本文給大家帶來的百面算法工程師是深度學習目標檢測YOLOv6面試總結,文章內總結了常見的提問問題,旨在為廣大學子模擬出更貼合實際的面試問答場景。在這篇文章中,我們還將介紹一些常見的深度學習目標檢測面試問題,并提供參考的回答及其理論基礎,以幫助求職者更好地準備面試。通過對這些問題的理解和回答,求職者可以展現出自己的深度學習目標檢測領域的專業知識、解決問題的能力以及對實際應用場景的理解。同時,這也是為了幫助求職者更好地應對深度學習目標檢測崗位的面試挑戰,提升面試的成功率和競爭力。
專欄地址:百面算法工程師——總結最新各種計算機視覺的相關算法面試問題
YOLOv6論文地址 :點擊即可跳轉
YOLOv6 官方開源庫地址: 官方代碼倉庫點擊即可跳轉
目錄
1. 數據增強模塊
2. 網絡結構
2.1 Backbone
?2.2 Neck
2.3 Head
3. 正負樣本匹配策略
3.1 Anchor 設置
3.2 Bbox 編解碼過程
3.3 匹配策略
4. Loss 設計
4.1 分類損失函數 VarifocalLoss
4.2 回歸損失函數 GIoU Loss / SIoU Los
?文章中部分內容已在YOLOv5中講過,此處不再贅述,感興趣的同學可以閱讀
百面算法工程師 | YOLOv5面試考點原理全解析_yolov5面試詳解-CSDN博客
 ?
?
YOLOv6 提出了一系列適用于各種工業場景的模型,包括 N/T/S/M/L,考慮到模型的大小,其架構有所不同,以獲得更好的精度-速度權衡。本算法專注于檢測的精度和推理效率,并在網絡結構、訓練策略等算法層面進行了多項改進和優化。
簡單來說 YOLOv6 開源庫的主要特點為:
- 統一設計了更高效的 Backbone 和 Neck:受到硬件感知神經網絡設計思想的啟發,基于 RepVGG style 設計了可重參數化、更高效的骨干網絡 EfficientRep Backbone 和 Rep-PAN Neck。
- 相比于 YOLOX 的 Decoupled Head,進一步優化設計了簡潔有效的 Efficient Decoupled Head,在維持精度的同時,降低了一般解耦頭帶來的額外延時開銷。
- 在訓練策略上,采用 Anchor-free 的策略,同時輔以 SimOTA 標簽分配策略以及 SIoU 邊界框回歸損失來進一步提高檢測精度。
YOLOv6 和 YOLOv5 一樣也可以分成數據增強、模型結構、loss 計算等組件,如下所示:
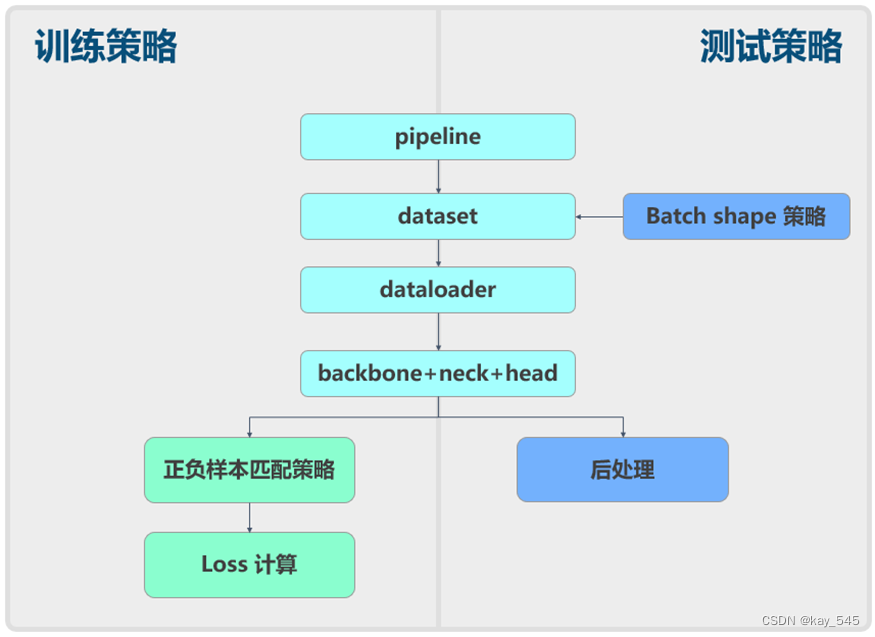
1. 數據增強模塊
YOLOv6 目標檢測算法中使用的數據增強與 YOLOv5 基本一致,唯獨不一樣的是沒有使用 Albu 的數據增強方式:
- Mosaic 馬賽克
- RandomAffine 隨機仿射變換
- MixUp
圖像模糊等采用 Albu庫實現的變換- HSV 顏色空間增強
- 隨機水平翻轉
關于每一個增強的詳細解釋,詳情請看YOLOv5 數據增強模塊
百面算法工程師 | YOLOv5面試考點原理全解析_yolov5面試詳解-CSDN博客
另外,YOLOv6 參考了 YOLOX 的數據增強方式,分為 2 種增強方法組,一開始和 YOLOv5 一致,但是在最后 15 個 epoch 的時候將 Mosaic 使用 YOLOv5KeepRatioResize + LetterResize 替代了,個人感覺是為了擬合真實情況。
2. 網絡結構
YOLOv6 N/T/S 模型的網絡結構由 EfficientRep + Rep-PAN + Efficient decoupled Head 構成,M/L 模型的網絡結構則由 CSPBep + CSPRepPAFPN + Efficient decoupled Head 構成。其中,Backbone 和 Neck 部分的結構與 YOLOv5 較為相似,但不同的是其采用了重參數化結構 RepVGG Block 替換掉了原本的 ConvModule,在此基礎上,將 CSPLayer 改進為了多個 RepVGG 堆疊的 RepStageBlock(N/T/S 模型)或 BepC3StageBlock(M/L 模型);Head 部分則參考了 FCOS 和 YOLOX 的檢測頭,將回歸與分類分支解耦成兩個分支進行預測。
2.1 Backbone
已有研究表明,多分支的網絡結構通常比單分支網絡性能更加優異,例如 YOLOv5 的 CSPDarknet,但是這種結構會導致并行度降低進而增加推理延時;相反,類似于 VGG 的單分支網絡則具有并行度高、內存占用小的優點,因此推理效率更高。而 RepVGG 則同時具備上述兩種結構的優點,在訓練時可解耦成多分支拓撲結構提升模型精度,實際部署時可等效融合為單個 3×3 卷積提升推理速度,RepVGG 示意圖如下。因此,YOLOv6 基于 RepVGG 重參數化結構設計了高效的骨干網絡 EfficientRep 和 CSPBep,其可以充分利用硬件算力,提升模型表征能力的同時降低推理延時。
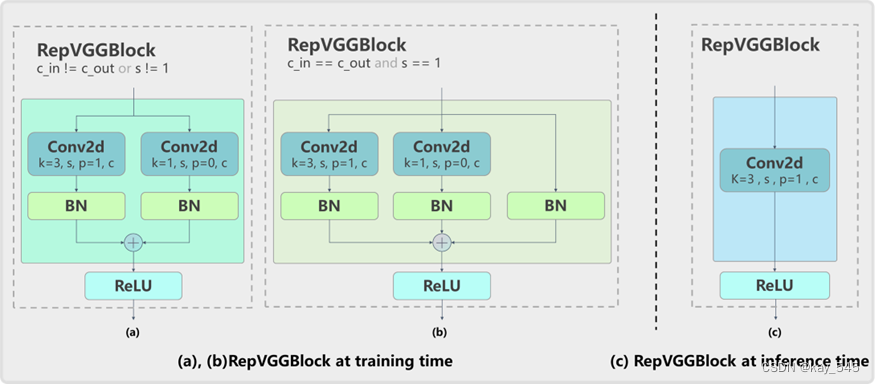
?在 N/T/S 模型中,YOLOv6 使用了 EfficientRep 作為骨干網絡,其包含 1 個 Stem Layer 和 4 個 Stage Layer,具體細節如下:
- Stem Layer 中采用 stride=2 的 RepVGGBlock 替換了 stride=2 的 6×6 ConvModule。
- Stage Layer 結構與 YOLOv5 基本相似,將每個 Stage layer 的 1 個 ConvModule 和 1 個 CSPLayer 分別替換為 1 個 RepVGGBlock 和 1 個 RepStageBlock,如上圖 Details 部分所示。其中,第一個 RepVGGBlock 會做下采樣和 Channel 維度變換,而每個 RepStageBlock 則由 n 個 RepVGGBlock 組成。此外,仍然在第 4 個 Stage Layer 最后增加 SPPF 模塊后輸出。
在 M/L 模型中,由于模型容量進一步增大,直接使用多個 RepVGGBlock 堆疊的 RepStageBlock 結構計算量和參數量呈現指數增長。因此,為了權衡計算負擔和模型精度,在 M/L 模型中使用了 CSPBep 骨干網絡,其采用 BepC3StageBlock 替換了小模型中的 RepStageBlock 。如下圖所示,BepC3StageBlock 由 3 個 1×1 的 ConvModule 和多個子塊(每個子塊由兩個 RepVGGBlock 殘差連接)組成。
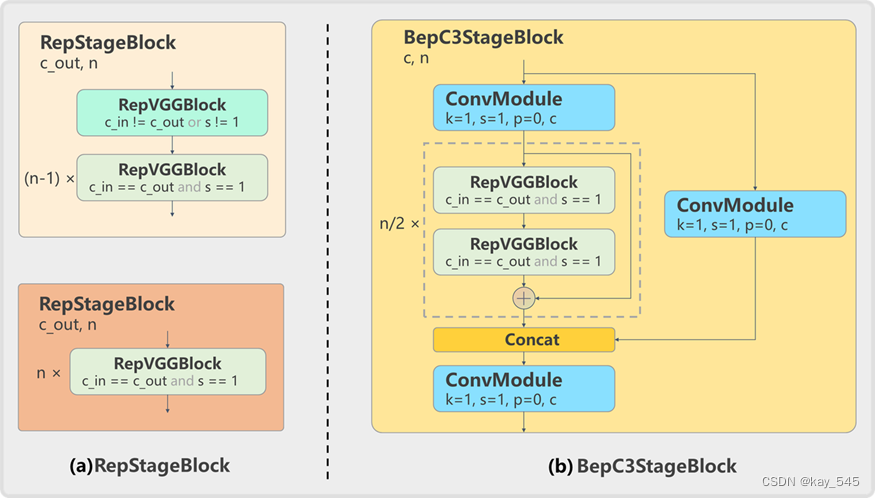
?2.2 Neck
Neck 部分結構仍然在 YOLOv5 基礎上進行了模塊的改動,同樣采用 RepStageBlock 或 BepC3StageBlock 對原本的 CSPLayer 進行了替換,需要注意的是,Neck 中 Down Sample 部分仍然使用了 stride=2 的 3×3 ConvModule,而不是像 Backbone 一樣替換為 RepVGGBlock。
2.3 Head
不同于傳統的 YOLO 系列檢測頭,YOLOv6 參考了 FCOS 和 YOLOX 中的做法,將分類和回歸分支解耦成兩個分支進行預測并且去掉了 obj 分支。同時,采用了 hybrid-channel 策略構建了更高效的解耦檢測頭,將中間 3×3 的 ConvModule 減少為 1 個,在維持精度的同時進一步減少了模型耗費,降低了推理延時。此外,需要說明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函數是 ReLU,而在 Head 部分則使用的是 SiLU。
由于 YOLOv6 是解耦輸出,分類和 bbox 檢測通過不同卷積完成。以 COCO 80 類為例:
- P5 模型在輸入為 640x640 分辨率情況下,其 Head 模塊輸出的 shape 分別為 (B,4,80,80), (B,80,80,80), (B,4,40,40), (B,80,40,40), (B,4,20,20), (B,80,20,20)。
3. 正負樣本匹配策略
YOLOv6 采用的標簽匹配策略與 TOOD相同, 前 4 個 epoch 采用 ATSSAssigner 作為標簽匹配策略的 warm-up , 后續使用 TaskAlignedAssigner 算法選擇正負樣本。
3.1 Anchor 設置
YOLOv6 采用與 YOLOX 一樣的 Anchor-free 無錨范式,省略了聚類和繁瑣的 Anchor 超參設定,泛化能力強,解碼邏輯簡單。在訓練的過程中會根據 feature size 去自動生成先驗框。
3.2 Bbox 編解碼過程
YOLOv6 的 BBox Coder 采用的是 DistancePointBBoxCoder。
網絡 bbox 預測的值為 (top, bottom, left, right),解碼器將 anchor point 通過四個距離解碼到坐標 (x1,y1,x2,y2)。
3.3 匹配策略
- 0 <= epoch < 4,使用 BatchATSSAssigner
- epoch >= 4,使用 BatchTaskAlignedAssigner
ATSSAssigner
ATSSAssigner 是 ATSS 中提出的標簽匹配策略。 ATSS 的匹配策略簡單總結為:通過中心點距離先驗對樣本進行初篩,然后自適應生成 IoU 閾值篩選正樣本。 YOLOv6 的實現種主要包括如下三個核心步驟:
- 因為 YOLOv6 是 Anchor-free,所以首先將 anchor point 轉化為大小為 5*strdie 的 anchor。
- 對于每一個 GT,在 FPN 的每一個特征層上, 計算與該層所有 anchor 中心點距離(位置先驗), 然后優先選取距離 topK 近的樣本,作為 初篩樣本。
- 對于每一個 GT,計算其 初篩樣本 的 IoU 的均值 mean與標準差 std,將 mean + std 作為該 GT 的正樣本的 自適應 IoU 閾值 ,大于該 自適應閾值 且中心點在 GT 內部的 anchor 才作為正樣本,使得樣本能夠被 assign 到合適的 FPN 特征層上。
下圖中,(a) 所示中等大小物體被 assign 到 FPN 的中層,(b) 所示偏大的物體被 assign 到 FPN 中檢測大物體和偏大物體的兩個層。
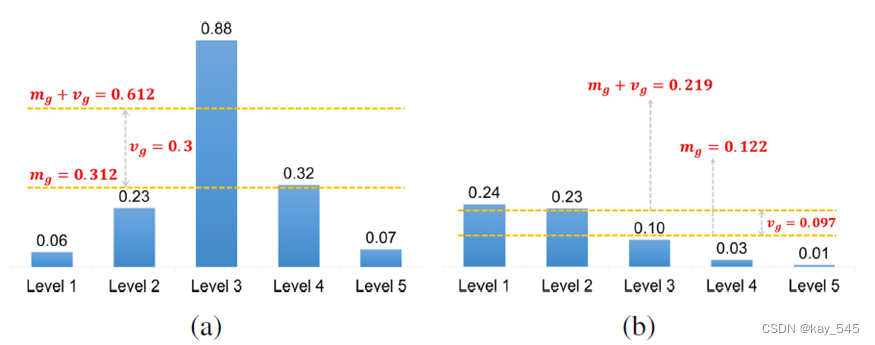
TaskAlignedAssigner
TaskAlignedAssigner 是 TOOD中提出的一種動態樣本匹配策略。 由于 ATSSAssigner 是屬于靜態標簽匹配策略,其選取正樣本的策略主要根據 anchor 的位置進行挑選, 并不會隨著網絡的優化而選取到更好的樣本。在目標檢測中,分類和回歸的任務最終作用于同一個目標,所以 TaskAlignedAssigner 認為樣本的選取應該更加關注到對分類以及回歸都友好的樣本點。
TaskAlignedAssigner 的匹配策略簡單總結為: 根據分類與回歸的分數加權的分數選擇正樣本。
- 對于每一個 GT,對所有的 預測框 基于 GT類別對應分類分數 與 預測框與 GT 的 IoU 的加權得到一個關聯分類以及回歸的對齊分數 alignment_metrics。
- 對于每一個 GT,直接基于 alignment_metrics 對齊分數選取 topK 大的作為正樣本。
因為在網絡初期參數隨機, 分類分數 和 預測框與 GT 的 IoU 都不準確,所以需要經過前 4 個 epoch 的 ATSSAssigner 的 warm-up。經過預熱之后的 TaskAlignedAssigner 標簽匹配策略就不使用中心距離的先驗, 而是直接對每一個GT 選取 alignment_metrics 中 topK 大的樣本作為正樣本。
4. Loss 設計
參與 Loss 計算的共有兩個值:loss_cls 和 loss_bbox,其各自使用的 Loss 方法如下:
- Classes loss:使用的是 mmdet.VarifocalLoss
- BBox loss:l/m/s使用的是 GIoULoss, t/n 用的是 SIoULoss
權重比例是:loss_cls : loss_bbox = 1 : 2.5
4.1 分類損失函數 VarifocalLoss
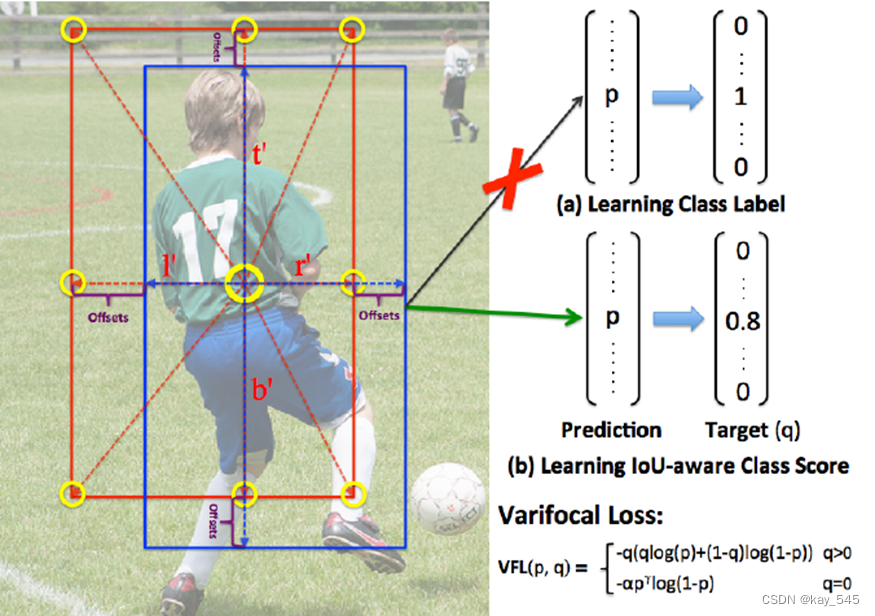
Varifocal Loss (VFL) 是 VarifocalNet: An IoU-aware Dense Object Detector中的損失函數。
 ?
?
VFL 是在 GFL 的基礎上做的改進
在上述標簽匹配策略中提到過選擇樣本應該優先考慮分類回歸都友好的樣本點, 這是由于目標檢測包含的分類與回歸兩個子任務都是作用于同一個物體。 與 GFL 思想相同,都是將 預測框與 GT 的 IoU 軟化作為分類的標簽,使得分類分數關聯回歸質量, 使其在后處理 NMS 階段有分類回歸一致性很強的分值排序策略,以達到選取優秀預測框的目的。
Varifocal Loss 原本的公式:
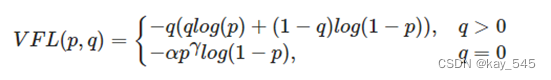
?其中 𝑞 是預測 bboxes 與 GT 的 IoU,使用軟標簽的形式作為分類的標簽。 𝑝∈[0,1] 表示分類分數。
- 對于負樣本,即當 𝑞=0 時,標準交叉熵部分為 ?log?(𝑝),負樣本權重使用 𝛼𝑝^𝛾 作為 focal weight 使樣本聚焦與困難樣本上,這與 Focal Loss 基本一致。
- 對于正樣本,即當 𝑞>0 時,首先計算標準二值交叉熵部分
但是針對正樣本的權重設置,Varifocal Loss 中并沒有采用類似 𝛼𝑝𝛾的方式降權, 而是認為在網絡的學習過程中正樣本相對于負樣本的學習信號來說更為重要,所以使用了分類的標簽 𝑞, 即 IoU 作為 focal weight, 使得聚焦到具有高質量的樣本上。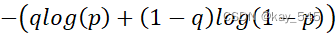
但是 YOLOv6 中的 Varifocal Loss 公式采用 TOOD 中的 Task ALignment Learning (TAL), 將預測的 IoU 根據之前標簽匹配策略中的分類對齊度 alignment_metrics 進行了歸一化, 得到歸一化 𝑡^。 具體實現方式為:
對于每一個 Gt,找到所有樣本中與 Gt 最大的 IoU,具有最大 alignment_metrics 的樣本位置的 t=max(Iou)
?
最終 YOLOv6 分類損失損失函數為:
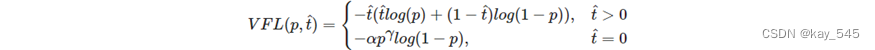 ?
?
4.2 回歸損失函數 GIoU Loss / SIoU Loss
在 YOLOv6 中,針對不同大小的模型采用了不同的回歸損失函數,其中 l/m/s使用的是 GIoULoss, t/n 用的是 SIoULoss。
其中GIoULoss 詳情請看Loss——?百面算法工程師 | 損失函數篇-CSDN博客
SIou Loss
SIoU 損失函數是 SIoU Loss: More Powerful Learning for Bounding Box Regression 中提出的度量預測框與 GT 的匹配度的指標,由于之前的GIoU, CIoU, DIoU 都沒有考慮預測框向 GT 框回歸的角度,然而角度也確實是回歸中一個重要的影響因素,因此提出了全新的SIoU。
SIoU 損失主要由四個度量方面組成:
- IoU成本
- 角度成本
- 距離成本
- 形狀成本
如下圖所示,角度成本 就是指圖中預測框 𝐵 向 𝐵𝐺𝑇 的回歸過程中, 盡可能去使得優化過程中的不確定性因素減少,比如現將圖中的角度 𝛼 或者 𝛽 變為 0 ,再去沿著 x 軸或者 y 軸去回歸邊界。
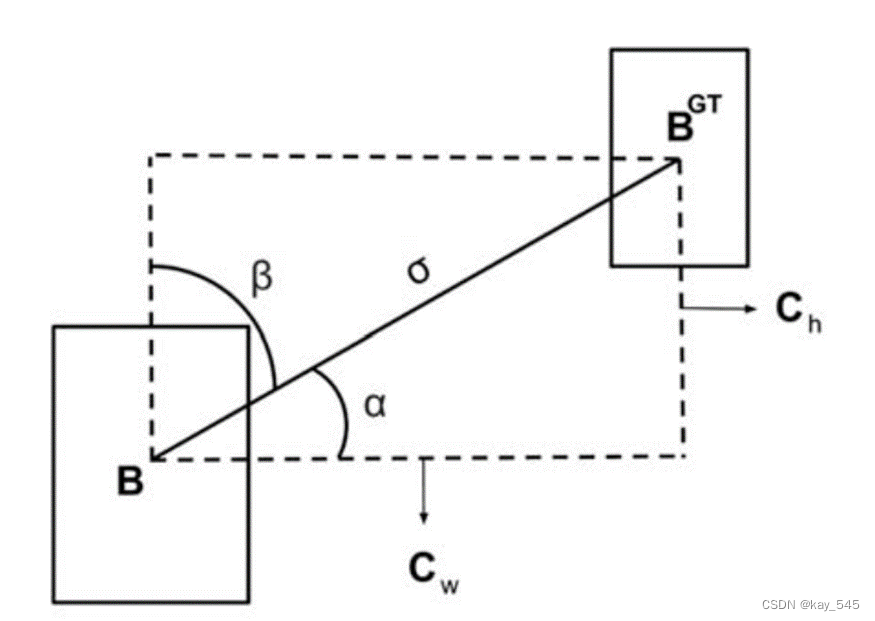
?Object Loss
在 YOLOv6 中,由于額外的置信度預測頭可能與 Aligned Head 有所沖突,經實驗驗證在不同大小的模型上也都有掉點, 所以最后選擇棄用 Objectness 分支。
1.5 優化策略和訓練過程
1.5.1 優化器分組
與 YOLOv5 一致,詳情請看 YOLOv5 優化器分組
1.5.2 weight decay 參數自適應
與 YOLOv5 一致,詳情請看 YOLOv5 weight decay 參數自適應
1.6 推理和后處理過程
YOLOv6 后處理過程和 YOLOv5 高度類似,實際上 YOLO 系列的后處理邏輯都是類似的。 詳情請看YOLOv5 推理和后處理過程
再次放上YOLOv5的面試總結,方便大家閱讀
百面算法工程師 | YOLOv5面試考點原理全解析_yolov5面試詳解-CSDN博客




及其用例)



)

)
)


)




