在技術領域,“Overlay”和“Overlap”常因拼寫相似被混淆,但二者實則代表兩種截然不同的優化邏輯:Overlay 是“主動構建分層結構”,通過資源復用與隔離提升效率;Overlap 是“讓耗時環節時間交叉”,通過并行化壓縮整體耗時。本文將拆解這兩個概念的技術落地場景,帶你看清如何用“疊加”與“重疊”雙引擎優化系統性能。
一、先理清:Overlay 與 Overlap 的核心差異
在性能優化語境下,二者的本質區別體現在“操作邏輯”與“優化目標”上,我們用一張表明確邊界:
| 維度 | Overlay(主動疊加) | Overlap(時間重疊) |
|---|---|---|
| 核心邏輯 | 構建“分層結構”,復用底層資源、隔離上層操作 | 讓“等待環節”與“計算環節”時間交叉,減少空轉 |
| 優化目標 | 降低資源占用(存儲、網絡、內存) | 縮短整體耗時(IO密集、多任務場景) |
| 典型場景 | 容器存儲、分布式網絡、圖形渲染 | 批量API調用、數據處理流水線、任務調度 |
| 類比生活 | 抽屜分層收納——復用抽屜空間,隔離不同物品 | 邊燒水邊切菜——利用等待時間完成其他操作 |
簡單說:Overlay 是“空間上的優化”,通過分層復用資源;Overlap 是“時間上的優化”,通過并行重疊環節。二者雖邏輯不同,但常結合使用(如容器環境中用 Overlay 做存儲分層,再用 Overlap 優化容器啟動流程)。
二、Overlay:用“分層疊加”實現資源高效利用
Overlay 的核心價值是通過“底層復用+上層隔離”的分層結構,避免重復存儲、簡化網絡通信、降低資源開銷。最典型的落地場景是容器存儲和分布式網絡。
場景1:容器存儲(OverlayFS)——分層復用鏡像資源
容器鏡像的“輕量性”全靠 Overlay 技術支撐。傳統虛擬機需為每個實例分配完整磁盤,而 Docker/containerd 用 OverlayFS(疊加文件系統) 構建分層存儲,實現資源復用。
核心原理:三層疊加的“魔法”
OverlayFS 由三個部分組成,共同形成容器的文件視圖:
- Lowerdir(只讀鏡像層):容器鏡像的底層(如基礎鏡像
alpine:latest),多個容器可共享同一層,無需重復存儲; - Upperdir(讀寫容器層):容器運行時的修改層(如新建文件、修改配置),僅存儲當前容器的變更,不影響底層鏡像;
- Merged(聯合視圖):容器最終看到的“統一文件系統”,將只讀層與讀寫層的內容疊加展示。
性能優勢:寫時復制(Copy-on-Write)
當容器修改只讀層中的文件時,OverlayFS 會先將該文件“復制”到讀寫層,再修改副本——這一機制避免了對底層鏡像的破壞,同時讓多個容器共享99%的鏡像資源。例如:
- 10個基于
alpine:latest(5MB)的容器,傳統存儲需50MB,而 OverlayFS 僅需5MB(基礎鏡像)+ 每個容器的修改量(通常<1MB),資源節省近90%。
實操驗證:查看Docker的Overlay存儲
Docker 默認使用 overlay2 驅動,可通過以下命令查看分層結構:
# 查看容器的Overlay層
docker inspect --format '{{.GraphDriver.Data}}' <容器ID>
# 輸出示例(顯示lowerdir、upperdir、merged路徑)
# map[LowerDir:/var/lib/docker/overlay2/xxx/lowerdir upperdir:/var/lib/docker/overlay2/xxx/upperdir merged:/var/lib/docker/overlay2/xxx/merged]
場景2:分布式網絡(Overlay Network)——疊加虛擬網絡簡化通信
在 Kubernetes 等分布式集群中,不同主機的容器要通信,需跨越物理網絡的限制。Overlay 網絡通過在物理網絡上“疊加”一層虛擬網絡,讓跨主機容器像在同一子網內一樣通信,大幅簡化網絡配置。
核心原理:隧道封裝實現跨主機通信
Overlay 網絡通過 VXLAN(虛擬擴展局域網) 技術封裝數據包:
- 底層:現有物理網絡(如企業內網192.168.0.0/24);
- 疊加層:為容器分配獨立虛擬子網(如10.244.0.0/16);
- 通信過程:容器數據包先被封裝成物理網絡的數據包,傳輸到目標主機后再解封裝,交付給目標容器。
性能優勢:突破物理網絡限制
無需修改物理網絡配置,即可實現:
- 跨主機容器直接通信(如Pod1(10.244.1.2)直接訪問Pod2(10.244.2.3));
- 網絡隔離(不同命名空間的容器默認不互通);
- 動態擴縮容(新節點加入集群后自動接入Overlay網絡)。
實操驗證:查看K8s的Overlay網絡
K8s 常用 Flannel 插件實現 Overlay 網絡,可通過以下命令查看虛擬子網:
# 查看節點的Pod子網
kubectl get nodes -o custom-columns=NAME:.metadata.name,POD_CIDR:.spec.podCIDR
# 輸出示例
# NAME POD_CIDR
# node-1 10.244.0.0/24
# node-2 10.244.1.0/24
三、Overlap:用“時間重疊”壓縮整體耗時
Overlap 的核心價值是讓“等待環節”(IO、網絡、鎖)與“計算環節”(數據處理、邏輯運算)在時間上交叉,避免資源空轉。最典型的落地場景是批量IO任務和數據處理流水線。
場景1:批量API調用——讓“請求等待”與“結果處理”重疊
痛點:批量調用遠程API時,串行流程(請求1→處理1→請求2→處理2)中,“網絡等待”會導致CPU閑置。例如3個API(每個請求200ms、處理100ms),串行總耗時900ms。
優化思路:發起請求后不等待結果,立即發起下一個請求;當第一個請求返回時,利用其他請求的“等待時間”處理結果——讓“網絡IO”與“CPU計算”完全重疊。
代碼實現(Go):Goroutine 實現重疊優化
package mainimport ("fmt""time"
)// fetch 模擬API請求(IO等待,200ms)
func fetch(url string) (string, error) {time.Sleep(200 * time.Millisecond)return fmt.Sprintf("[%s] 響應", url), nil
}// process 模擬結果處理(CPU計算,100ms)
func process(data string) string {time.Sleep(100 * time.Millisecond)return "處理完成:" + data
}func main() {urls := []string{"url1", "url2", "url3"}// 1. 串行執行(基準對比)startSerial := time.Now()for _, url := range urls {data, _ := fetch(url)_ = process(data)}fmt.Printf("串行耗時:%v\n", time.Since(startSerial)) // 約900ms// 2. Overlap優化:請求與處理重疊startOverlap := time.Now()resultCh := make(chan string, len(urls)) // 緩沖通道避免阻塞for _, url := range urls {go func(u string) {data, _ := fetch(u) // 網絡請求(等待)resultCh <- process(data) // 處理(與其他請求重疊)}(url)}// 收集結果for i := 0; i < len(urls); i++ {<-resultCh}fmt.Printf("Overlap優化后耗時:%v\n", time.Since(startOverlap)) // 約200ms
}
效果:耗時從900ms降至200ms,性能提升4.5倍
場景2:數據處理流水線——讓“數據加載”與“計算”重疊
痛點:處理大量數據時,串行流程(加載1→處理1→加載2→處理2)中,“磁盤IO等待”會浪費計算資源。例如3批數據(每批加載300ms、處理200ms),串行總耗時1500ms。
優化思路:處理當前批次數據時,異步預加載下一批數據——讓“磁盤IO”與“CPU計算”重疊。
代碼實現(Go):預加載實現重疊優化
package mainimport ("fmt""time"
)// loadData 模擬數據加載(磁盤IO,300ms)
func loadData(batch int) ([]int, error) {time.Sleep(300 * time.Millisecond)return []int{batch*10, batch*10 + 1}, nil
}// processBatch 模擬數據處理(CPU計算,200ms)
func processBatch(data []int) int {time.Sleep(200 * time.Millisecond)sum := 0for _, v := range data {sum += v}return sum
}func main() {batches := 3// 1. 串行執行(基準對比)startSerial := time.Now()for i := 0; i < batches; i++ {data, _ := loadData(i)_ = processBatch(data)}fmt.Printf("串行耗時:%v\n", time.Since(startSerial)) // 約1500ms// 2. Overlap優化:預加載下一批數據startOverlap := time.Now()dataCh := make(chan []int, 1)// 預加載第一批數據go func() {data, _ := loadData(0)dataCh <- data}()for i := 0; i < batches; i++ {currentData := <-dataCh // 等待當前批次數據// 預加載下一批(與當前處理重疊)if i < batches-1 {go func(next int) {nextData, _ := loadData(next)dataCh <- nextData}(i + 1)}_ = processBatch(currentData) // 處理當前批次}fmt.Printf("Overlap優化后耗時:%v\n", time.Since(startOverlap)) // 約900ms
}
效果:耗時從1500ms降至900ms,性能提升66%
四、協同增效:Overlay 與 Overlap 結合的實戰案例
在實際系統中,Overlay 與 Overlap 常結合使用,形成“空間+時間”的雙重優化。以“K8s 容器啟動流程”為例:
- Overlay 優化存儲:容器鏡像通過 OverlayFS 分層存儲,節點只需拉取一次基礎鏡像,后續容器復用該層,減少鏡像拉取時間和存儲占用;
- Overlap 優化啟動:
- 拉取鏡像時,采用“邊拉邊解壓”(拉取數據的IO等待與解壓的CPU計算重疊);
- 啟動容器時,預加載容器配置(配置加載的IO等待與鏡像層掛載的操作重疊)。
通過二者結合,K8s 容器的啟動時間可從秒級壓縮至百毫秒級,同時節點存儲占用降低70%以上。
五、總結:如何選擇兩種優化邏輯?
當你面臨性能問題時,可按以下流程判斷該用 Overlay 還是 Overlap:
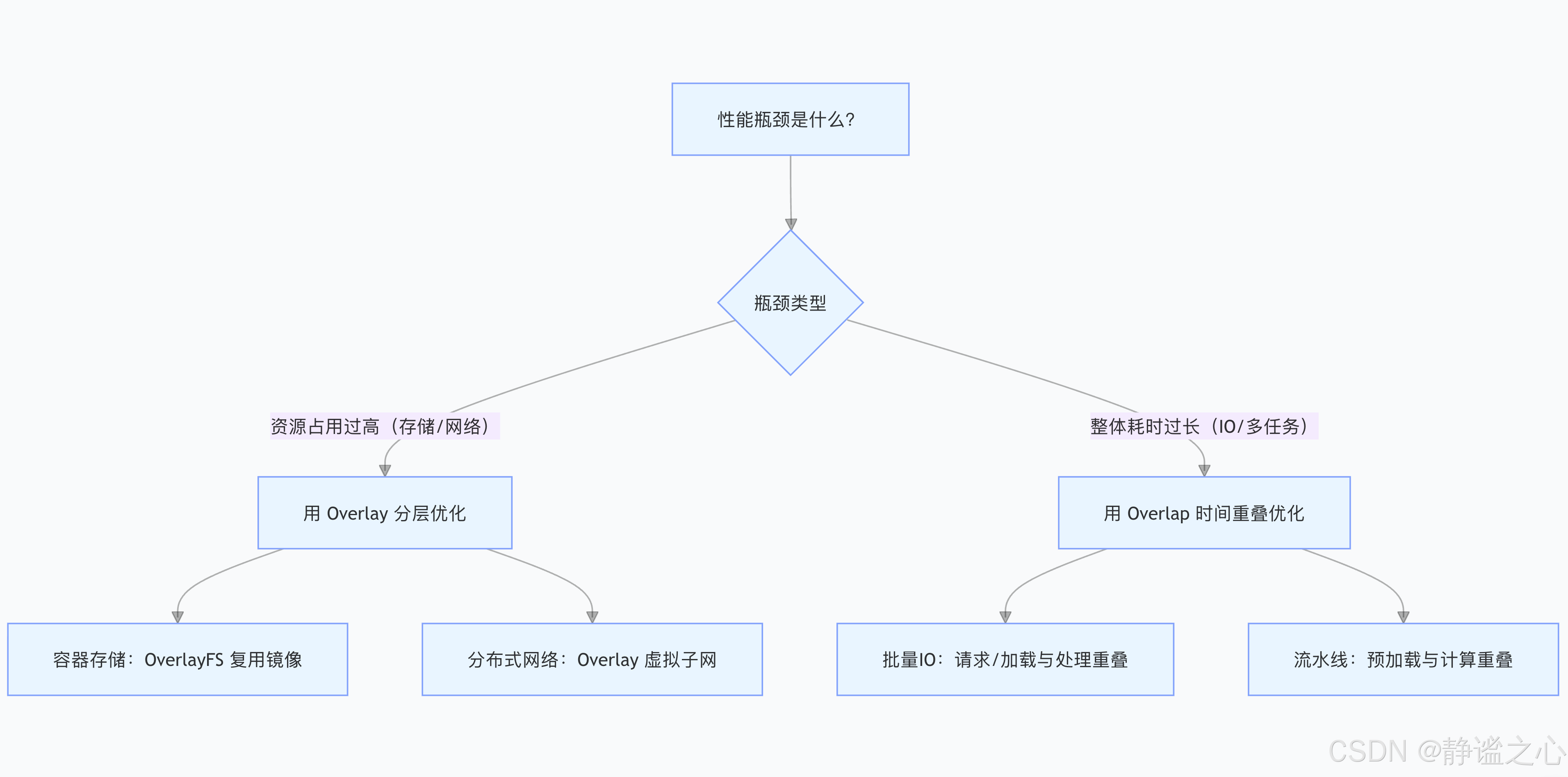
Overlay 是“給資源做減法”,通過分層復用降低開銷;Overlap 是“給時間做減法”,通過并行重疊縮短耗時。理解二者的核心邏輯,才能在技術優化中精準發力,實現“資源更省、速度更快”的雙重目標。
:指令與過濾器)


)


日志系統原理以及k8s集群日志采集過程)
 復雜度分析筆記)
![【光照】Unity中的[經驗模型]](http://pic.xiahunao.cn/【光照】Unity中的[經驗模型])

)






![【光照】Unity中的[光照模型]概念辨析](http://pic.xiahunao.cn/【光照】Unity中的[光照模型]概念辨析)

