計算機硬件
考情分析:趨勢很小,22年考過,根據趨勢以后考的可能較小
- 基本組成:運算器,控制器,儲存器,輸入設備,輸出設備
- 運算器和控制器也統稱為中央處理單元(CPU),CPU是用于數據的加工處理,能完成邏輯運算,算術和控制功能
- 儲存器:計算機系統的記憶系統,又分為外部儲存器和內部儲存器
- 輸入輸出設備又合稱外部設備(外設)
1.中央處理單元
- 功能:程序控制,操作控制,時間控制,數據控制;CPU還會對系統的內部和外部的異常中斷做出響應,進行處理;
- 程序控制:CPU通過指令來控制程序的執行順序
- 操作控制:一條指令功能需要有若干個操作信號來配合完成,CPU產生每條指令的操作信號并將操作信號發往對應的部件,控制相應的部件進行指定的功能進行操作
- 時間控制:CPU對各種操作進行時間的控制,既指令執行過程中操作信號的出現時間,持續時間,出現順序進行一個嚴格的控制
- 數據處理:
- 組成:運算器,控制器,寄存器和內部總線等部件組成
- 運算器:由ALU,AC,DR,PSW組成。完成所有的算術運算;執行所有的邏輯運算并進行邏輯測試;
- 算術邏輯單元(ALU):實現對數據的算術和邏輯運算
- 累加寄存器(AC):運算結果和源數據的存放區
- 數據緩沖寄存器(DR):暫時存放內存的指令或數據
- 狀態條件寄存器(PSW)保持指令運行結構的條件碼內容
- 控制器:由IR,PC,AR,ID組成;控制整個CPU的工作,最為重要
- 指令寄存器(IR):暫存CPU指令
- 程序計數器(PC):存放指令執行地址
- 地址寄存器(AR):保存當前CPU所訪問的內存地址
- 指令譯碼器(ID):分析指令操作碼
- 運算器:由ALU,AC,DR,PSW組成。完成所有的算術運算;執行所有的邏輯運算并進行邏輯測試;
1.CPU執行算術運算或者邏輯運算時,常將源操作數和結果暫存在( )中。
A.程序計數器(PC) B.累加器(AC)
C.指令寄存器(IR) D.地址寄存器(AR)
2.執行CPU指令時,在一個指令周期的過程中,首先需從內存讀取要執行的指令
,此時先要將指令的地址即()的內容送到地址總線上。
A.指令寄存器(IR) B.通用寄存器(GR)
C.程序計數器(PC) D.狀態寄存器(PSW)
2.校驗碼
- 碼距:在兩個編碼中,從A變成B所需要改變的位數我們統稱為碼距(如:A:00=》B:01,需要改變1位,則A到B的碼距為1)
- 奇偶校驗碼:在編碼中增加以為驗證位來使編碼中1的個數為奇數(奇校驗)或偶數(偶校驗),從而使得碼距變為二
- CRC:CRC只能糾錯不能矯正,CRC編碼需要先約定一個G(x),生成多項式的最高位和最低位必須是1。假設原始信息有m位,則對應多項式M(x)。生成校驗碼思想就是在原始信息位后追加若干校驗位,使得追加的信息能被Gx整除。接收方接收到帶校驗位的信息,然后用G(x)整除。余數為0,則沒有錯誤;反之則發生錯誤。
- 假設原始數據:1100,多項式為x^3+x+1
- 左移:當前多項式的最高階位(既:1100000為被除數)
- 生成的多項式:根據當前階位得出除數:1011
- 兩者開模相除得到結果:010 --和原始數據相拼得出CRC編碼為:1100010
1.循環冗余校驗碼(Cyclic Redundancy Check ,CRC)是數據通信領域中最
常用的一種差錯校驗碼,該校驗方法中,使用多項式除法(模2除法)運算后的
余數為校驗字段。若數據信息為n位,則將其左移k位后,被長度為k+1位的生成
多項式相除,所得的k位余數即構成k個校驗位,構成n+k位編碼。若數據信息為
1100,生成多項式為X3+X+1(即1011),則CRC編碼是()。
A.1100010 B.1011010
C.1100011 D.1011110
3.指令系統
- 計算機指令由操作碼和操作數組成
- 操作碼:決定要完成的操作
- 操作數:參與運算的數據及其所在的單元位置
- 計算機指令執行步驟:取指令-分析指令-執行指令
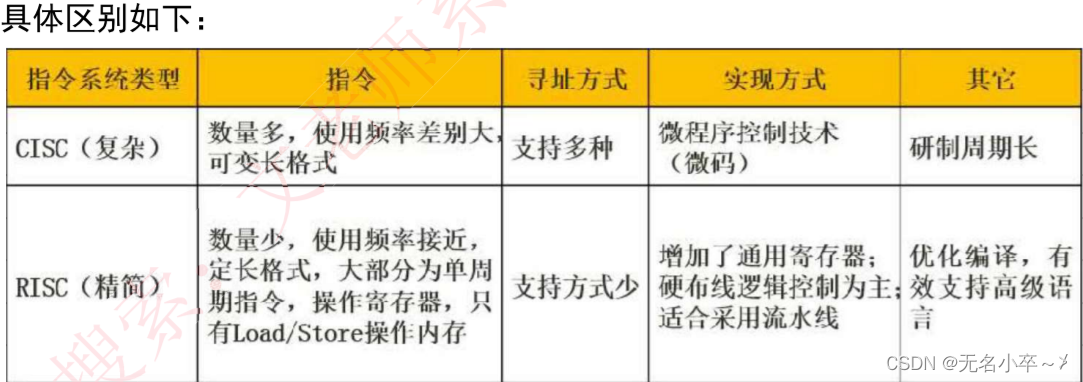
- CISC是復雜指令系統,兼容強,指令繁多,長度可變,由微程序控制
- RISC是精簡指令系統,指令少,使用頻率接近,主要由硬件實現(通用寄存器和布線邏輯控制)
- 指令流水線原理:將指令分成不同段,每段由不同部分處理,因此可以產生疊加效果,所有的部件都可以執行指令的不同段
- RISC的流水線技術
- 超流水線(Super Pipe Line)技術:實質是以空間換取時間
- 超標量(Super Salar)技術:實質是以時間換取空間
- 超長指令字(Very Long Instruction Word ,VLIW)技術
- 流水線時間計算
- 流水線周期:指令分成不同段,執行時間最長的段位流水線時間周期
- 流水線執行時間:1條指令的總時長+(總指令條數-1)*流水線周期
- 流水線吞吐率的計算:總指令條數/流水線執行時間
- 流水線的加速比計算:不使用流水線的時間/使用流水線的時間
1.
流水線的吞吐率是指流水線在單位時間里所完成的任務數或輸出的結果數。設某
流水線有5段,有1段的時間為2ns,另外4段的每段時間為1ns,利用此流水線
完成100個任務的吞吐率約為()個/s 。
A.500×10^6
B.490×10^6
C.250×10^6
D.167×10^6
在此題中:
流水線周期:2ns
流水線執行時間:2+4+2*(100-1)=204 ns=2.04 * 10^-7 s^
吞吐率:100/2.04*10-7 = 4.90 * 106
2.
流水線技術是通過并行硬件來提高系統性能的常用方法對.于一個k段流水線,假
設其各段的執行時間均相等(設為t),輸入到流水線中的任務是連續的理想情況
下,完成n個連續任務需要的總時間為( )。若某流水線浮點加法運算器分為5段
,所需要的時間分別是6ns、7ns、8ns、9ns和6ns,則其最大加速比為( ) 。
A.nkt B.(k+n-1)t C.(n-k)kt D.(k+n+1)t
A.4 B.5 C.6 D.7
不使用流水線的執行時間:(6+7+8+9+6)n=36n
使用流水線的執行時間:39+(n-1)*9 = 9n+27
最大加速比:36n/9n-27=4
假設磁盤塊與緩沖區大小相同,每個盤塊讀入緩沖區的時間為15us,由緩沖區
送至用戶區的時間是5us,在用戶區內系統對每塊數據的處理時間為1us,若用
戶需要將大小為10個磁盤塊的Docl文件逐塊從磁盤讀入緩沖區,并送至用戶區
進行處理,那么采用單緩沖區需要花費的時間為()us;采用雙緩沖區需要花費
的時間為()us。
A.150 B.151 C.156 D.201
A.150 B.151 C.156 D.2014.儲存系統
- 計算機采用分級存儲體系的目的:解決存儲容量,成本和速度之間的矛盾問題
- 兩級存儲:Cache-主存,主存-輔存(虛擬存儲體系)
- 局限性原理:
- 時間局部性原理:相鄰的時間里會訪問同一個數據項
- 空間局部性原理:相鄰的空間里會被連續訪問
- 高速緩存:存儲最活躍的程序和數據,和CPU直接交互,位于CPU和主存之間,速度是內存的5-10倍
- Cache
- 地址映射:將主存地址轉換為Cache存儲地址,這種地址的轉換叫地址映射。重點:Cache里的地址映射是由硬件自動完成的。完成轉換有下面三種方法:
- 直接映像:地址變換簡單,但是不靈活
- 全相聯映像:地址變換復雜,速度較慢,是最不容易發生沖突的方式
- 組組相聯映像:是直接映射和全相聯映像的結合
- Cache的替換算法:
- 隨機替換算法
- 先進先出算法
- 近期最少使用算法
- 優化替換算法
- 命中率及平均時間:
- 平均時間的計算:90%的命中率,Cache時間為1ns,主存為1000ns,則:(90%*1+10%*1000)ns
1.
按照Cache地址映像的塊沖突概率,從高到低排列的是( )。
A.全相聯映像→直接映像→組相聯映像
B.直接映像→組相聯映像→全相聯映像
C.組相聯映像→全相聯映像→直接映像
D.直接映像→全相聯映像→組相聯映像- 磁盤的結構:正反兩個盤面,每個盤面有多個同心圓,每個同心圓有分為幾個扇面,數據就存儲在每個扇面中
- 磁盤讀取數據的時間:尋道時間+旋轉時間
2.
假設某磁盤的每個磁道劃分成11個物理塊,每塊存放1個邏輯記錄。邏輯記錄RO
,R1,. . . ,R9,R10存放在同一個磁道上,記錄的存放順序如下表所示
如果磁盤的旋轉周期為33ms,磁頭當前處在RO的開始處。若系統使用單緩沖區
順序處理這些記錄,每個記錄處理時間為3ms,則處理這11個記錄的最長時間為
()﹔若對信息存儲進行優化分布后,處理11個記錄的最少時間為( ) 。
A.33ms B.336ms C.366ms D.376ms
A.33ms B.66ms C.86ms D.93ms

3.
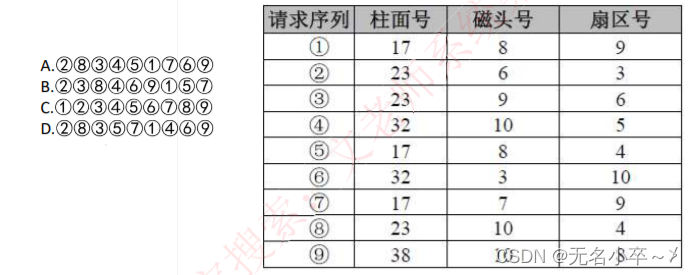
在磁盤調度管理中,應先進行移臂調度,再進行旋轉調度。假設磁盤移動臂位于21號柱面上,進程的請求序列
如下表所示。如果采用最短移臂調度算法,那么系統的響應序列應為()。
5.輸入輸出技術
-
內存和接口地址的編址方式:
- 獨立編址:內存地址和接口地址完全獨立
- 缺點:功能弱,用于接口指令少
- 統一編址:內存地址和接口地址統一在一個公共的地址空間內
- 優點:全部內存地址可以用于接口,
- 缺點:會將內存地址切分為兩個部分,會導致內存地址不連續
- 獨立編址:內存地址和接口地址完全獨立
-
計算機和外設之間的交互方式
- 程序控制(查詢)方式:CPU主動查詢外設是否完成數據傳輸,效率極其低下
- 程序中斷方式:外設完成數據傳輸后,向CPU發送中斷,效率相對較高
- DMA方式(直接主存存取):CPU只需要完成必要的初始化等操作,數據傳輸的整個過程由DMA控制器來完成,在主存和外設之間建立直接的數據通路,效率很高
-
在一個總線周期結束后,CPU會響應DMA請求開始讀取數據;CPU響應中斷請求是在一個指令執行結束時
6.總線
- 總線:是計算機設備和設備之間傳輸數據的公共數據通道
- 內部總線
- 系統總線:扳級總線,具體可分為下面三個
- 數據總線
- 控制總線
- 地址總線
- 外部總線

1-----1.B 2.C
2-----1A
3-----1.B 2.BA 3.DC
4-----1.B 2.CB 3.D
5-----1.D 2.C


—測試模型)



![【Linux】-Tomcat安裝部署[12]](http://pic.xiahunao.cn/【Linux】-Tomcat安裝部署[12])












