????????在分割的研究中,傳統卷積神經網絡(CNN)存在兩大關鍵問題:一是池化操作雖能降低計算復雜度,卻會導致特征圖中有效空間信息丟失,尤其太陽暗條這類不規則、精細結構的特征易被削弱;二是傳統 CNN 對特征圖通道間依賴關系建模不足,各通道特征獨立處理,難以充分挖掘通道間關聯信息,且現有深度學習模型(如 Mask R-CNN、經典 U-Net)常因參數規模大、計算成本高,難以適配高度集成化的地基與天基觀測設備需求。此外,復雜模型在硬件資源受限場景(如 GPU 內存不足)下,訓練與推理效率顯著下降。為解決這些問題,CSA-ConvBlock(通道自注意力卷積塊)被提出,旨在通過優化通道特征權重分配,在強化特征提取能力的同時控制參數規模,為輕量化網絡(如 Flat U-Net)提供核心組件,滿足太陽暗條分割等天文圖像任務對精度與效率的雙重需求???????
1.CSA-ConvBlock原理
????????CSA-ConvBlock 的核心原理是借助通道自注意力機制,重構特征圖通道間的關聯關系,動態分配通道權重,同時結合殘差連接與歸一化操作,實現高效的特征提取。
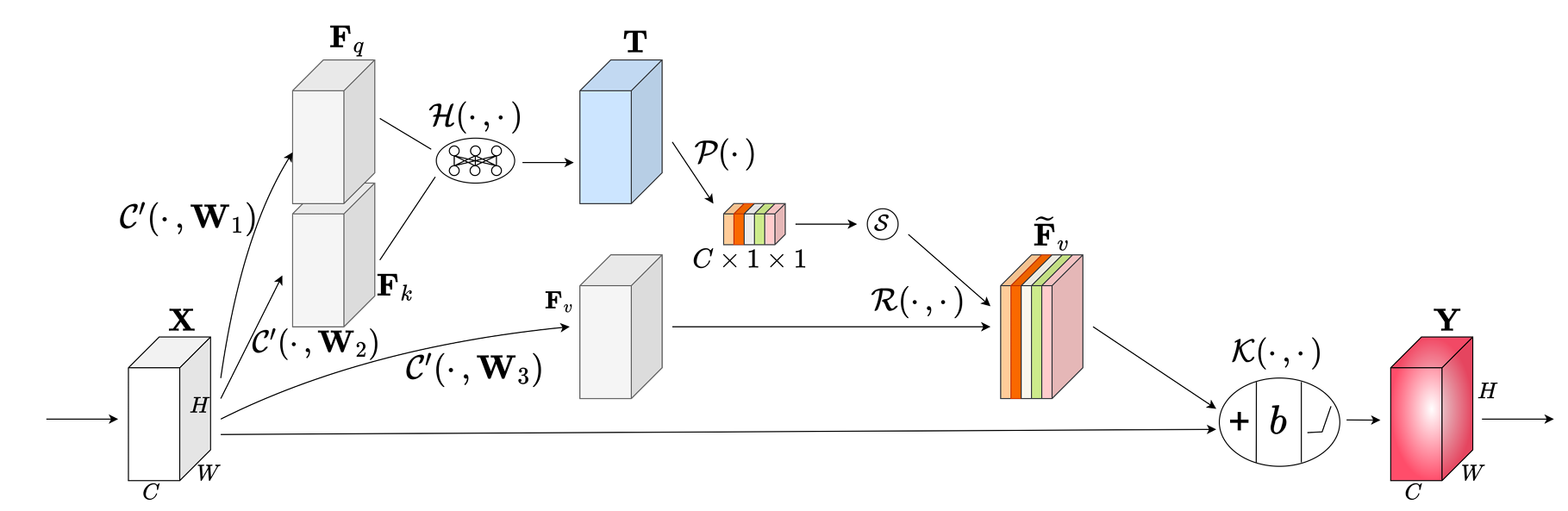
????????1.輸入層:接收經過預處理的特征圖,該特征圖通常由單通道的全日面 Hα 圖像通過卷積操作擴展為多通道,特征圖維度為(通道數 × 高度 × 寬度)。
????????2.無偏卷積層:包含三個并行的無偏卷積操作(卷積核權重初始化時無偏置),這三個操作分別將輸入特征圖轉換為查詢、鍵和值三種特征圖,三種特征圖的維度均與輸入特征圖保持一致,是實現通道自注意力機制的核心轉換單元。
????????3.相似度計算模塊:通過廣播點積運算,計算查詢與鍵的通道間相似度,生成相似度張量;同時引入歸一化因子對相似度張量進行縮放,確保數值穩定性,為后續權重計算提供可靠基礎。
????????4.全局平均池化層:對相似度張量的每個通道進行空間維度上的全局平均池化,將原本包含空間信息的張量壓縮為僅包含通道信息的向量,實現空間信息向通道權重的轉化。
????????5.?Softmax 激活層:對全局平均池化得到的向量進行 Softmax 歸一化處理,生成通道權重,明確各通道的重要性排序,使模型能聚焦于關鍵通道特征。
????????6.特征加權層:將 Softmax 層輸出的通道權重與值特征圖的每個通道進行逐元素乘法運算,對值特征圖進行加權重構,強化有效特征信息。
????????7.殘差連接與歸一化激活層:先將加權重構后的特征圖與輸入層的原始特征圖進行殘差連接,再通過批量歸一化層消除內部協變量偏移,最后經過 ReLU 激活函數引入非線性,輸出維度與輸入特征圖一致的優化特征圖,該輸出可直接作為下一層網絡的輸入。
2.CSA-ConvBlock習作思路
CSA-ConvBlock在目標檢測中的優點
????????在目標檢測任務中,CSA-ConvBlock 能顯著提升模型對目標特征的捕捉精度與效率。一方面,其通道自注意力機制可動態評估各通道重要性,針對性強化目標相關特征(如目標邊緣、紋理、局部結構)對應的通道權重,同時抑制背景噪聲通道干擾,尤其在復雜場景(如目標遮擋、光照變化)下,能有效降低背景誤檢率,提升目標定位準確性;另一方面,CSA-ConvBlock 僅通過少量無偏卷積、池化與激活操作實現注意力計算,參數增量極小,不會大幅增加模型計算復雜度,適配實時目標檢測對速度的需求,即使處理小目標時,也能通過挖掘通道間關聯信息,彌補小目標特征不完整的缺陷,提升小目標檢測召回率,同時避免傳統復雜注意力機制因大量矩陣運算導致的硬件資源占用過高問題。????????
CSA-ConvBlock在圖像分割中的優點
????????在圖像分割任務中,CSA-ConvBlock 對精細分割結果的提升作用尤為突出。首先,分割任務對像素級特征準確性要求極高,CSA-ConvBlock 通過全局通道權重分配,可充分挖掘不同通道間的互補信息(如部分通道聚焦目標輪廓、部分通道聚焦目標內部紋理),重構后的特征圖能更全面地表征目標的像素級特征,減少因特征缺失導致的分割邊緣模糊、孔洞等問題;其次,分割任務中池化操作易導致空間信息丟失,而 CSA-ConvBlock 的殘差連接設計可保留原始輸入的空間細節,結合注意力加權后的特征,有效緩解池化帶來的信息損失,尤其在處理不規則、精細結構目標(如太陽暗條、醫學影像中的器官邊緣)時,能提升分割結果的完整性與精細度;此外,CSA-ConvBlock 的輕量化特性使其可嵌入分割網絡的多個層級,從低維到高維特征均能進行通道優化,避免傳統分割模型因層級加深導致的特征冗余問題,在保證分割精度的同時,降低模型內存占用與推理時間,適配資源受限場景下的分割需求。????????
3. YOLO與CSA-ConvBlock的結合? ???? ? ?
? ? ? ? ?將 CSA-ConvBlock 融入 YOLO 模型,一方面,YOLO 通過多尺度特征融合檢測不同大小目標,CSA-ConvBlock 能在特征提取階段強化目標關鍵通道特征(如小目標的局部細節、大目標的結構特征),減少背景噪聲干擾,尤其在復雜場景下,可顯著提升小目標與遮擋目標的檢測召回率及定位精度;另一方面,CSA-ConvBlock 參數規模小,不會大幅增加 YOLO 的計算負擔,能在保證 YOLO 實時檢測核心優勢的前提下優化性能,即使在嵌入式設備等硬件資源受限場景,也能實現高效的目標檢測推理。
4.CSA-ConvBlock代碼部分
YOLO11|YOLO12|改進| 深度反向卷積Converse2D,通過非迭代的正則化優化實現特征精確恢復,增強特征上采樣,減少特征丟失_嗶哩嗶哩_bilibili
YOLO12模型改進方法,快速發論文,總有適合你的改進,還不改進上車_嗶哩嗶哩_bilibili
?代碼獲取:YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. CSA-ConvBlock引入到YOLOv12中
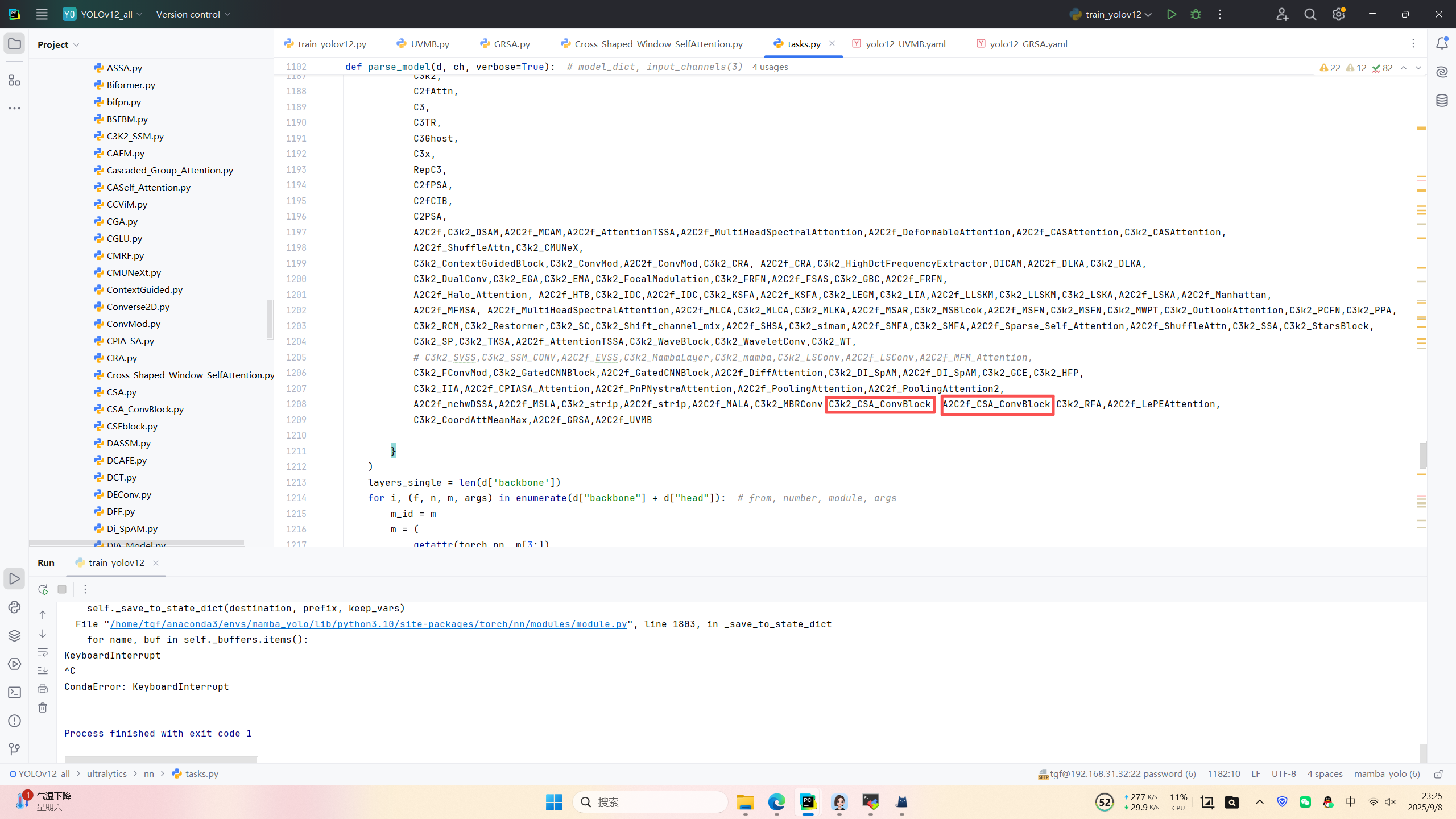
第一: 先新建一個v12_changemodel,將下面的核心代碼復制到下面這個路徑當中,如下圖如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。
第二:在task.py中導入包
?????????????????????????? ?
?
第三:在task.py中的模型配置部分下面代碼
??????????????????????????
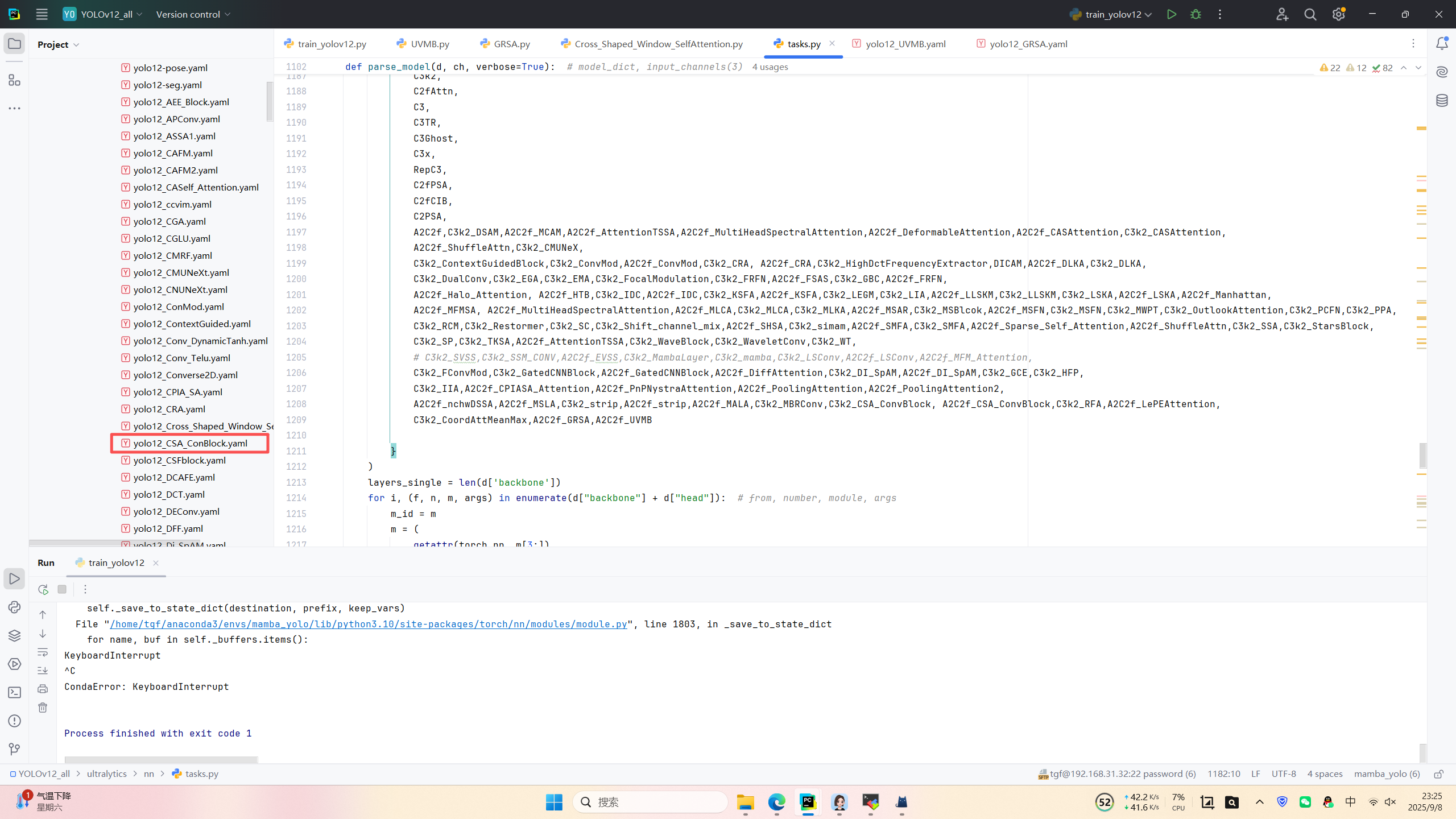
第四:將模型配置文件復制到YOLOV11.YAMY文件中
??????????????
? ???????????????????????????????????????????????第五:運行代碼
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":# 使用自己的YOLOv8.yamy文件搭建模型并加載預訓練權重訓練模型model = YOLO("/home/tgf/tgf/yolo/model/YOLO12_All/ultralytics/cfg/models/12/yolo12_CSA_ConBlock.yaml")\# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weightsresults = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",epochs=300,imgsz=640,batch=4,# cache = False,# single_cls = False, # 是否是單類別檢測# workers = 0,# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',amp = True)









![[數據結構——lesson3.單鏈表]](http://pic.xiahunao.cn/[數據結構——lesson3.單鏈表])








