目錄
什么是梯度增強特征選擇(GBFS)
為什么 GBM 適合做特征選擇
GBFS 的一般步驟
代碼示例
什么是梯度增強特征選擇(GBFS)
GBFS 并非一個像 Lasso 或隨機森林那樣有嚴格標準定義的獨立算法,而是一種基于梯度提升機(Gradient Boosting Machine, GBM)模型來進行特征選擇的思想和策略。
其核心思想是:利用訓練好的 GBM 模型(如 XGBoost, LightGBM, CatBoost)內置的特征重要性評分,來識別并選擇對預測目標最重要的特征子集
為什么 GBM 適合做特征選擇
-
內置的特征重要性(Feature Importance):大多數 GBM 實現都會自動計算特征重要性。最常見的兩種計算方式是:
- 基于分裂(Gain): 衡量一個特征在所有樹中被用于分裂時,所帶來的不純度(如基尼系數、均方誤差)減少的總和。這是最常用、最可靠的指標。
- 基于頻率(Frequency): 衡量一個特征在所有樹中被用作分裂點的次數。
-
強大的非線性擬合能力:GBM 能夠捕捉特征與目標之間復雜的非線性關系和交互效應,因此其評估出的特征重要性比一些線性模型(如 Lasso)更全面。
-
抗過擬合和魯棒性:通過集成多棵弱學習器(樹),GBM 對噪聲數據相對魯棒,其給出的特征重要性排序也更為穩定
GBFS 的一般步驟
- 訓練一個 GBM 模型:使用全部特征在訓練集上訓練一個梯度提升模型(如?
XGBRegressor?或?LGBMClassifier)。 - 獲取特征重要性:從訓練好的模型中提取每個特征的重要性分數。
- 排序和選擇:將特征按重要性分數從高到低排序。
- 確定閾值:選擇一個閾值來選擇特征。方法有:
- 選擇 Top-K 個特征:例如,只保留最重要的前 20 個特征。
- 重要性分數閾值:例如,只保留重要性分數大于平均值的特征。
- 遞歸消除:結合遞歸特征消除(RFE),逐步剔除最不重要的特征,通過交叉驗證來確定最佳特征數量
代碼示例
# 導入必要的庫
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier# 1. 加載數據
data = load_breast_cancer()
X, y = data.data, data.target
feature_names = data.feature_names# 查看數據形狀
print("原始特征維度:", X.shape) # (569, 30)# 2. 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 訓練一個XGBoost模型(使用所有特征)
model = XGBClassifier(random_state=42, use_label_encoder=False, eval_metric='logloss')
model.fit(X_train, y_train)# 4. 獲取特征重要性(基于Gain)
importance_scores = model.feature_importances_
# 創建一個(特征名:重要性分數)的字典,并排序
feat_imp_dict = dict(zip(feature_names, importance_scores))
sorted_feat_imp = sorted(feat_imp_dict.items(), key=lambda x: x[1], reverse=True)# 打印最重要的10個特征
print("\n最重要的10個特征:")
for feat, imp in sorted_feat_imp[:10]:print(f"{feat}: {imp:.4f}")
# worst concave points: 0.2856
# mean concave points: 0.2357
# worst perimeter: 0.1743
# worst radius: 0.0760
# worst area: 0.0570
# worst texture: 0.0217
# worst concavity: 0.0187
# perimeter error: 0.0186
# mean texture: 0.0144
# mean radius: 0.0128# 5. 可視化特征重要性(可選)
plt.figure(figsize=(10, 8))
indices = np.argsort(importance_scores)[::-1] # 按重要性降序排列的索引
plt.title('Feature Importances (XGBoost - Gain)')
plt.barh(range(len(indices)), importance_scores[indices], color='b', align='center')
plt.yticks(range(len(indices)), [feature_names[i] for i in indices])
plt.xlabel('Relative Importance')
plt.gca().invert_yaxis() # 讓最重要的特征顯示在頂部
plt.tight_layout()
plt.show()# 6. 進行特征選擇:我們選擇最重要的前10個特征
top_k = 10
selected_feature_indices = indices[:top_k] # 獲取最重要特征的索引X_train_selected = X_train[:, selected_feature_indices]
X_test_selected = X_test[:, selected_feature_indices]print(f"\n選擇后的特征維度:{X_train_selected.shape}") # (455, 10)# 7. 使用選擇后的特征重新訓練模型,驗證效果
model_selected = XGBClassifier(random_state=42, use_label_encoder=False, eval_metric='logloss')
model_selected.fit(X_train_selected, y_train)# 預測
y_pred_full = model.predict(X_test)
y_pred_selected = model_selected.predict(X_test_selected)# 評估準確率
acc_full = accuracy_score(y_test, y_pred_full)
acc_selected = accuracy_score(y_test, y_pred_selected)print(f"\n模型性能對比:")
print(f"使用所有特征的測試集準確率: {acc_full:.4f}") # 0.9561
print(f"使用Top-{top_k}個特征的測試集準確率: {acc_selected:.4f}") # 0.9561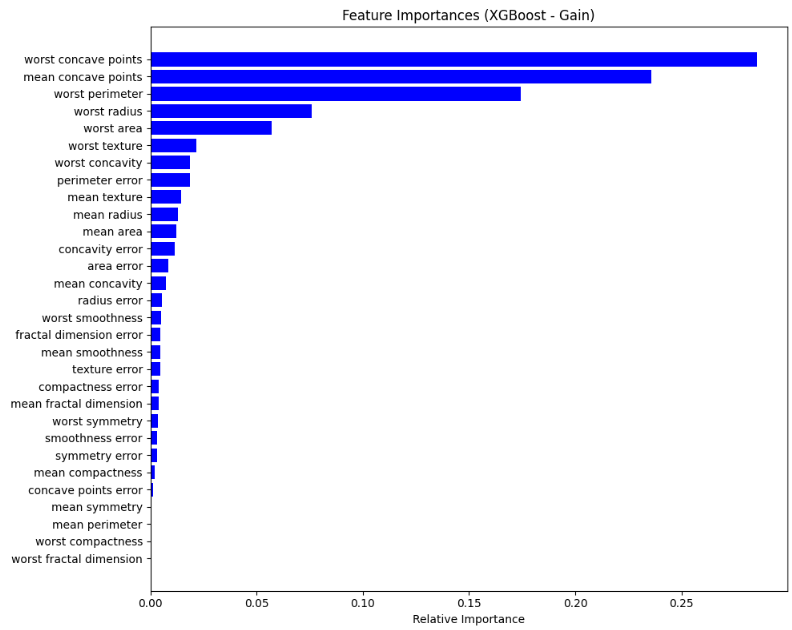



)





:Modbus RTU串口通信實現)




)
策略模式)

:SQL語句的執行之旅)

