3.物理分區
Flink 提供以下方法讓用戶根據需要在數據轉換完成后對數據分區進行更細粒度的配置。
a)自定義分區
DataStream → DataStream
使用自定義的 Partitioner 為每個元素選擇目標任務。
dataStream.partitionCustom(partitioner, "someKey");
dataStream.partitionCustom(partitioner, 0);
b)隨機分區
DataStream → DataStream
將元素隨機地均勻劃分到分區。
dataStream.shuffle();
c)Rescaling
DataStream → DataStream
將元素以 Round-robin 輪詢的方式分發到下游算子。
如果想將數據源的多個并發實例的數據分發到多個下游 map 來實現負載分配,但又不想像 rebalance() 那樣引起完全重新平衡,該算子將只會到本地數據傳輸而不是網絡數據傳輸,這取決于其它配置值,例如 TaskManager 的 slot 數量。
上游算子將元素發往哪些下游的算子實例集合同時取決于上游和下游算子的并行度;例如,如果上游算子并行度為 2,下游算子的并發度為 6, 那么上游算子的其中一個并行實例將數據分發到下游算子的三個并行實例, 另外一個上游算子的并行實例則將數據分發到下游算子的另外三個并行實例中。再如,當下游算子的并行度為2,而上游算子的并行度為 6 的時候,那么上游算子中的三個并行實例將會分發數據至下游算子的其中一個并行實例,而另外三個上游算子的并行實例則將數據分發至另下游算子的另外一個并行實例。
當算子的并行度不是彼此的倍數時,一個或多個下游算子將從上游算子獲取到不同數量的輸入。
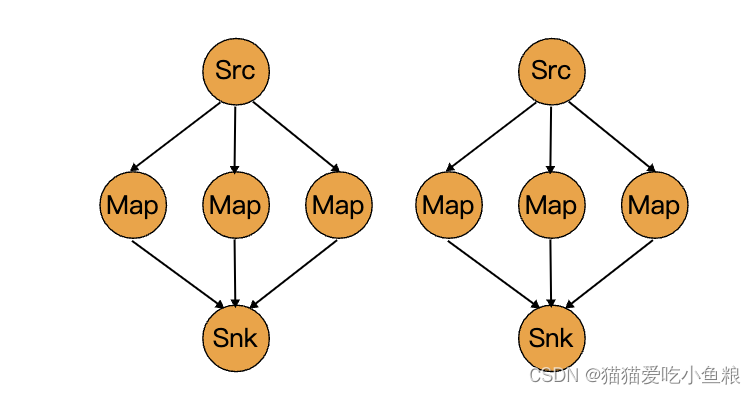
dataStream.rescale();
d)廣播
DataStream → DataStream
將元素廣播到每個分區 。
dataStream.broadcast();



)





)







及其用例)

