引言:時序數據管理的挑戰與機遇
在工業4.0與物聯網技術深度融合的今天,全球設備產生的時序數據量正以指數級增長。據IDC預測,到2025年物聯網設備產生的數據將達79.4ZB,其中60%為時序數據。這類數據具有高頻采集(毫秒級)、維度豐富(單設備數百監測點)、嚴格有序(時間戳為核心)等特性,傳統關系型數據庫在處理時面臨寫入吞吐不足、存儲成本高企、查詢效率低下等痛點。
本文從大數據視角出發,結合國際權威測試數據,系統解析時序數據庫選型的核心維度,并重點闡述Apache IoTDB如何通過技術創新成為工業場景的首選解決方案。

文章目錄
- 引言:時序數據管理的挑戰與機遇
- 選型核心維度:性能、成本與生態的三重考量
- 1. 寫入性能:工業場景的生命線
- 2. 存儲效率:壓縮比決定TCO
- 3. 查詢響應:毫秒級決策的關鍵
- 4. 成本效益:每一美元的價值
- IoTDB技術架構解析:專為工業場景而生
- 1. 存儲引擎創新
- 2. 計算引擎優勢
- 3. 分布式架構設計
- 行業應用實踐:從中國制造到全球標桿
- 1. 能源電力場景
- 2. 智能制造場景
- 3. 軌道交通創新
- 選型實踐建議:從需求到落地的完整路徑
- 1. 需求分析階段
- 2. POC驗證要點
- 3. 部署策略
- 未來演進方向:時序數據與AI的深度融合
- 立即體驗IoTDB
選型核心維度:性能、成本與生態的三重考量
1. 寫入性能:工業場景的生命線
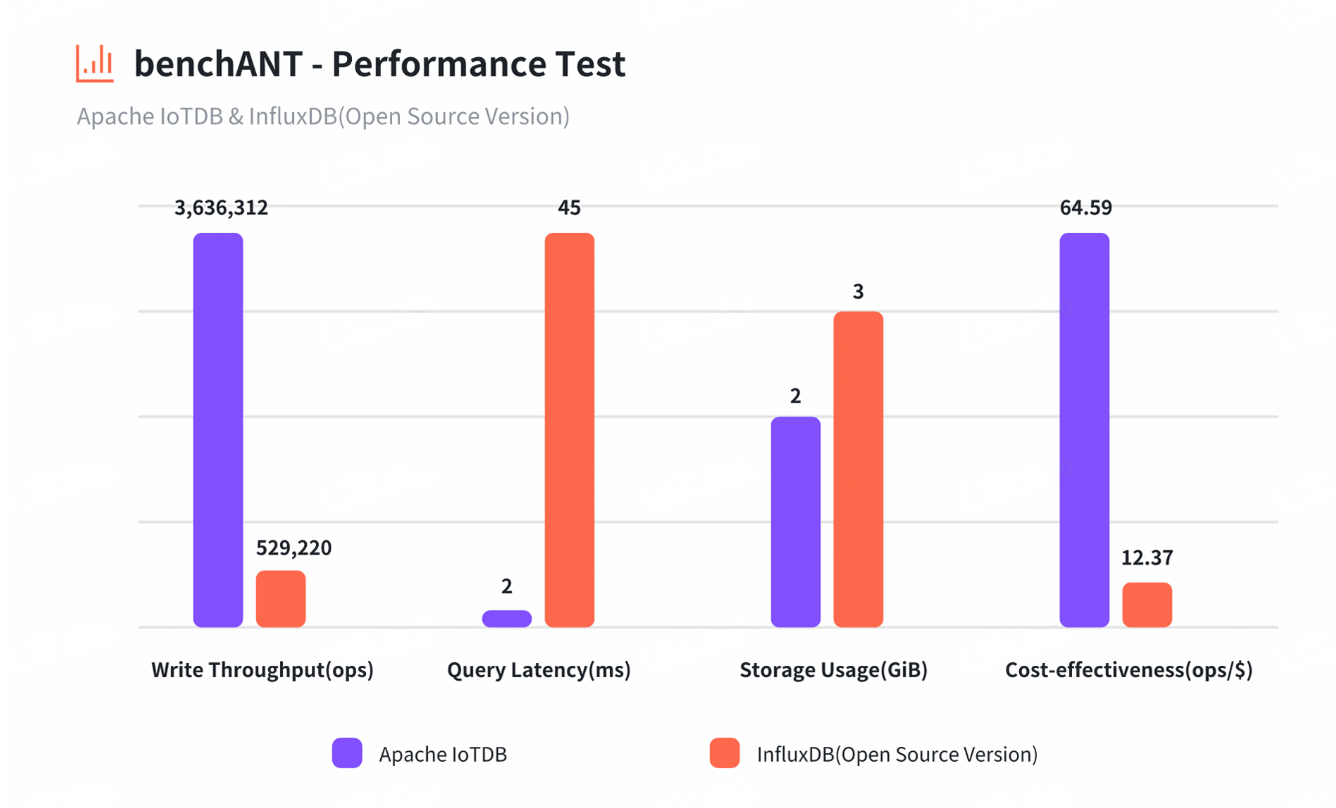
工業監控系統要求數據庫具備百萬級數據點/秒的單節點寫入能力。根據德國benchANT測試機構的權威報告,IoTDB在AWS云環境中實現:
- xSmall集群:142萬點/秒寫入吞吐,超InfluxDB 5.4倍
- Small集群:363萬點/秒寫入吞吐,超QuestDB 1.4倍
2. 存儲效率:壓縮比決定TCO
IoTDB自研的TsFile存儲格式通過自適應編碼算法實現驚人壓縮比:
- 某風電企業采用后存儲空間降至原方案的1/20
- benchANT測試顯示存儲占用僅2GiB,超TimescaleDB 35倍
3. 查詢響應:毫秒級決策的關鍵
在"1設備1測點1小時聚合查詢"場景中:
- IoTDB實現2ms級查詢延遲,超InfluxDB 96.5倍
- 支持百億級數據量的亞秒級響應
4. 成本效益:每一美元的價值
通過AWS硬件成本測算,IoTDB的單位美元操作數(Operations Per Cost)指標:
- 超VictoriaMetrics 22.2倍
- 超TimescaleDB 1.4倍
IoTDB技術架構解析:專為工業場景而生
1. 存儲引擎創新
TsFile三級存儲架構:
- 元數據層:設備樹狀結構管理,支持百萬級設備節點
- 數據層:時間分區+自適應索引,實現冷熱數據智能分層
- 索引層:動態構建查詢模式匹配索引
-- 示例:IoTDB設備建模
CREATE TIMESERIES root.factory.d1.sensor1 WITH DATATYPE=FLOAT, ENCODING=RLE
CREATE TIMESERIES root.factory.d1.sensor2 WITH DATATYPE=INT32, ENCODING=TS_2DIFF
2. 計算引擎優勢
- 流批一體:相同SQL支持歷史數據查詢與實時流處理
- 內置時序函數:提供滑動窗口、異常檢測等100+專用函數
- AI集成:支持庫內執行機器學習模型推理
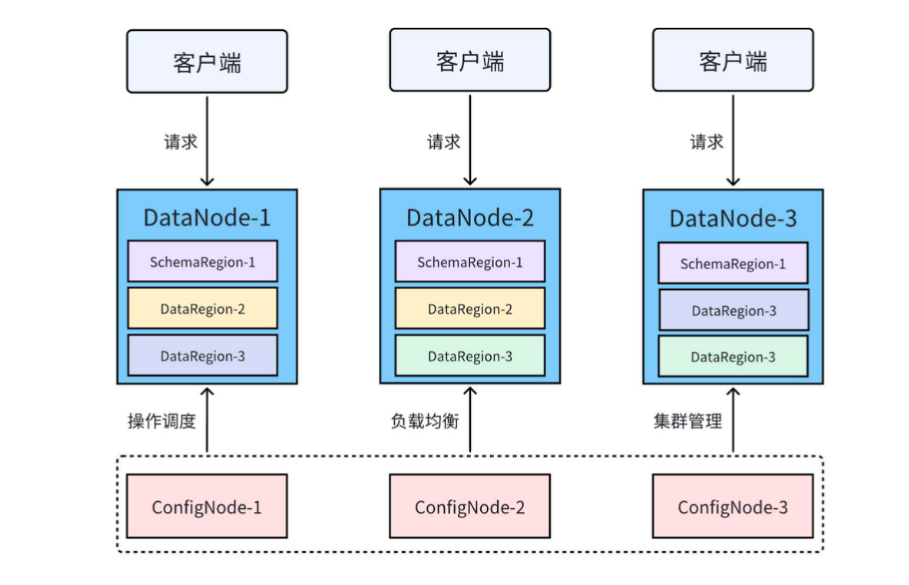
3. 分布式架構設計
3C3D獨特架構:
- ConfigNode集群:元數據管理(3節點高可用)
- DataNode集群:數據存儲與計算(線性擴展)
- 自動負載均衡:支持動態擴縮容與故障轉移
行業應用實踐:從中國制造到全球標桿
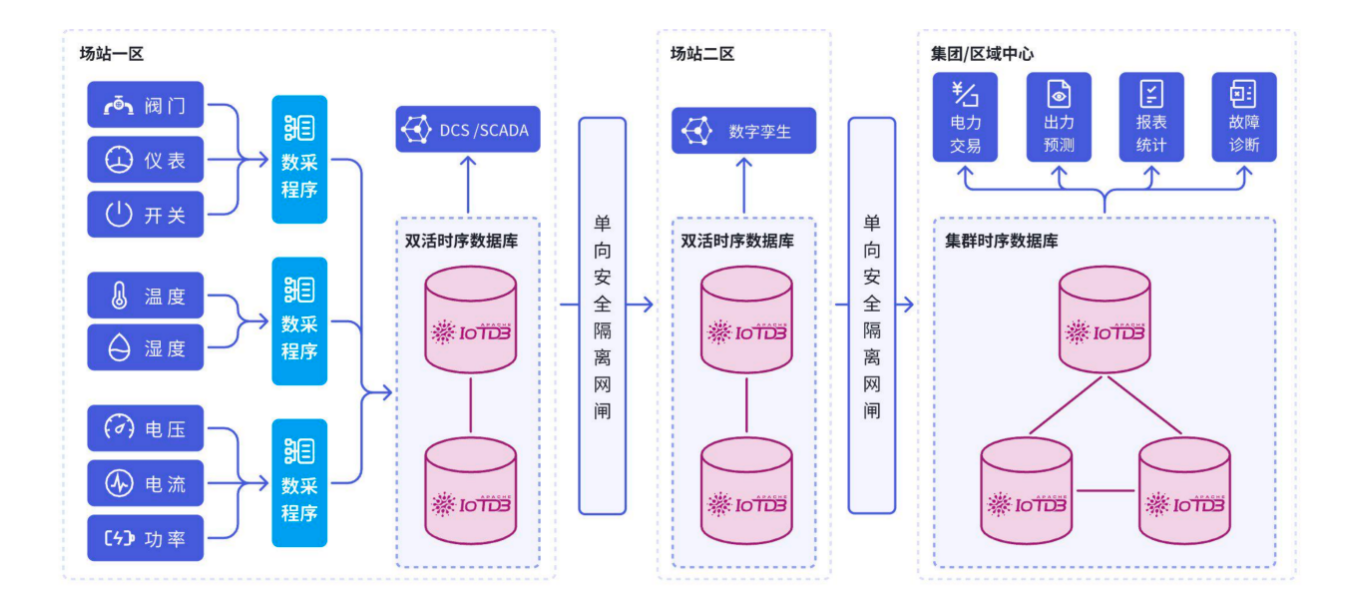
1. 能源電力場景
某省級電網采用IoTDB構建:
- 200萬+采集點,日新增數據50TB
- 故障追溯時間從小時級降至秒級
- 網閘穿透等工業特性保障數據安全
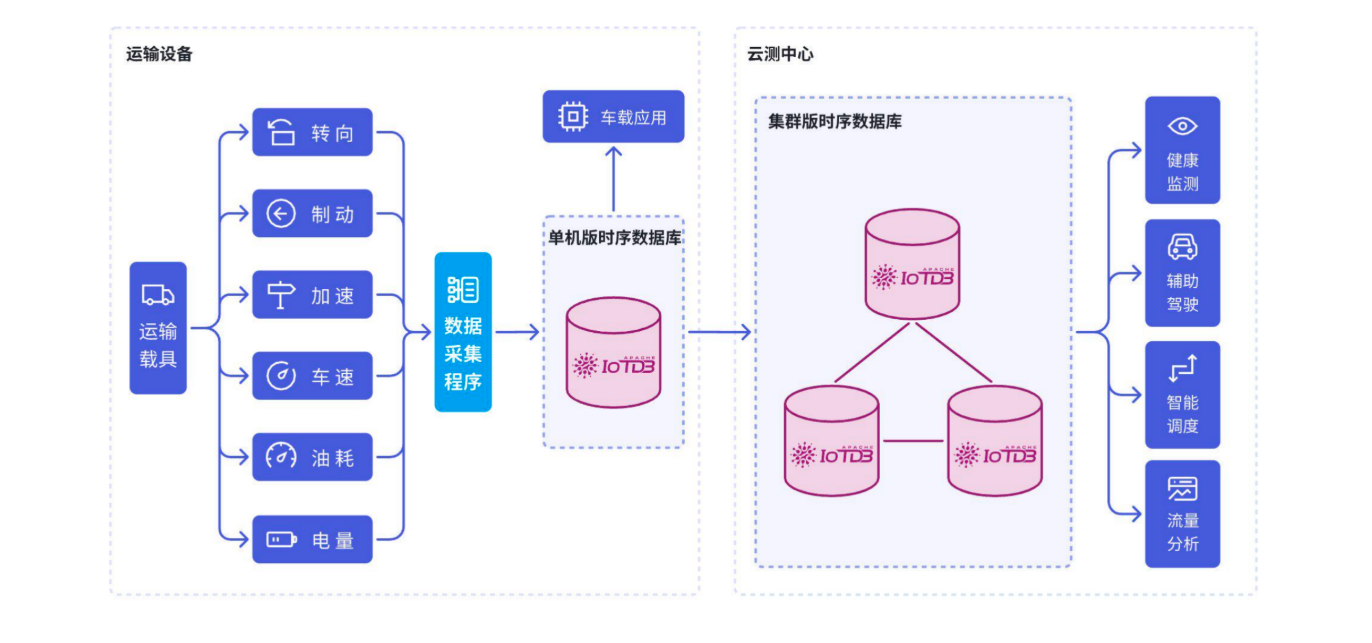
2. 智能制造場景
汽車工廠應用案例:
- 5000+設備,100ms采樣頻率
- 存儲成本降低82%
- 邊緣預處理減少90%網絡傳輸
3. 軌道交通創新
德國鐵路BZ-NEA項目:
- 燃料電池系統實時監控,滿足KRITIS數據保護法規
- OpenID Token授權機制實現細粒度權限控制
選型實踐建議:從需求到落地的完整路徑
1. 需求分析階段
- 數據規模評估:設備數×測點數×采樣頻率
- 查詢模式定義:實時監控(亞秒級)vs 歷史分析(批量查詢)
- SLA要求:可用性(99.99%)、延遲容忍度
2. POC驗證要點
# 示例:IoTDB壓力測試代碼
from iotdb import SessionPool
import numpy as npwith SessionPool(host='localhost', port=6667) as session:for _ in range(1000):timestamps = np.arange(1609459200000, 1609459200000+3600*1000, 1000)values = np.random.randn(len(timestamps))session.insert("root.factory.d1",{"sensor1": values},timestamps)
3. 部署策略
- 邊緣-云端協同:邊緣節點實時處理,云端集中分析
- 多級存儲規劃:熱數據(SSD)+ 溫數據(HDD)+ 冷數據(對象存儲)
- 災備方案:雙活部署+跨區域同步
未來演進方向:時序數據與AI的深度融合
IoTDB企業版(TimechoDB)已實現:
- 時序預測:LSTM模型集成,支持設備健康度預測
- 異常檢測:基于統計與深度學習的混合算法
- 知識圖譜:與COVESA數據服務平臺集成,實現語義推理
立即體驗IoTDB
訪問官方網站下載最新版本:
- 開源版:https://iotdb.apache.org/zh/Download/
- 企業版:https://timecho.com
通過本文解析可見,Apache IoTDB憑借其在工業場景的深度優化、超越國際競品的性能表現,以及完整的生態整合能力,已成為時序數據庫選型的標桿解決方案。無論是能源、制造還是交通領域,IoTDB都在幫助企業實現從數據采集到智能決策的全鏈路升級。
)
)






:指令與過濾器)


)


日志系統原理以及k8s集群日志采集過程)
 復雜度分析筆記)
![【光照】Unity中的[經驗模型]](http://pic.xiahunao.cn/【光照】Unity中的[經驗模型])

)
