順序一致性(Sequential Consistency)
ZooKeeper
一種說法是ZooKeeper是最終一致性,因為由于多副本、以及保證大多數成功的ZAB協議,當一個客戶端進程寫入一個新值,另外一個客戶端進程不能保證馬上就能讀到這個值,但是能保證最終能讀取到這個值。另外一種說法是ZooKeeper的ZAB協議類似于Paxos,提供了強一致性。但這兩種說法都不準確,ZooKeeper文檔中明確寫明它的一致性是Sequential Consitency即順序一致。ZooKeeper中針對同一個FollowerA提交的寫請求request1、request2,某些Follower雖然可能不能在提交成功后立即看到(也就是強一致性),但經過自身與Leader之間的同步后,這些Follower在看到這連個請求時,一定是先看到request1,request2,兩個請求之間不會亂序,即順序一致性。
其實,實現ZooKeeper的一致性更復雜一些,ZooKeeper的讀操作是sequential consistency的,ZooKeeper的寫操作是linearizability的,關于這個說法,ZooKeeper的官方文檔中沒有寫出來,但是在社區的郵件組有詳細的討論。ZooKeeper的論文《Modular Composition of Coordination Services》中也有提到這個觀點。
總結一下,可以這么理解ZooKeeper:從整體(read操作 + write操作)上來說是sequential consistency,寫操作實現了Linearizability
線性一致性(Linearizability)
線性一致性又被稱為強一致性、嚴格一致性、原子一致性。是程序能實現的最高的一致性模型,也是分布式系統用戶最期望的一致性。CAP中的C一般就指它。順序一致性中進程只關心大家認同的順序一樣就行,不需要與全局時鐘一致,線性就更嚴格,從這種偏序(partial order)要達到全序(total order)要求是:
- 1.任何一次讀都能讀到某個數據的最近一次寫的數據
- 2.系統中的所有進程,看到的操作順序,都與全局時鐘下的順序一致。
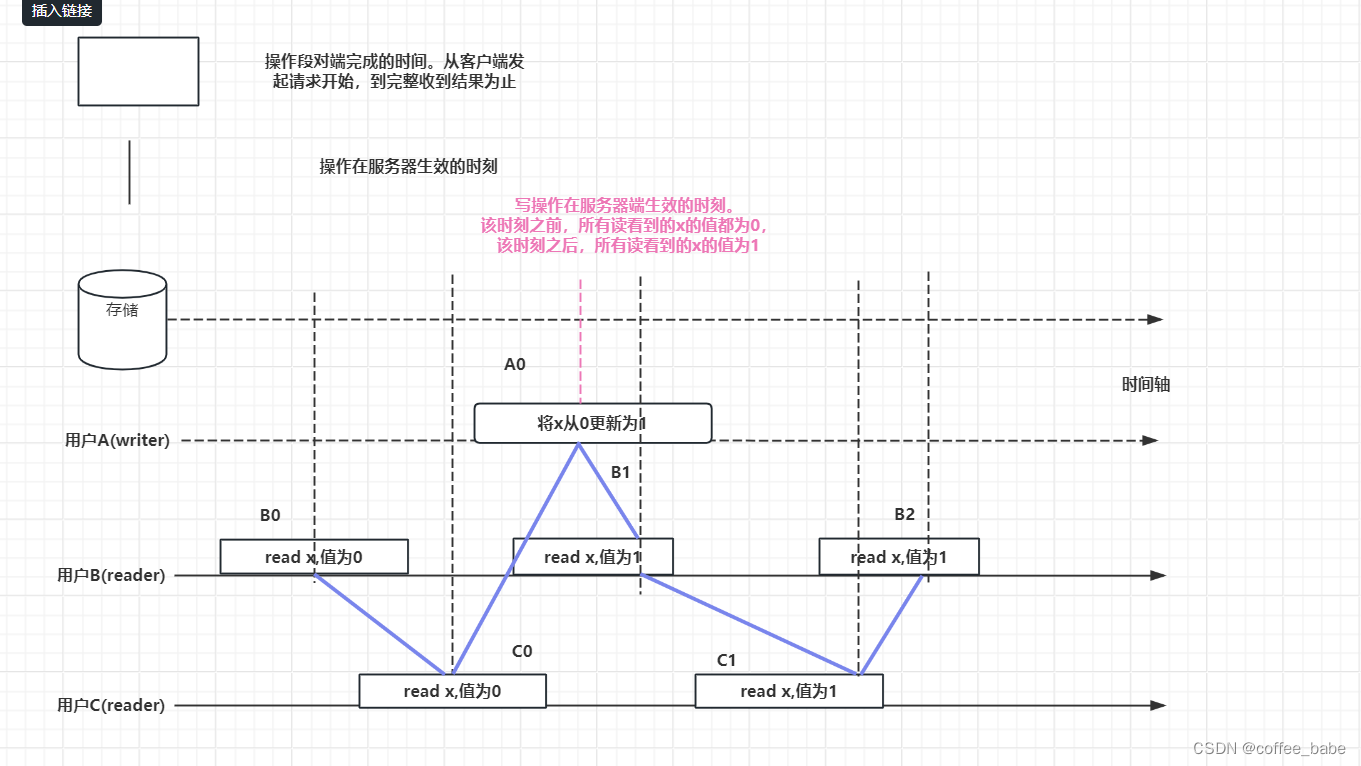
以前面講的例3繼續討論:
B1看到X的新值,C1反而看到的是舊值,即對用戶來說,x的值發生了回跳
在線性一致的系統中,如果B1看到的x值為1,則C1看到的值也一定為1。任何操作在該系統生效的時刻都對應時間軸上的一個點。如果我們把這些時刻連接起來,如圖中紫線所示,則這條線會一致沿時間軸向前,不會反向回跳。所以任何操作都需要互相比較決定,誰發生在前,誰發生在后。例如B1發生在A0之前,C1發生在A0之后,而在前面順序一致性模型中,我們無法比較諸如B1和A0的先后關系。線性一致性的理論在軟件上有哪些體現呢?
etcd與raft
上面提到ZooKeeper的寫是線性一致性,讀是順序一致性。而etecd讀寫都做了線性一致,即etcd是標準的強一致性保證。
etcd是基于raft來實現的,raft是共識算法,雖然共識和一致性的關系很微妙,經常一起討論,但共識算法只是提供基礎,要實現線性一致還需要在算法之上做出更多的努力如庫封裝,代碼實現等。如Raft中對于一致性讀給出了兩種方案,來保證處理這次讀請求的一定是Leader:
- 1.ReadIndex
- 2.LeaseRead
基于Raft的軟件有很多,如etcd、tidb、SOFAJRaft等,這些軟件在實現一致讀時都是基于這兩種方式。這里對ReadIndex和Lease Read做下解釋,即etcd中線性一致性讀的具體實現。由于在Raft算法中,寫操作成功僅僅意味著日志達成了一致(已經落盤),而并不能確保當前狀態機也已經apply了日志。狀態機apply日志的行為在大多數Raft算法的實現中都是異步的,所以此時讀取狀態機并不能準確反映數據的狀態,很可能會讀到過期數據。
基于以上這個原因,要想實現線性一致性讀,一個交為簡單通用的策略就是:每次讀操作的時候記錄此時集群的committed index,當狀態機的apply index大于或等于committed index時才讀取數據并返回。由于此時狀態機已經把度請求發起時的已提交日志進行了apply動作,所以此時狀態機的狀態就可以響應度請求發起時的狀態,符合線性一致性讀的要求。這便是ReadIndex算法。
那如何準確獲取集群的committed index?如果獲取到的committed index不準確,那么以不準確的committed index為基準的ReadIndex算法講可能拿到過期數據。為了確保committed index的準確,我們需要: - 1.讓leader來處理讀請求
- 2.如果follower收到讀請求,將請求forward給leader
- 3.確保當前leader仍然是leader
leader會發起一次廣播請求,如果還能收到大多數節點的應答,則說明此時leader還是leader.這點非常關鍵,如果沒有這個環節,leader有可能因網絡分區等原因已不再是leader,度請求依然由過期的leader處理,那么久將有可能讀到過去的數。這樣,我們從leader獲取的committed index久作為此次讀請求的ReadIndex.
以網絡分區為例:
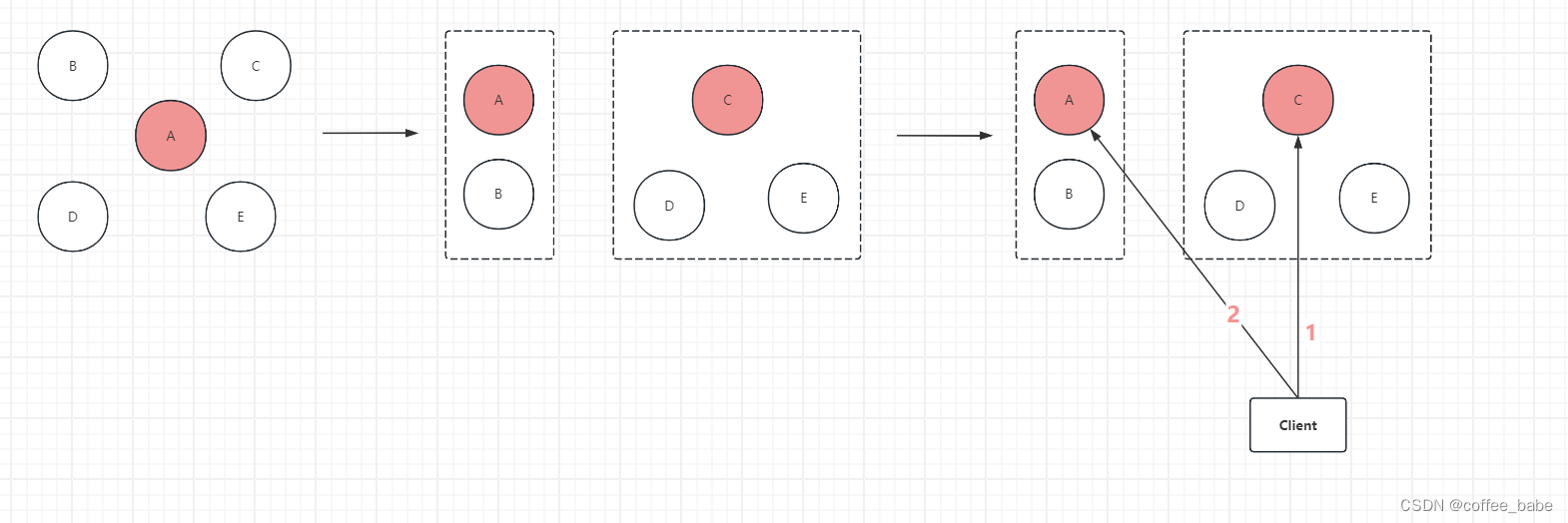
- 1.初始狀態時集群有5個節點:A、B、C、D和E,其中A是leader;
- 2.發生網絡隔離,集群被分割成兩部分,一個A和B,另外一個是C、D、E。雖然A會持續向其他介個節點發送headerbeat,但由于網絡隔離,C、D、E將無法接收到A的heartbeat。默認地,A不處理向follower節點發送heartbeat失敗(此處為網絡超時)的情況(協議沒有明確說明heartbeat是一個必須收到follower ack的雙向過程);
- 3.C、D、E組成的分區在經過一定時間沒有收到leader的heartbeat后,觸發election timeout,此時C成為leader.此時,原來5節點集群因網絡分區分割成兩個集群:小集群A和B;大集群C、D、E,C為leader
- 4.此時客戶端進行讀寫操作。在Raft算法中,客戶端無法感知集群的leader變化(更無法感知服務端有網絡隔離的事件發生)。客戶端在向集群發起讀寫請求時。如果客戶端一開始選擇C節點,并成功寫入數據(C節點集群已經commit操作日志),然后因客戶端某些原因(比如斷線重連),選擇節點A進行讀操作。由于A并不知道另外3個節點已經組成當前集群的大多數并寫入了新的數據,所以節點A無法返回準確的數據。此時客戶端將讀到過期數據。不過相應地,如果此時客戶端向節點A發起寫操作,那么寫操作將失敗,因為A因網絡隔離無法收到大多數節點的寫入響應
- 5.針對上述情況,其實節點C、D、E組成的新集群才是當前5節點集群中大多數,讀寫操作應該發生在這個集群中而不是原來的小集群(節點A和B).如果此時節點A能感知它已經不再是集群的leader,那么節點A將不再處理讀寫請求。于是,我們可以在leader處理讀寫請求時,發起一次check quorum環節:
leader向集群的所有節點發起廣播。當leader還能收到集群大多數節點的響應,說明leader還是當前集群的有效leader,擁有當前集群完整的數據,否則,讀請求失敗,將迫使客戶端崇訓選擇新節點進行讀寫
這樣一來,Raft算法久可以保障CAP中的C和P,但無法保障A:網絡分區時并不是所有節點都可以響應請求,少數節點的分區將無法進行服務,從而不符合Availablility。因此,Raft算法是CP類型的一致性算法


 . name () 與 typeid() . raw_name () 測試數據類型的區別)




)







)

)

