- 作者:Xuan Yao1,2^{1,2}1,2, Junyu Gao1,2^{1,2}1,2, Changsheng Xu1,2,3^{1,2,3}1,2,3
- 單位:1^{1}1中科院自動化所多模態人工智能系統國家重點實驗室,2^{2}2中國科學院大學人工智能學院,3^{3}3鵬城實驗室
- 論文標題:NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments
- 論文鏈接:https://arxiv.org/pdf/2506.23468
- 代碼鏈接:https://github.com/Feliciaxyao/NavMorph
主要貢獻
- 提出了自演化世界模型框架 NavMorph,能夠自適應地建模連續環境的潛在表示,從而實現基于預見的決策制定和在線導航中的適應性。
- 設計了世界感知導航器和預見行動規劃器,并將其與上下文演化記憶無縫整合,以積累導航見解,實現合理且動態的行動規劃。
- 在典型的 VLN-CE基準測試中進行了廣泛的實驗,結果表明 NavMorph 顯著提升了多個模型的性能,驗證了其在適應性和泛化能力方面的改進。
研究背景
- 近年來,具身智能(Embodied AI)作為一個跨學科的研究方向,吸引了計算機視覺、自然語言處理和機器人學等領域的廣泛關注。其中,視覺語言導航(VLN)任務因其在現實世界中的廣泛應用前景而備受關注,例如機器人輔助、自主導航和智能家居系統等。
- VLN 任務要求智能體能夠解釋自然語言指令,在動態環境中處理視覺信息,并執行一系列動作以到達目標位置。然而,現有的方法在泛化到新環境和適應導航過程中的持續變化方面存在挑戰。
- 為了解決這些問題,研究者們受到人類認知能力的啟發,提出了世界模型的概念,通過模擬動作及其對世界狀態的影響來顯式建模環境動態。盡管已有研究展示了世界模型在導航中的潛力,但在 VLN 中的應用仍處于探索階段,尤其是在處理連續空間和動態環境適應性方面。
研究方法
任務定義
- VLN-CE(連續環境中的視覺語言導航)任務利用 Habitat Simulator 渲染 Matterport3D 數據集的環境觀測,為智能體提供 RGB-D 視覺輸入。
- 每個導航任務(episode)開始時,智能體接收指令和初始視覺觀測,任務結束條件是智能體選擇“停止”動作或達到最大步數限制。
- 智能體在每個時間步預測導航路徑上的點,這些點隨后被轉換為低層次的控制動作。觀測序列 o1:to_{1:t}o1:t? 表示從初始時刻到當前時刻 ttt 的所有觀測,而 a1:t?1a_{1:t-1}a1:t?1? 表示到 t?1t-1t?1 時刻的所有導航動作。
框架概述

NavMorph 模型旨在通過在結構化的潛在空間中學習和適應連續環境的時空動態,從而在在線測試期間促進有效的推理和行動規劃。該框架由兩個主要組件構成:
- 世界感知導航器(World-Aware Navigator,推理網絡):負責從歷史上下文和當前觀測中推斷環境動態,并在潛在空間中構建環境表示。
- 預見行動規劃器(Foresight Action Planner,預測網絡):利用潛在表示來預測未來狀態,從而促進有效的策略學習和戰略導航。
世界感知導航器
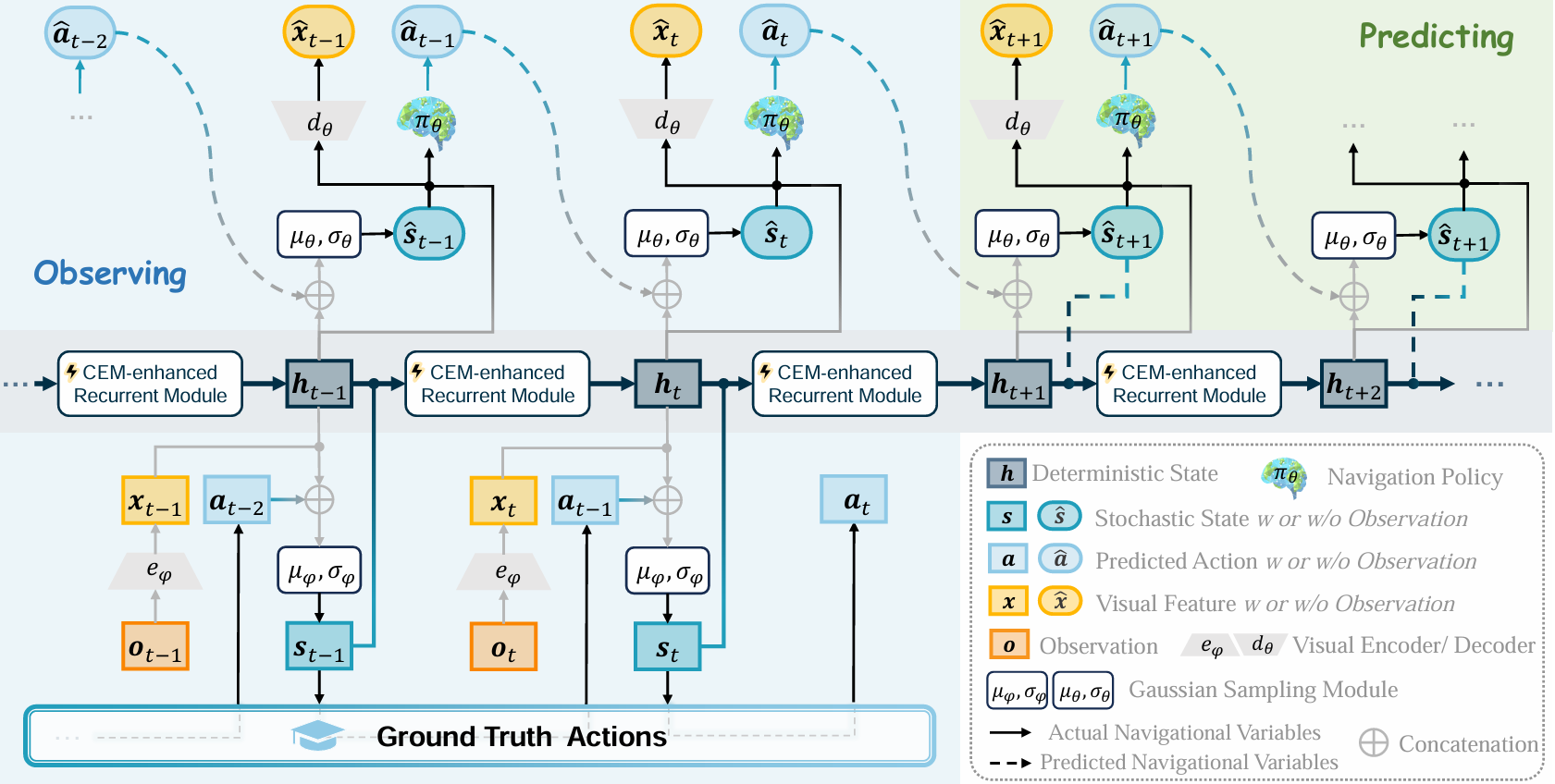
該部分是基于 RSSM(Recurrent State-Space Model)的策略型智能體,旨在將跨模態輸入映射到一系列動作上。具體步驟如下:
- 視覺表示:使用視覺編碼器 e?e_{\phi}e?? 處理觀測 oto_tot?,得到視覺特征 xtx_txt?。
- 初始潛在確定性狀態:h1h_1h1? 從零初始化。
- 遞歸模型:將前一時刻的確定性狀態 ht?1h_{t-1}ht?1? 和隨機狀態 st?1s_{t-1}st?1? 輸入到遞歸模塊 fff,得到當前時刻的確定性狀態 hth_tht?。
- 動態轉換模型:根據歷史觀測和動作,推斷當前時刻的隨機狀態 sts_tst?,遵循高斯分布 q?(st∣o1:t,a1:t?1)q_{\phi}(s_t|o_{1:t},a_{1:t-1})q??(st?∣o1:t?,a1:t?1?)。
此外,為了增強智能體保留和利用歷史導航見解的能力,引入了上下文演化記憶(CEM)。CEM 維護一系列場景上下文特征,通過動態更新這些特征,使模型能夠適應新場景,同時保留關鍵的視覺語義信息。具體來說:
- CEM 的增強機制:在訓練和在線測試過程中,CEM 通過前饋更新機制動態整合場景上下文信息,而不是依賴于基于梯度的反向傳播。這種機制確保了模型能夠快速適應新環境,同時保持對過去經驗的利用。
- CEM 的更新過程:通過計算當前狀態與記憶中特征的相似度,選擇最相關的特征進行更新,從而在保留關鍵信息的同時,避免了過時信息的干擾。
預見行動規劃器
該部分賦予智能體預測環境變化的能力,基于世界感知導航器學到的潛在狀態表示,通過在潛在空間中想象潛在場景來執行未來規劃。具體步驟如下:
- 初始潛在隨機狀態:s1s_1s1? 從標準正態分布初始化。
- 隨機狀態模型:根據當前的確定性狀態和前一時刻的隨機狀態,預測下一時刻的隨機狀態 s^t\hat{s}_ts^t?,遵循高斯分布 pθ(s^t∣ht,s^t?1)p_{\theta}(\hat{s}_t|h_t,\hat{s}_{t-1})pθ?(s^t?∣ht?,s^t?1?)。
- 視覺解碼器:將預測的隨機狀態 s^t\hat{s}_ts^t? 轉換為預測的視覺嵌入 x^t\hat{x}_tx^t?,為行動預測提供豐富的語義信息。
- 行動解碼器:根據預測的視覺嵌入和確定性狀態,預測下一時刻的行動 a^t\hat{a}_ta^t?。
此外,為了增強模型對未來狀態的預測能力,引入了一個重建任務,通過視覺解碼器 dθd_{\theta}dθ? 重建輸入觀測的視覺嵌入,而不是直接進行像素級別的圖像重建。這種重建目標有助于模型學習有用的潛在表示,并提高規劃的準確性。
預訓練目標
NavMorph 通過最大化數據對數似然的變分下界來訓練,涉及最小化視覺重建損失、動作預測損失以及后驗和先驗狀態分布之間的散度。具體來說:
- 損失函數 LWL_WLW?:包括過去和未來狀態的視覺重建損失、動作預測損失,以及后驗和先驗分布之間的 Kullback-Leibler(KL)散度損失。
- 正則化項:為了確保預測的導航軌跡與實際軌跡的時間一致性和對齊,引入了基于歸一化動態時間規整(NDTW)的正則化項。
- 完整損失函數:將世界模型損失 LWL_WLW? 與模仿學習目標 LILL_{IL}LIL? 結合,形成完整的損失函數 L=LW+LILL = L_W + L_{IL}L=LW?+LIL?。
工作模式
NavMorph 在訓練和測試階段以兩種不同的模式運行:
- 訓練階段:模型通過未來狀態預測來學習環境的潛在動態,處理觀測序列和相應的動作,通過優化損失函數來更新模型參數。
- 測試階段:自演化世界模型通過演化機制持續適應環境變化。遞歸模塊在測試過程中以在線方式更新 CEM,使模型能夠保留最近觀測的有用信息,同時調整對測試場景的理解,從而保持對周圍環境的豐富且最新的理解。
實驗
實驗設置
數據集
- R2R-CE:包含5,611條最短路徑軌跡,分為訓練、驗證和測試集。每條軌跡配有約3條英文指令,平均路徑長度為9.89米,指令長度為32詞。該數據集中的智能體具有0.10米的底盤半徑,可在導航時沿障礙物滑動。
- RxR-CE:規模更大且更具挑戰性,提供多種語言(英語、印地語和泰盧固語)的指令,平均指令長度為120詞。智能體的底盤半徑為0.18米,不能沿障礙物滑動,因此更容易發生碰撞。
評估指標
采用標準的VLN-CE評估指標,包括軌跡長度(TL)、導航誤差(NE)、成功率(SR)、路徑長度加權成功率(SPL)、歸一化動態時間規整(NDTW)和成功加權NDTW(SDTW)。
實現細節
- 對于全景設置,每個位置由12個RGB-D圖像表示,每30度拍攝一次。
- 在單目設置中,采用VLN-3DFF模型,利用預訓練的3D特征場模型進行部署。
- 所有實驗均使用PyTorch框架在單個NVIDIA RTX 3090 GPU上進行。
與最新VLN模型的比較
R2R-CE 數據集
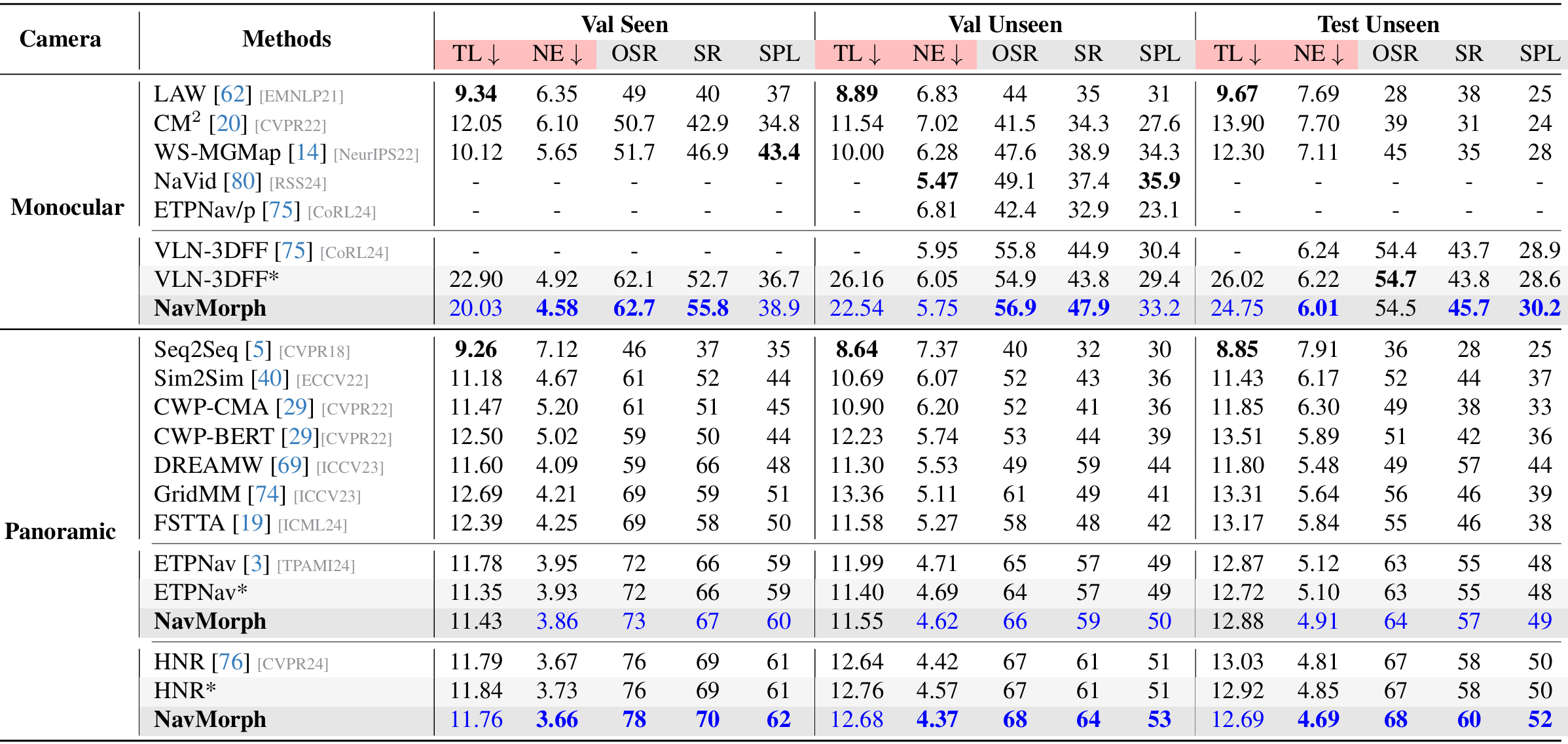
- 單目設置:NavMorph在多個指標上優于其他單目方法,尤其在未見環境中表現突出。例如,在Val Unseen分割上,NavMorph的SR和SPL分別比基線VLN-3DFF提高了超過4%。在Test Unseen分割上,NavMorph的SPL比VLN-3DFF提高了1.6%,SR提高了約2%。
- 全景設置:NavMorph在全景設置中也表現出色,與ETPNav和HNR等專門的全景方法相比具有競爭力。例如,在Test Unseen分割上,NavMorph的SPL為62,SR為70%,表現優異。
RxR-CE 數據集
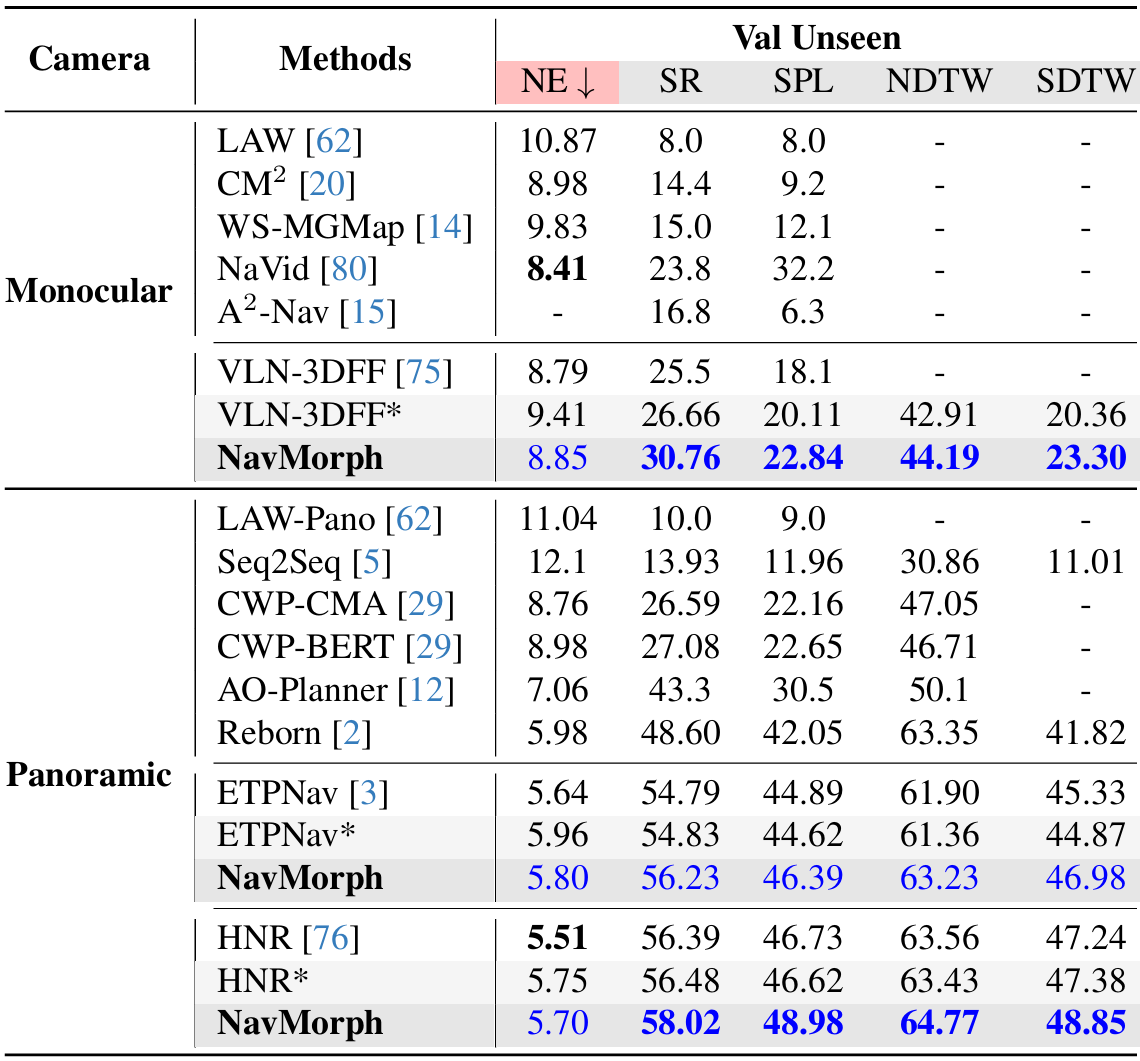
- 單目設置:NavMorph在單目設置中顯著優于之前的最佳方法VLN-3DFF,SR提高了4.1%,SPL提高了2.73%。此外,在NDTW和SDTW指標上也表現出色,分別達到64.77和48.85,表明NavMorph能夠忠實地遵循指令并保持路徑保真度。
- 全景設置:NavMorph在全景設置中也表現出色,SR為58.02%,SPL為48.98%,與ETPNav和HNR等方法相當。
消融研究與進一步分析
世界模型的消融研究
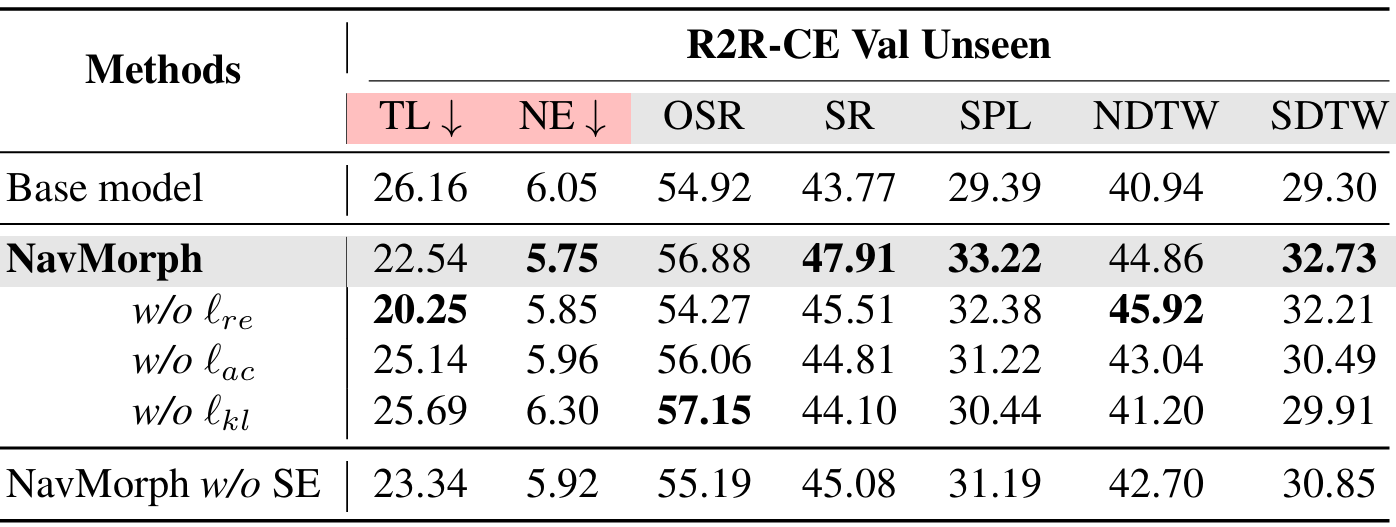
- 移除個別損失項會導致性能適度下降,這強調了這些損失項在捕捉世界模型潛在動態中的集體重要性。例如,移除視覺嵌入重建損失 ?re\ell_{re}?re? 會導致路徑長度縮短(22.54→20.25)和OSR降低(56.88%→54.27%),這突出了視覺一致性在維持周圍環境時間穩定表示中的作用。同樣,省略動作預測損失 ?ac\ell_{ac}?ac? 會降低多個指標,因為對預測動作序列的約束支持有效的策略學習。
- 此外,后驗和先驗分布之間的一致性對于維持學習到的潛在動態與實際導航場景之間的一致性至關重要,確保潛在表示的校準良好。
- 為了更好地評估自演化的貢獻,評估了不進行自演化的NavMorph(記為NavMorph w/o SE),結果表明,即使沒有自演化,世界模型架構本身也能帶來顯著的性能提升,而CEM支持的自演化進一步增強了導航效果。
CEM的消融研究
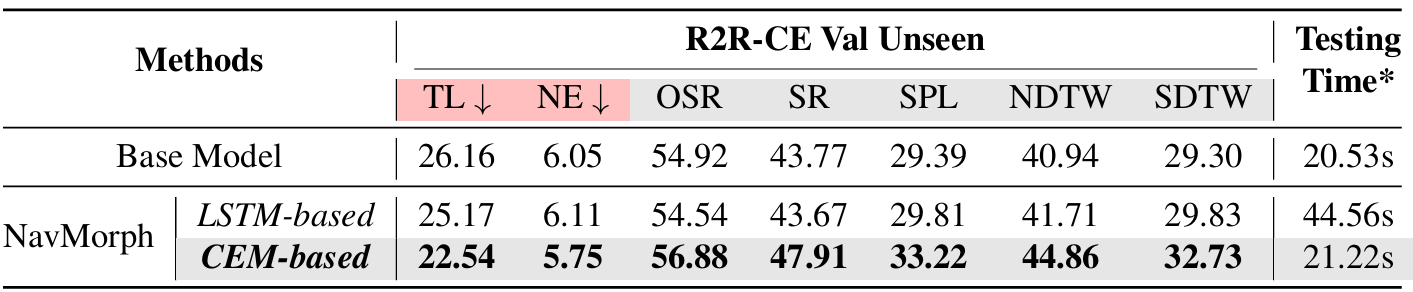
- CEM作為自演化的核心模塊,使智能體能夠保留和提煉歷史場景信息,以提高導航任務中的適應性。與依賴于梯度反向傳播進行在線測試適應的傳統循環架構(例如RNN、LSTM)不同,CEM采用前饋迭代更新機制,能夠高效地整合新觀測,而無需承擔過多的計算成本。
- 通過在相同的評估設置下進行消融研究,比較基于CEM的自演化機制與基于LSTM的替代方案。結果表明,基于CEM的NavMorph在所有關鍵指標上均優于基于LSTM的方法,這表明CEM在未見環境中具有更強的適應性。值得注意的是,盡管兩種方法都通過自演化提高了泛化能力,但基于LSTM的方法由于依賴于梯度優化,在測試時的計算成本增加了2.1倍。
上下文演化記憶的大小
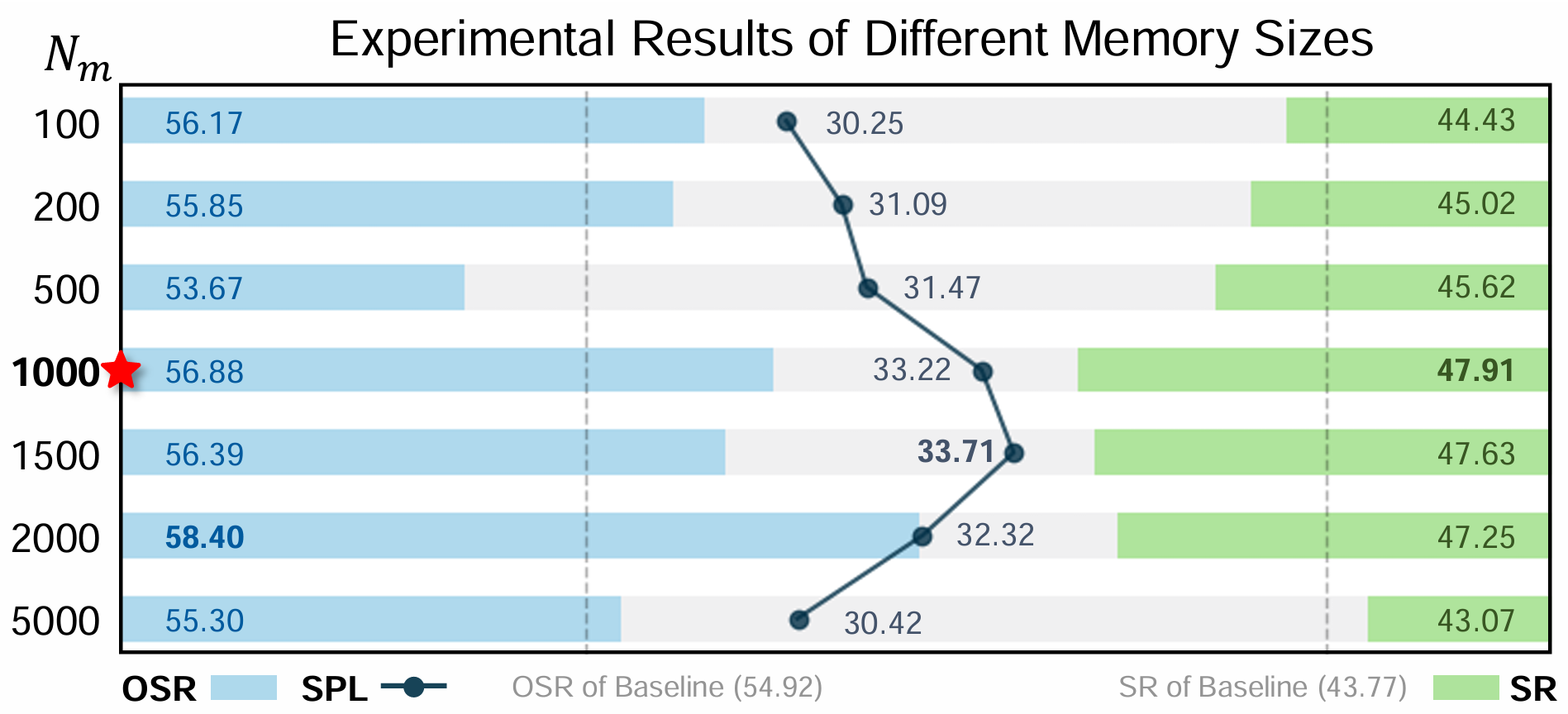
- 通過改變CEM中的記憶大小 NmN_mNm? 進行了全面的消融研究。結果表明,當 Nm=1000N_m = 1000Nm?=1000 時,模型達到了最佳性能,SR達到47.91%,OSR達到56.88%,SPL達到33.22%。較小或較大的記憶大小都會導致性能下降。
- 這表明,記憶容量不足會限制模型存儲關鍵上下文信息的能力,而過大的記憶可能會引入噪聲和冗余,從而干擾有效的決策制定。實驗結果驗證了在CEM中設置1000的記憶大小是上下文保留和適應性之間的最佳平衡,增強了智能體的導航魯棒性。
與最新在線VLN方法的比較

- NavMorph的自演化世界模型在在線測試時會積累來自測試環境的場景特定信息,并將其存儲為記憶信息。盡管這種記憶機制在測試樣本的地面真實動作不可用的情況下運行,但它可能會引發關于評估公平性的擔憂。然而,最近的研究已經建立了在線測試時適應在VLN任務中的實際意義,證明了其在現實世界部署中的價值,因為智能體必須不斷適應新環境。
- 與基于梯度的測試時適應方法FSTTA相比,NavMorph在導航準確性和效率方面均顯著優于FSTTA。此外,消融研究結果也表明,NavMorph能夠有效地利用積累的信息進行高效適應,同時保持穩健的性能。
結論與未來工作
- 結論:
- NavMorph 通過其自演化世界模型框架,在連續環境中的視覺語言導航任務中實現了顯著的性能提升。
- 該模型通過建模環境動態并利用上下文演化記憶,有效地適應了新環境,提高了導航的準確性和效率。
- 未來工作:
- 盡管 NavMorph 在 VLN-CE 任務中取得了良好的效果,但仍存在一些挑戰和改進方向。
- 例如,設計一個直接從真實環境中學習的導航獎勵函數,以更好地平衡任務目標與環境約束,從而增強長期決策能力。
- 此外,開發一個具有標準化組件的模塊化世界模型框架,將有助于通過系統化的模塊抽象來靈活組合和演化智能體的能力。









/S905L2(B)/S905L3(B)-原機安卓4升級安卓7/安卓9-通刷包)

)
)





)

 和 reactive() 的區別)