目錄
1.程序功能描述
2.測試軟件版本以及運行結果展示
3.部分程序
4.算法理論概述
5.完整程序
1.程序功能描述
? ? ? 紅尾鷹優化的LSTM(RTH-LSTM)算法,是將紅尾鷹優化算法(Red-Tailed Hawk Optimization, RTHO)與長短期記憶網絡(Long Short-Term Memory, LSTM)結合,針對一維時間序列預測任務提出的混合模型。其核心邏輯在于:利用RTHO算法的全局尋優能力,解決LSTM網絡訓練中易陷入局部最優、初始權重與偏置參數隨機化導致預測精度低的問題,再通過LSTM捕捉時間序列的長短期依賴關系,最終實現高精度預測。
2.測試軟件版本以及運行結果展示
MATLAB2022A/MATLAB2024B版本運行
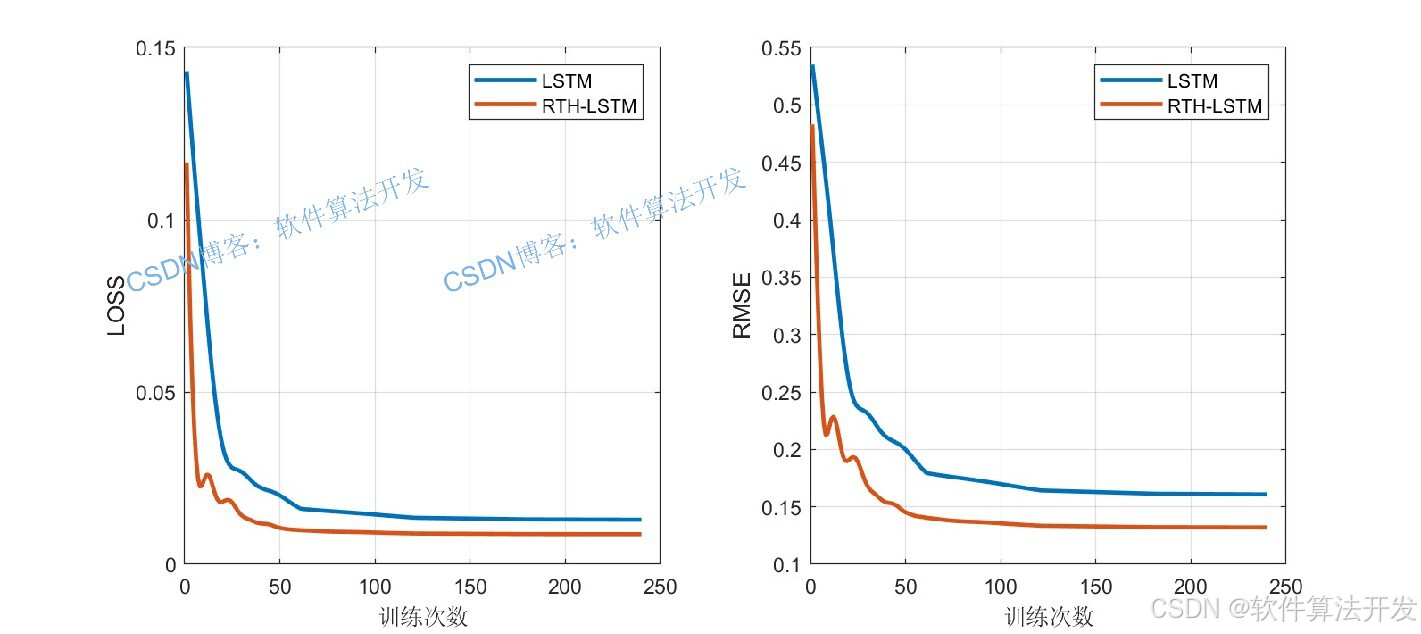
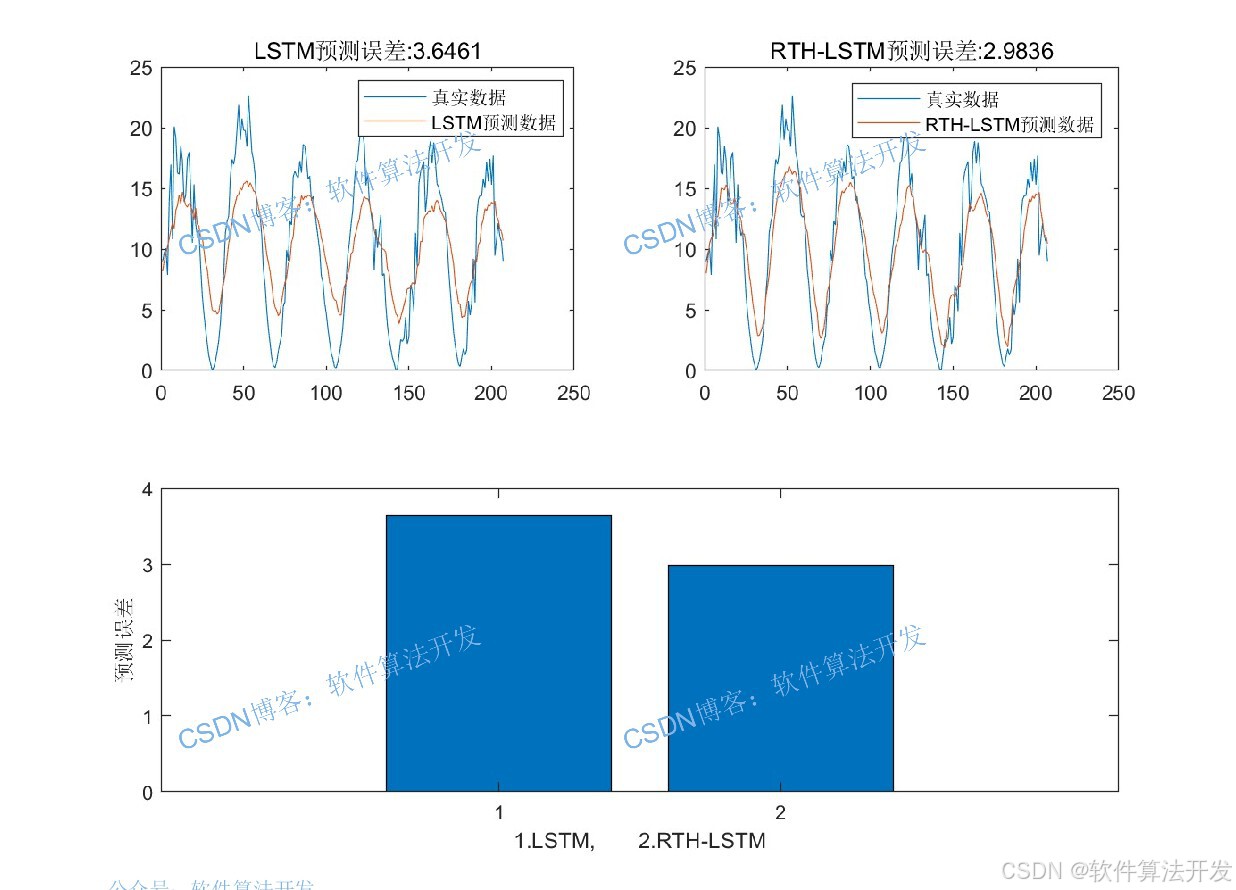
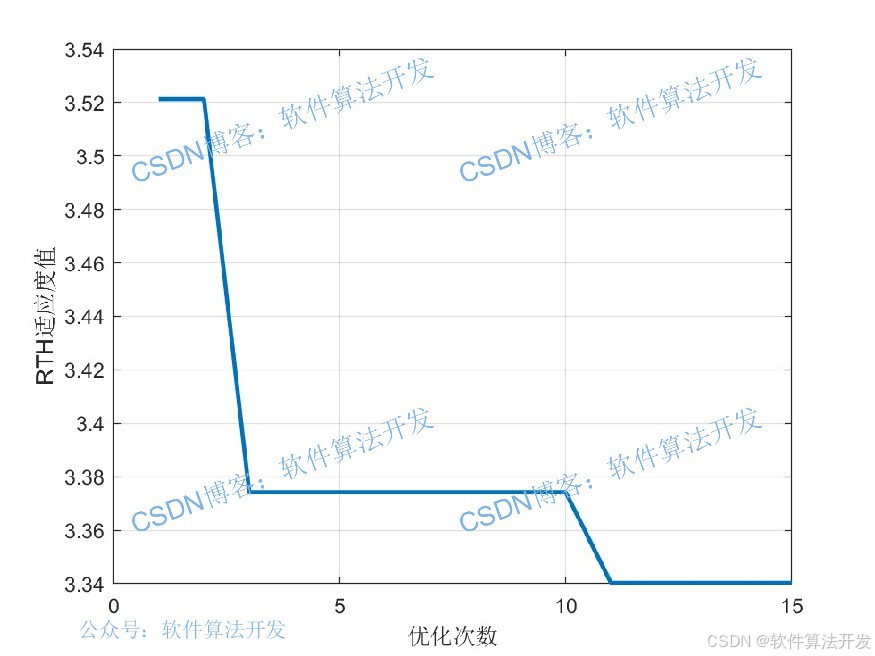
3.部分程序
% 定義全局變量,用于存儲訓練和測試數據及相關參數
global T_train; % 訓練目標數據
global T_test; % 測試目標數據
global Pxtrain; % 訓練輸入數據
global Txtrain; % 訓練目標數據(歸一化后)
global Pxtest; % 測試輸入數據
global Txtest; % 測試目標數據(歸一化后)
global Norm_I; % 輸入數據歸一化參數
global Norm_O; % 輸出數據歸一化參數
global indim; % 輸入數據維度
global outdim; % 輸出數據維度% 加載數據文件data.mat
load data.mat
% 調用數據處理函數,對原始數據進行預處理
[T_train,T_test,Pxtrain,Txtrain,Pxtest,Txtest,Norm_I,Norm_O,indim,outdim]=func_process(dat);% 定義優化參數范圍
low = 5; % 搜索空間下界
high = 100; % 搜索空間上界
dim = 1; % 優化維度
Tmax = 15; % 最大迭代次數
Npop = 10; % 種群大小% 初始化最優解
Xbestcost = inf; % 初始化最優代價為無窮大
Xbestpos = rand(Npop,dim); % 初始化最優位置% 將優化得到的最佳參數轉換為整數,作為LSTM隱藏層神經元數量
NN=floor(Xnewpos)+1;
% 定義LSTM神經網絡結構
layers = [ ...]; % 回歸層,用于回歸任務% 訓練LSTM網絡
[net,INFO] = trainNetwork(Pxtrain, Txtrain, layers, options);% 使用訓練好的網絡進行預測
Dat_yc1 = predict(net, Pxtrain); % 對訓練數據進行預測
Dat_yc2 = predict(net, Pxtest); % 對測試數據進行預測% 將預測結果反歸一化,恢復原始數據范圍
Datn_yc1 = mapminmax('reverse', Dat_yc1, Norm_O);
Datn_yc2 = mapminmax('reverse', Dat_yc2, Norm_O); % 將細胞數組轉換為矩陣
Datn_yc1 = cell2mat(Datn_yc1);
Datn_yc2 = cell2mat(Datn_yc2);% 保存訓練信息、預測結果和收斂曲線
save R2.mat INFO Datn_yc1 Datn_yc2 T_train T_test Convergence_curve
X14.算法理論概述
? ? ? LSTM通過 “門控機制” 解決傳統循環神經網絡(RNN)的梯度消失 / 爆炸問題,其核心結構包括輸入門(Input Gate)、遺忘門(Forget Gate)、細胞狀態(Cell State)和輸出門(Output Gate)。
? ? ? 設LSTM網絡層N的取值,N∈[N_min, N_max],如 N_min=10、N_max=50)。?以LSTM在訓練集上的預測誤差作為適應度函數(目標:最小化誤差),采用均方根誤差(RMSE),公式為:
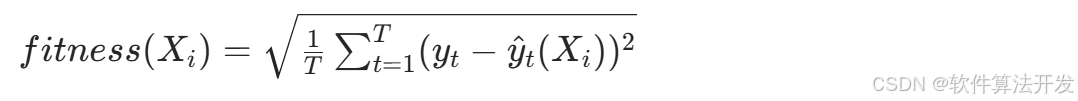
其中,T為訓練集樣本數, y t ?為t時刻真實值, y^ t ? (Xi ?) 為基于個體 Xi ?的LSTM預測值。
? ? ?RTH通過兩輪更新實現尋優,模擬紅尾鷹的搜索行為:
第一輪:盤旋搜索(全局探索) 紅尾鷹圍繞獵物區域盤旋,個體位置更新公式為:

第二輪:俯沖捕食(局部開發) 當紅尾鷹鎖定獵物后俯沖,個體位置向最優個體靠近,同時引入局部擾動:

? ? ? ?當迭代次數達到預設最大值T ,或最優個體的適應度值小于預設誤差閾值?時,停止尋優,將此時的最優個體Xbest ? 作為LSTM的初始參數。
算法核心優勢
自適應層數量選擇:避免人工調參(如憑經驗設N=20 或30)的主觀性,RTH可根據序列復雜度自動匹配最優N,平衡欠擬合與過擬合。
參數 - 結構協同優化:同步優化層數量與對應層參數,相比 “先定N再調參” 的傳統方式,大幅提升模型收斂速度與預測精度。
魯棒性強:RTH的全局尋優能力降低了初始參數隨機化對模型的影響,對含噪聲的時間序列(如工業傳感器數據)適應性更強。
5.完整程序
VVV













)

)


深度解析)
![[能源化工] 面向鋰電池RUL預測的開源項目全景速覽](http://pic.xiahunao.cn/[能源化工] 面向鋰電池RUL預測的開源項目全景速覽)