的挑戰主要體現在以下幾個方面:
-
多跳問題的答案分散在多個文檔中,需要模型具備跨文檔的檢索和推理能力。這對文本匹配模型提出了更高要求。
-
構建多跳問題的評測集需要更細粒度的證據標注,既要標明問題的最終答案,還要標明推理鏈上的關鍵證據片段。人工標注的成本較高。
-
評測集要具有良好的問題類型覆蓋性。基于對實際應用場景的觀察,本文將多跳問題歸納為推理類、比較類、時序類和空問題類四種。
-
評測集的知識庫要與預訓練語言模型的訓練數據相區分,以測試模型在未見過的領域上的檢索推理能力。
針對這些挑戰,本文提出了一種基于GPT-4輔助構建的"MultiHop-RAG"數據集:
本文利用GPT-4強大的語言理解和生成能力,實現了MultiHop-RAG數據集的半自動化構建。具體而言,首先從一個新聞文章數據集出發,抽取每篇文章中的事實性句子作為原始證據。接著利用GPT-4改寫每個證據,生成對應的聲明,并識別出其中的核心實體和話題作為后續生成多跳問題的"橋接點"。然后再利用GPT-4圍繞相同的橋接實體或話題,構造出推理類、比較類、時序類和空問題類四種多跳問題及其答案。最后,本文還設計了一套嚴格的人工檢查和模型驗證流程,以保證構建數據的質量。
與依賴純人工方式構建的傳統做法相比,本文方法在保證數據質量的同時大幅提升了標注效率。更重要的是,借助GPT-4的知識化生成能力,本文得以構建出難度更高、類型更豐富的多跳問題。MultiHop-RAG最終包含了2500余個多跳問題,其中88%的問題答案需要結合知識庫中2-4個證據片段推理得出。在后續的評測實驗中,無論是檢索階段還是答案生成階段,現有的RAG模型在MultiHop-RAG上的表現都遠低于單跳問題,充分說明了該數據集對RAG模型研究的推動作用。
2 研究方法
論文提出了一種新的數據集MultiHop-RAG,旨在評估能夠從多個證據源檢索和推理信息以回答多跳查詢的檢索增強生成(RAG)系統的性能。MultiHop-RAG包含一個知識庫、大量多跳查詢及其參考答案和相關證據。
2.1 MultiHop-RAG數據集構建
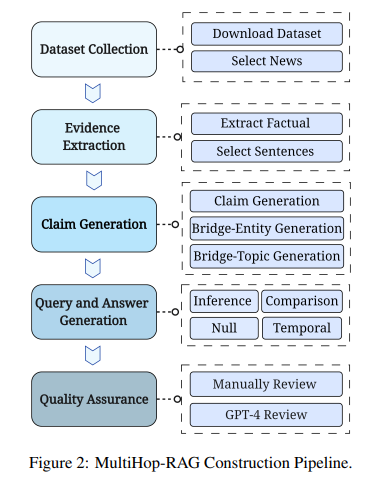
2.1.1 知識庫構建
為了構建MultiHop-RAG的知識庫,論文使用mediastack API下載了大量英文新聞文章,涵蓋娛樂、商業、體育、技術、健康和科學等不同類別。為了模擬真實的RAG場景,論文選擇了2023年9月26日至12月26日期間發布的新聞,這個時間范圍超出了ChatGPT和LLaMA等廣泛使用的語言模型的知識截止點。此外,論文只保留了token數大于等于1024的文章,每篇新聞都有標題、發布日期、作者、類別、URL和新聞來源等元數據。
2.1.2 數據生成流程
論文采用了一個廣泛的流程來構建多樣化的多跳查詢集合,每個查詢都需要從知識庫中檢索和推理多個文檔。首先,論文使用訓練好的語言模型從每篇新聞文章中提取事實性或觀點性句子作為證據。然后,論文利用GPT-4對證據進行釋義,稱為"主張"(claim),并識別每個主張的主題(topic)和實體(entity)。這些主題和實體可以作為不同證據之間的橋梁,稱為bridge-topic或bridge-entity。接下來,論文使用GPT-4根據具有相同bridge-topic或bridge-entity的主張集合來生成具體的多跳查詢及其答案。最后,論文采取驗證步驟以確保數據質量,包括人工抽檢和使用GPT-4評估每個樣本是否滿足特定標準。
2.1.3 多跳查詢類型
根據真實RAG系統中常見的查詢類型,論文將多跳查詢分為四類:
-
推理查詢(Inference query):需要從證據集合中推理出答案。
-
比較查詢(Comparison query):需要比較證據集合中的事實。
-
時序查詢(Temporal query):需要分析檢索到的證據塊的時序信息。
-
空查詢(Null query):答案無法從檢索集合中得出。空查詢用于評估語言模型在缺乏相關證據時是否會產生幻覺。
這四種查詢類型代表了RAG系統在實踐中經常遇到的場景。例如,在一個由財務報告組成的知識庫中,分析師可能會詢問"谷歌、蘋果和英偉達中哪家公司在2023年第三季度報告中利潤率最高?"(比較查詢),或"蘋果過去三年的銷售趨勢如何?"(時序查詢)。
2.2 使用MultiHop-RAG進行評估
論文通過兩個實驗展示了如何使用MultiHop-RAG來評估RAG系統的檢索和生成性能。實驗使用基于LlamaIndex框架實現的RAG系統。
2.2.1 檢索任務
第一個實驗比較了不同嵌入模型在檢索多跳查詢相關證據方面的性能。實驗將知識庫中的文檔劃分為包含256個token的塊,并使用嵌入模型將文本塊轉換為向量表示。對于每個查詢,實驗檢索與查詢嵌入具有最高余弦相似度的前K個塊。實驗測試了多種嵌入模型,包括OpenAI的ada-embeddings、voyage-02、llm-embedder等。實驗使用平均精度(MAP@K)、平均倒數排名(MRR@K)和命中率(Hit@K)等指標評估檢索性能。
2.2.2 生成任務
第二個實驗評估了不同語言模型在給定檢索證據的情況下回答多跳查詢的能力。實驗考慮了兩種設置:1)使用表現最佳的檢索模型檢索前K個文本塊;2)直接使用與每個查詢相關的真實證據。后一種設置代表了語言模型生成能力的上限。實驗評估了GPT-4、GPT-3.5、PaLM、Claude-2、Llama2-70B和Mixtral-8x7B等領先的語言模型。結果表明,當前的RAG系統在有效檢索和回答多跳查詢方面還有很大的改進空間。即使在提供真實證據的情況下,開源語言模型的生成準確率也不理想。相比之下,GPT-4展現出較強的推理能力,但仍有進一步提升的空間。
總的來說,MultiHop-RAG數據集提供了一個具有挑戰性的基準,用于評估RAG系統從多個來源檢索和推理信息以回答復雜查詢的能力。論文詳細介紹了數據集的構建過程,展示了如何使用該數據集來評估RAG系統的不同組件,為RAG研究社區提供了有價值的資源。
4 實驗
4.1 實驗場景介紹
該論文提出了一個新的多跳查詢數據集MultiHop-RAG,用于基于檢索的語言生成任務(Retrieval-augmented Generation, RAG)的評估。論文實驗旨在展示MultiHop-RAG數據集在評估RAG系統的檢索和生成能力方面的benchmarking作用。
4.2 實驗設置
-
實驗使用論文提出的MultiHop-RAG數據集,該數據集包含一個知識庫、大量多跳查詢、相應的ground-truth答案以及支撐證據。
-
實驗使用LlamaIndex框架實現RAG系統。
- 評估指標:
-
檢索任務使用MRR@K、MAP@K、Hits@K等指標
-
生成任務使用Accuracy指標
-
-
實驗環境:未提及
4.3 實驗結果
4.3.1 實驗一、不同Embedding模型在多跳查詢檢索任務上的表現對比

目的: 評估不同Embedding模型在多跳查詢檢索任務上的表現。
涉及圖表: 表5
實驗細節概述:
-
將MultiHop-RAG知識庫中的文檔分割成chunks,每個chunk包含256個token
-
使用不同的Embedding模型將chunk轉換為向量表示,存入向量數據庫
-
使用相同的Embedding模型將查詢轉換為向量,檢索與查詢向量余弦相似度最高的Top-K個chunk
-
評估檢索結果,NULL類型查詢不包含在評估中
結果:
-
現有的Embedding模型在檢索多跳查詢相關證據方面表現不佳,即使使用Reranker技術,Hits@10的最佳結果也只有0.7467
-
實際RAG系統中,語言模型的上下文窗口通常有限制,因此檢索的chunk數量受限,Hits@4只有0.6625,說明現有方法無法有效檢索多跳查詢的相關證據
4.3.2 實驗二、不同語言模型在多跳查詢生成任務上的表現對比
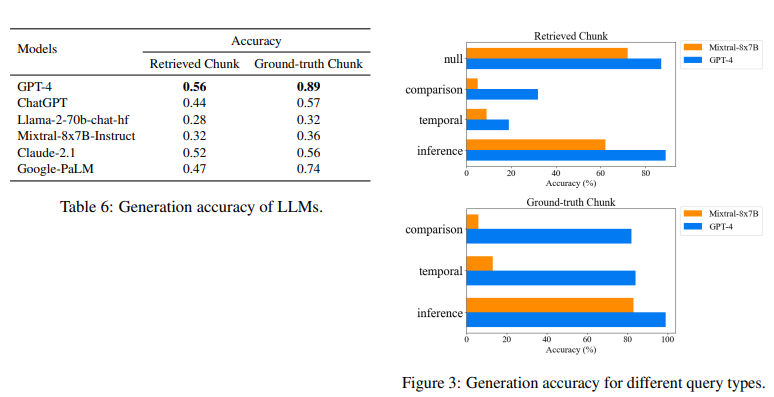
目的: 評估不同語言模型在多跳查詢生成任務上的表現。
涉及圖表: 表6,圖3
實驗細節概述:
-
實驗一:使用實驗一中性能最佳的檢索模型(voyage-02+bge-reranker-large)檢索Top-K文本作為Language Model的輸入
-
實驗二:直接使用每個查詢對應的ground-truth evidence作為Language Model的輸入,代表理想檢索結果下的Language Model表現上限
-
評估GPT-4、GPT-3.5、Claude-2、Google-PaLM等商業模型和Mixtral-8x7B、Llama-2-70B等開源模型
結果:
-
使用檢索文本作為輸入時,最先進的GPT-4模型的準確率也只有0.56
-
即使直接使用ground-truth evidence作為輸入,GPT-4的準確率為0.89,其他模型更低,說明語言模型在多跳查詢推理方面還有很大提升空間
-
不同類型的多跳查詢難度不同,Null Query較易判斷,而Comparison Query和Temporal Query對語言模型推理能力要求更高
4 總結后記
本論文針對現有Retrieval-Augmented Generation (RAG)系統在回答多跳查詢(Multi-hop query)方面表現不佳的問題,構建了一個新的數據集MultiHop-RAG。該數據集包含一個知識庫、大量多跳查詢及其標準答案和支撐證據。論文詳細介紹了利用新聞文章數據構建數據集的過程,并通過兩個實驗展示了MultiHop-RAG在評測RAG系統性能方面的有用性。實驗結果表明,現有RAG方法在檢索和回答多跳查詢方面表現欠佳。MultiHop-RAG有望成為社區開發有效RAG系統的寶貴資源。
疑惑和想法:
-
除了新聞文章,是否可以利用其他領域的文本來構建類似的多跳查詢數據集?不同領域的數據在RAG任務難度上可能存在差異。
-
除了精確匹配和Reranker,是否存在其他更有效的多跳查詢證據檢索方法?如何利用查詢分解、知識圖譜等技術來提升檢索性能?
-
論文目前只評測了生成準確性,是否可以引入其他指標如生成流暢性、多樣性等,以更全面地評估RAG系統的生成能力?
可借鑒的方法點:
-
利用GPT-4等強大語言模型自動構建大規模、高質量的評測數據集的方法可推廣到其他NLP任務。
-
多跳查詢的定義和分類方法可用于指導其他涉及多文檔推理的任務如多文檔摘要、開放域問答等的研究。
-
實驗中檢索模型和生成模型分別評測的思路可用于論文的發現和評估,有利用解耦不同模塊,定位RAG系統的優化方向。













)
)




