Mysql全局優化總結
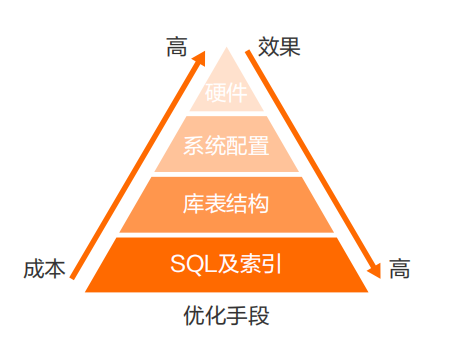
從上圖可以看出SQL及索引的優化效果是最好的,而且成本最低,所以工作中我們要在這塊花更多時間。
補充一點配置文件my.ini或my.cnf的全局參數:
假設服務器配置為:
- CPU:32核
- 內存:64G
- DISK:2T SSD
下面參數都是服務端參數,默認在配置文件的 [mysqld] 標簽下
mysql server系統參數
msyql server系統參數
max_connections=3000
連接的創建和銷毀都需要系統資源,比如內存、文件句柄,業務說的支持多少并發,指的是每秒請求數,也就是QPS。
一個連接最少占用內存是256K,最大是64M,如果一個連接的請求數據超過64MB(比如排序),就會申請臨時空間,放到硬盤上。
如果3000個用戶同時連上mysql,最小需要內存3000256KB=750M,最大需要內存300064MB=192G。
如果innodb_buffer_pool_size是40GB,給操作系統分配4G,給連接使用的最大內存不到20G,如果連接過多,使用的內存超過20G,將會產生磁盤SWAP,此時將會影響性能。連接數過高,不一定帶來吞吐量的提高,而且可能占用更多的系統資源。
max_user_connections=2980
允許用戶連接的最大數量,剩余連接數用作DBA管理。
back_log=300
MySQL能夠暫存的連接數量。如果MySQL的連接數達到max_connections時,新的請求將會被存在堆棧中,等待某一連接釋放資源,該堆棧數量即back_log,如果等待連接的數量超過back_log,將被拒絕。
wait_timeout=300
指的是app應用通過jdbc連接mysql進行操作完畢后,空閑300秒后斷開,默認是28800,單位秒,即8個小時。
interactive_timeout=300
指的是mysql client連接mysql進行操作完畢后,空閑300秒后斷開,默認是28800,單位秒,即8個小時。
sort_buffer_size=4M
每個需要排序的線程分配該大小的一個緩沖區。增加該值可以加速ORDER BY 或 GROUP BY操作。
sort_buffer_size是一個connection級的參數,在每個connection(session)第一次需要使用這個buffer的時候,一次性分配設置的內存。
sort_buffer_size:并不是越大越好,由于是connection級的參數,過大的設置+高并發可能會耗盡系統的內存資源。例如:500個連接將會消耗500*sort_buffer_size(4M)=2G。
join_buffer_size=4M
用于表關聯緩存的大小,和sort_buffer_size一樣,該參數對應的分配內存也是每個連接獨享。
innodb參數
innodb相關參數
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_buffer_pool_size
innodb_thread_concurrency=64
此參數用來設置innodb線程的并發數,默認值為0表示不被限制,若要設置則與服務器的CPU核心數相同或是CPU的核心數的2倍,如果超過配置并發數,則需要排隊,這個值不宜太大,不然可能會導致線程之間鎖爭用嚴重,影響性能。
innodb_buffer_pool_size=40G
innodb存儲引擎buffer pool緩存大小,一般為物理內存的60%-70%。
內存大小直接反應數據庫的性能。
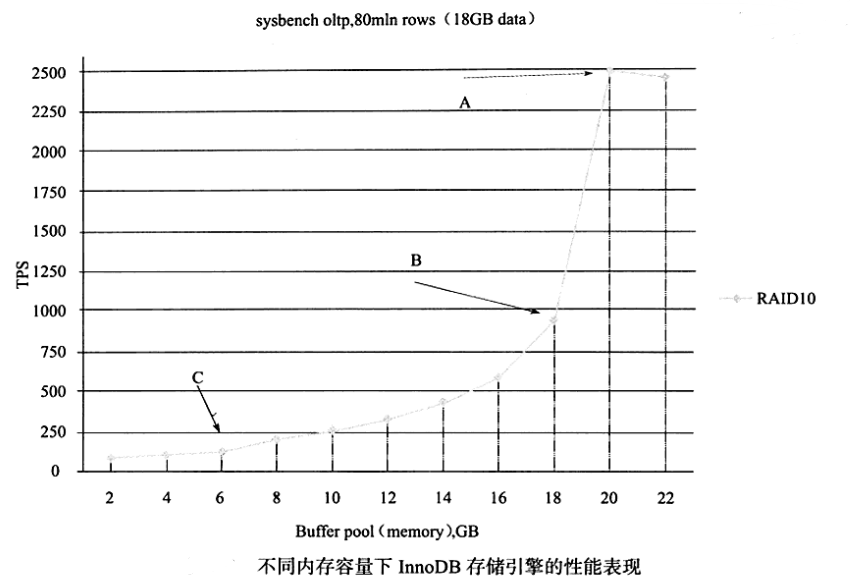
如何判斷當前數據庫的內存是否已經達到瓶頸了呢?
可以通過查看當前服務器的狀態,比較物理磁盤的讀取和內存讀取的比例來判斷緩沖池的命中率,通常InnoDB存儲引擎的緩沖池的命中率不應該小于99%,如:
mysql> show global status like ‘innodb%read%’\G;
當前服務器的狀態參數:
- Innodb_buffer_pool_reads:表示從物理磁盤讀取頁的次數
- Innodb_buffer_pool_read_ahead:預讀的次數
- Innodb_buffer_pool_read_ahead_evicted:預讀的頁,但是沒有被讀取就從緩沖池中被替換的頁的數量,一般用來判斷預讀的效率
- Innodb_buffer_pool_read_requests:從緩沖池中讀取頁的次數
- Innodb_data_readsInnodb_rows_read:總共讀入的字節數
- Innodb_data_reads:發起讀取請求的次數,每次讀取可能需要讀取多個頁
以下公式可以計算各種對緩沖池的操作:

innodb_lock_wait_timeout=10
行鎖鎖定時間,默認50s,根據公司業務定,沒有標準值。
innodb_flush_log_at_trx_commit=1
binlog參數
binlog相關參數
https://dev.mysql.com/doc/refman/8.0/en/replication-options-binary-log.html
sync_binlog=1
Mysql 8.0新特性詳解
建議使用8.0.17及之后的版本,更新的內容比較多。
參考文檔
添加棄用和刪除的特性:https://dev.mysql.com/doc/refman/8.0/en/mysql-nutshell.html
添加棄用和刪除的參數:https://dev.mysql.com/doc/refman/8.0/en/added-deprecated-removed.html
Mysql8 InnoDB架構:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
1、新增降序索引
MySQL在語法上很早就已經支持降序索引,但實際上創建的仍然是升序索引,如下MySQL 5.7 所示,c2字段降序,但是從show create table看c2仍然是升序。8.0可以看到,c2字段降序。只有Innodb存儲引擎支持降序索引。
# ====MySQL 5.7演示====
mysql> create table t1(c1 int,c2 int,index idx_c1_c2(c1,c2 desc));
Query OK, 0 rows affected (0.04 sec)mysql> insert into t1 (c1,c2) values(1, 10),(2,50),(3,50),(4,100),(5,80);
Query OK, 5 rows affected (0.02 sec)mysql> show create table t1\G
*************************** 1. row ***************************Table: t1
Create Table: CREATE TABLE `t1` (`c1` int(11) DEFAULT NULL,`c2` int(11) DEFAULT NULL,KEY `idx_c1_c2` (`c1`,`c2`) --注意這里,c2字段是升序
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)mysql> explain select * from t1 order by c1,c2 desc; --5.7也會使用索引,但是Extra字段里有filesort文件排序
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)# ====MySQL 8.0演示====
mysql> create table t1(c1 int,c2 int,index idx_c1_c2(c1,c2 desc));
Query OK, 0 rows affected (0.02 sec)mysql> insert into t1 (c1,c2) values(1, 10),(2,50),(3,50),(4,100),(5,80);
Query OK, 5 rows affected (0.02 sec)mysql> show create table t1\G
*************************** 1. row ***************************Table: t1
Create Table: CREATE TABLE `t1` (`c1` int DEFAULT NULL,`c2` int DEFAULT NULL,KEY `idx_c1_c2` (`c1`,`c2` DESC) --注意這里的區別,降序索引生效了
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)mysql> explain select * from t1 order by c1,c2 desc; --Extra字段里沒有filesort文件排序,充分利用了降序索引
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t1 order by c1 desc,c2; --Extra字段里有Backward index scan,意思是反向掃描索引;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Backward index scan; Using index |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t1 order by c1 desc,c2 desc; --Extra字段里有filesort文件排序,排序必須按照每個字段定義的排序或按相反順序才能充分利用索引
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t1 order by c1,c2; --Extra字段里有filesort文件排序,排序必須按照每個字段定義的排序或按相反順序才能充分利用索引
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | t1 | NULL | index | NULL | idx_c1_c2 | 10 | NULL | 1 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)
2、group by 不再隱式排序
mysql 8.0 對于group by 字段不再隱式排序,如需要排序,必須顯式加上order by 子句。
# ====MySQL 5.7演示====
mysql> select count(*),c2 from t1 group by c2;
+----------+------+
| count(*) | c2 |
+----------+------+
| 1 | 10 |
| 2 | 50 |
| 1 | 80 |
| 1 | 100 |
+----------+------+
4 rows in set (0.00 sec)# ====MySQL 8.0演示====
mysql> select count(*),c2 from t1 group by c2; --8.0版本group by不再默認排序
+----------+------+
| count(*) | c2 |
+----------+------+
| 1 | 10 |
| 2 | 50 |
| 1 | 100 |
| 1 | 80 |
+----------+------+
4 rows in set (0.00 sec)mysql> select count(*),c2 from t1 group by c2 order by c2; --8.0版本group by不再默認排序,需要自己加order by
+----------+------+
| count(*) | c2 |
+----------+------+
| 1 | 10 |
| 2 | 50 |
| 1 | 80 |
| 1 | 100 |
+----------+------+
4 rows in set (0.00 sec)
3、增加隱藏索引
使用 invisible 關鍵字在創建表或者進行表變更中設置索引為隱藏索引。索引隱藏只是不可見,但是數據庫后臺還是會維護隱藏索引的,在查詢時優化器不使用該索引,即使用force index,優化器也不會使用該索引,同時優化器也不會報索引不存在的錯誤,因為索引仍然真實存在,必要時,也可以把隱藏索引快速恢復成可見。注意,主鍵不能設置為 invisible。
軟刪除就可以使用隱藏索引,比如我們覺得某個索引沒用了,刪除后發現這個索引在某些時候還是有用的,于是又得把這個索引加回來,如果表數據量很大的話,這種操作耗費時間是很多的,成本很高,這時,我們可以將索引先設置為隱藏索引,等到真的確認索引沒用了再刪除。
# 創建t2表,里面的c2字段為隱藏索引
mysql> create table t2(c1 int, c2 int, index idx_c1(c1), index idx_c2(c2) invisible);
Query OK, 0 rows affected (0.02 sec)mysql> show index from t2\G
*************************** 1. row ***************************Table: t2Non_unique: 1Key_name: idx_c1Seq_in_index: 1Column_name: c1Collation: ACardinality: 0Sub_part: NULLPacked: NULLNull: YESIndex_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
*************************** 2. row ***************************Table: t2Non_unique: 1Key_name: idx_c2Seq_in_index: 1Column_name: c2Collation: ACardinality: 0Sub_part: NULLPacked: NULLNull: YESIndex_type: BTREEComment:
Index_comment: Visible: NO --隱藏索引不可見Expression: NULL
2 rows in set (0.00 sec)mysql> explain select * from t2 where c1=1;
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t2 | NULL | ref | idx_c1 | idx_c1 | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t2 where c2=1; --隱藏索引c2不會被使用
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> select @@optimizer_switch\G --查看各種參數
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on
1 row in set (0.00 sec)mysql> set session optimizer_switch="use_invisible_indexes=on"; ----在會話級別設置查詢優化器可以看到隱藏索引
Query OK, 0 rows affected (0.00 sec)mysql> select @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=on,skip_scan=on,hash_join=on
1 row in set (0.00 sec)mysql> explain select * from t2 where c2=1;
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t2 | NULL | ref | idx_c2 | idx_c2 | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)mysql> alter table t2 alter index idx_c2 visible;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> alter table t2 alter index idx_c2 invisible;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
4、新增函數索引
之前我們知道,如果在查詢中加入了函數,索引不生效,所以MySQL 8引入了函數索引,MySQL 8.0.13開始支持在索引中使用函數(表達式)的值。
函數索引基于虛擬列功能實現,在MySQL中相當于新增了一個列,這個列會根據你的函數來進行計算結果,然后使用函數索引的時候就會用這個計算后的列作為索引。
mysql> create table t3(c1 varchar(10),c2 varchar(10));
Query OK, 0 rows affected (0.02 sec)mysql> create index idx_c1 on t3(c1); --創建普通索引
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> create index func_idx on t3((UPPER(c2))); --創建一個大寫的函數索引
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> show index from t3\G
*************************** 1. row ***************************Table: t3Non_unique: 1Key_name: idx_c1Seq_in_index: 1Column_name: c1Collation: ACardinality: 0Sub_part: NULLPacked: NULLNull: YESIndex_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
*************************** 2. row ***************************Table: t3Non_unique: 1Key_name: func_idxSeq_in_index: 1Column_name: NULLCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: YESIndex_type: BTREEComment:
Index_comment: Visible: YESExpression: upper(`c2`) --函數表達式
2 rows in set (0.00 sec)mysql> explain select * from t3 where upper(c1)='ZHUGE';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t3 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)mysql> explain select * from t3 where upper(c2)='ZHUGE'; --使用了函數索引
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t3 | NULL | ref | func_idx | func_idx | 43 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
5、innodb存儲引擎select for update跳過鎖等待
對于select … for share(8.0新增加查詢共享鎖的語法)或 select … for update, 在語句后面添加NOWAIT、SKIP LOCKED語法可以跳過鎖等待,或者跳過鎖定。
在5.7及之前的版本,select…for update,如果獲取不到鎖,會一直等待,直到innodb_lock_wait_timeout超時。
在8.0版本,通過添加nowait,skip locked語法,能夠立即返回。如果查詢的行已經加鎖,那么nowait會立即報錯返回,而skip locked也會立即返回,只是返回的結果中不包含被鎖定的行。
應用場景比如查詢余票記錄,如果某些記錄已經被鎖定,用skip locked可以跳過被鎖定的記錄,只返回沒有鎖定的記錄,提高系統性能。
# 先打開一個session1:
mysql> select * from t1;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 10 |
| 2 | 50 |
| 3 | 50 |
| 4 | 100 |
| 5 | 80 |
+------+------+
5 rows in set (0.00 sec)mysql> begin;
Query OK, 0 rows affected (0.00 sec)mysql> update t1 set c2 = 60 where c1 = 2; --鎖定第二條記錄
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0# 另外一個session2:
mysql> select * from t1 where c1 = 2 for update; --等待超時
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> select * from t1 where c1 = 2 for update nowait; --查詢立即返回
ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set.mysql> select * from t1 for update skip locked; --查詢立即返回,過濾掉了第二行記錄
+------+------+
| c1 | c2 |
+------+------+
| 1 | 10 |
| 3 | 50 |
| 4 | 100 |
| 5 | 80 |
+------+------+
4 rows in set (0.00 sec)
6、新增innodb_dedicated_server自適應參數
能夠讓InnoDB根據服務器上檢測到的內存大小自動配置innodb_buffer_pool_size,innodb_log_file_size等參數,會盡可能多的占用系統可占用資源提升性能。解決非專業人員安裝數據庫后默認初始化數據庫參數默認值偏低的問題,前提是服務器是專用來給MySQL數據庫的,如果還有其他軟件或者資源或者多實例MySQL使用,不建議開啟該參數,不然會影響其它程序。
mysql> show variables like '%innodb_dedicated_server%'; --默認是OFF關閉,修改為ON打開
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_dedicated_server | OFF |
+-------------------------+-------+
1 row in set (0.02 sec)
7、死鎖檢查控制
MySQL 8.0 (MySQL 5.7.15)增加了一個新的動態變量 innodb_deadlock_detect,用于控制系統是否執行 InnoDB 死鎖檢查,默認是打開的。死鎖檢測會耗費數據庫性能的,對于高并發的系統,我們可以關閉死鎖檢測功能,提高系統性能。但是我們要確保系統極少情況會發生死鎖,同時要將鎖等待超時參數調小一點,以防出現死鎖等待過久的情況。
mysql> show variables like '%innodb_deadlock_detect%'; --默認是打開的
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_deadlock_detect | ON |
+------------------------+-------+
1 row in set, 1 warning (0.01 sec)
8、undo文件不再使用系統表空間
默認創建2個UNDO表空間,不再使用系統表空間。


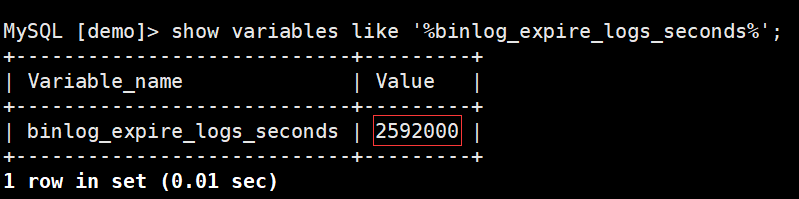
9、 binlog日志過期時間精確到秒
之前是天,并且參數名稱發生變化. 在8.0版本之前,binlog日志過期時間設置都是設置expire_logs_days參數,而在8.0版本中,MySQL默認使用binlog_expire_logs_seconds參數。
10、窗口函數(Window Functions):也稱分析函數
從 MySQL 8.0 開始,新增了一個叫窗口函數的概念,它可以用來實現若干新的查詢方式。窗口函數與 SUM()、COUNT() 這種分組聚合函數類似,在聚合函數后面加上over()就變成窗口函數了,在括號里可以加上partition by等分組關鍵字指定如何分組,窗口函數即便分組也不會將多行查詢結果合并為一行,而是將結果放回多行當中,即窗口函數不需要再使用 GROUP BY。
# 創建一張賬戶余額表
CREATE TABLE `account_channel` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '姓名',`channel` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '賬戶渠道',`balance` int DEFAULT NULL COMMENT '余額',PRIMARY KEY (`id`)
) ENGINE=InnoDB;# 插入一些示例數據
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('1', 'zhuge', 'wx', '100');
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('2', 'zhuge', 'alipay', '200');
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('3', 'zhuge', 'yinhang', '300');
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('4', 'lilei', 'wx', '200');
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('5', 'lilei', 'alipay', '100');
INSERT INTO `account_channel` (`id`, `name`, `channel`, `balance`) VALUES ('6', 'hanmeimei', 'wx', '500');mysql> select * from account_channel;
+----+-----------+---------+---------+
| id | name | channel | balance |
+----+-----------+---------+---------+
| 1 | zhuge | wx | 100 |
| 2 | zhuge | alipay | 200 |
| 3 | zhuge | yinhang | 300 |
| 4 | lilei | wx | 200 |
| 5 | lilei | alipay | 100 |
| 6 | hanmeimei | wx | 500 |
+----+-----------+---------+---------+
6 rows in set (0.00 sec)mysql> select name,sum(balance) from account_channel group by name;
+-----------+--------------+
| name | sum(balance) |
+-----------+--------------+
| zhuge | 600 |
| lilei | 300 |
| hanmeimei | 500 |
+-----------+--------------+
3 rows in set (0.00 sec)# 在聚合函數后面加上over()就變成分析函數了,后面可以不用再加group by制定分組,因為在over里已經用partition關鍵字指明了如何分組計算,這種可以保留原有表數據的結構,不會像分組聚合函數那樣每組只返回一條數據
mysql> select name,channel,balance,sum(balance) over(partition by name) as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500 |
| lilei | wx | 200 | 300 |
| lilei | alipay | 100 | 300 |
| zhuge | wx | 100 | 600 |
| zhuge | alipay | 200 | 600 |
| zhuge | yinhang | 300 | 600 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)mysql> select name,channel,balance,sum(balance) over(partition by name order by balance) as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500 |
| lilei | alipay | 100 | 100 |
| lilei | wx | 200 | 300 |
| zhuge | wx | 100 | 100 |
| zhuge | alipay | 200 | 300 |
| zhuge | yinhang | 300 | 600 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)# over()里如果不加條件,則默認使用整個表的數據做運算
mysql> select name,channel,balance,sum(balance) over() as sum_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | sum_balance |
+-----------+---------+---------+-------------+
| zhuge | wx | 100 | 1400 |
| zhuge | alipay | 200 | 1400 |
| zhuge | yinhang | 300 | 1400 |
| lilei | wx | 200 | 1400 |
| lilei | alipay | 100 | 1400 |
| hanmeimei | wx | 500 | 1400 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)mysql> select name,channel,balance,avg(balance) over(partition by name) as avg_balance from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | avg_balance |
+-----------+---------+---------+-------------+
| hanmeimei | wx | 500 | 500.0000 |
| lilei | wx | 200 | 150.0000 |
| lilei | alipay | 100 | 150.0000 |
| zhuge | wx | 100 | 200.0000 |
| zhuge | alipay | 200 | 200.0000 |
| zhuge | yinhang | 300 | 200.0000 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)專用窗口函數:
- 序號函數:ROW_NUMBER()、RANK()、DENSE_RANK()
- 分布函數:PERCENT_RANK()、CUME_DIST()
- 前后函數:LAG()、LEAD()
- 頭尾函數:FIRST_VALUE()、LAST_VALUE()
- 其它函數:NTH_VALUE()、NTILE()
# 按照balance字段排序,展示序號
mysql> select name,channel,balance,row_number() over(order by balance) as row_number1 from account_channel;
+-----------+---------+---------+-------------+
| name | channel | balance | row_number1 |
+-----------+---------+---------+-------------+
| zhuge | wx | 100 | 1 |
| lilei | alipay | 100 | 2 |
| zhuge | alipay | 200 | 3 |
| lilei | wx | 200 | 4 |
| zhuge | yinhang | 300 | 5 |
| hanmeimei | wx | 500 | 6 |
+-----------+---------+---------+-------------+
6 rows in set (0.00 sec)# 按照balance字段排序,first_value()選出排第一的余額
mysql> select name,channel,balance,first_value(balance) over(order by balance) as first1 from account_channel;
+-----------+---------+---------+--------+
| name | channel | balance | first1 |
+-----------+---------+---------+--------+
| zhuge | wx | 100 | 100 |
| lilei | alipay | 100 | 100 |
| zhuge | alipay | 200 | 100 |
| lilei | wx | 200 | 100 |
| zhuge | yinhang | 300 | 100 |
| hanmeimei | wx | 500 | 100 |
+-----------+---------+---------+--------+
6 rows in set (0.01 sec)
11、默認字符集由latin1變為utf8mb4
在8.0版本之前,默認字符集為latin1,utf8指向的是utf8mb3,8.0版本默認字符集為utf8mb4,utf8默認指向的也是utf8mb4。
12、MyISAM系統表全部換成InnoDB表
將系統表(mysql)和數據字典表全部改為InnoDB存儲引擎,默認的MySQL實例將不包含MyISAM表,除非手動創建MyISAM表。
13、元數據存儲變動
MySQL 8.0刪除了之前版本的元數據文件,例如表結構.frm等文件,全部集中放入mysql.ibd文件里。可以看見下圖test庫文件夾里已經沒有了frm文件。


14、自增變量持久化
在8.0之前的版本,自增主鍵AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重啟后,會重置AUTO_INCREMENT=max(primary key)+1,這種現象在某些情況下會導致業務主鍵沖突或者其他難以發現的問題。自增主鍵重啟重置的問題很早就被發現(https://bugs.mysql.com/bug.php?id=199),一直到8.0才被解決,8.0版本將會對AUTO_INCREMENT值進行持久化,MySQL重啟后,該值將不會改變。
# ====MySQL 5.7演示====
mysql> create table t(id int auto_increment primary key,c1 varchar(20));
Query OK, 0 rows affected (0.03 sec)mysql> insert into t(c1) values('zhuge1'),('zhuge2'),('zhuge3');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge3 |
+----+--------+
3 rows in set (0.00 sec)mysql> delete from t where id = 3;
Query OK, 1 row affected (0.01 sec)mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
+----+--------+
2 rows in set (0.00 sec)mysql> exit;
Bye# 重啟MySQL服務,并重新連接MySQL
mysql> insert into t(c1) values('zhuge4');
Query OK, 1 row affected (0.01 sec)mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge4 |
+----+--------+
3 rows in set (0.00 sec)mysql> update t set id = 5 where c1 = 'zhuge1';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 3 | zhuge4 |
| 5 | zhuge1 |
+----+--------+
3 rows in set (0.00 sec)mysql> insert into t(c1) values('zhuge5');
Query OK, 1 row affected (0.01 sec)mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 3 | zhuge4 |
| 4 | zhuge5 |
| 5 | zhuge1 |
+----+--------+
4 rows in set (0.00 sec)mysql> insert into t(c1) values('zhuge6');
ERROR 1062 (23000): Duplicate entry '5' for key 'PRIMARY'# ====MySQL 8.0演示====
mysql> create table t(id int auto_increment primary key,c1 varchar(20));
Query OK, 0 rows affected (0.02 sec)mysql> insert into t(c1) values('zhuge1'),('zhuge2'),('zhuge3');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 3 | zhuge3 |
+----+--------+
3 rows in set (0.00 sec)mysql> delete from t where id = 3;
Query OK, 1 row affected (0.01 sec)mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
+----+--------+
2 rows in set (0.00 sec)mysql> exit;
Bye
[root@localhost ~]# service mysqld restart
Shutting down MySQL.... SUCCESS!
Starting MySQL... SUCCESS! # 重新連接MySQL
mysql> insert into t(c1) values('zhuge4');
Query OK, 1 row affected (0.00 sec)mysql> select * from t; --生成的id為4,不是3
+----+--------+
| id | c1 |
+----+--------+
| 1 | zhuge1 |
| 2 | zhuge2 |
| 4 | zhuge4 |
+----+--------+
3 rows in set (0.00 sec)mysql> update t set id = 5 where c1 = 'zhuge1';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 4 | zhuge4 |
| 5 | zhuge1 |
+----+--------+
3 rows in set (0.00 sec)mysql> insert into t(c1) values('zhuge5');
Query OK, 1 row affected (0.00 sec)mysql> select * from t;
+----+--------+
| id | c1 |
+----+--------+
| 2 | zhuge2 |
| 4 | zhuge4 |
| 5 | zhuge1 |
| 6 | zhuge5 |
+----+--------+
4 rows in set (0.00 sec)
15、DDL原子化
InnoDB表的DDL支持事務完整性,要么成功要么回滾。
MySQL 8.0 開始支持原子 DDL 操作,其中與表相關的原子 DDL 只支持 InnoDB 存儲引擎。一個原子 DDL 操作內容包括:更新數據字典,存儲引擎層的操作,在 binlog 中記錄 DDL 操作。支持與表相關的 DDL:數據庫、表空間、表、索引的 CREATE、ALTER、DROP 以及 TRUNCATE TABLE。支持的其它 DDL :存儲程序、觸發器、視圖、UDF 的 CREATE、DROP 以及ALTER 語句。支持賬戶管理相關的 DDL:用戶和角色的 CREATE、ALTER、DROP 以及適用的 RENAME等等。
# MySQL 5.7
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| account |
| actor |
| employee |
| film |
| film_actor |
| leaf_id |
| t1 |
| test_innodb |
| test_myisam |
| test_order_id |
+----------------+
10 rows in set (0.01 sec)mysql> drop table t1,t2; //刪除表報錯不會回滾,t1表會被刪除
ERROR 1051 (42S02): Unknown table 'test.t2'
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| account |
| actor |
| employee |
| film |
| film_actor |
| leaf_id |
| test_innodb |
| test_myisam |
| test_order_id |
+----------------+
9 rows in set (0.00 sec)# MySQL 8.0
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| account |
| actor |
| employee |
| film |
| film_actor |
| leaf_id |
| t1 |
| test_innodb |
| test_myisam |
| test_order_id |
+----------------+
10 rows in set (0.00 sec)mysql> drop table t1,t2; //刪除表報錯會回滾,t1表依然還在
ERROR 1051 (42S02): Unknown table 'test.t2'
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| account |
| actor |
| employee |
| film |
| film_actor |
| leaf_id |
| t1 |
| test_innodb |
| test_myisam |
| test_order_id |
+----------------+
10 rows in set (0.00 sec)
16、參數修改持久化
MySQL 8.0版本支持在線修改全局參數并持久化,通過加上PERSIST關鍵字,可以將修改的參數持久化到新的配置文件(mysqld-auto.cnf)中,重啟MySQL時,可以從該配置文件獲取到最新的配置參數。set global 設置的變量參數在mysql重啟后會失效。
mysql> set persist innodb_lock_wait_timeout=25;
系統會在數據目錄下生成一個包含json格式的mysqld-auto.cnf 的文件,格式化后如下所示,當my.cnf 和mysqld-auto.cnf 同時存在時,后者具有更高優先級。
{"Version": 1,"mysql_server": {"innodb_lock_wait_timeout": {"Value": "25","Metadata": {"Timestamp": 1675290252103863,"User": "root","Host": "localhost"}}}
}



Excel)

)




)
)




)



