目錄
一、企業注重數據可視化的原因
1.提升數據理解效率
2.發現數據中的規律和趨勢
3.促進企業內部溝通與協作
4.增強決策的科學性
5.提升企業競爭力
二、可視化數據圖表的基本概念
1.常見的可視化圖表類型
2.可視化圖表的構成要素
3.可視化圖表的設計原則
三、制作可視化數據圖表的步驟
1.明確數據可視化的目標
2.收集和整理數據
3.選擇合適的圖表類型
4.進行數據可視化設計
5.驗證和優化可視化圖表
總結
Q&A 常見問答
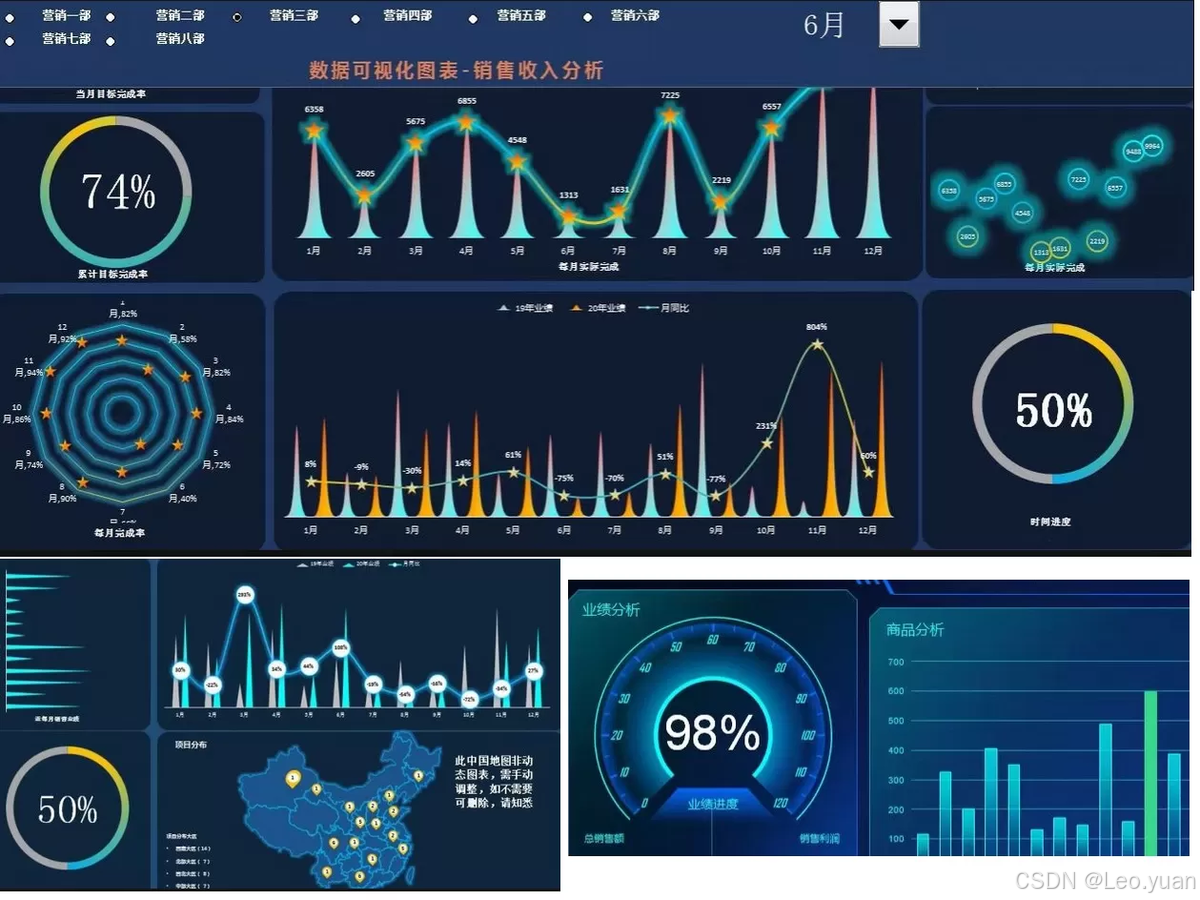
不知道你有沒有過這種經歷?開會的時候,同事甩來一張滿是數字的Excel表,密密麻麻幾十行,講了半天“銷售額增長情況”,你盯著數字還是沒搞懂到底漲了多少、哪個產品漲得好?最后還得自己花時間去琢磨,又費時又費力。
這就是現在企業都在做數據可視化的原因——不是為了“好看”,是為了讓數據“能看懂、能用起來”。一堆數字藏著的信息,換成圖表一眼就能看明白。像FineBI,就是幫企業把這些數字變成圖表的工具,不管是銷售數據、庫存數據,都能快速轉成直觀的圖,開會的時候不用再對著數字糾結。今天咱們就說透兩件事:企業為啥非要做數據可視化?還有,可視化圖表到底該怎么做才有用,全是能落地的干貨,保證你看完就會用。
一、企業注重數據可視化的原因
1.提升數據理解效率
我一直強調,人對圖像的反應速度比數字快太多了。你看一張寫著“A產品賣了50萬、B產品賣了30萬、C產品賣了20萬”的表格,得逐行看數字、在腦子里算對比;但要是換成柱狀圖,三根柱子一擺,誰高誰低一眼就知道,A產品賣得最好,C產品最差,不用花時間解讀。
說白了,數據可視化就是“把數字翻譯成圖”,省掉中間“讀數字、算對比”的步驟。
很多企業天天說“數據驅動”,但數據都藏在表格里沒人能快速看懂,怎么驅動?可視化就是解決這個問題的,讓不管是老板還是基層員工,都能快速get數據里的信息。
2.發現數據中的規律和趨勢
光看懂還不夠,可視化還能幫你找到數據里藏著的規律。比如你看一家服裝店的銷售數據,表格里每天的銷量數字看著都差不多,但做成折線圖就會發現:每周五、周六銷量會漲,每年3月、9月會有小高峰——這就是趨勢,靠看數字很難發現。
換個角度來看,不是數據里沒有規律,是數字太多把規律蓋住了。可視化就像把這些規律“拎出來”,讓你能看到數據的變化趨勢、周期性波動,這些信息對做計劃太重要了。
3.促進企業內部溝通與協作
企業里最頭疼的就是“部門間溝通不同步”。銷售部說“這個月銷量很好”,財務部說“利潤沒漲”,市場部說“我們的推廣起作用了”,但沒人能拿出大家都看得懂的數據,最后吵半天沒結果。
數據可視化能解決這個問題,因為圖表是“通用語言”。比如銷售部用柱狀圖展示各產品銷量,財務部用折線圖展示各產品利潤,市場部用餅圖展示各渠道推廣效果,大家對著圖表聊,能快速達成共識:哦,原來A產品銷量高但利潤低,B產品利潤高但銷量沒上去,推廣要往B產品傾斜。這就是可視化的好處,把抽象的“分歧”變成具體的“數據問題”,溝通效率高多了。
4.增強決策的科學性
老板做決策的時候,最怕“拍腦袋”。比如要不要開新店、要不要推新品,要是只憑“感覺”,很容易出錯。但有了可視化圖表,決策就有了依據。
用過來人的經驗告訴你,不是有數據就能做對決策,是得讓數據“能支撐決策”。可視化把關鍵信息直觀地展示出來,老板不用再從一堆數字里找答案,決策的時候更有底氣,也不容易出錯。
5.提升企業競爭力
現在市場變化太快了,比如電商平臺搞促銷,得實時看銷量變化,要是等下班了再整理表格,可能錯過調整價格、補庫存的時機。數據可視化能幫企業“實時響應變化”。
比如做直播帶貨的企業,用FineBI做實時儀表盤,展示當前銷量、客單價、退貨率,主播和運營能隨時看:哦,這個產品銷量突然漲了,得趕緊讓倉庫補貨;那個產品客單價低但退貨率高,得在直播里多講清楚產品細節。這樣才能抓住機會,減少損失。這就是可視化的競爭力,讓企業能快速應對市場變化,比對手反應更快>>>https://www.fanruan.com/login?action=active-fbi
二、可視化數據圖表的基本概念
1.常見的可視化圖表類型
很多人做可視化,一上來就問“哪個圖表好看”,其實根本錯了——選圖表要看“你想表達什么”,不同的圖表有不同的用途,選錯了會誤導人。
- 先說最常用的柱狀圖,用來“對比不同類別的數據”。比如對比各門店銷量、各產品利潤,柱子越高代表數據越大,直觀得很。但要注意,別用3D柱狀圖,看著花里胡哨,反而看不清高度,普通的平面柱狀圖就夠了。
- 然后是折線圖,用來“展示數據隨時間的變化趨勢”。比如每月銷量變化、每周用戶增長,折線往上走就是漲,往下走就是跌,還能看出漲得快還是慢。我之前有個客戶做線上教育,用折線圖看每日新增用戶,發現周一到周五增長慢,周末增長快,就把推廣重點放在周末,效果立竿見影。
- 餅圖用來“展示各部分占總體的比例”。比如各渠道銷售額占比、各產品利潤占比,一塊餅代表總體,每一小塊的大小就是占比。但要注意,別用超過5個類別的餅圖,不然小塊太多,看不清誰占比大,比如你把10個產品的銷量做成餅圖,最后只能看到一堆小塊,根本分不清。
- 散點圖用來“看兩個變量之間的關系”。比如廣告投入和銷量的關系,每個點代表一次廣告投放,點的位置能看出:廣告投入多的時候,銷量是不是也高?要是點大致往上走,說明兩者正相關,以后可以多投廣告;要是點很分散,說明沒什么關系,投廣告沒用。
- 值得一提的是,還有熱力圖,用來“展示數據的密度或強度”。比如門店的客流熱力圖,紅色區域代表客流大,藍色區域代表客流小,能直觀看到哪個區域客人多,方便調整貨架位置。FineBI里這些圖表都有,不用自己畫,選好數據就能生成。
2.可視化圖表的構成要素
一個好的圖表,不是只有“圖”,得有這些要素,不然別人看不懂:
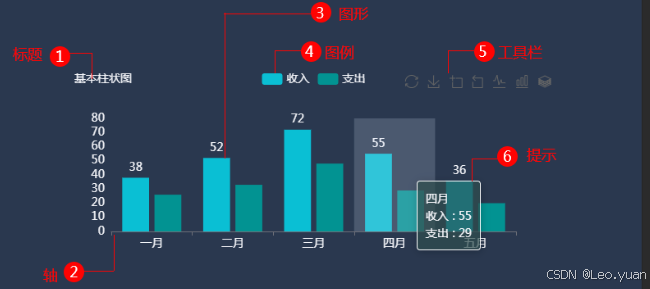
- 標題:得清楚說明“圖表講的是什么”,簡潔凝練為主。
- 坐標軸:橫軸和縱軸都要標清楚“代表什么、單位是什么”,單位要選擇合適的比列,不然圖表會顯得奇怪。
- 圖例:要是圖表里有多個數據系列,比如柱狀圖里有“2023年銷量”和“2024年銷量”,圖例要說明“藍色柱子是2023年,紅色柱子是2024年”,不然別人分不清哪個是哪個。
- 數據標簽:關鍵數據最好標在圖表上。比如柱狀圖里,最高的柱子標上“500萬元”,最低的標上“120萬元”,別人不用看縱軸也能知道具體數值,不用再“估摸著看”。
- 注釋:如果有特殊情況,要在圖表下面加注釋說明,不然別人會誤解。
3.可視化圖表的設計原則
很多人做圖表,喜歡加各種特效,比如3D效果、漸變顏色、動態閃爍,其實完全沒必要,反而會干擾對數據的理解。設計圖表要遵循“簡潔、準確、易懂”三個原則。
- 簡潔性原則:別加無關的裝飾,記住,圖表是為了展示數據,不是為了“好看”。
- 準確性原則:這是最關鍵的,不能誤導人。比如縱軸的刻度別從中間開始,要是銷量從100萬到500萬,縱軸從0開始,能看出差距;要是從100萬開始,會顯得差距特別大,誤導別人以為“銷量翻了好幾倍”。還有,餅圖的各部分比例加起來必須是100%,不能算錯。
- 易懂性原則:要讓不懂業務的人也能看明白。比如用顏色的時候,別用太偏的顏色,紅色代表下降、綠色代表增長,符合大家的習慣;別搞“紅色代表增長、綠色代表下降”,別人會看反。還有,字體要清晰,別用太小的字體,不然別人看不清標簽。
三、制作可視化數據圖表的步驟
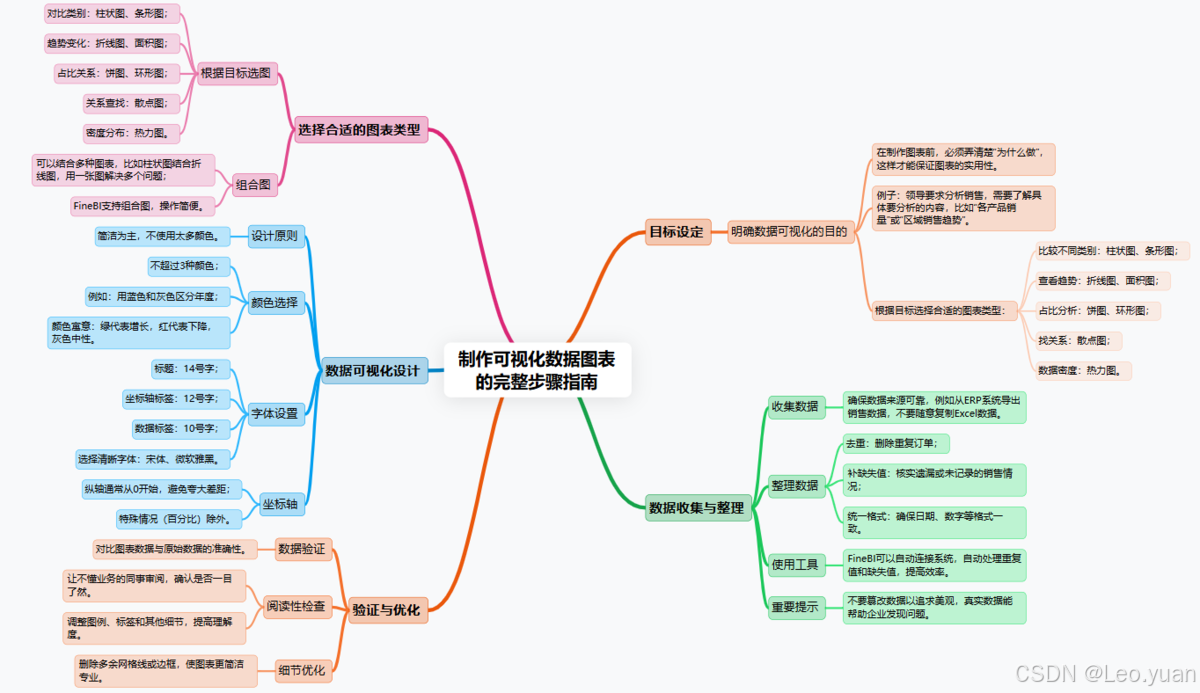
1.明確數據可視化的目標
很多人做圖表之前,沒搞清楚“為什么做”,結果做出來的圖表沒用。
所以第一步一定要明確目標:我們做這個圖表,是要解決什么問題?是要對比不同類別的數據,還是要看趨勢,還是要找關系?不同的目標要選擇不同的圖表類型,目標琢磨不清楚的話會影響后期圖表的制作。
2.收集和整理數據
數據是圖表的基礎,數據錯了,圖表再好看也沒用。所以收集數據的時候,要注意“數據來源可靠”,別隨便復制,容易出錯。
整理數據的時候,要做三件事:
- 去重
- 補缺失值
- 統一格式
FineBI有個好處,能直接連ERP、CRM這些系統,不用手動導數據,還能自動處理重復值、缺失值,省了很多時間。我之前幫一家企業做數據整理,手動弄要花一天,用FineBI自動處理,半小時就搞定了,還沒出錯。
這里要提醒一句,別為了“好看”篡改數據,這樣做出來的圖表雖然好看,但會誤導決策,最后害了企業。數據要真實,哪怕結果不好,也能幫企業發現問題。
3.選擇合適的圖表類型
選圖表的時候,記住“什么目標選什么圖”,別憑感覺。我總結了一個簡單的對應關系,你可以照著選:
- 要對比不同類別數據:選柱狀圖、條形圖
- 要展示數據隨時間變化:選折線圖、面積圖
- 要展示各部分占總體比例:選餅圖、環形圖(
- 要找兩個變量的關系:選散點圖
- 要展示數據密度:選熱力圖
這樣做合適嗎?并不!不是所有情況都按這個來,比如你想同時展示“各產品銷量”和“銷量趨勢”,可以用組合圖——柱狀圖展示各產品銷量,折線圖展示銷量同比增長率,這樣一張圖能說明兩個問題,不用做兩張圖。FineBI支持組合圖,操作也簡單,選好兩個數據系列就能生成。

4.進行數據可視化設計
設計的時候,記住“簡潔為主”,別搞花里胡哨的。
- 首先是顏色,別用超過3種顏色,并且顏色要符合習慣,比如增長用綠色,下降用紅色,中性數據用灰色。
- 然后是字體,標題用14號字,坐標軸標簽用12號字,數據標簽用10號字,別用太花哨的字體,需要清晰易讀。
- 還有坐標軸設置,縱軸要從0開始,除非是百分比數據,不然會夸大差距,讓讀者產生誤解。
5.驗證和優化可視化圖表
圖表做出來之后,別直接用,要驗證和優化。
- 首先驗證數據準確性,把圖表里的數據和原始數據對比,別因為公式錯了導致數據不對。
- 然后檢查可讀性,找個不懂業務的同事看一眼,問他“你能看懂這張圖講的是什么嗎?能看出哪個數據最好、哪個最差嗎?”要是他看不懂,說明圖表設計有問題,得改。
- 最后優化細節,比如有沒有多余的網格線、邊框。我之前做圖表,一開始加了很多網格線,后來刪掉多余的,看起來清爽多了,也更容易聚焦數據。
FineBI有個“預覽”功能,能模擬在不同設備上的顯示效果,比如在電腦上看和在手機上看,確保在手機上也能看清標簽和數據,很實用。
總結
企業看重數據可視化,根本不是為了“做漂亮圖表”,而是為了讓數據“能用、好用、能解決問題”——把藏在表格里的銷量差距、成本漏洞、流失風險,變成直觀的圖,不管是老板還是基層員工,都能快速看懂、快速行動。
制作可視化圖表也沒有那么復雜,像是現在的FineBI這類工具在這中間幫了不少忙,但工具只是輔助,關鍵還是要“以用為核心”,別為了做圖表而做圖表。
好了,言歸正傳。現在很多企業都在做數字化,但數字化不是“把數據存起來”,而是“把數據用起來”。數據可視化就是“用數據”的第一步——讓數據從“沒人看的數字”變成“能指導行動的工具”。不管你是做銷售、財務還是HR,學會做實用的可視化圖表,不僅能提高自己的工作效率,還能幫企業發現問題、抓住機會,這才是數據可視化真正的價值。
Q&A 常見問答
Q1:數據量太大,做可視化圖表的時候加載很慢,怎么解決?
A:數據量大導致加載慢,主要是“數據沒處理好”,不是工具的問題。可以試試這三個方法:
- 第一,做數據抽樣或聚合。比如你有1000萬條銷售明細數據,不用全加載,抽樣取10萬條,加載速度會快很多;或者把明細數據聚合,比如按“天”聚合,不用加載每小時的數據,除非你要做小時級監控。FineBI里有“數據聚合”功能,能自動按時間、地區等維度聚合數據,不用手動處理。
- 第二,優化數據存儲。如果數據存在Excel里,換成數據庫(比如MySQL、Hadoop),數據庫處理大量數據的速度比Excel快10倍以上。FineBI能直接連數據庫,加載數據的時候不用導出來,直接從數據庫取,速度會快很多。我之前有個客戶,把100萬條數據從Excel轉到MySQL,加載圖表的時間從5分鐘降到了10秒。
- 第三,減少圖表中的數據系列。比如做折線圖,別同時放20個產品的銷量,只放重點的5個,其他歸為“其他產品”,圖表加載的時候要處理的數據少了,速度自然快。要是非要展示20個產品,可以分多個圖表,比如“Top5產品銷量”“其他產品銷量”,別擠在一張圖里。
Q2:同一個數據,不同部門做的可視化圖表結果不一樣,怎么統一?
A:這種情況很常見,解決辦法是定“統一數據口徑”,最好成立一個“數據小組”(由IT、業務部門、財務部門組成),一起制定規則:比如“月度銷量”統一按“當月實際到賬金額”算,包含線上線下所有渠道,不包含退貨金額;“產品分類”統一按“公司產品目錄”分,別銷售部按“價格”分、財務部按“品類”分。規則定好后,寫在“數據口徑文檔”里,所有部門做圖表都按這個文檔來,還要定期檢查,確保沒人用錯口徑。你懂我意思嗎?不是數據本身有問題,是

應用指南)








![[rStar] 搜索代理(MCTS/束搜索)](http://pic.xiahunao.cn/[rStar] 搜索代理(MCTS/束搜索))



)




