目的
最近做一個加密方面的研究,加密之后的二進制,通過轉碼之后,再也找不回之前的二進制了。
怎么試都不行,真是非常得奇怪!!!!

先說說字符編碼基礎知識
在信息技術的海洋中,字符編碼是數據表示的基本橋梁,它使計算機能夠存儲和傳輸文本信息。字符編碼的本質,是對字符集進行數字化的一種方式,通過特定的編碼規則將文字轉換為計算機可以處理的二進制代碼。理解字符編碼的工作原理對于從事軟件開發、數據處理等IT行業的專業人員來說至關重要。
字符集與編碼
字符集是一組符號和編碼的集合,而編碼則是這些字符集的數字化表示(這句話有理,編碼就是二進制,轉化編碼就是更改二進制)。不同的編碼方式有不同的特性,它們決定了數據存儲、網絡傳輸及文件處理的效率和范圍。
常見字符編碼
字符編碼的種類繁多,常見的包括ASCII、GBK、UTF-8等。每種編碼都有其特定的使用背景和適用場景。掌握這些基礎知識,有助于我們更好地處理國際化文本、網絡數據交換等問題。
情況分析
實例分析

點擊加密之后顯示:

點擊解密之后:

解密里沒顯示什么,后臺提示了報錯:
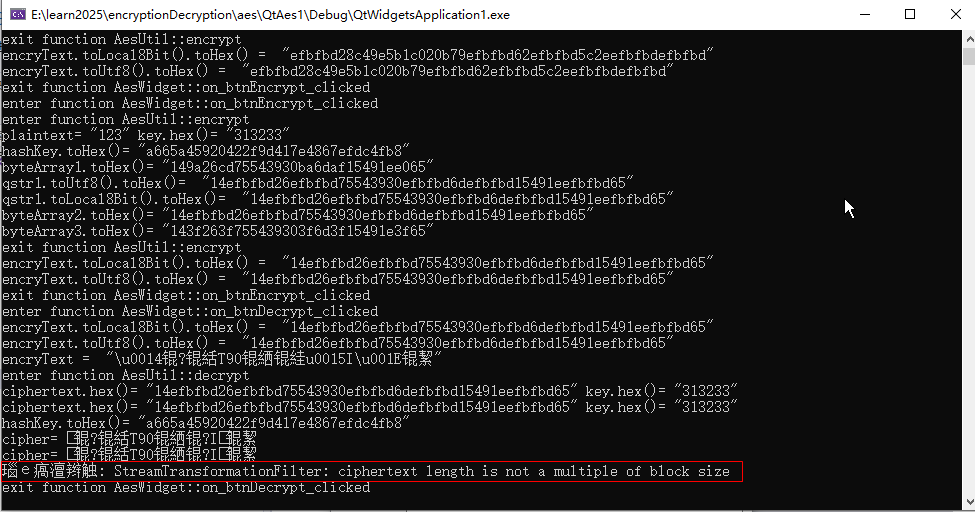
怎么回事,那就跟蹤代碼看看情況:
先看加密的代碼:
源碼如下:
QByteArray AesUtil::encrypt(const QString& plaintext, const QString& key) {qDebug("enter function AesUtil::encrypt");qDebug()<< "plaintext="<< plaintext << "key.hex()=" << key.toLocal8Bit().toHex();try {QByteArray hashKey = QCryptographicHash::hash(key.toUtf8(),QCryptographicHash::Sha256);hashKey = hashKey.left(16);qDebug() << "hashKey.toHex()=" << hashKey.toHex();//std::string plain = qtToStdString(plaintext);std::string plain = plaintext.toUtf8();//std::string plain2 = plaintext.toUtf8().constData();//std::string keyStr = qtToStdString(key);byte iv[CryptoPP::AES::BLOCKSIZE] = { 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16};CryptoPP::CBC_Mode<CryptoPP::AES>::Encryption encryptor((byte*)hashKey.data(), hashKey.size(), iv);std::string cipher;CryptoPP::StringSource(plain, true,new CryptoPP::StreamTransformationFilter(encryptor,new CryptoPP::StringSink(cipher)));// 將二進制密文轉換為十六進制字符串便于顯示和傳輸/*string encoded;StringSource(cipher, true,new HexEncoder(new StringSink(encoded)));*/QByteArray ar1 = QByteArray::fromStdString(cipher);std::string cipher2 = ar1.toStdString();QString str1 = QString::fromLocal8Bit(cipher.c_str());QString str3 = QString::fromUtf8(cipher.c_str());QString str2 = ar1;QByteArray byteArray1 = QByteArray::fromStdString(cipher);qDebug() << "byteArray1.toHex()=" << byteArray1.toHex();QString qstr1 = QString::fromUtf8(byteArray1);qDebug() << "qstr1.toUtf8().toHex()= " << qstr1.toUtf8().toHex();qDebug() << "qstr1.toLocal8Bit().toHex()= " << qstr1.toLocal8Bit().toHex();QByteArray byteArray2 = qstr1.toUtf8();qDebug() << "byteArray2.toHex()=" << byteArray2.toHex();QByteArray byteArray3 = qstr1.toLatin1();qDebug() << "byteArray3.toHex()=" << byteArray3.toHex();qDebug("exit function AesUtil::encrypt");return QByteArray::fromStdString(cipher);}catch (const CryptoPP::Exception& e) {cerr << "加密失敗: " << e.what() << endl;return "";}qDebug("exit function AesUtil::encrypt");
}
跟蹤代碼的情況:
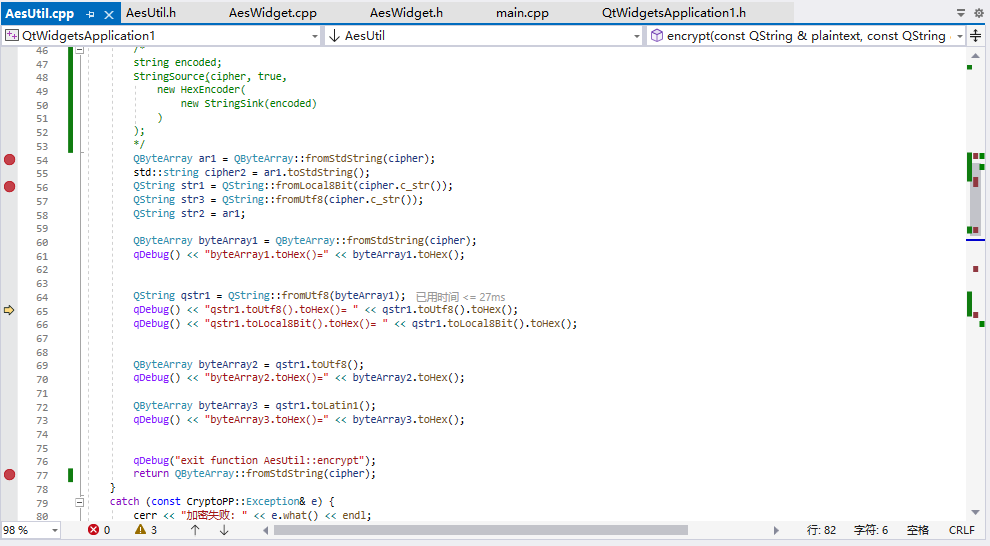
調試情況:
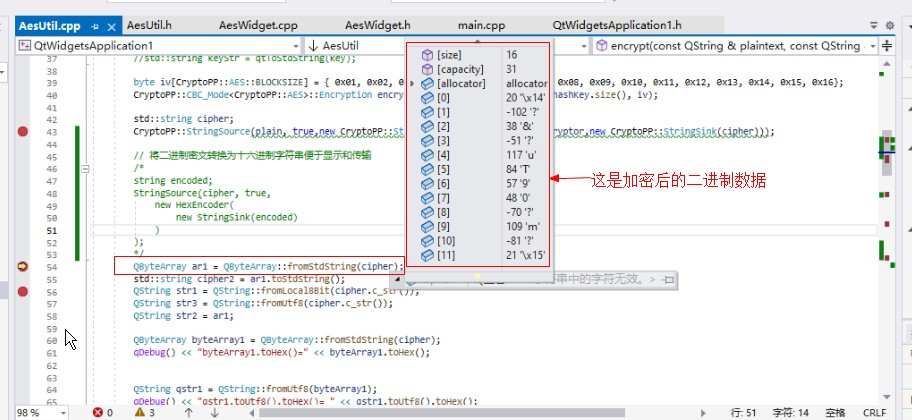
下面把密文轉化為QByteArray類型:
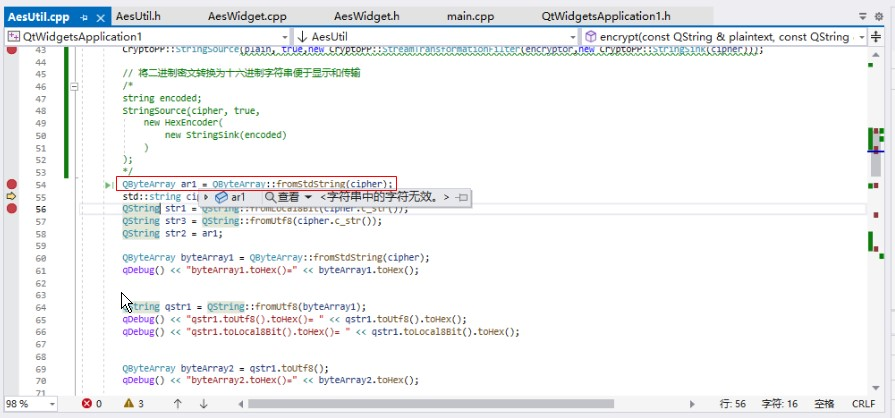
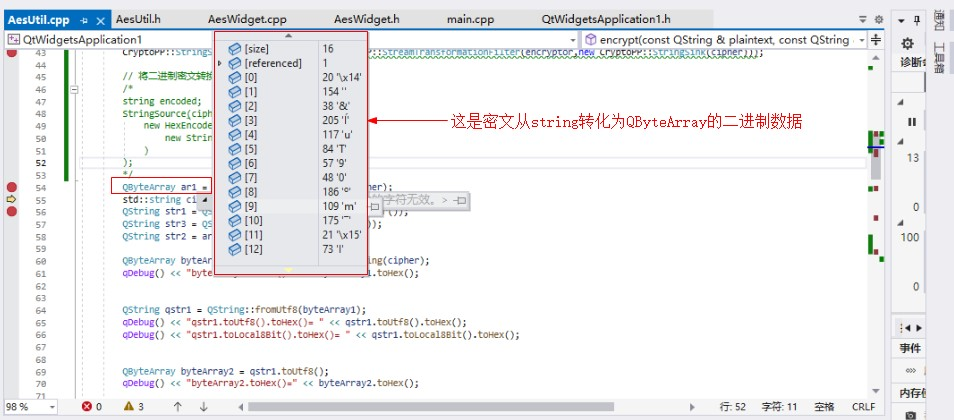
QByteArray的數據與原始二進制數據是一致的,因為負號的處理方式不同,所以有些顯示不一樣,但二進制數據是一樣的。
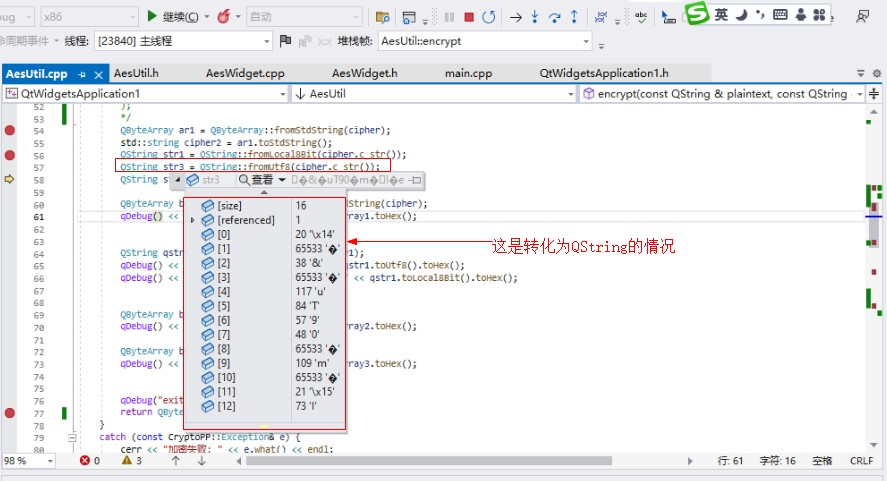
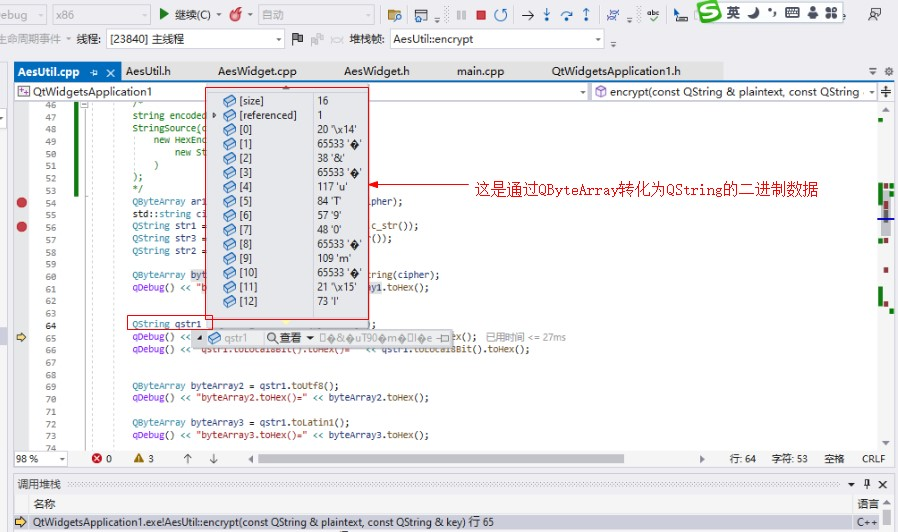
到了QString數據明顯不一樣了,但表示的編碼是一致的。
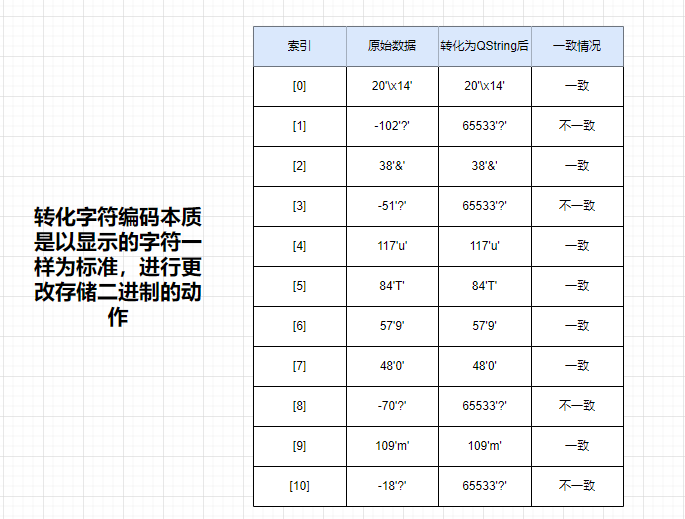
可以對比一下看看:(第一張圖是原始加密二進制數據,第二張圖是轉化為QString的加密二進制數據)
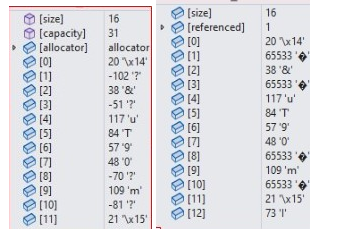
上面最顯著的區別是:原始數據[1][3][8][10]數值是不一樣的,但到了QString 卻成了一樣的了是65533,并且都顯示為?號。
這證明了QString進行了utf8的轉化,這種編碼轉化是以字符為標準的進行更改相應的二進制數,也可以說是以顯示的東西為標準,更改后面的二進制數,當然,也有相同的,相同是因為巧合而已,所以這說明了,要想保持二進制一樣,就不能進行編碼相關的轉化。
因為編碼的本質是以顯示的東西一樣為要求,對存儲的二進制數進行更改。
解密時變化會更為明顯:
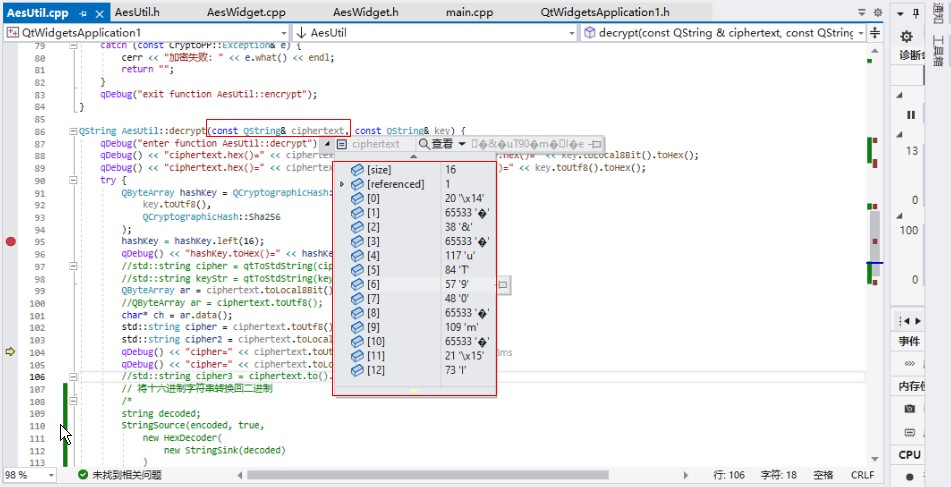
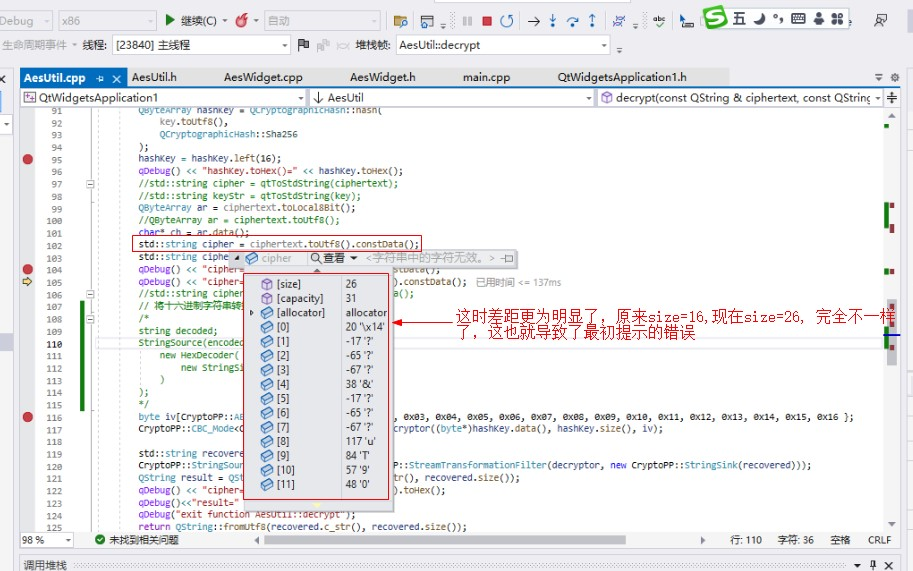
解碼的相關代碼:
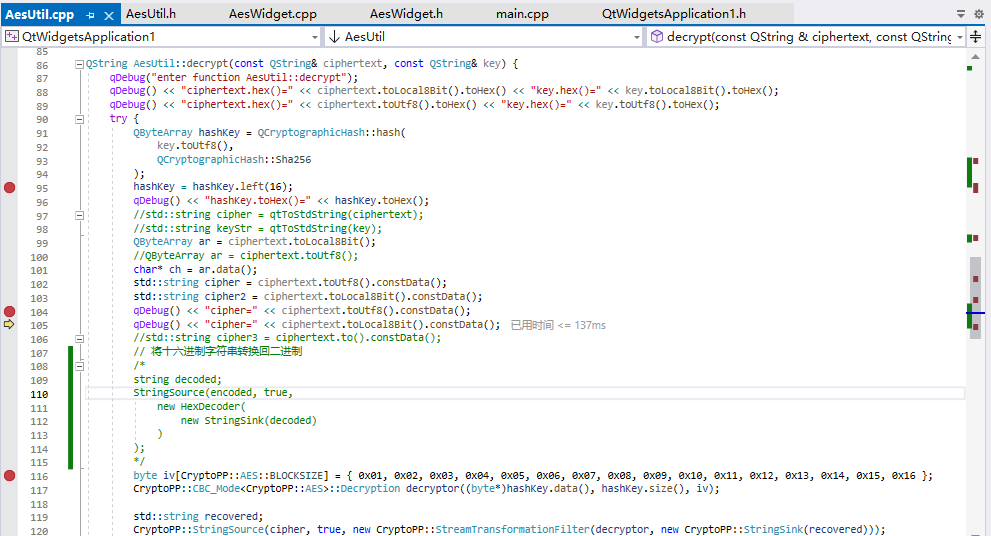
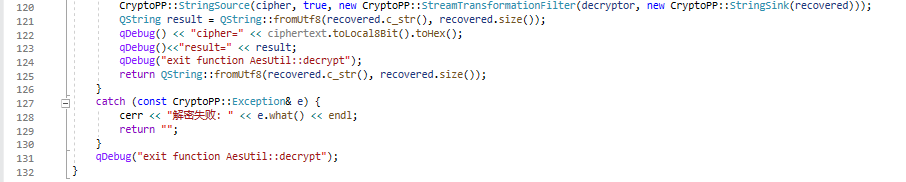
關于常用的編碼
UTF-8 和 GBK 編碼的本質區別在于?字符集覆蓋范圍?和?編碼方式?:
字符集覆蓋范圍
?GBK?:基于 GB2312 擴展,支持21003個漢字及682個符號,主要用于中文信息處理。 ?
?UTF-8?:基于 Unicode 標準,理論上支持任何字符(包括中文、英文、數字等),兼容 ASCII 字符,廣泛應用于多語言場景。 ?
編碼方式
?GBK?:采用雙字節編碼,首字節為0x81-0xFE,尾字節為0x40-0xFE,通過高位字節擴展漢字數量。 ?
?UTF-8?:可變長度編碼(1-4字節),第一個字節與ASCII兼容,后續字節用于擴展字符范圍。 ?
應用場景
?GBK?:適合中文系統內部處理(如Windows系統默認中文編碼)。 ?
?UTF-8?:優先用于國際化和跨平臺數據交換(如網頁、郵件)。
總結
之所以出現了上面的錯誤,還是沒理解字符編碼的本質,編碼就是用數字對應字符,就是這么簡單。
比如ASCII編碼:
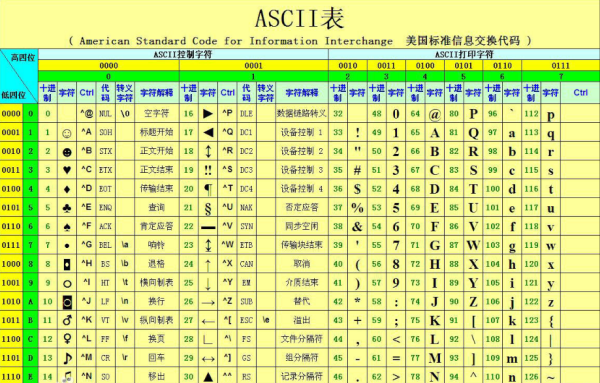
最后總結:



)
)




)







)

