第2章:搜索代理(MCTS/束搜索)
歡迎回到rStar
在前一章中,我們學習了求解協調器,它就像是解決數學問題的項目經理。
它組織整個過程,但本身并不進行"思考",而是將這項工作委托給其專家團隊。
今天,我們將認識這個團隊中最重要的成員:搜索代理。它們是rStar的"思考者"或"策略家"。
什么是搜索代理?
想象我們在玩一個復雜的棋盤游戲,比如國際象棋。
我們不會隨機選擇一步棋;而是會前瞻思考。我們會考慮幾種可能的走法,設想對手可能的應對,并嘗試找到通往勝利的最佳路徑。
rStar中的搜索代理正是做這樣的事情,但針對的是數學問題
它們是"思考"并探索不同解決路徑的核心算法。當面對復雜問題時,它們不會只嘗試一種方法;而是構建一個潛在解決步驟的"樹",探索各種想法,直到找到最佳方案。
在rStar中,我們主要使用兩種類型的搜索代理,每種都有其獨特的策略:
- MCTS(蒙特卡洛樹搜索):這個代理像一個策略性的棋盤游戲玩家,
探索多種走法,從結果中學習,并專注于有希望的路徑。 - 束搜索(Beam Search):這個代理像一個更簡單的玩家,
每一步都選擇最好的幾個走法,決策更直接。
讓我們深入了解每一種代理,看看它們如何幫助rStar解決問題。
蒙特卡洛樹搜索(MCTS)
將MCTS想象成一個非常好奇且策略性強的探索者。當面對數學問題時,它不會立即知道最佳路徑,因此會嘗試許多不同的路線。
以下是MCTS的簡化工作流程:
- 探索(模擬):選擇一條路徑進行探索,嘗試新的步驟。這就像在決策樹中探索一個新的分支。
- 評估(推演):一旦到達一個"葉子"(潛在的終點或有趣的點),它會快速模擬問題的其余部分,猜測該路徑可能有多好。這就像在腦海中快速推演游戲的剩余部分。
- 學習(
反向傳播):然后更新關于該路徑所有步驟的知識。如果路徑導致好的結果,這些步驟會得到更高的分數;如果導致壞的結果,則分數較低。 - 決策(選擇):基于所有探索和學習,決定哪條路徑最有希望進一步探索。它平衡嘗試新事物(探索)和專注于之前表現良好的路徑(利用)。
經過多次迭代,MCTS變得非常擅長識別解決數學問題最有希望的步驟序列。
rStar工作流中的MCTS
在rStar中,MCTS代理從策略與獎勵大語言模型獲取想法,并構建一個復雜的搜索樹。求解協調器通過探索和學習的循環指導它。
以下是MCTS一次"推演"或"迭代"的簡化視圖:
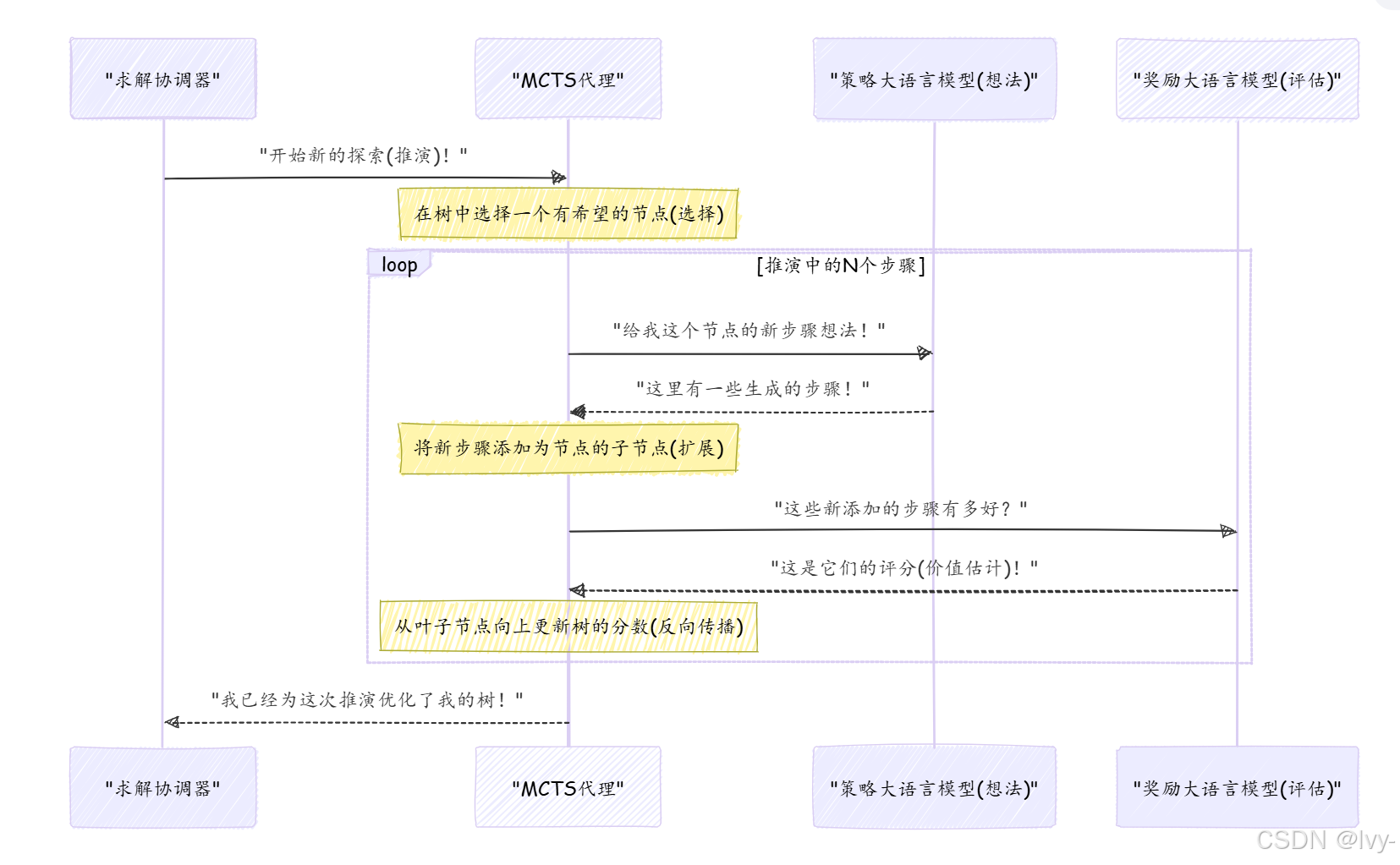
這個循環使MCTS能夠逐步構建一個更健壯的搜索樹,別更好的解決路徑。
樹中的每個"節點"代表一個解決方案節點——通向答案的部分步驟。
束搜索(Beam Search)
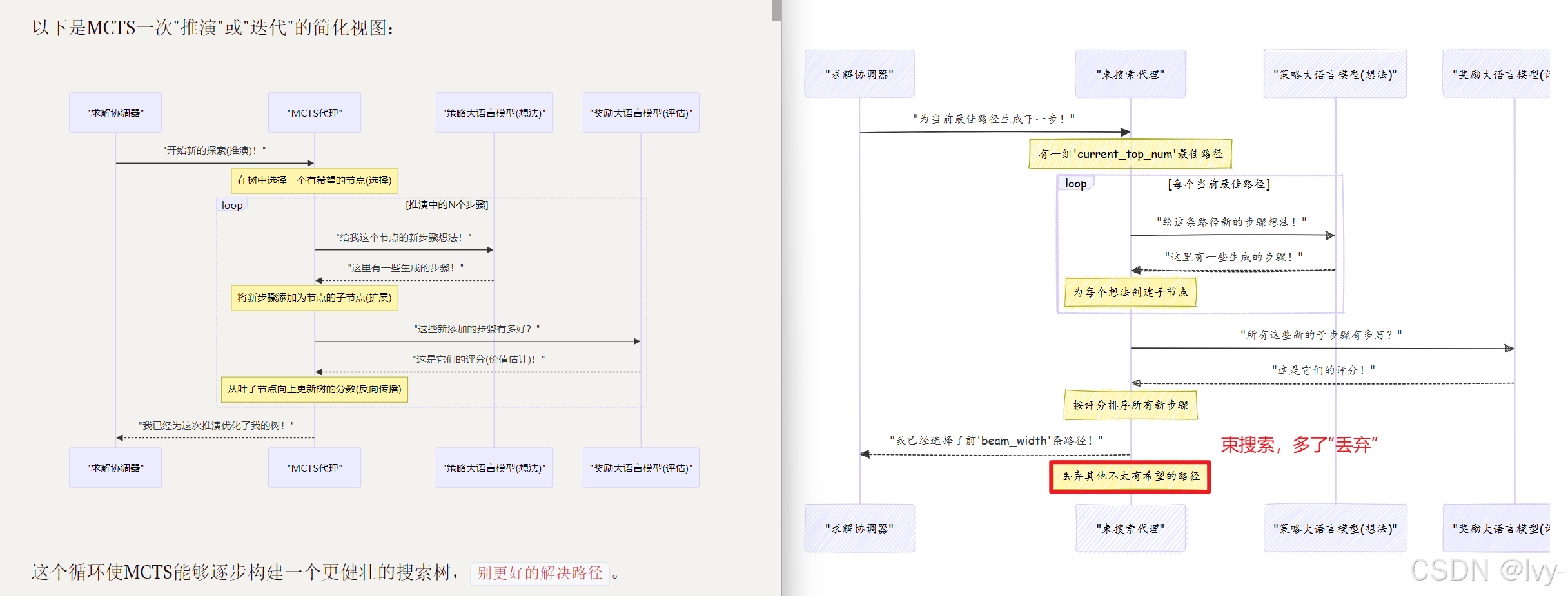
現在,讓我們看看束搜索。如果MCTS是一個策略性的深度思考者,束搜索更像是一個務實的=="當下最佳"決策者==。
以下是束搜索的工作方式:
- 生成想法:在問題的每一步,請求一組可能的下一步。
- 評估想法:評估所有這些可能的下一步。
- 選擇最佳幾個:不是探索所有路徑,而是只保留
N個最佳路徑(N稱為"束寬度")。立即丟棄其他不太有希望的路徑。 - 重復:繼續這個過程,始終只擴展前
N個路徑,逐步推進,直到找到解決方案或達到最大步數。
束搜索比MCTS更快,因為它不進行深度探索或復雜學習。它是一種"貪心"方法,始終嘗試選擇當前可用的最佳選項。
rStar工作流中的束搜索
rStar中的束搜索代理也使用策略與獎勵大語言模型獲取想法并評估它們。關鍵區別在于它如何處理這些評估以決定保留哪些路徑。
MCTS與束搜索:快速比較
MCTS和束搜索都是強大的搜索代理,但在不同場景下表現優異:
| 特性 | 蒙特卡洛樹搜索(MCTS) | 束搜索 |
|---|---|---|
| 策略 | 探索多條路徑,學習,平衡探索/利用。 | 貪心地選擇每一步的最佳幾個選項。 |
| 探索性 | 高——尋找新路徑并從結果中學習。 | 低——專注于擴展已知的良好路徑。 |
| 復雜性 | 更復雜,涉及模擬和樹更新。 | 更簡單,每一步評估和剪枝。 |
| 適用場景 | 需要深度策略推理的問題;不確定性較高。 | 良好的局部決策能導向良好全局結果的問題。 |
| 資源消耗 | 通常需要更多計算和內存,因為樹更深。 | 通常更高效,但可能錯過最優解。 |
如何在rStar中使用搜索代理
我們不會直接"調用"MCTS或束搜索代理。相反,我們通過配置告訴求解協調器使用哪種類型的代理。協調器會為我們初始化和管理這些代理。
以下是如何在rStar中通過配置文件(如config/sample_mcts.yaml或config/sft_eval_bs.yaml)指定代理類型:
# 來自config/sample_mcts.yaml
mode: "mcts" # 這行告訴rStar使用MCTS!
# ... 其他MCTS特定設置,如'iterations'和'c_puct'
# 來自config/sft_eval_bs.yaml
mode: "bs" # 這行告訴rStar使用束搜索!
# ... 其他束搜索特定設置,如'step_beam_width'
以下是求解協調器(來自第1章)如何根據我們的config創建和使用這些代理的概念性代碼:
# 概念性Python代碼,簡化自main.py和solver.pyfrom rstar_deepthink.agents import MCTS, BS
from rstar_deepthink.solver import Solver
from omegaconf import OmegaConf # 用于加載配置文件# 1. 加載所需的配置
# (例如,MCTS或束搜索的配置)
config = OmegaConf.load("config/sft_sample_mcts.yaml") # 或"config/sft_eval_bs.yaml"# 2. 初始化求解協調器
solver = Solver(config=config)# 3. 準備問題數據(例如,數學問題列表)
cur_data = [{"question": "2+2等于多少?", "answer": "4"}]# 4. 求解協調器根據配置中的'mode'創建代理
agents = []
for q in cur_data:if config.mode == "mcts":agents.append(MCTS(config=config, question=q['question'], ground_truth=q['answer']))elif config.mode == "bs":agents.append(BS(config=config, question=q['question'], ground_truth=q['answer']))else:raise ValueError("不支持的搜索模式配置!")# 5. 求解協調器指示這些代理解決問題
print(f"使用{config.mode}代理解決問題...")
solutions = solver.solve(agents, "results.jsonl", cur_data)print("找到解決方案!")
# 輸出可能如下:
# 使用mcts代理解決問題...
# 推演處理: 100%|██████████| 48/48 [00:0X<00:00, X.X 推演/s]
# 找到解決方案!
在這個例子中,只需在配置文件中更改mode(并確保為該模式提供正確的設置),就可以切換rStar的核心問題解決策略
搜索代理內部:代碼窺探
讓我們快速看看這些代理在rStar代碼庫中是如何定義的。
rStar中的所有搜索代理都繼承自一個共同的BaseTree類,該類提供了構建和導航解決方案樹的共享功能。
# 來自rstar_deepthink/agents/__init__.py
# 此文件列出所有可用的代理類型
from .tree import BaseTree
from .beam_search import BS
from .mcts import MCTS__all__ = ['BaseTree','BS', # 我們的束搜索代理'MCTS', # 我們的MCTS代理
]
這告訴我們BS和MCTS是主要的代理類。
BaseTree基礎
BaseTree類(在rstar_deepthink/agents/tree.py中)為所有代理設置了通用結構。它保存問題question、config,以及最重要的,解決方案樹的root節點。
# 來自rstar_deepthink/agents/tree.py(簡化)class BaseTree(BaseModel):config: Anyquestion: strroot: Optional[Type[BaseNode]] = None # 解決方案樹的起點current_node: Optional[Type[BaseNode]] = None # 當前在樹中的位置def __init__(self, **kwargs) -> None:super().__init__(**kwargs)self.root = self.create_root() # 創建第一個節點self.current_node = self.rootdef create_root(self) -> Type[BaseNode]:# 此方法為問題創建第一個節點root = self.create_node()root.state["extra_info"] = f"question: {self.question}"return root@abstractmethoddef create_node(self, parent: Optional[Type[BaseNode]] = None) -> Type[BaseNode]:# 每個特定代理(MCTS,束搜索)將定義自己的節點類型passdef collect_partial_solution(self, node: Type[BaseNode]) -> str:# 幫助從節點回溯到根節點收集步驟trajectory = []while node:if node.state['text']:trajectory.append(node.state['text'])node = node.parentreturn "".join(reversed(trajectory))# ... 其他通用方法
每個代理通過create_root()創建一個root節點。create_node方法留空(@abstractmethod),因為每個代理將使用稍微不同類型的解決方案節點來存儲其獨特信息。collect_partial_solution方法對于重建迄今為止采取的步驟很有用。
束搜索(BS)實現
BS類(在rstar_deepthink/agents/beam_search.py中)實現了束搜索邏輯。其核心思想是維護一個current_top_num(我們的束寬度)的最佳路徑。
# 來自rstar_deepthink/agents/beam_search.py(簡化)from rstar_deepthink.nodes.base_node import BaseNode # 束搜索使用基本節點class BS(BaseTree):current_top_num: int = 1 # 這是束寬度(config.step_beam_width)current_nodes: List[Type[BaseNode]] = [] # 當前正在探索的節點candidate_nodes: List[Type[BaseNode]] = [] # 所有新生成的子節點def __init__(self, **kwargs) -> None:super().__init__(**kwargs)self.candidate_nodes.append(self.current_node) # 從根節點開始self.current_top_num = self.config.step_beam_width # 從配置設置束寬度def create_node(self, parent: Optional[Type[BaseNode]] = None) -> Type[BaseNode]:# 束搜索使用標準BaseNode作為其解決步驟return BaseNode(parent=parent, additional_state_keys=self.NODE_KEYS)def select_next_step(self, outputs=None, from_root=False) -> None:# 生成想法并獲取值后,選擇最佳的幾個if outputs is not None:for candidate_node, output in zip(self.candidate_nodes, outputs):# 根據獎勵模型輸出更新節點值candidate_node.value = output.value_estimate if output.value_estimate is not None else 0# 按值(它們有多好)對所有候選節點排序self.candidate_nodes = sorted(self.candidate_nodes, key=lambda x: x.value, reverse=True)# 僅保留前'current_top_num'(束寬度)節點self.current_nodes = self.candidate_nodes[:self.current_top_num]# ... 也處理終端節點def generate_next_step(self, outputs: List[RequestOutput]) -> None:self.candidate_nodes = []for current_node, output in zip(self.current_nodes, outputs):self.current_node = current_node # 設置當前上下文# 為每個當前路徑生成多個子步驟(來自LLM的想法)for idx, output in enumerate(output.outputs):step_result, parser_result = self.step_unwrap(output.text + output.stop_reason)self.create_child(step_result, parser_result, current_node)self.candidate_nodes.extend(current_node.children) # 將所有新子節點添加為候選
select_next_step方法是束搜索的關鍵:它獲取所有新想法(子節點),獲取它們的分數(值),排序它們,并僅保留step_beam_width個最佳節點。generate_next_step是代理向策略與獎勵大語言模型請求多個下一步想法的地方,針對其當前最佳路徑。
蒙特卡洛樹搜索(MCTS)實現
MCTS類(在rstar_deepthink/agents/mcts.py中)更復雜,因為其探索-利用策略。它使用特殊的MCTSNode來跟蹤訪問次數和Q值。
# 來自rstar_deepthink/agents/mcts.py(簡化)from rstar_deepthink.nodes import MCTSNode # MCTS使用特殊的MCTS節點
from .beam_search import BS # MCTS繼承自束搜索,復用一些邏輯class MCTS(BS): # MCTS擴展束搜索,復用一些邏輯search_node: Type[MCTSNode] = None # 當前正在探索的特定節點def create_node(self, parent: Optional[Type[MCTSNode]] = None) -> Type[MCTSNode]:# MCTS使用MCTSNode,它跟蹤訪問次數和分數以進行決策return MCTSNode(parent=parent, additional_state_keys=self.NODE_KEYS, c_puct=self.config.c_puct)def selection(self, from_root=False) -> Optional[Type[MCTSNode]]:# 核心MCTS"選擇"步驟:選擇一個節點進行探索node = self.root if from_root else self.search_node# 此方法使用MCTSNode的PUCT值(利用和探索的平衡)# 來決定哪個子節點最有希望深入探索# ...(基于PUCT值選擇最佳子節點的復雜邏輯)...return node # 返回選擇的節點以進一步探索def expand_node(self, outputs: List[CompletionOutput], node: Type[MCTSNode]) -> None:# 核心MCTS"擴展"步驟:從LLM想法創建新的子節點for idx, output in enumerate(outputs):step_result, parser_result = self.step_unwrap(output.text + output.stop_reason)self.create_child(step_result, parser_result, node, idx)def eval_final_answer(self, node: Type[MCTSNode]) -> None:# 到達終端狀態(或評估潛在答案)后,# 此方法將獎勵"反向傳播"到所有父節點if node.state["final_answer"] in [NO_VALID_CHILD, TOO_MANY_STEPS, TOO_MANY_CODE_ERRORS]:node.update(self.config.negative_reward) # 分配懲罰return# ... 檢查答案是否正確并遞歸更新節點的邏輯# 這是MCTS學習的"反向傳播"步驟,所有祖先節點都從這個結果中學習node.update_recursive(value_estimate, self.root)
selection方法是MCTS決定下一步探索哪條路徑的地方,使用c_puct參數平衡已知信息(利用)和嘗試新事物(探索)。expand_node從策略與獎勵大語言模型提供的想法創建新的子節點。最后,eval_final_answer(包括"反向傳播"步驟)對MCTS的學習至關重要;它更新導致特定結果的所有節點的分數和訪問次數。
結論
現在我們已經認識了搜索代理——rStar背后的智能"思考者", 我們學習了:
- 什么是搜索代理,以及它們如何構建潛在解決步驟的樹。
- MCTS,策略性探索者,學習并專注于有希望的路徑。
- 束搜索,務實的決策者,總是選擇最佳的幾個選項。
- 如何配置
rStar使用MCTS或束搜索。 - 使這些代理工作的核心代碼的簡要介紹
這些代理之所以強大,是因為它們不只是猜測;而是系統地探索、評估和學習不同的解決路徑。然而,它們嚴重依賴"專家"來提供好的想法和準確的評估。
在下一章中,我們將探索這些"專家":策略與獎勵大語言模型,它們是負責生成創造性步驟并評估其質量的大語言模型。
下一章:策略與獎勵大語言模型



)





 D題題解記錄)









