深度神經網絡由多層網絡連接而成,網絡連接處防止線性直接相關,采用非線性函數進行逐層隔離,真正實現每層參數的獨立性,也就是只對本層提取到的特征緊密相關。因為如果是線性函數直接相連就成了一層中間網絡了,只不過參數之間做變換,失去了深度學習的意義。
1.非線性函數的意義
? ? ? ? 每一層可以聯想為一組正交基,可以理解成一個平面,平面通過非線性變換達到扭曲逼近擬合真實要求的曲面。這是基于目前通常的思路,一個平面上y=Wx?+B變換后,再通過非線性進行扭曲成y=x*sin(x)(效果舉例,不是真正就是這個函數).實現了逐層扭曲直至達到最終要求。
? ? ? ? ?可不可以拋開第一步的正交基,直接用非平面內的非線性曲面來擬合本層任務的扭曲要求,有待進一步探索。
2.損失函數
????????輸入數據->深度網絡模型->輸出數據,在這個數據流向里,數據最終經過n層網絡的處理后,也就是多個函數變換后(有線性、也有非線性)得到一個輸出值(不是數量1個),怎么判斷輸出值是不是我們想要的?那就是離真實值越接近越好。最直觀的就是loss = |f(x)-y|,loss值太大后,我們要求反向逐層調整W,B的值,直至loss值比較小為止。
下面單獨講損失函數。
L1 LOSS?
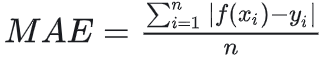
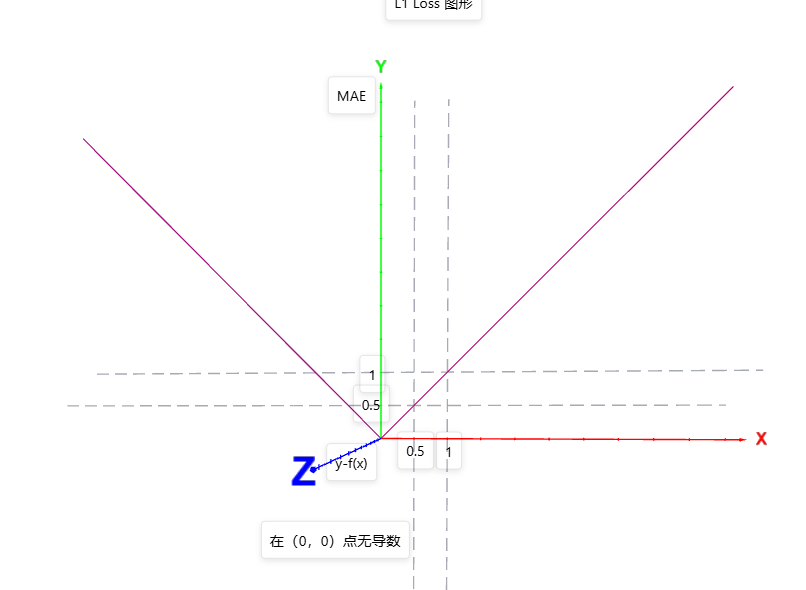
圖中很明顯在(0,0)點無導數,在其他位置導數是常數。優點是:導數常量不會梯度爆炸,就是不出現極大值。
L2 loss
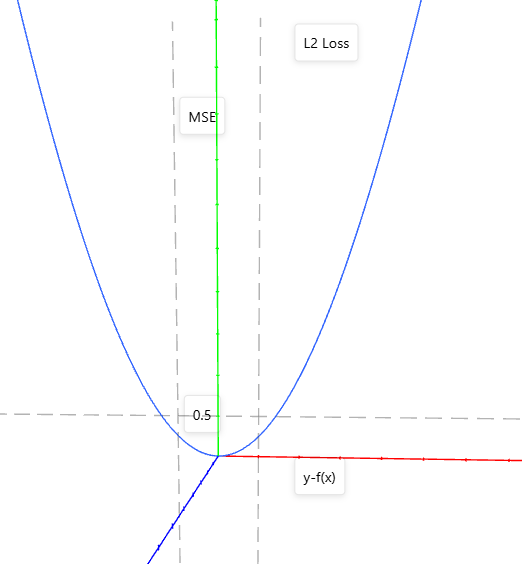
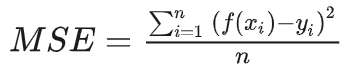
也就是f=x*x的函數圖形。
優點:函數曲線連續,處處可導,隨著誤差值的減小,梯度也減小,有利于收斂到最小值。缺點:當函數的輸入值距離中心值較遠的時候,使用梯度下降法求解的時候梯度很大,可能造成梯度爆炸。
3.Smooth L1 loss
公式如下:
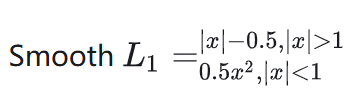
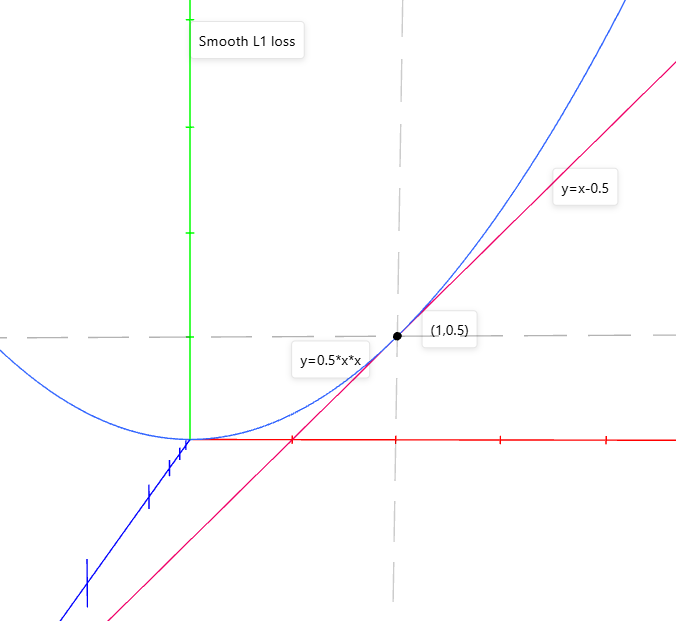
Smooth L1 loss 結合了L1和L2的優點,高偏差時采用固定梯度防梯度爆炸,靠近精度需求時,采用可導方式,有效調參。



)







)


)




