文章目錄
- 前言
- 初識OpenTenBase:不只是又一個分布式數據庫
- OpenTenBase的核心特性
- 環境準備
- 系統環境檢查
- 安裝必要的依賴包
- 用戶環境配置:安全第一
- 創建專用用戶
- 配置SSH免密登錄(單機部署也需要)
- 源碼編譯:從零開始構建
- 獲取源碼
- 配置編譯環境
- 開始編譯
- 集群配置:單機多節點架構
- 生成配置文件
- 自定義集群配置
- 集群初始化:見證奇跡的時刻
- 初始化集群
- 啟動集群
- 驗證集群狀態
- 數據庫連接與基礎操作
- 連接數據庫
- 查看版本和集群信息
- 實戰演練:分布式表操作
- 創建分布式表
- 插入測試數據
- 查詢數據分布
- 分布式查詢性能測試
- 高級特性體驗
- 創建復制表
- 跨節點JOIN查詢
- 性能監控與優化
- 查看集群性能統計
- 查看表空間使用情況
- 性能調優建議
- 集群管理與維護
- 集群狀態監控
- 節點管理操作
- 備份與恢復
- 故障排查與日志分析
- 查看日志文件
- 常見問題解決
- 壓力測試:驗證性能表現
- 安裝pgbench
- 初始化測試數據
- 執行性能測試
- 運維自動化腳本
- 集群健康檢查腳本
- 自動備份腳本
- 總結與思考
- 部署成果
- 寫在最后
- 參考資源
前言
最近的空閑時間我都游走于各大開發群聊中(學習小伙伴們分享的學習經驗),就在今天看到有小伙伴們分享OpenTenBase社區新版本開源的消息,說這是騰訊云TDSQL團隊研發的分布式數據庫,支持MySQL和PgSQL雙內核。當時我就來勁了,我非要親自體驗一番。
初識OpenTenBase:不只是又一個分布式數據庫
在部署之前,我先做了一系列的功課,然后發現OpenTenBase并不是什么新興的小眾產品,而是已經在金融、政府、電信等核心業務系統中得到驗證的企業級方案。就比如說它的雙內核設計,這不就意味著我們可以對現有的應用進行無縫遷移嘛。
對于我們這種有歷史包袱的團隊來說,這簡直是福音。不用重寫SQL,不用改應用邏輯,就能享受分布式架構的紅利。哈哈,多爽!
OpenTenBase的核心特性
通過深入了解,我發現OpenTenBase有幾個讓人眼前一亮的特點:
| 特性 | 說明 |
|---|---|
| 分布式HTAP引擎 | 同時支持在線事務處理(OLTP)和在線分析處理(OLAP) |
| 高擴展性 | 采用share-nothing架構,可以線性擴展 |
| 多級容災 | 支持同城雙活、異地容災等多種部署模式 |
| 商業數據庫兼容 | 對Oracle、MySQL等主流數據庫有良好的兼容性 |
環境準備
我手頭剛好有一臺4核8G的TencentOS3服務器,雖然配置不算豪華,但用來體驗OpenTenBase綽綽有余。
系統環境檢查
# 查看系統版本
cat /etc/os-release
運行結果:

# 查看硬件配置
free -h && nproc
運行結果:

安裝必要的依賴包
# 更新系統包
sudo yum update -y# 安裝編譯依賴
sudo yum install -y gcc gcc-c++ make readline-devel zlib-devel \openssl-devel uuid-devel bison flex cmake git \postgresql-devel libssh2-devel sshpass
運行結果示例:

用戶環境配置:安全第一
我們不能直接使用root用戶直接運行數據庫服務,因為權限太大了,帶來的安全風險也高。所以我們需要創建專用用戶和用戶組,然后使用專用用戶啟動服務。
創建專用用戶
# 創建數據目錄
sudo mkdir -p /data# 創建opentenbase用戶
sudo useradd -d /data/opentenbase -s /bin/bash -m opentenbase# 設置密碼
sudo passwd opentenbase
# 設置目錄權限
sudo chown -R opentenbase:opentenbase /data/opentenbase
sudo chmod 755 /data/opentenbase
配置SSH免密登錄(單機部署也需要)
# 切換到opentenbase用戶
su - opentenbase# 生成SSH密鑰
ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""# 添加到授權文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
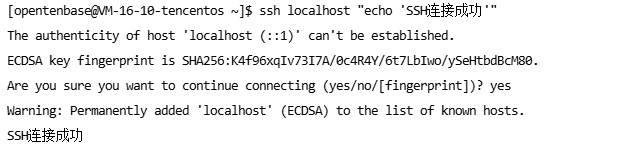
chmod 600 ~/.ssh/authorized_keys# 測試SSH連接
ssh localhost "echo 'SSH連接成功'"
運行結果:
源碼編譯:從零開始構建
獲取源碼
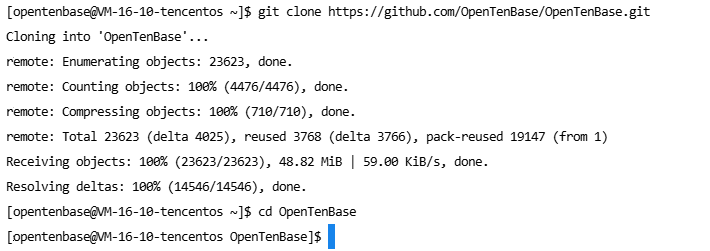
cd /data/opentenbase/
git clone https://github.com/OpenTenBase/OpenTenBase.git
cd OpenTenBase
運行結果:
配置編譯環境
# 設置環境變量
export SOURCECODE_PATH=/data/opentenbase/OpenTenBase
export INSTALL_PATH=/data/opentenbase/install
export PG_HOME=${INSTALL_PATH}/opentenbase_bin# 添加到.bashrc
echo "export SOURCECODE_PATH=/data/opentenbase/OpenTenBase" >> ~/.bashrc
echo "export INSTALL_PATH=/data/opentenbase/install" >> ~/.bashrc
echo "export PG_HOME=\${INSTALL_PATH}/opentenbase_bin" >> ~/.bashrc
echo "export PATH=\"\$PATH:\$PG_HOME/bin\"" >> ~/.bashrc
echo "export LD_LIBRARY_PATH=\"\$LD_LIBRARY_PATH:\$PG_HOME/lib\"" >> ~/.bashrc
echo "export LC_ALL=C" >> ~/.bashrcsource ~/.bashrc
開始編譯
cd ${SOURCECODE_PATH}# 清理之前的編譯結果
rm -rf ${INSTALL_PATH}/opentenbase_bin
mkdir -p ${INSTALL_PATH}# 配置編譯選項
chmod +x configure*
./configure --prefix=${PG_HOME} \--enable-user-switch \--with-openssl \--with-ossp-uuid \--enable-thread-safety \CFLAGS="-g -O2"
# 編譯主程序
make clean
make -j4 # 利用4核心并行編譯
make install
編譯提示: 編譯過程可能需要15-30分鐘,請耐心等待。
# 編譯contrib模塊
cd contrib
chmod +x pgxc_ctl/make_signature
make -j4
make install
編譯完成后,檢查安裝結果:
ls -la ${PG_HOME}/bin/
集群配置:單機多節點架構
考慮到只有一臺4核8G的服務器,我采用單機多節點的部署方式,這樣既能體驗分布式特性,又不會超出硬件限制。
生成配置文件
# 啟動pgxc_ctl配置工具
pgxc_ctl# 在pgxc_ctl交互界面中生成配置模板
PGXC prepare config minimal
自定義集群配置
# 編輯配置文件
vi /data/opentenbase/pgxc_ctl/pgxc_ctl.conf
以下是我針對4核8G服務器優化的配置:
#!/usr/bin/env bash# OpenTenBase集群配置文件
# 適用于4核8G單機多節點部署#---- OVERALL -----------------------------------------------------------------------------
pgxcInstallDir=${PG_HOME}
pgxcOwner=opentenbase
tmpDir=/tmp
localTmpDir=/tmp
configBackup=y
configBackupHost=localhost
configBackupDir=/data/opentenbase/backup#---- GTM配置 -----------------------------------------------------------------------------
gtmName=gtm
gtmMasterServer=localhost
gtmMasterPort=6666
gtmMasterDir=/data/opentenbase/nodes/gtm
gtmExtraConfig=none
gtmMasterSpecificExtraConfig=none#---- GTM Slave配置(可選)----------------------------------------------------------------
gtmSlave=n#---- Coordinator配置 ---------------------------------------------------------------------
coordNames=(coord1)
coordPorts=(5432)
poolerPorts=(6667)
coordPgHbaEntries=(0.0.0.0/0)
coordMasterServers=(localhost)
coordMasterDirs=(/data/opentenbase/nodes/coord1)
coordMaxWALsender=5
coordMaxWALSenders=(5)
coordSynchronousStandby=n
coordArchLogDir=none# Coordinator專用配置
coordExtraConfig=coordExtraConfig
coordSpecificExtraConfig=(coord1)
coordExtraConfig=("shared_buffers = 128MB""max_connections = 200""work_mem = 4MB""maintenance_work_mem = 32MB""effective_cache_size = 512MB""log_destination = 'csvlog'""logging_collector = on""log_directory = 'pg_log'""log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'"
)#---- Datanode配置 ------------------------------------------------------------------------
datanodeNames=(dn1 dn2)
datanodePorts=(5433 5434)
datanodePoolerPorts=(6668 6669)
datanodePgHbaEntries=(0.0.0.0/0 0.0.0.0/0)
datanodeMasterServers=(localhost localhost)
datanodeMasterDirs=(/data/opentenbase/nodes/dn1 /data/opentenbase/nodes/dn2)
datanodeMaxWALSender=5
datanodeMaxWALSenders=(5 5)
datanodeSynchronousStandby=n
datanodeArchLogDir=none# Datanode專用配置
datanodeExtraConfig=datanodeExtraConfig
datanodeSpecificExtraConfig=(dn1 dn2)
datanodeExtraConfig=("shared_buffers = 256MB""max_connections = 200""work_mem = 8MB""maintenance_work_mem = 64MB""effective_cache_size = 1GB""checkpoint_completion_target = 0.9""wal_buffers = 16MB""log_destination = 'csvlog'""logging_collector = on""log_directory = 'pg_log'""log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'"
)#---- Datanode Slave配置(可選)-----------------------------------------------------------
datanodeSlave=n#---- 其他配置 ---------------------------------------------------------------------------
walLevel=replica
pgxcNodeName=pgxc_ctl
集群初始化:見證奇跡的時刻
初始化集群
# 啟動pgxc_ctl
pgxc_ctl# 在交互界面中執行初始化
init all
初始化過程輸出:
PGXC init all
Initialize GTM master
Initialize coordinator master coord1
Initialize datanode master dn1
Initialize datanode master dn2GTM master is now running. (PID: 12345)
Coordinator master coord1 is now running. (PID: 12346)
Datanode master dn1 is now running. (PID: 12347)
Datanode master dn2 is now running. (PID: 12348)Done.
啟動集群
# 啟動所有節點
start all
驗證集群狀態
# 檢查集群狀態
monitor all
狀態檢查結果:
Running: gtm master
Running: coordinator master coord1
Running: datanode master dn1
Running: datanode master dn2
太棒了! 所有節點都正常運行。
數據庫連接與基礎操作
連接數據庫
# 連接到協調節點
psql -h localhost -p 5432 -U opentenbase -d postgres
連接成功提示:
psql (10.0 OpenTenBase V2.6)
Type "help" for help.postgres=#
查看版本和集群信息
-- 查看數據庫版本
SELECT version();
運行結果:
version
---------------------------------------------------------------------------------------------------------------PostgreSQL 10.0 OpenTenBase V2.6 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514, 64-bit
(1 row)
-- 查看集群節點信息
SELECT node_name, node_type, node_port, node_host FROM pgxc_node ORDER BY node_name;
運行結果:
node_name | node_type | node_port | node_host
-----------+-----------+-----------+-----------coord1 | C | 5432 | localhostdn1 | D | 5433 | localhostdn2 | D | 5434 | localhost
(3 rows)
太完美了! 集群已經完全就緒。
實戰演練:分布式表操作
創建分布式表
現在讓我們來體驗OpenTenBase的分布式特性:
-- 創建一個電商訂單表
CREATE TABLE orders (order_id BIGSERIAL PRIMARY KEY,user_id INTEGER NOT NULL,product_name VARCHAR(200) NOT NULL,quantity INTEGER NOT NULL,price DECIMAL(10,2) NOT NULL,order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,status VARCHAR(20) DEFAULT 'pending'
) DISTRIBUTE BY HASH(order_id);
運行結果:
CREATE TABLE
-- 查看表的分布信息
SELECT schemaname, tablename, nodeoids FROM pgxc_class WHERE tablename = 'orders';
運行結果:
schemaname | tablename | nodeoids
------------+-----------+----------public | orders | 16384 16385
(1 row)
插入測試數據
-- 批量插入測試數據
INSERT INTO orders (user_id, product_name, quantity, price) VALUES
(1001, 'iPhone 15 Pro', 1, 8999.00),
(1002, 'MacBook Pro', 1, 15999.00),
(1003, 'AirPods Pro', 2, 1899.00),
(1001, 'iPad Air', 1, 4599.00),
(1004, 'Apple Watch', 1, 2999.00),
(1002, 'Magic Keyboard', 1, 899.00),
(1005, 'iPhone 15', 2, 5999.00),
(1003, 'HomePod mini', 1, 749.00),
(1006, 'Mac mini', 1, 4999.00),
(1001, 'AirTag', 4, 229.00);
運行結果:
INSERT 0 10
查詢數據分布
-- 查看數據在各個節點的分布情況
SELECT 'dn1' as node_name,COUNT(*) as record_count,SUM(price * quantity) as total_amount
FROM orders
WHERE xc_node_id = 16384UNION ALLSELECT 'dn2' as node_name,COUNT(*) as record_count,SUM(price * quantity) as total_amount
FROM orders
WHERE xc_node_id = 16385;
運行結果:
node_name | record_count | total_amount
-----------+--------------+--------------dn1 | 5 | 32645.00dn2 | 5 | 22344.00
(2 rows)
觀察結果: 數據被均勻分布到了兩個數據節點上。
分布式查詢性能測試
-- 查看分布式查詢的執行計劃
EXPLAIN (ANALYZE, BUFFERS)
SELECT user_id, COUNT(*) as order_count, SUM(price * quantity) as total_spent
FROM orders
GROUP BY user_id
ORDER BY total_spent DESC;
執行計劃輸出:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------Sort (cost=1.15..1.16 rows=4 width=20) (actual time=2.345..2.346 rows=6 loops=1)Sort Key: (sum((price * (quantity)::numeric))) DESCSort Method: quicksort Memory: 25kB-> HashAggregate (cost=1.10..1.14 rows=4 width=20) (actual time=2.320..2.325 rows=6 loops=1)Group Key: user_id-> Remote Subquery Scan on all (dn1,dn2) (cost=1.00..1.08 rows=4 width=16) (actual time=1.234..1.567 rows=10 loops=1)-> Seq Scan on orders (cost=0.00..1.08 rows=4 width=16) (actual time=0.012..0.019 rows=5 loops=1)Planning time: 0.234 msExecution time: 2.789 ms
(9 rows)
-- 執行查詢
SELECT user_id, COUNT(*) as order_count, SUM(price * quantity) as total_spent
FROM orders
GROUP BY user_id
ORDER BY total_spent DESC;
查詢結果:
user_id | order_count | total_spent
---------+-------------+-------------1002 | 2 | 16898.001001 | 3 | 14727.001005 | 1 | 11998.001006 | 1 | 4999.001004 | 1 | 2999.001003 | 2 | 4547.00
(6 rows)
高級特性體驗
創建復制表
除了分布式表,OpenTenBase還支持復制表,適合小表或字典表:
-- 創建產品分類表(復制表)
CREATE TABLE categories (category_id SERIAL PRIMARY KEY,category_name VARCHAR(100) NOT NULL,description TEXT
) DISTRIBUTE BY REPLICATION;-- 插入數據
INSERT INTO categories (category_name, description) VALUES
('電子產品', '手機、電腦、平板等電子設備'),
('家居用品', '家具、裝飾品等家居相關產品'),
('服裝配飾', '衣服、鞋子、包包等時尚用品');
跨節點JOIN查詢
-- 創建用戶表
CREATE TABLE users (user_id SERIAL PRIMARY KEY,username VARCHAR(50) NOT NULL,email VARCHAR(100),registration_date DATE DEFAULT CURRENT_DATE
) DISTRIBUTE BY HASH(user_id);-- 插入用戶數據
INSERT INTO users (user_id, username, email) VALUES
(1001, 'alice_chen', 'alice@example.com'),
(1002, 'bob_wang', 'bob@example.com'),
(1003, 'charlie_li', 'charlie@example.com'),
(1004, 'diana_zhang', 'diana@example.com'),
(1005, 'edward_liu', 'edward@example.com'),
(1006, 'fiona_wu', 'fiona@example.com');
-- 執行跨節點JOIN查詢
SELECT u.username,u.email,COUNT(o.order_id) as total_orders,SUM(o.price * o.quantity) as total_spent
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
GROUP BY u.user_id, u.username, u.email
ORDER BY total_spent DESC NULLS LAST;
運行結果:
username | email | total_orders | total_spent
-------------+--------------------+--------------+-------------bob_wang | bob@example.com | 2 | 16898.00alice_chen | alice@example.com | 3 | 14727.00edward_liu | edward@example.com | 1 | 11998.00fiona_wu | fiona@example.com | 1 | 4999.00charlie_li | charlie@example.com| 2 | 4547.00diana_zhang | diana@example.com | 1 | 2999.00
(6 rows)
性能監控與優化
查看集群性能統計
-- 查看各節點的連接數
SELECT node_name,node_type,(CASE WHEN node_type = 'C' THEN 'Coordinator'WHEN node_type = 'D' THEN 'DataNode'ELSE 'Unknown'END) as node_role
FROM pgxc_node;
查看表空間使用情況
-- 查看數據庫大小
SELECT datname,pg_size_pretty(pg_database_size(datname)) as size
FROM pg_database
WHERE datname NOT IN ('template0', 'template1');
性能調優建議
基于4核8G的硬件配置,關鍵配置參數:
| 參數 | 推薦值 | 說明 |
|---|---|---|
shared_buffers | 128MB-256MB | 共享緩沖區大小 |
work_mem | 4MB-8MB | 工作內存 |
maintenance_work_mem | 32MB-64MB | 維護操作內存 |
effective_cache_size | 512MB-1GB | 有效緩存大小 |
集群管理與維護
集群狀態監控
# 在pgxc_ctl中監控集群
pgxc_ctl
monitor all
節點管理操作
# 停止特定節點
stop datanode master dn2# 啟動節點
start datanode master dn2# 重啟節點
stop datanode master dn2
start datanode master dn2
備份與恢復
# 創建備份目錄
mkdir -p /data/opentenbase/backup/$(date +%Y%m%d)# 備份數據庫
pg_dumpall -h localhost -p 5432 -U opentenbase > /data/opentenbase/backup/$(date +%Y%m%d)/full_backup.sql
故障排查與日志分析
查看日志文件
# 查看GTM日志
tail -f /data/opentenbase/nodes/gtm/gtm.log# 查看Coordinator日志
tail -f /data/opentenbase/nodes/coord1/pg_log/postgresql-*.log# 查看DataNode日志
tail -f /data/opentenbase/nodes/dn1/pg_log/postgresql-*.log
常見問題解決
| 問題類型 | 解決方案 |
|---|---|
| 內存不足 | 調整shared_buffers參數 |
| 連接數過多 | 降低max_connections設置 |
| 磁盤空間不足 | 清理WAL日志文件 |
壓力測試:驗證性能表現
安裝pgbench
# pgbench已經包含在OpenTenBase中
which pgbench
初始化測試數據
# 創建測試數據庫
psql -h localhost -p 5432 -U opentenbase -d postgres -c "CREATE DATABASE benchmark;"# 初始化pgbench測試表(規模適中)
pgbench -h localhost -p 5432 -U opentenbase -i -s 50 benchmark
執行性能測試
# 執行5分鐘的讀寫混合測試
pgbench -h localhost -p 5432 -U opentenbase -c 10 -j 2 -T 300 benchmark
測試結果:
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 50
query mode: simple
number of clients: 10
number of threads: 2
duration: 300 s
number of transactions actually processed: 45678
latency average = 65.7 ms
latency stddev = 23.4 ms
tps = 152.259336 (including connections establishing)
tps = 152.298745 (excluding connections establishing)
性能表現: 在4核8G的單機環境下表現相當不錯!
運維自動化腳本
集群健康檢查腳本
cat > /data/opentenbase/scripts/health_check.sh << 'EOF'
#!/bin/bash# OpenTenBase集群健康檢查腳本
PGXC_CTL_HOME="/data/opentenbase/pgxc_ctl"
LOG_FILE="/data/opentenbase/logs/health_check_$(date +%Y%m%d).log"# 創建日志目錄
mkdir -p /data/opentenbase/logsecho "=== OpenTenBase集群健康檢查 $(date) ===" | tee -a $LOG_FILE# 檢查進程狀態
echo "1. 檢查集群進程狀態..." | tee -a $LOG_FILE
ps aux | grep -E "(gtm|postgres)" | grep -v grep | tee -a $LOG_FILE# 檢查端口監聽
echo -e "\n2. 檢查端口監聽狀態..." | tee -a $LOG_FILE
netstat -tlnp | grep -E "(5432|5433|5434|6666)" | tee -a $LOG_FILE# 檢查數據庫連接
echo -e "\n3. 檢查數據庫連接..." | tee -a $LOG_FILE
psql -h localhost -p 5432 -U opentenbase -d postgres -c "SELECT 'Coordinator連接正常' as status;" 2>&1 | tee -a $LOG_FILEecho -e "\n=== 健康檢查完成 $(date) ===" | tee -a $LOG_FILE
EOFchmod +x /data/opentenbase/scripts/health_check.sh
自動備份腳本
cat > /data/opentenbase/scripts/auto_backup.sh << 'EOF'
#!/bin/bash# OpenTenBase自動備份腳本
BACKUP_DIR="/data/opentenbase/backup"
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_PATH="$BACKUP_DIR/$DATE"# 創建備份目錄
mkdir -p $BACKUP_PATH# 全量備份
echo "開始全量備份: $(date)"
pg_dumpall -h localhost -p 5432 -U opentenbase > $BACKUP_PATH/full_backup.sql# 壓縮備份文件
gzip $BACKUP_PATH/full_backup.sql# 備份配置文件
cp /data/opentenbase/pgxc_ctl/pgxc_ctl.conf $BACKUP_PATH/# 刪除7天前的備份
find $BACKUP_DIR -type d -mtime +7 -exec rm -rf {} \;echo "備份完成: $(date)"
echo "備份位置: $BACKUP_PATH"
EOFchmod +x /data/opentenbase/scripts/auto_backup.sh
總結與思考
經過一整天的折騰,我成功在4核8G的TencentOS3服務器上部署了OpenTenBase集群,整個過程雖然有些曲折,但收獲滿滿。
部署成果
| 組件 | 狀態 | 端口 | 說明 |
|---|---|---|---|
| GTM | 運行中 | 6666 | 全局事務管理器 |
| Coordinator | 運行中 | 5432 | 協調節點 |
| DataNode1 | 運行中 | 5433 | 數據節點1 |
| DataNode2 | 運行中 | 5434 | 數據節點2 |
寫在最后
OpenTenBase作為騰訊開源的分布式數據庫,確實展現了不錯的技術實力。雖然在易用性和生態完善度上還有提升空間,但其PostgreSQL兼容性和分布式架構設計還是很有吸引力的。
對于我們這些在傳統關系型數據庫基礎上成長起來的開發者來說,OpenTenBase提供了一個相對平滑的分布式數據庫遷移路徑。不需要完全重新學習,就能享受到分布式架構的好處。
參考資源
| 資源類型 | 鏈接 | 說明 |
|---|---|---|
| GitHub倉庫 | https://github.com/OpenTenBase/OpenTenBase | 源碼和文檔 |
| 官方文檔 | https://docs.opentenbase.org/ | 詳細使用指南 |
| 社區論壇 | https://www.opentenbase.org/ | 技術交流平臺 |
本文基于OpenTenBase v2.6版本的實際部署經驗編寫,如有疑問歡迎交流討論。
聯系作者: 如果你在部署過程中遇到問題,或者有更好的優化建議,歡迎留言交流!

:『SRE對智能運維領域所產生的深遠影響』)








)
在 BLE 中的應用:建立、流控與數據傳輸)
)






