前言:上一篇文章我們介紹了C++入門的一些基礎的語法,將了命名空間,缺省參數等。這篇文章我們就來介紹剩余的語法。

文章目錄
- 一,函數重載
- 二,引用
- 2.1引用的概念和定義
- 2.2引用的特性
- 2.3引用的引用場景
- 2.3.1做函數形參,修改形參影響實參
- 2.3.2 做函數形參時減少拷貝,提高效率
- 2.3.3 引用做返回值類型,修改返回對象,減少拷貝提高效率
- 2.4引用返回的坑
- 3.1 const引用
- 4.1指針和引用的關系
一,函數重載
函數重載:函數重載(Function Overloading)允許在同一個作用域內定義多個同名函數,但這些函數的參數列表必須不同(參數類型、數量或順序)。編譯器根據調用時傳遞的實參類型和數量選擇最匹配的函數版本。紫
舉個例子:
void func1(int x,int y)
{printf("%d %d",x,y);
}
void func2(double x,double y)
{printf("%lf %lf",x,y);
}
int main()
{int a = 10;int b = 20;double c = 10.0;double d = 20.0;//同樣在調用加法函數時調用的是不同的func函數//int類型的都調用func1func1(a,b);//double類型的就調用func2func2(c,d);return 0;
}在C語言的學習過程中,功能相同的函數由于它們的參數類型不同,我們就要再創建一個函數并用數字區別開來,從而保證編譯器能區分不同函數。本質上就是函數名不能相同。這種行為一方面增加了代碼的冗余度,另一方面很麻煩如果有很多不同的類型那么我們要根據不同類型創建函數從效率上來說是很低的。
C++的祖師爺本賈尼博士覺得這個問題很麻煩,每次調用都要指定func1,func2。說能不能搞一個func函數,且可以創建多個func函數函數內部的區別就是參數不同,這樣每次調用只用寫func就好了,具體比較什么類型的參數由func函數自己去匹配。
于是祖師爺就創造出了函數重載。
函數重載有幾種情況
情況一:參數類型不同
#include<iostream>
using namespace std;
int Add(int x,int y)
{cout<<"int Add(int x,int y)"<<endl;return x+y;
}
double Add(double x,double y)
{cout<<"double Add(double x,double y)"<<endl;return x+y;
}
int main()
{int a = 10;int b = 20;double c = 10.0;double d = 20.0;//Add進行了函數重載 同名函數參數與返回類型不同Add(a, b);Add(c, d);return 0;
}
情況二:參數順序不同
void func(int a,char b)
{cout<<"func(int a,char b)"<<endl;
}
void func(char a,int b)
{cout<<"func(char a,int b)"<<endl;
}
情況三:參數的個數不同
void func()
{cout<<"func()"<<endl;
}
void func(int a)
{cout<<"func(int a)"<<endl;
}
情況四:返回類型不同
void func(int x,int y)
{cout<<"func(int x,int y)"<<endl;
}
int func(int x,int y)
{return x+y;
}
注意,僅僅是返回值不同,參數相同的同名函數是不構成函數重載的。因為在調用函數的時候也分不清到底是調用有返回值的那個還是沒有返回值的那個。
情況五,在情況三的基礎上加上缺省值
void func()
{cout<<"func()"<<endl;
}
void func(int a=10)
{cout<<"func(int a)"<<endl;
}
int main()
{//傳指定參數就直接調用第二個func函數func(20);//不串參數這時編譯器就搞不清楚了 到底是第一個還是第二個func();return 0;
}
注意,這里如果不傳參調用func函數就會存在歧義,因為不傳參的話無參的func函數能調用,有缺省值的func函數也能調用,編譯不清楚要調用哪個所以會報錯。
特別注意:
- 僅僅是返回值不同,參數類型相同的同名函數不構成重載!
- 函數重載只發生在相同域或作用域里面,不同域的同名函數不叫函數重載!
二,引用
引用是C++中一個非常重要且使用的語法,且貫穿著整個C++的學習包括后面的STL部分都會使用到引用,所以學好引用是非常有必要的。
2.1引用的概念和定義
- 引用是C++中一種特殊的變量類型,本質是已存在變量的別名。它與指針類似,但更安全且語法更簡潔。引用必須在聲明時初始化,且無法重新綁定到其他變量。
- 在引用時使用的是C語言中的
&取地址運算符,使用方法是類型& 引用的別名=引用的對象舉個例子:
#include<iostream>
using namespace std;
int main()
{int a = 10;//給a取一個別名叫bint& b = a;//也可以給b取一個別名叫c 此時c也相當于是a的別名int& c = b;cout << "a=" << a << endl;++b;cout << "++b=" << a << endl;++c;cout << "++c=" << a << endl;cout<<"&a="<<&a<<endl;cout<<"&b="<<&b<<endl;cout<<"&c="<<&c<<endl;return 0;
}

通過運行結果可以看到對b和c進行加加改變的是a的值,并且它們的地址還是同一個。由此我們可以得出一個結論:引用沒有開新空間,引用就是給變量起了一個新的別名,對別名的操作就是對被引用對象的操作。
2.2引用的特性
- 引用在定義時必須初始化:告訴那個引用它是誰的別名,這就是對引用的初始化。
#include <iostream>
using namespace std;
int main()
{int p=2;
//這樣做是不行的 沒初始化會報錯
//int& rp;//至少要告訴rp引用的是誰 rp找不到引用對象就報錯int a = 1;
//對ra初始化 告訴ra它引用的是a
int& ra = a;
return 0;
}
- 一個變量可以有多個引用:就像人西游記中的孫悟空一樣,有齊天大圣,弼馬溫,猴哥等別名,變量也一樣可以有多個。
- 引用一旦引用了一個實體就不可能再引用其他的實體。就像一個狗子一般它一旦認定了一個主人就不會再認其他的主人了。
#include <iostream>
using namespace std;
int main()
{int a=10;int& b=a;int& c=a;int& d=a;//其中bcd都是a的別名cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;int p=100;d=p;//這里要注意p是賦值給d 而不是d是p的別名//因為d已經是a的別名了已經有一個實體了 它就不可能是另外一個變量的別名了return 0;
}
既然引用這么重要這么有用。那我們來看看引用的引用場景。
2.3引用的引用場景
2.3.1做函數形參,修改形參影響實參
回憶一下過去在C語言中,我們通過形參來影響實參是通過指針間接來控制的,比如:
#include<stdio.h>
void swap(int*x,int*y)
{int tmp=*x;*x=*y;*y=tmp;
}
int main()
{int a=10;int b=20;printf("交換前:\n");printf("a=%d\n",a);printf("b=%d\n",b);swap(&a,&b);printf("交換后:\n");printf("a=%d\n",a);printf("b=%d\n",b);return 0;
}
在C語言階段,我們通過形參影響實參的方式只有通過指針交換指針指向的內容從而實現實參的交換,那C++有了引用之后就可以使用引用來平替指針比如:
#include<iostream>
using namespace std;
void swap(int&x,int&y)
{int tmp=x;x=y;y=tmp;
}
int main()
{int a = 10;int b = 20;swap(a, b);cout << "a=" << a << endl;cout << "b=" << b << endl;return 0;
}
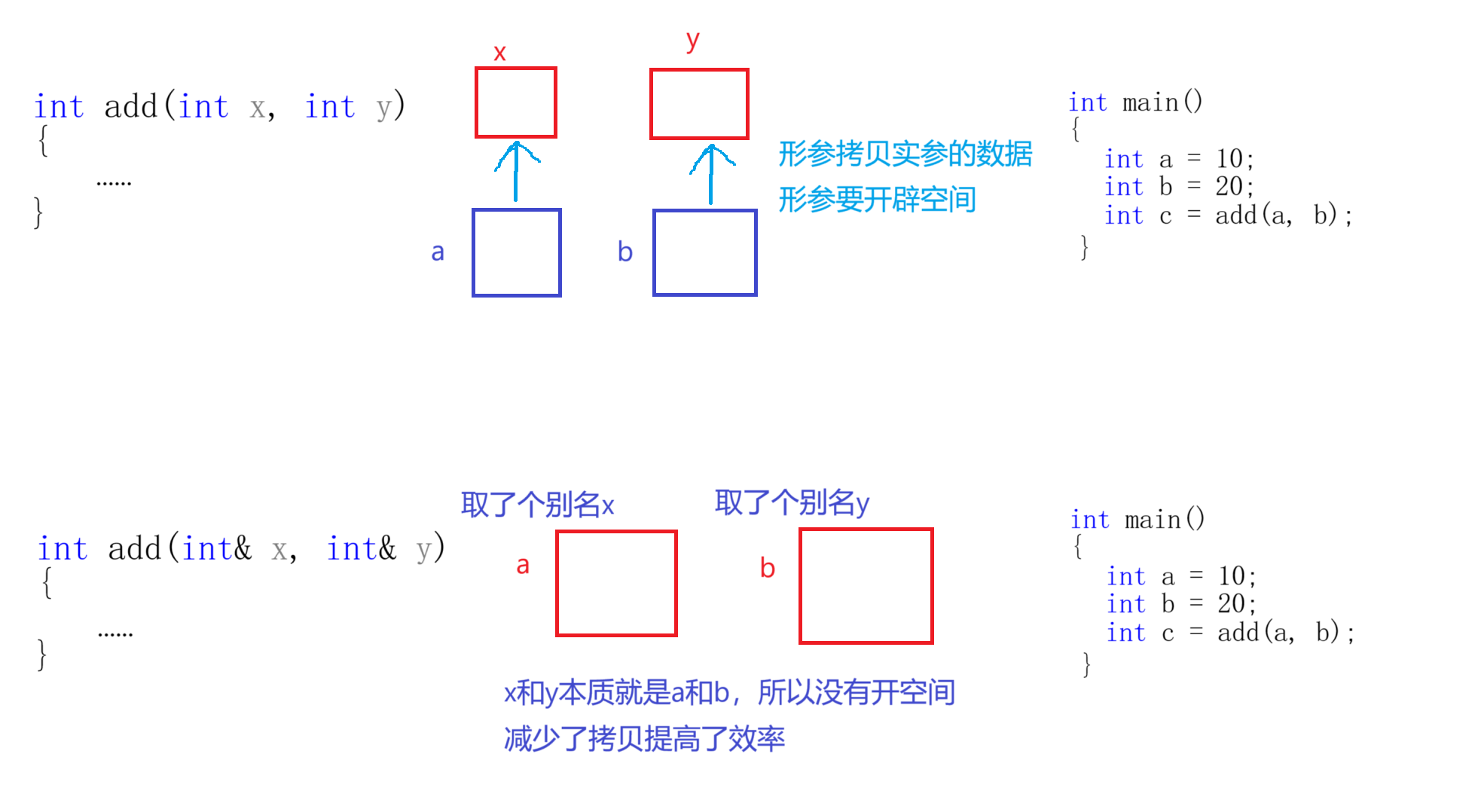
因為引用就是別名,形參中的x和y就是實參對應的別名,操作它們就相當于操作實參,所以形參的改變可以影響實參。
2.3.2 做函數形參時減少拷貝,提高效率
這個很好理解,舉個例子:
int add(int x,int y)
{return x+y;
}int main()
{int a=10;int b=20;int c=add(a,b);
}
上面這段代碼是我們在C語言段會寫的代碼,且在C語言階段我們知道形參是實參的臨時拷貝,形參會自己開空間所以形參與實參不一樣。但是C++不一樣:
int add(int&x,int&y)
{return x+y;
}
int main()
{int a=10;int b=20;int c=add(a,b);
}
2.3.3 引用做返回值類型,修改返回對象,減少拷貝提高效率
首先回顧一下我們在C語言階段學過的返回值類型有哪些?無非就是有返回值和沒有返回值。有返回值一般返回的是內置類型像int char double和struct定義的結構體。
比如:
int func()
{int ret=10;//......return ret;
}
int main()
{int x=func();//嘗試修改一下返回值func()=20;//10=20//被const修飾的tmp具有常量的屬性不能再被修改//const int tmp = 10;//tmp = 20;return 0;
}
通過上面的代碼我們來看看有返回值的傳值返回本質是什么?當我們嘗試去修改返回值的時候,這個時候編譯器就會報錯:
那什么情況下會報這種左操作數為左值的錯誤呢?將上面那一小段將20賦值給10以及給const變量賦值的代碼去編譯就會出現這種錯誤,因此我們可以推測出:傳值返回傳回來的是一個臨時變量(因為ret出了函數棧幀會銷毀 ),該變量不能被修改的原因可能是被const修飾了,具有了常量的屬性不能再被修改。

了解完了傳值返回,接著我們再來看看C++支持的傳引用返回:
#include<iostream>
using namespace std;
typedef struct SList
{int* arr;int size;int capacity;
}SL;void SLInit(SL& sl,int n=4)
{int* tmp = (int*)malloc(sizeof(int) * n);sl.arr = tmp;sl.size = 0;sl.capacity = 4;
}void SLPush(SL& sl,int x)
{if (sl.size == sl.capacity){sl.arr = (int*)realloc(sl.arr, 2 * sl.capacity);}sl.arr[sl.size] = x;sl.size++;
}int& SLAt(SL& sl, int i)
{assert(i < sl.size);return sl.arr[i];
}int main()
{SL sl1;SLInit(sl1);SLPush(sl1, 1);SLPush(sl1, 2);SLPush(sl1, 3);//傳引用返回可以對返回值進行修改SLAt(sl1, 0) += 2;return 0;先來分析一下
SLAt(sl1,0)+=2這段代碼:
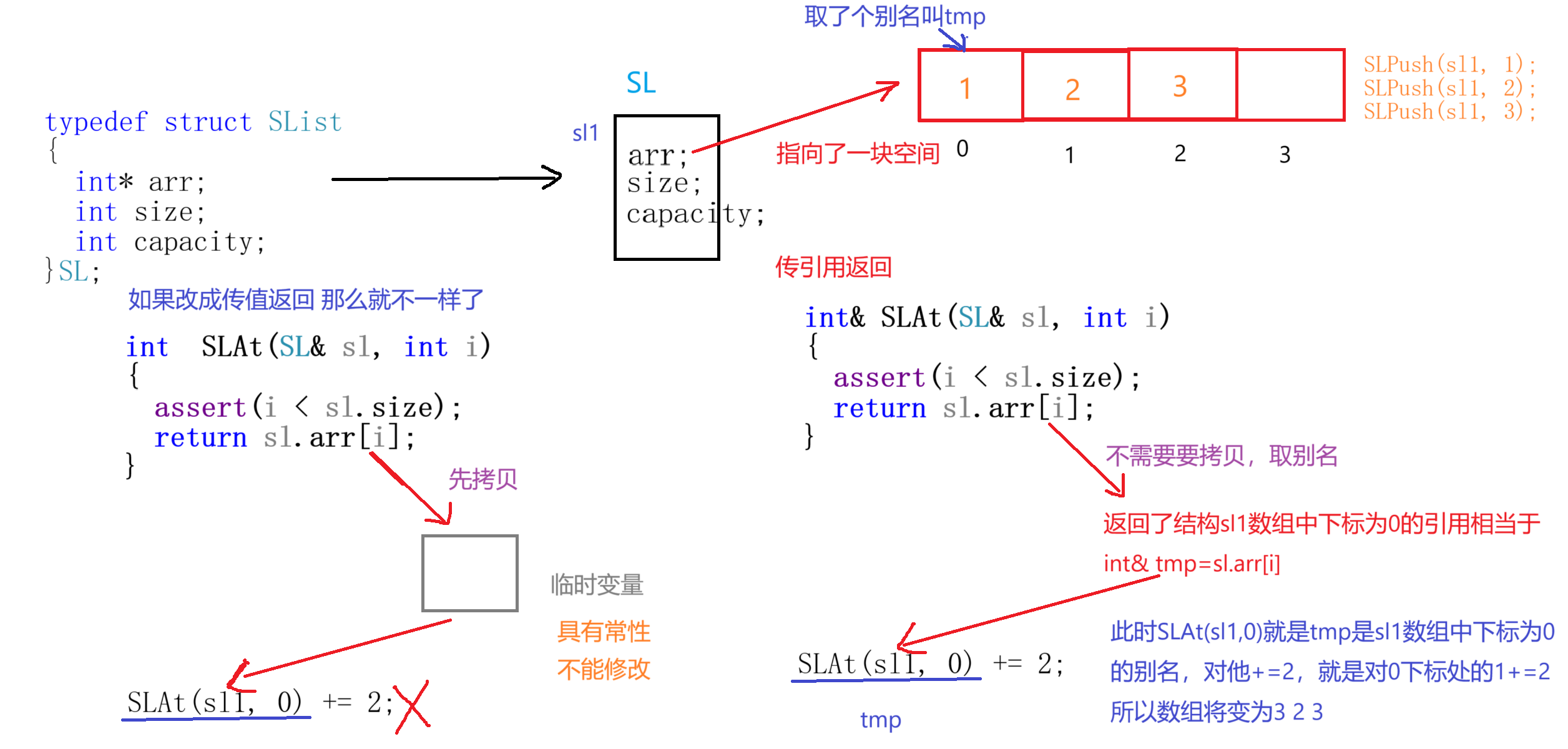
同樣在上面的分析中,我們看到傳值返回是要經過拷貝成臨時變量才返回的,而引用返回本質就是給變量取了一個別名不需要拷貝不會浪費空間極大的提高了效率。試想:如果返回的是一個占用內存很大的結構體,使用傳值返回或者做函數形參,拷貝的時候要花費多少空間?所以從節省空間這方面來說引用還是很香的!
2.4引用返回的坑
引用返回既然這么香,那么以后是否就只使用引用就好了?當然不是,引用和指針一樣是一把雙刃劍用的好可以快捷高效,用不好會造成一定后果。
舉個例子:
int& func()
{int ret = 0;//...return ret;
}int& fun()
{int xxx = 1000;//...return xxx;
}
int main()
{//傳值返回/*int x = func();cout << x << endl;*/int& x = func();cout << x << endl;fun();cout << x << endl;//野引用對越界的空間進行訪問 在vs編譯器下可能查不到//因為vs編譯器對越界讀的行為是抽查行為int arr[10];//越界讀不一定報錯cout<<arr[12]<<endl;//越界寫可能會報錯 也有可能不會報錯 vs僅在數組末尾一兩個位置上設置了檢查arr[20]=1;return 0;
}

兩次打印
x,我們發現x的值竟然被fun函數中的xxx給修改了,這時為什么呢?
首先,func函數是傳引用返回給了x那么x就是ret的別名沒跑。第二次打印的x的值與xxx一樣為1000,這很難不讓人聯想到x可能是xxx的別名,為什么會造成這種情況呢?原因是ret是在函數棧幀中創建的,棧幀銷毀后ret的空間被回收,被回收的空間被起了一個別名叫x,好巧不巧的是當fun函數執行的時候xxx分配到的空間就是原來ret的空間,此時這個空間還有一個別名叫x,所以我們打印x就是xxx的值本質上x與xxx就是同一塊空間。
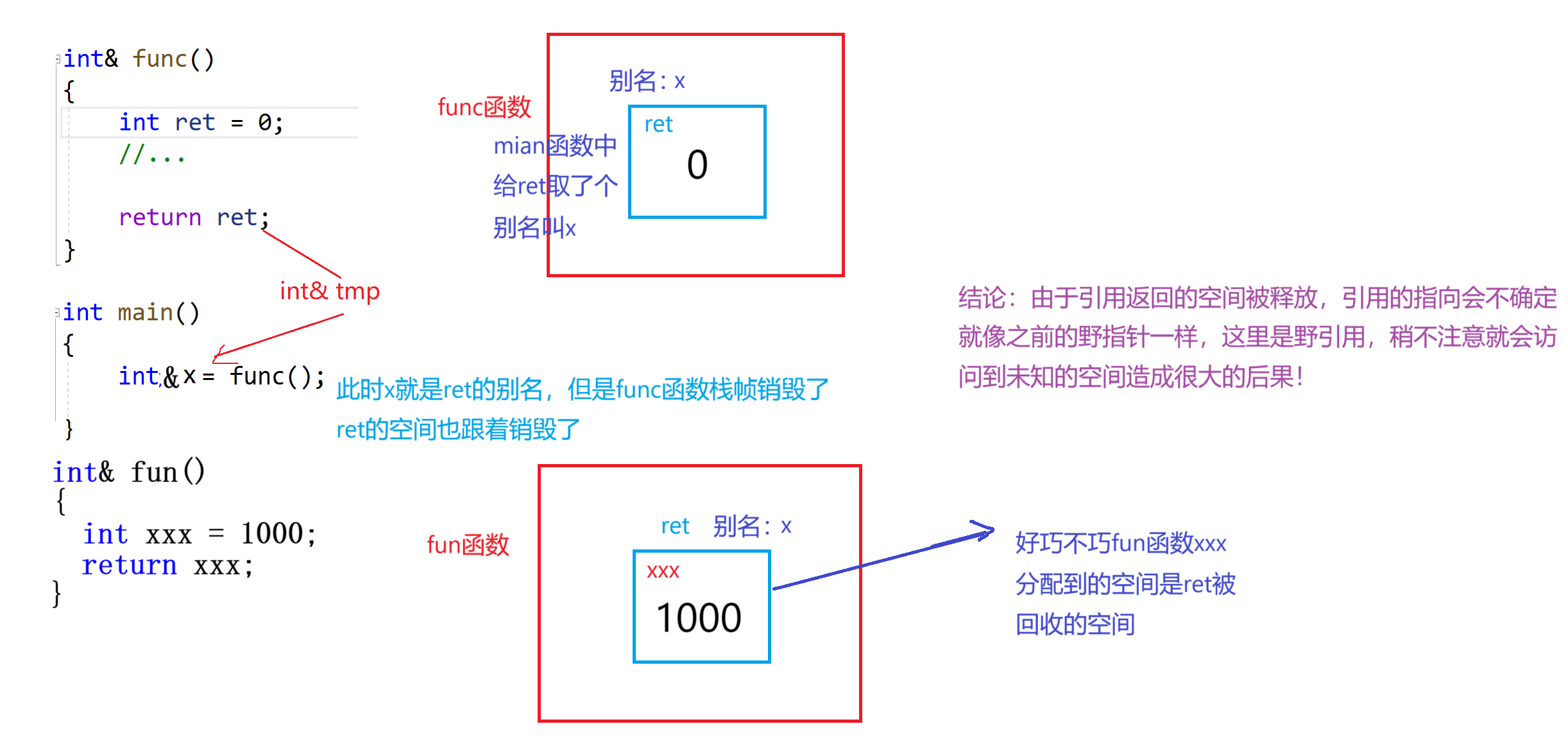
這里還有一點要注意就是,上面
SLAt的引用返回能夠使用是因為sl1中的數組是在堆上開辟的空間,函數棧幀的銷毀不影響它的銷毀;只有被手動釋放才會銷毀所以引用返回是沒有問題的!
3.1 const引用
提到const在C語言階段就會想到被限制的問題。例如:被const修飾過的指針其指向的內容或其本身就會受到限制,那么在C++中我們就習慣稱之為權限問題:
int main()
{//引用int x = 10;int& a = x;int y = 20;//權限可以縮小const int& a1 = x;//a1雖然是x的別名 但是加上const修飾后 a1就不能改了a1 = y;//權限相同const int z = 10;const int& c = z;c = x; //同樣c雖然是z的別名 但是c被const修飾定死了 不能被修改 這主要是在后面函數傳參的時候用到//權限不能被放大const int r = 10;int& b = r;//這是對權限的放大 這樣做是不行的 因為r本身已經被限制 再給r取別名的時侯也因該對別名進行修飾 const int y=10;int z=y;//權限有沒有放大?//沒有 就是普通的賦值
}
通過上面代碼要注意:可以引??個const對象,但是必須?const引用(相同權限下)。const引用也可以引用普通對象,因為對象的訪問權限在引用過程中可以縮小,但是不能放大。
void func(const int& x)
{//這里形參要用const修飾 因為實參已經被const修飾了 不能存在權限的放大}int main()
{int x = 1;const int y = 2;double d = 1.1;const int& r1 = x;const int& r2 = y;const int& r3 = 10;const int& r4 = x * 10;//編譯器會將x*10給存在一個臨時變量中 再將這個臨時變量賦給r4 所以r4的改變不會影響x//int& r5=d; 這樣是不行的,因為d會將臨時變量給r5 臨時變量具有常性 如果要引用臨時變量要怎么辦? 加上const修飾限制權限const int& r5 = d;//這里要注意 d給r5是一個普通的賦值 func(x);func(y);func(10);func(x*10);//這里的實參是 x*10后的值func(d);return 0;
}
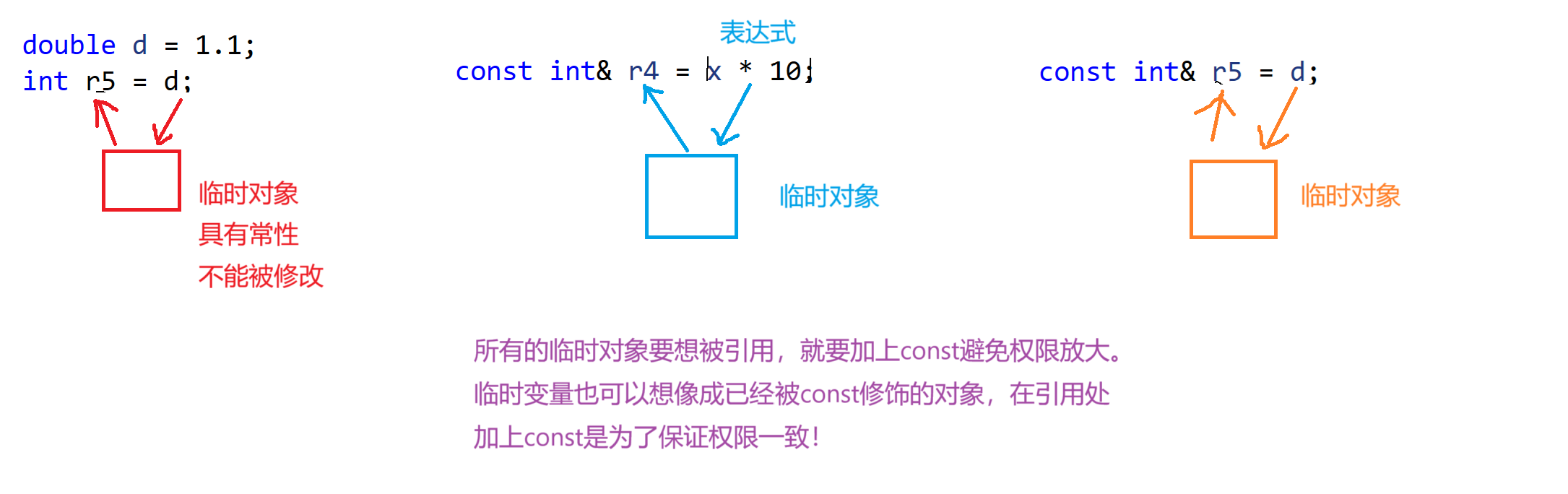
為什么要加const控制權限呢?比如上面的函數傳參,如果不用const修飾那么臨時變量都是傳不過去的,因為臨時變量具有常性不能被修改如果不加const修飾就引用就是權限放大了,所以這些都是為了以后傳參更加方便。 注意:權限問題只有在指針和引用的時候才會出現!!!
4.1指針和引用的關系
首先要明確一點:C++中出現的引用就是為了優化指針在C語言上的不足;換句話說引用就是優化指針的復雜度,但卻不能替代彼此。比如在鏈式結構和屬性結構中只有指針才能改變指向引用不能所以必須使用指針。
那么引用與指針的關系到底是什么呢?
在將引用返回的坑那里的時候,代碼編譯有兩個警告:
這里就有人疑問了?明明是引用返回怎么警告說是返回局部變量的地址?

我們打開反匯編代碼:
我們看到指針與引用在匯編代碼層面是極其的相似,所以不難推出引用它就是使用指針來實現的,就像上面的兩個警告一樣引用返回的是局部變量的地址,按照上面的分析也說得過去。

以上就是本章的全部內容啦!
最后感謝能夠看到這里的讀者,如果我的文章能夠幫到你那我甚是榮幸,文章有任何問題都歡迎指出!制作不易還望給一個免費的三連,你們的支持就是我最大的動力!

)






:指令與過濾器)


)


日志系統原理以及k8s集群日志采集過程)
 復雜度分析筆記)
![【光照】Unity中的[經驗模型]](http://pic.xiahunao.cn/【光照】Unity中的[經驗模型])

)

