PE: position embedding
一、PETR算法動機回歸
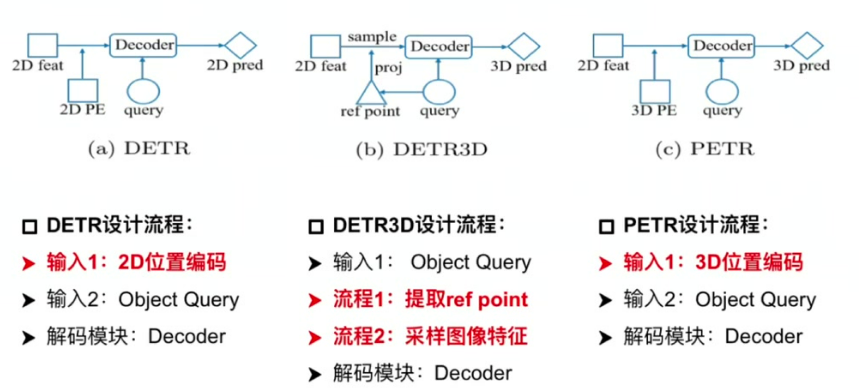
1.1 DETR
輸入組成:包含2D位置編碼和Object Query
核心流程:通過Object Query直接索引2D特征圖,結合位置編碼迭代更新Query
特點:整體流程簡潔,每個Query代表一個潛在目標
1.2 DETR3D
特征采樣機制:通過Query生成3D參考點,反投影到2D圖像采樣特征
存在問題:
- 投影偏差:參考點位置出錯會導致特征采樣失效
- 特征局限性:僅使用單點特征導致全局信息學習不足
- 流程復雜度:需要反復投影和特征重采樣,影響落地效率
二、PETR網絡結構
三種結構的對比
核心改進:引入3D位置編碼生成3D感知特征
關鍵技術:
- 特征融合:將2D圖像特征與3D位置編碼結合形成
- 流程簡化:省略反投影步驟,直接建立3D語義環境
- 優勢:避免特征采樣偏差,增強全局特征學習能力
PETR網絡結構
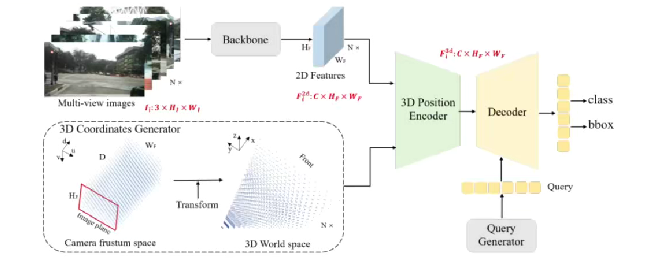
1. Image-view Encoder設計流程
輸入輸出:處理6視角圖像(如nuScenes數據集),輸出多尺度特征
Backbone選擇:支持ResNet/Swin Transformer等架構
特征處理:
- 初始特征:維度為(原始圖像) 3HW
- 輸出特征:通過FPN得到的多尺度融合特征 C * Hf * Wf
2. 3D Coordinates Generator設計流程
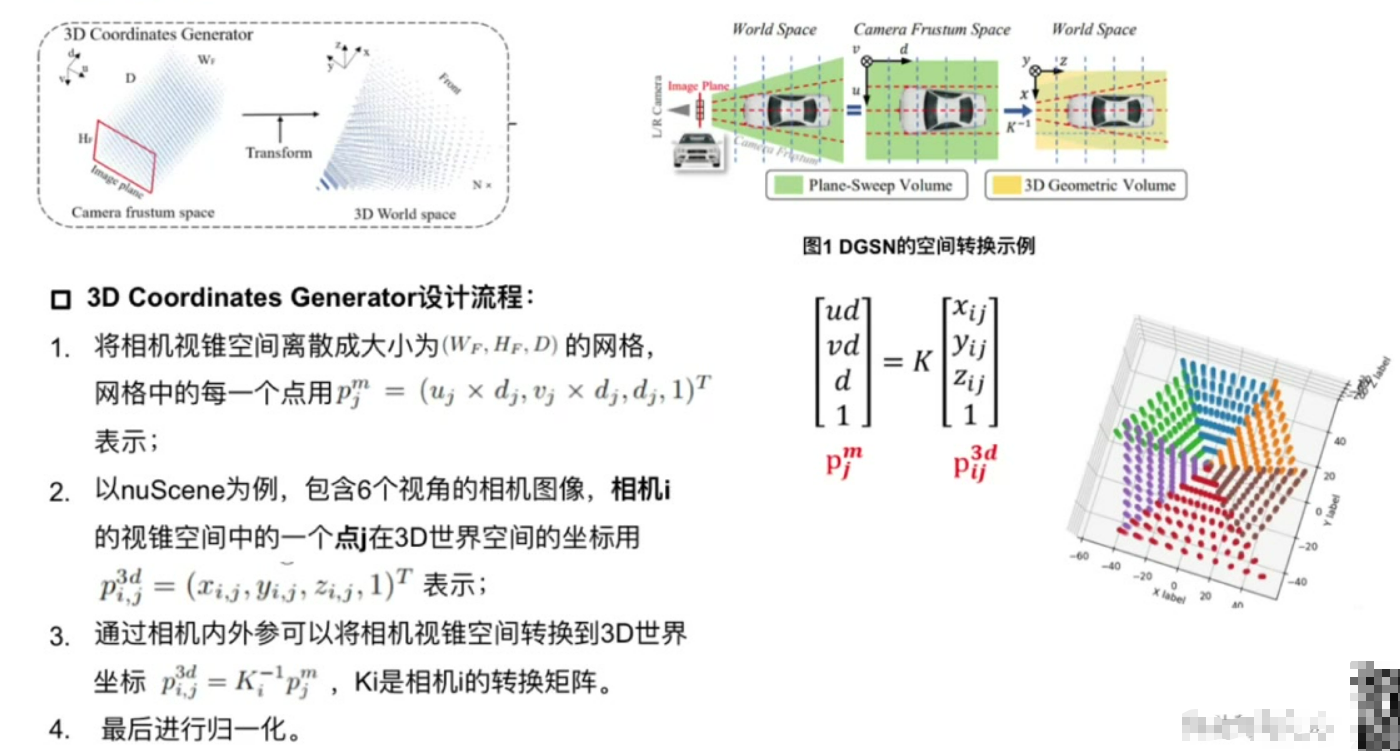
空間離散化:將相機視錐空間劃分為三維網格
坐標轉換:
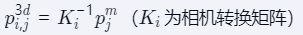
實現步驟:
- 像素坐標與深度值構成網格點
- 通過相機內外參轉換到世界坐標系
- 對6視角結果進行歸一化處理
輸出特性:不同視角轉換結果存在重疊區域,共同構成完整3D空間
3. 3D Position Encoder設計流程
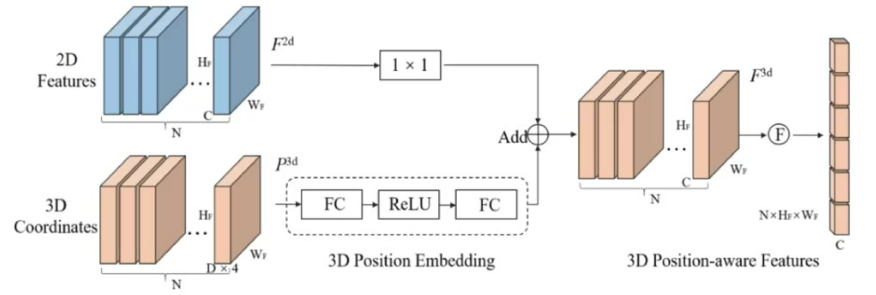
雙支路處理:
- 圖像特征支路:使用1×1卷積進行通道降維
- 坐標支路:通過3D PE模塊對齊維度
特征融合:
- 操作方式:將處理后的2D特征與3D坐標特征相加
- 輸出特性:生成具有位置感知的3D特征
后續處理:展平后與Object Query共同輸入Decoder進行預測
三、PETR損失函數
損失組成: 包含分類損失和回歸框損失等標準3D檢測損失
結構特點: 與DETR3D等模型采用相同的損失函數設計
訓練穩定性: 通過CBGS(Class Balanced Grouping and Sampling)策略進行訓練優化
四、PETR性能對比
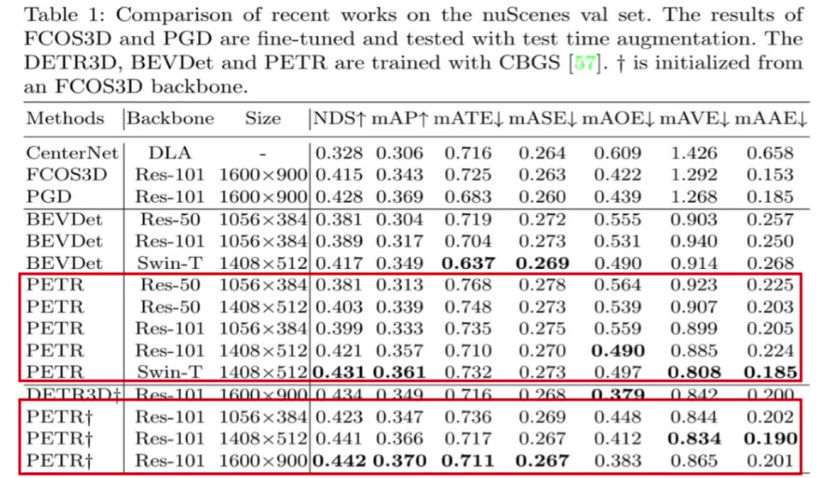
分辨率影響: 高分辨率圖像(如1600×900)性能明顯優于低分辨率(1056×384)
Backbone影響: ResNet101性能優于ResNet50,Swin Transformer表現最佳
收斂特性: 相比DETR3D收斂速度較慢,需要更長訓練時間
位置編碼優勢: 3D位置編碼(3D PE)相比傳統2D PE帶來顯著性能提升
五、PETR V2
5.1 網絡結構
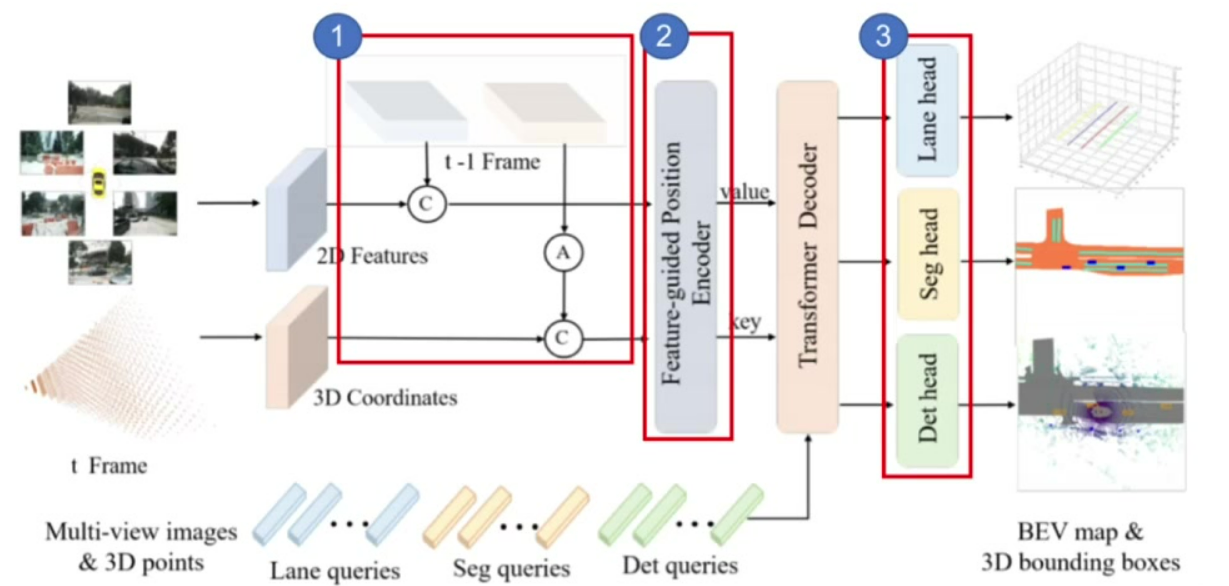
核心改進: 引入時序建模和多任務學習兩大創新點
時序建模: 通過姿態變換對齊歷史幀3D坐標,實現隱式時序特征融合,如圖中模塊1
多任務擴展: 新增分割頭和車道線檢測任務,形成統一感知框架,如圖中模塊3
5.2 多任務學習
任務類型: 同時支持3D檢測、BEV分割和車道線檢測
查詢設計: 針對不同任務設計專用Query(Det/Seg/Lane queries)
性能優勢: 多任務聯合訓練帶來各任務性能的協同提升
5.3 網絡結構與輸入輸出
輸入保持: 延續多視角RGB圖像輸入
輸出擴展: 除3D檢測框外,新增分割mask和車道線輸出
特征提取: 支持ResNet/Swin Transformer等多種backbone
5.4 特征提取與融合
2D特征提取: 通過共享backbone提取多視角圖像特征
3D坐標生成: 將視錐空間坐標轉換為世界坐標系
特征融合: 通過改進的position encoder融合2D特征和3D坐標
5.5 時序信息處理
關鍵創新: 通過實現歷史幀3D坐標對齊
性能驗證: 時序建模顯著提升運動物體檢測精度
5.6 檢測任務擴展
檢測頭改進: 在原有檢測頭基礎上增加分割分支
查詢機制: 不同任務使用獨立可學習的query向量
聯合優化: 通過多任務損失函數實現端到端訓練
5.7 實驗性能與結論
綜合性能: 在nuScenes等基準測試中達到SOTA水平
計算效率: 保持實時性(FPS>10)的同時提升精度
框架優勢: 驗證了統一感知框架的可行性




)
在 BLE 中的應用:建立、流控與數據傳輸)
)







部署技術與框架)


)

