在日常的數據分析場景中,我們經常會向 Apache Doris 寫入大量數據,無論是實時導入、批量導入,還是通過流式寫入。但你是否想過:一條數據從客戶端發出,到最終穩定落盤,中間到底經歷了哪些步驟?
今天我們就來全面拆解 Doris 寫入原理,帶你走進它的內部世界。
1. 整體脈絡
一條寫入數據在 Doris 的“旅程”可以分成若干層次:
入口:客戶端通過 HTTP(Stream Load)、JDBC/SQL(INSERT)、Broker/Spark(批量)、Routine Load(Kafka)等方式把數據送入系統。各種 Load 方法的分類和用途說明鏈接。
FE 層(協調):SQL 解析、計劃、事務分配、路由與元數據管理(表/分區/Tablet 信息由 FE 管理并存儲)。
BE 層(執行):負責真實的數據寫入、內存結構、落盤(Segment)、索引構建、Compaction、查詢執行。
2. 寫入模式
選擇合適的寫入模式是發揮 Doris 性能的前提。不同模式的事務粒度、資源占用、延遲表現差異顯著,需根據業務需求精準選型。
| 寫入模式 | 傳輸協議 | 典型場景 | 延遲 | 吞吐能力 | 事務特征 |
|---|---|---|---|---|---|
| Stream Load | HTTP | 實時日志、訂單數據導入 | 秒級 | 高(GB / 分) | 單事務,支持導入任務級重試 |
| Routine Load | Kafka 協議 | Kafka 日志流持續同步 | 秒級 | 中高 | 分區級事務,支持斷點續傳 |
| Broker Load | 內部 RPC | HDFS/S3 離線批量數據加載 | 分鐘級 | 極高(TB / 時) | 單事務,支持大文件切分并行導入 |
| Spark Load | Spark API | 超大規模數據集(>10TB) | 小時級 | 極高 | 分布式事務,依賴 Spark 集群 |
| Insert Into | MySQL/JDBC | 手動補數、低并發小批量寫入 | 秒級 | 低 | 單條 / 批量事務,支持事務回滾 |
3. 寫入流程關鍵內容解析
3.1 數據接收與請求解析
流程細分:
- 客戶端通過 HTTP / MySQL 協議向 FE 或 BE 發起寫入請求。
- 如果請求到 FE:FE 做 SQL 解析(SQL parser)、語義校驗(列類型、分區存在性等)、權限校驗。
- FE 根據目標表的分區/分桶/Distribution 信息,執行 路由決策:確定目標 Tablet(或者多個 Tablet)。
- FE 為該寫入分配一個 事務 ID(Txn ID) 或者在批量場景下分配批次標識,用來跟蹤后續的各個 BE 寫入結果與可見性。
3.2 BE 的內存寫入 — MemTable
核心流程:
- BE 在接收到寫入行后,會采用了類 LSM 樹的結構,將數據先寫到 Memtable 中,當 Memtable 數據寫滿后,才會進行下一步數據寫入。
- MemTable 在邏輯上做去重/聚合/排序(取決于表類型:Duplicate/Unique/Aggregate)。如主鍵表會在內存階段做主鍵合并或覆蓋邏輯。
內部細節:
- 數據格式化:將網絡序列化數據解析為內部列式/行式表示(列式更利于壓縮與向量化)。
- 短鍵索引構建(Short key / MinMax):MemTable 會收集用于快速定位的小索引信息(比如每個塊的最小/最大值、短鍵)。
- 鎖與并發控制:寫入到同一個 Tablet 的并發寫請求需要合適的并發控制(同 Tablet 同步或分區內并發寫控制),以保證事務語義。
3.3 Flush 到磁盤 — 生成 Segment 文件
Flush 過程:
-
當Memtable數據寫滿后,會異步flush生成一個Segment進行持久化,同時生成一個新的Memtable繼續接收新增數據導入
-
在寫入磁盤前會做最終的編碼、壓縮、索引構建(如短鍵索引、列級統計信息、ZoneMap/MinMax),并生成元數據描述該 Segment(如行數、列偏移、壓縮方式)。
3.4 事務管理與元數據發布
事務與可見性:
- FE 為寫入分配 Txn ID / Version,用來保證原子性和版本管理。
- BE 在本地成功寫入 Segment 后,會向 FE 匯報“寫入完成并持久化”的消息(包含生成的 Segment 元信息)。
- FE 收到足夠的確認(通常基于多數副本策略)后,會發 Publish 任務使導入的 Rowset 版本生效。任務中指定了發布的生效 version 版本信息。之后 BE 存儲層才會將這個版本的 Rowset 設置為可見。最后Rowset 加入到 BE 存儲層的 Tablet 進行管理。
元數據更新:
- FE 在提交時更新元數據(Tablet 的版本、Segment 列表、事務日志),并把新的元信息持久化到元存儲。
3.5 后臺優化:Compaction(合并)
為什么需要 Compaction:
- 寫入產生許多小的 rowset(小文件),長期積累會:
- 增加查詢時需要掃描的文件數(查詢隨機 IO 增多)。
- 增大元數據開銷。
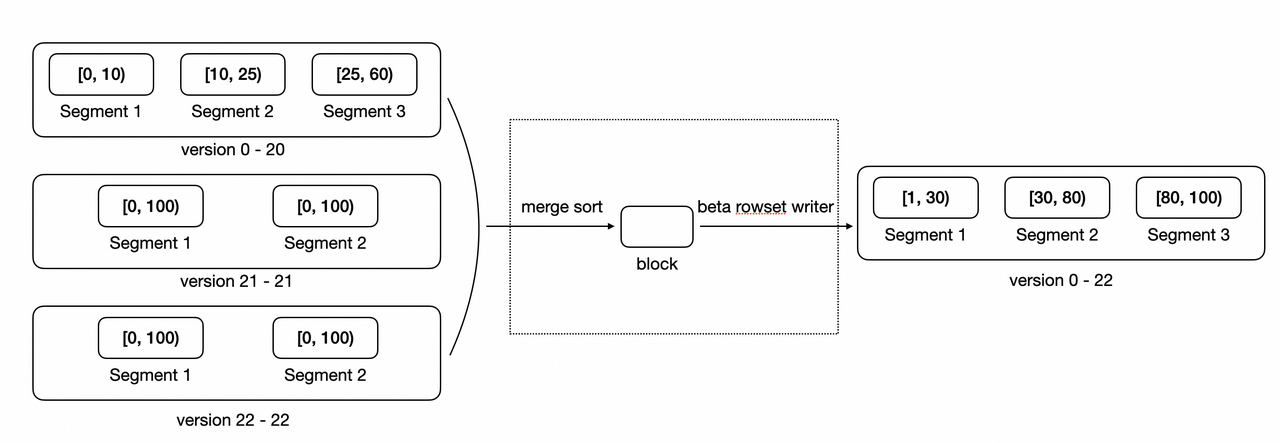
常見 Compaction 策略:
- Cumulative Compaction:優先合并新寫入的小 Rowset,避免直接與大 Rowset 合并導致效率低下。新導入的零散數據(如實時寫入的小批次數據 ),先通過Cumulative Compaction逐步 “攢大”,減少后續 Base Compaction 的壓力。。
- Base Compaction:當Cumulative Rowset 合并到一定規模后,再與 歷史大 Rowset(Base Rowset)合并,最終形成更緊湊的大 Rowset。
更多Compaction原理與優化可參考鏈接內容
4. 總結
一條數據寫入到 Doris 的旅程包含多個環節,理解數據寫入的每個環節(MemTable、Flush、Compaction、FE 事務等),能夠更好的幫助我們優化寫入性能與穩定性。







)

)


深度解析)
![[能源化工] 面向鋰電池RUL預測的開源項目全景速覽](http://pic.xiahunao.cn/[能源化工] 面向鋰電池RUL預測的開源項目全景速覽)





)