CornerNet于2019年3月份提出,CW近期回顧了下這個在當時引起不少關注的目標檢測模型,它的亮點在于提出了一套新的方法論——將目標檢測轉化為對物體成對關鍵點(角點)的檢測。通過將目標物體視作成對的關鍵點,其不需要在圖像上鋪設先驗錨框(anchor),可謂實實在在的anchor-free,這也減少了整體框架中人工設計(handcraft)的成分。
CornerNet于2019年3月份提出,CW近期回顧了下這個在當時引起不少關注的目標檢測模型,它的亮點在于提出了一套新的方法論——將目標檢測轉化為對物體成對關鍵點(角點)的檢測。通過將目標物體視作成對的關鍵點,其不需要在圖像上鋪設先驗錨框(anchor),可謂實實在在的anchor-free,這也減少了整體框架中人工設計(handcraft)的成分。CornerNet于2019年3月份提出,CW近期回顧了下這個在當時引起不少關注的目標檢測模型,它的亮點在于提出了一套新的方法論——將目標檢測轉化為對物體成對關鍵點(角點)的檢測。通過將目標物體視作成對的關鍵點,其不需要在圖像上鋪設先驗錨框(anchor),可謂實實在在的anchor-free,這也減少了整體框架中人工設計(handcraft)的成分。
為了讓自己的梳理工作更好地反饋到自身以實現內化,CW決定在此記錄下自己對CornerNet的理解,同時也和大家進行分享,如果有幸能夠幫助到你們,那我就更是happy了!
本文內容有些長,但是如果你打算認真回顧和思考有關CornerNet技術原理的細節,不妨耐心地看下去。CW也將本文的目錄列出來了,大家也可根據自身需求節選部分內容來看。(見文末)
研究動機及背景
作者發現,目標檢測中anchor-based方法存在以下問題:
1.為了給gt提供正樣本,需要密集鋪設多尺度的anchors,但這同時會造成正負樣本不均衡;
2.anchor的存在就勢必引入眾多handcraft成分,如anchor數量、尺度、長寬比等,模型的訓練效果極大地受到這些因素的影響,另外還會影響模型推斷速度;
那么如何改進呢..不知怎地,作者靈光一閃,想到在解決人體姿態估計問題的方法中,有一類bottom-up框架,其方法是先對人體關鍵點部位進行檢測,再將檢測到的關鍵點部位拼接成人的姿態。
于是,作者腦回路:“咦,要不我也這么干好了!我也來檢測關鍵點。目標檢測最終不是要定位物體對應的預測框嗎,那我就檢測出框的左上和右下兩個角點,這樣我也能定位出整個框了,萬歲!”。于是,CornerNet就這樣機緣巧合地“出生”了。
概述
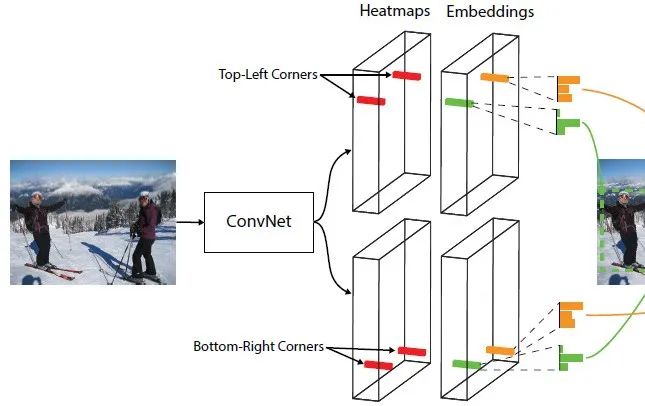
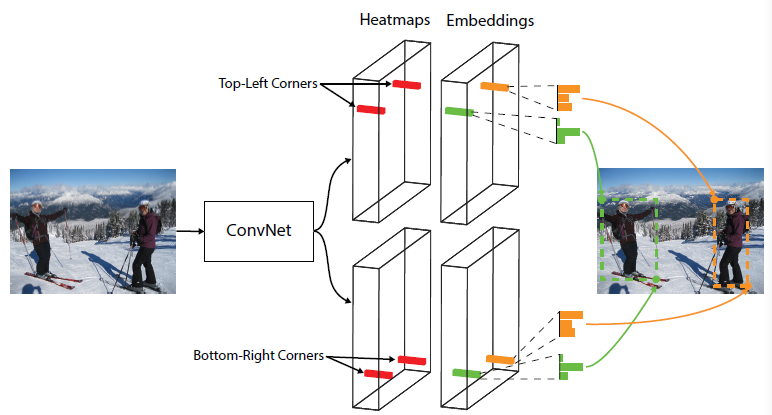
概括地說,CornerNet使用單個卷積網絡來檢測物體的左上角和右下角:
●? 通過預測得到的熱圖(heatmaps)來判別各位置是否屬于角點;
●? 基于預測的角點嵌入向量(embeddings)來對角點進行配對(屬于同一物體的一對角點的embeddings之間的距離會比較小,屬于不同物體的則比較大),從而判斷哪些左上角點和右下角點是屬于同一物體的;
●? 使用預測的偏移量(offsets)對角點位置進行調整;
另外,為了更好地檢測角點,提出了新型的池化層——Corner Pooling。
整體框架
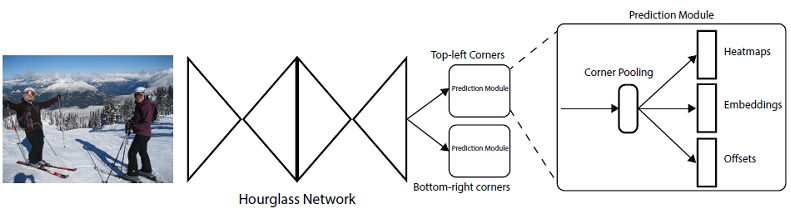
首先將輸入圖像通過預處理模塊:1個7×7的卷積模塊(conv+bn+relu)+1個殘差模塊,分別下采樣2倍,這會將輸入圖像尺寸縮小為原來的1/4(論文中使用的輸入圖像大小是511×511,于是下采樣后得到128×128大小的輸出特征圖)。
然后將預處理模塊輸出的特征圖輸入到backbone提取特征,backbone采用的是沙漏網絡(Hourglass Network)結構,這里串聯(堆疊)了兩個相同結構的Hourglass Network,其中每個在經過下采樣操作后會上采樣恢復到之前的大小,因此backbone輸出特征圖的大小與其輸入一致。
Hourglass Network后連接著兩個預測模塊,分別用于預測左上角和右下角。每個模塊包含其獨立的角池化(Corner Pooling)模塊。
接著,將Hourglass Network的輸出特征輸入到Corner Pooling模塊得到池化特征。
最后,將池化特征分別輸入到3個不同的卷積模塊來預測heatmaps、embeddings以及offsets。
角點檢測
檢測包括分類+定位,這里主要是分類,即判斷特征圖上的各個(特征點)位置是否屬于角點,不需要顯式回歸角點的位置,角點的位置基本由特征點的位置決定,然后通過預測的offsets進行調整。
●? Heatmaps
分類基于兩組heatmaps,分別用于左上角和右下角的判斷。每組heatmap的shape是
![]()
,是物體類別數(不含背景),
![]()
是特征圖的尺寸。這樣,每個通道就對應特定類別物體的角點判斷。理想狀態下,它是一個二值mask,值為1就代表該位置屬于角點,而通常模型預測出來每個位置上的值是0~1,代表該位置屬于角點的置信度。
●? Penalty Reduction
由此可知,對于每個角點,只有1個正樣本位置。那么訓練時,1個gt在heatmap上的標簽就只有在其對應的位置上值為1,其余均為0。不知你有沒feel到,這樣的話,很容易由于正樣本過少而導致低召回率。在實際情況中,即使我們選擇一對與gt角點有一定程度偏離的角點來形成預測框,那么它也有可能與gt box有較高的重疊度(IoU),這樣的預測框作為檢測結果也是不錯的選擇(如下圖,紅框是gt bboxes,綠框是距離gt角點較近的角點對形成的bboxes)。

于是,對于那些距離gt角點位置較近的負樣本位置,我們可以“在心里暗暗地將它們也作為候選的正樣本”,轉化到數學形式上,就是在計算loss時減低對它們的懲罰度,懲罰度與它們距離gt角點的遠近相關(gt角點 to 負樣本:你離我越近,我對你越溫柔~)。
具體來說,距離gt角點在半徑為 r 的圓內的那些負樣本,我們重新計算其標簽值為0~1之間的值(而非原來的0),離gt角點越近越接近1,否則越接近0:
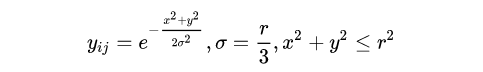
以上x,y代表負樣本位置與gt角點位置的橫、縱坐標之差,i,j是特征點的位置,
![]()
起到控制懲罰度嚴厲程度(變化快慢)的作用,值越大,懲罰越輕(可聯想到高斯曲線越扁平)。你看看,這就是CornerNet對這批“候選正樣本”的愛~
OK,已經感受到愛了,那么怎么用到loss計算上呢?作者設計了一種focal loss的變體:
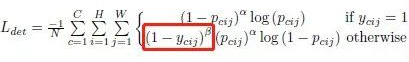
![]()
代表模型預測的heatmap中位置
![]()
屬于類別 C 物體角點的置信度,
![]()
。由上式可知,紅色框部分就可以達到降低距離gt角點較近的那些負樣本懲罰度的效果。而對于那些遠離gt角點的負樣本,它們對應的標簽值依然是0,因此不受影響。
CornerNet告訴我們,許多事情不是非正即負、非0即1,世界本就是混沌。做人也一樣,不能太死板,對待他人要理解與包容,適當的寬容能夠在生活中獲取小確幸(說不定還有大確幸呢)。
●? Radius Computation
以上只談到對于距離gt角點在半徑為的圓內的那些負樣本“給予適當的寬容”,但并未說明半徑如何計算,不急,因為要解方程式,可以先喝杯咖啡,休息下。
在作者制定的規則下,半徑是基于這樣一個條件計算出來的:在圓內的角點對形成的bbox(以下記為pred bbox)與gt box的IoU不小于(作者在實驗中設置為0.3)。根據這個條件,可以分3種情況來考慮:
1. pred bbox包圍著gt box,同時兩邊與圓相切
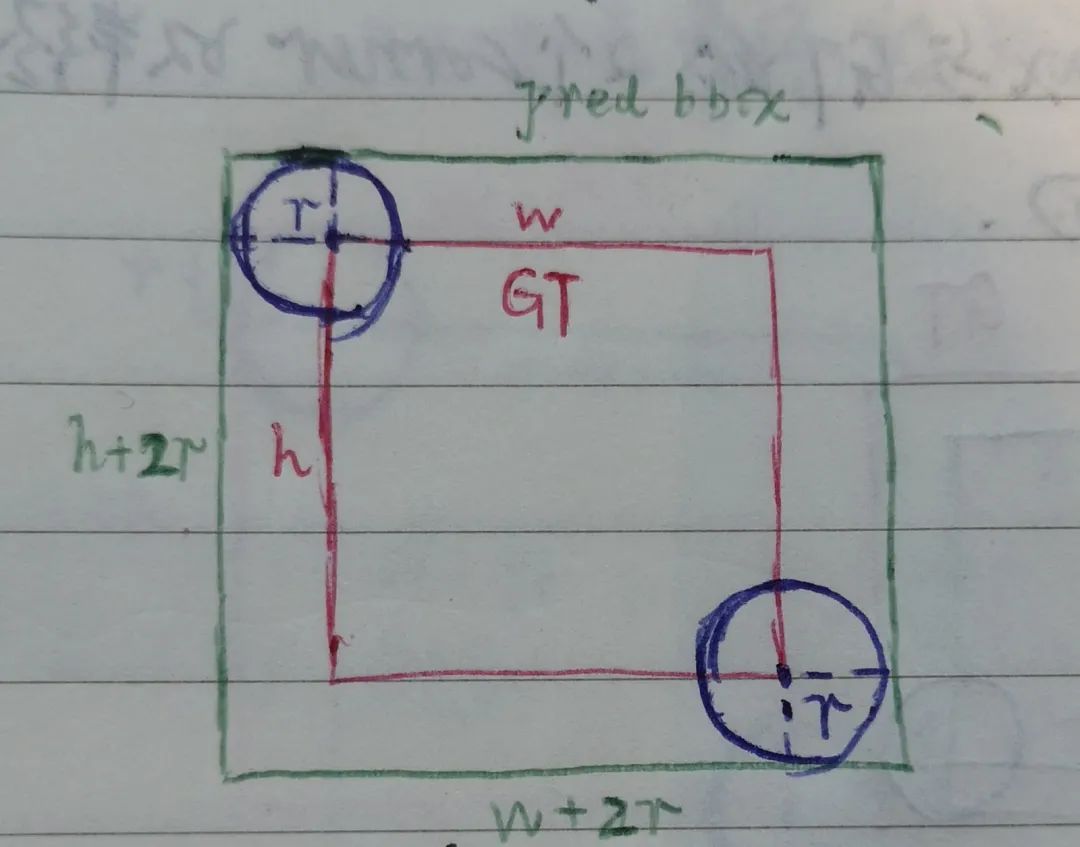
這時,
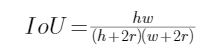
移項,整理得二元一次方程式:
![]()
還記得根的判別式因子嗎?其各項依次為:
![]()
易知判別式
![]()
(因為
![]()
所以),于是有解:
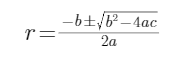
但是,我們需要的半徑應該是正根,于是最終:
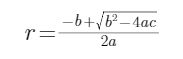
2.?gt box包圍著pred bbox,同時兩邊與圓相切
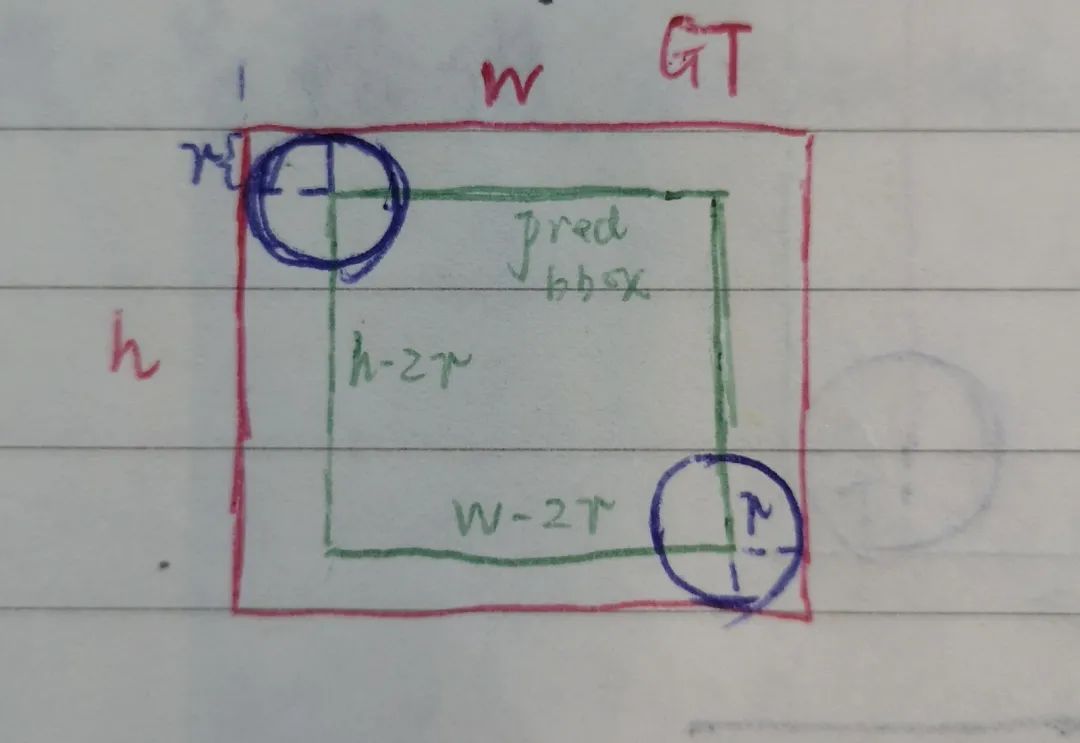
這時,
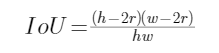
移項整理得:
![]()
此時,根的判別式因子:
![]()
判別式:
![]()
于是,方程有解,并且此時兩個根
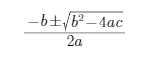
都是正根。為了兼容其它情況,我們需要取小的根,即?
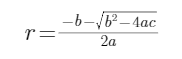
3.?pred bbox與gt box部分重疊,兩者分別有兩邊與圓相切
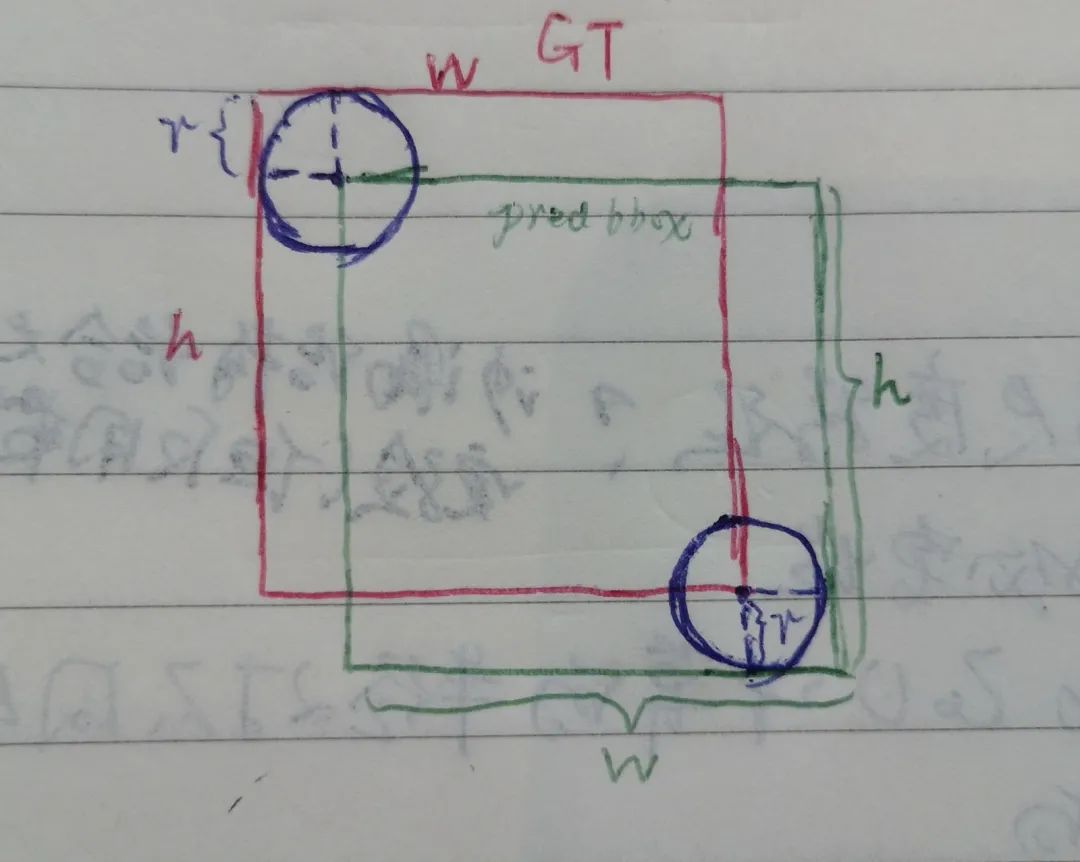
此時,
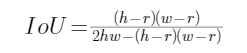
移項整理得:
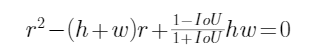
根的判別式因子:
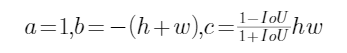
易證判別式
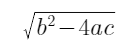
(請讓CW偷下懶..),最終取較小的根:
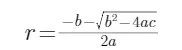
以上3種情況都是根據求根公式計算出對應的半徑值
![]()
,在實現時,將
![]()
代入計算。為了兼容各種情況,最終r的取值需要是三個解中的最小值:
![]()
●? location offsets
offsets用于調整預測的角點位置,使得定位更精確。注意,其和anchor-based框架中回歸的偏移量不同,在這里,offsets的實質是量化誤差。
由于在卷積神經網絡中存在著下采樣層,于是將特征圖中的位置重新映射到輸入圖像中的空間時,勢必會存在量化誤差,這極大地影響了小目標邊界框的定位。
為了緩解這一現象,在訓練時,計算gt角點位置映射到特征圖位置時的量化誤差,將其作為offsets的訓練標簽:
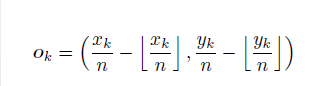
其中 n 是下采樣率,
![]()
是角點 k 在原圖的位置。
訓練模型讓其學會預測這個誤差值,以便在最終檢測時重新調整預測的角點位置。使用smooth-l1 loss對這部分進行學習:
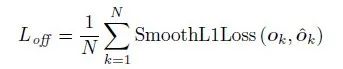
訓練完畢后,在測試時,就可以這樣調整預測的角點位置(實際實現時并非這樣,這里僅僅打個簡單的比方):
假設在heatmap上位置
![]()
被預測為角點,其對應預測的offsets為
![]()
,那么其映射到原圖上的位置就是:
![]()
其中[]表示向下取整。
角點配對
在特征圖的每個位置上,模型還會預測角點對應的嵌入向量(embeddings),用于將左上角點和右下角點進行配對。能否匹配成一對主要是由embeddings之間的距離來決定的(當然,其實還有其它條件,如預測的角點必須屬于相同類別、右下角點的坐標必須大于左上角點的坐標)。理想狀態下,同一物體的一對角點對應的embeddings之間的距離較小,而不同物體的則較大。那么,如何實現這一目標呢?
在訓練時,CornerNet使用'pull loss'來拉近屬于同一物體的角點的embeddings,同時使用'push loss'來遠離屬于不同物體的角點的embeddings:
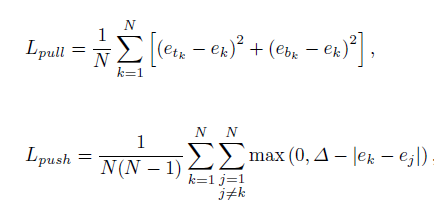
其中
![]()
分別為目標物體 K 的左上角和右下角對應的embeddings,則是兩者的均值,delta=1,代表不同物體的角點對應的embeddings之間的margin下限(to
![]()
:我們不熟,別靠太近,保持1米以外的文明距離)。?N 是目標物體的數量,也就是說,僅對gt角點位置對應的預測embeddings計算這些損失。
Corner Pooling
由于實際生活中許多物體并沒有角狀,比如圓形的餐盤、條形的繩子等,因此并沒有直觀明顯的視覺特征來表征角點。這也就是說,通過現有的視覺濾波器(卷積層、池化層等)去捕捉圖像的局部特征來檢測角點,效果并不會太好。比如以下這些情況,物體的左上角和右下角點處并不存在物體本身的部分,即這些角點的位置本身并不存在物體的特征。

于是,為了在角點處獲取到物體特征,我們需要將物體的特征匯集到角點處。比如對于左上角,可以將其水平向右以及豎直向下的特征都“收集”過來;而對于右下角點,則將其水平向左以及豎直向上的特征“收集”過來。
基于這種思想,作者提出了Corner Pooling,分別對用于收集左上角點特征和右下角點特征。對于左上角點,其處理如下:
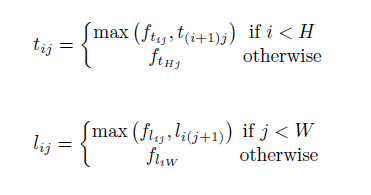
其中
![]()
分別表示池化層的輸入特征圖,它們的目標是分別將豎直方向和水平方向的特征不斷匯集到上方和左方。這樣,在
![]()
中的左上角點就分別擁有了豎直方向和水平方向的極大值特征,分別代表
![]()
中位置
![]()
的特征值。
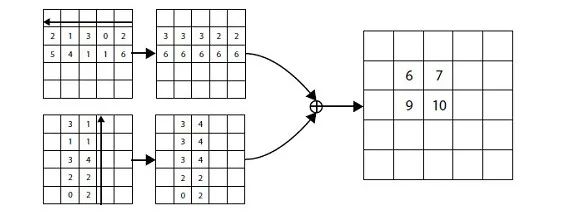
最終,將
![]()
進行element-wise add得到輸出特征圖,于是,在其中的左上角點處就擁有了豎直加水平方向的極大值特征。
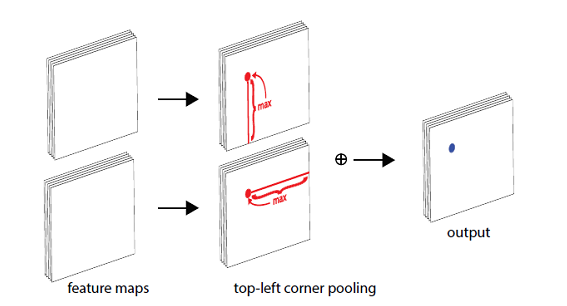
對于右下角點的處理也是同樣道理,經Corner Pooling處理后,會在輸出特征圖的右下角點處匯聚到豎直和水平方向的極大值特征。
訓練
網絡模型在基于Pytorch的默認方式下進行隨機初始化,并且沒有在額外的數據集上預訓練。
輸入圖像的分辨率設置為511×511,4倍下采樣后輸出特征的分辨率為128×128。為了減少過擬合,采用了不少數據增強技術,包括:隨機水平翻轉、隨機縮放、隨機裁剪以及隨機色彩抖動(調整圖像的亮度、飽和度和對比度)。最后,還將PCA應用于輸入圖像。
batch size設置為49,使用10個(Titan X PASCAL)GPUs來訓練,其中每個batch在master GPU上分配4張圖,其余GPUs各分配5張。
訓練損失最終的形式為:
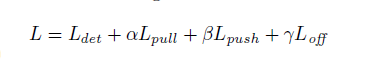
其中
![]()
使用Adam優化器進行優化,初始學習率設置為
![]()
。初始先訓練250k次迭代,在實驗中與其它檢測器進行比較時,額外再訓練250k次迭代,并且在最后的50k次迭代中將學習率減低至
![]()
。
●? Intermediate Supervision
作者在訓練時還添加了中間監督。前文提到過,backbone是兩個相同結構的Hourglass Networks串聯而成,中間監督的意思就是對第一個Hourglass Network的輸出預測也實行監督。具體來說,就是將第一個Hourglass Network的輸出特征圖也輸入到后面的預測模塊:先經過corner pooling池化,然后分別輸入到不同的卷積模塊分別預測heatmaps、embeddings和offsets,對這部分的預測結果也計算損失進行訓練。
那么可能有帥哥/靚女會疑問:那第二個Hourglass Network的輸入是什么呢?
OK,CW也大方地補充說明下:其實在兩個Hourglass Networks之間還有些中間處理模塊,它們的實質都是conv+bn+relu和殘差模塊,將第一個Hourglass Network的輸入、輸出特征圖經過這些中間模塊處理后就是第二個Hourglass Network的輸入。
測試
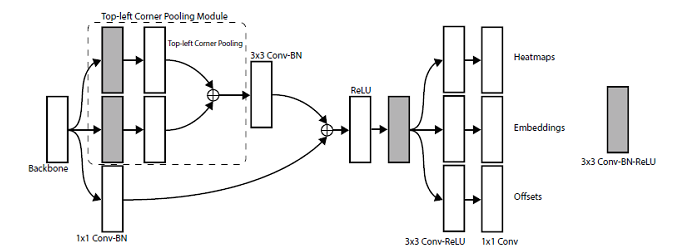
模型整體框架的pipeline就不細說了,前文已經詳細解析過,概括來說就是:Preprocess (7x7Conv+Bn+Relu & Residual Module)->Hourglass Networks->Corner Pooling->Prediction Head(output Heatmaps, Embeddings & Offsets)。
這里主要說明下測試時對圖像的處理和對模型輸出的后處理。
●? 測試圖像處理
測試時對圖像的處理方式還蠻有“個性”,作者在paper中一筆帶過:
Instead of resizing an image to a fixed size, we?maintain the original resolution?of the image and?pad it with zeros?before feeding it to CornerNet.
意思是,不改變圖像分辨率,但使用0填充。但是,具體怎么做的,填充多少部分卻沒有詳細說明(能不能坦誠相對..)。CW對這實在不能忍,看了源碼后,發現是這樣做的:

代碼中?' | 127 '?這種方式會將new height和new width的低7位全部置1,猜測作者這樣做的意思應該是想使得輸入圖像的尺寸至少為128x128吧(聯想到CornerNet訓練時輸入分辨率是511x511,輸出特征圖分辨率正好是128x128)。
最后,將原圖裁剪下來放置在填充的全0圖像中,保持中心對齊,同時會記錄原圖在這個填充圖像中的區域邊界:
![]()
,以便后續將檢測結果還原到原圖坐標空間。也就是說,在網絡輸入圖像中,區域邊界以外的部分都是0。
另外,對于每張圖片,還會將其水平鏡像圖片也一并輸入到網絡中(組成一個batch)進行測試,最終的檢測結果是綜合原圖和鏡像圖片的結果。
OK,再來說說后處理過程,看是如何得到最終檢測結果的。
1. 首先,對heatmaps使用kernel大小為3×3的最大池化層(pad=1),輸出分辨率維持不變。將池化后的heatmaps與原heatmaps作比較,于是可以知道,值改變了的位置就是非極大值位置,將這些位置的值(即置信度)置0,那么這些位置在后續就不可能作為可能的角點位置了,這樣起到了抑制非極大值的作用(paper中稱為NMS,但其實和目標檢測常用的NMS有所區別,這里特別說明下);
2. 然后,從heatmaps中根據置信度選擇top100個左上角和右下角位置(在所有分類下進行,不區分類別),并且根據對應位置預測的offsets來調整角點位置;
3. 接著,計算左上角和右下角(每個左上角都和其余99個右下角)位置對應預測的embeddings之間的距離,距離大于0.5的、屬于不同類別的、坐標關系不滿足(右下角坐標需大于左上角)的角點對就不能匹配成一對;
4. 緊接著,角點已經完成配對,再次根據每對角點的平均置信度(得分)選出top100對,同時它們的平均得分作為各目標的檢測分數;
5. 最后,結合原圖和鏡像圖的以上結果,在各類別下對角點對形成的bbox實施soft-nms(也就是說,soft-nms是對原圖和鏡像圖的預測bbox一并做的,但是分類別進行),如果之后每張圖片保留下來的bbox大于100個,那么去掉多余的,僅保留得分top100的檢測結果。
實驗分析
●? 性能瓶頸
CornerNet同時輸出熱圖、嵌入和偏移,所有這些結果都會影響檢測性能。比如:熱圖中漏檢了任何一個角點就會丟失一個目標、不正確的嵌入將導致許多錯誤的邊界框、預測的偏移不正確則嚴重影響邊界框的定位。
為了理解每個部件對最終的誤差有多大程度的影響,作者通過將預測的熱圖和偏移替換為gt,并在驗證集上評估性能,以此來進行誤差分析:
由實驗結果可知,單獨使用gt熱圖就可以將AP從38.5%提高到74.0%,這表明CornerNet的主要瓶頸在于角點的識別。

●? 對負樣本位置的懲罰度降低
CornerNet在訓練過程中減少了在gt角點位置一定半徑的圓內的負樣本位置的懲罰。為了理解這對檢測性能的影響,作者在實驗中額外訓練了一個沒有降低懲罰度的網絡和另一個有懲罰度降低但半徑值是固定的網絡,然后在驗證集上將它們與CornerNet進行比較:

實驗結果顯示,即使使用固定的半徑值,只要有懲罰度降低就可以將基線的AP提升2.7%,而使用基于物體大小計算出來的半徑則可以進一步將AP提高2.9%。此外,我們看到減少懲罰度特別有利于大中型目標。
思考
最后,CW談談值得思考的幾個點:
1.為何減少對部分負樣本的懲罰有利于大中型目標的檢測,卻對小目標的不友好呢?
可以feel到,大中型目標的尺度相對較大,那么即使角點和gt有些許偏移,也是由較高的可能性生成與gt box充分重疊的bbox的。因此,降低懲罰度的背后實際是提供了更多潛在的正樣本,于是提高了召回率。
相反,小目標尺度較小,對角點位置檢測的要求也因此較為苛刻,對于大中型目標來說降低懲罰度提供了更多潛在的正樣本,但對小目標來說可能它們就是實實在在的負樣本了。另外,通過實驗結果可知,降低懲罰度對于小目標來說其AP比基線也沒有下降太多,可以(寬容地)認為沒有太大影響。
2.后處理時使用max pooling進行非極大值抑制是否不妥?
想象下,如果兩個物體的角點靠得非常近,那么其中一個物體的檢測就很有可能被“誤殺”掉,可憐不..
不知道為何不基于一個置信度閥值去卡掉不好的檢測結果,作者也沒有相關的實驗說明。
3.測試時為何要連鏡像圖也一并輸入進行檢測?
關于這點,作者也沒有給出理由,也沒有給出實驗結果對比如果單獨使用原圖檢測效果如何。CW猜測,使用鏡像圖,可能是為了更充分地檢測角點:
在水平鏡像圖中,右上角和左下角會分別變成左上角和右下角。于是,使用鏡像圖的話,就可以對原圖中相反方向的角點對進行檢測,從而彌補在原圖中檢測角點對不夠充分的問題(由前面的實驗分析可知,CornerNet的主要瓶頸就在于角點的識別)。
4.為何不適用多尺度特征來進行預測?
作者在paper中強調過,僅使用最后一層特征來進行預測:
Unlike many other state-of-the-art detectors, we only use the features from the last layer of the whole network to make predictions.
怎么好像有點驕傲味道?
對于這點,在paper中其實有“半虛半實”地說到過。作者說,特征圖相比于輸入圖像只下采樣了4倍(因此對于小目標影響應該不會太嚴重),而backbone使用的是Hourglass Networks:在一系列下采樣后又上采樣至相同的分辨率,同時其中還添加了skip connection,因此最終的輸出特征能夠同時擁有淺層的全局信息(利于定位)與高層的局部信息(利于識別)。
另外,作者也通過實驗將backbone替換成ResNet with FPN,結果顯示backbone還是使用Hourglass Networks比較好。但是!在實驗中,作者僅使用FPN的最后一層進行預測,要是使用FPN多層的特征進行預測的話,性能誰搞誰低還真說不準..
5.為何基于角點能夠比基于錨框的檢測效果好?
作者在paper中展示了CornerNet與其它anchor-based的檢測器的性能比較,結果顯示CornerNet能夠取得更優的性能。對于這個情況,作者認為:
a). anchor boxes的中心點需要依賴于四條邊,而角點卻只依賴于兩條邊,因此角點更易定位(CW覺得應該叫可確定性更加高比較合適,是否真的更易定位難說..)。同時加上使用了corner pooling(這個專門為角點檢測而服務的大殺器),于是效果會比anchor-based更佳;
b). 本質上采用了更高效的檢測機制:僅使用
![]()
個corners就能替代了
![]()
個可能的anchor boxes對于以上b,解釋下:假設大小的圖像,角點由于僅用位置信息就可代表其可能性,因此有
![]()
;種;而anchor box的可能性除了與中心點位置有關,還與其長、寬相關。中心點位置可能性有
![]()
種,而一個anchor box在固定中心點又有
![]()
種長寬的可能,于是anchor boxes的可能性就是
![]()
?了。
參考鏈接:
paper&code:
https://arxiv.org/abs/1808.01244
https://github.com/princeton-vl/CornerNet
CornerNet: 將目標檢測問題視作關鍵點檢測與配對
)
)




)







)




