📊 Unicode 字符串轉 UTF-8 編碼算法剖析
——從 C# char 到 C++ wchar_t 的編碼轉換原理
引用:UTF-8 編解碼可視化分析
🔍 1. 算法功能概述
該函數將 Unicode 字符串(C# string)轉換為 UTF-8 編碼的字節數組,同時輸出有效字節數 count。
核心流程:
- 計算 UTF-8 編碼所需字節數
- 分配緩沖區(額外預留 3 字節)
- 逐字符編碼為 UTF-8 字節序列
🧠 2. 算法原理與 UTF-8 編碼規則
UTF-8 是變長編碼,規則如下:
| Unicode 碼點范圍 | UTF-8 字節序列結構 | 字節數 | 位模式圖示 |
|---|---|---|---|
U+0000 ~ U+007F | 0xxxxxxx | 1 | [0xxx xxxx] |
U+0080 ~ U+07FF | 110xxxxx 10xxxxxx | 2 | [110x xxxx] [10xx xxxx] |
U+0800 ~ U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 3 | [1110 xxxx] [10xx xxxx] [10xx xxxx] |
💡 注:C#
char為 16 位 Unicode,C++wchar_t在 Windows 中與之等價(Linux 為 32 位)。
🔄 3. 算法流程詳解
步驟 1:計算 UTF-8 字節數
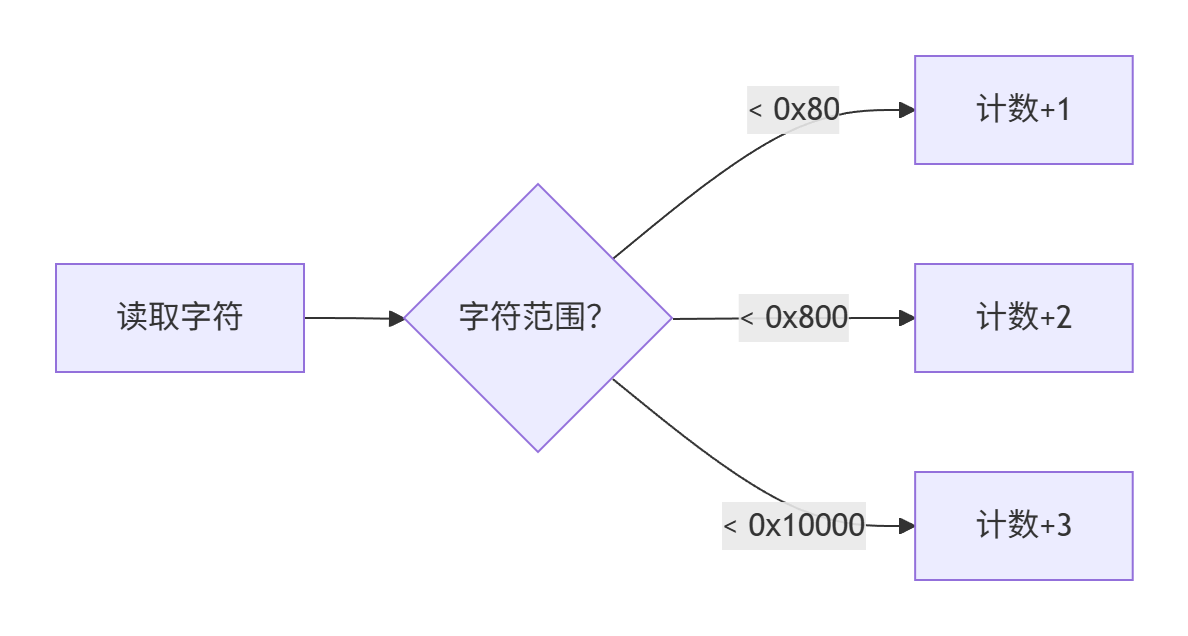
int k = 0;
while (i < s.Length) {char ch = s[i++];if (ch < 0x80) k++; // ASCII 字符(1 字節)else if (ch < 0x800) k += 2; // 2 字節字符else if (ch < 0x10000) k += 3; // 3 字節字符(含 CJK 字符)
}
count = k; // 輸出有效字節數
- 時間復雜度:O(n),需遍歷整個字符串。
步驟 2:分配緩沖區
buf = new byte[count + 3]; // 額外分配 3 字節(安全填充)
- 為什么 +3?
預留空間防止溢出(UTF-8 單字符最多占 3 字節),確保寫入安全。
步驟 3:編碼轉換(核心)
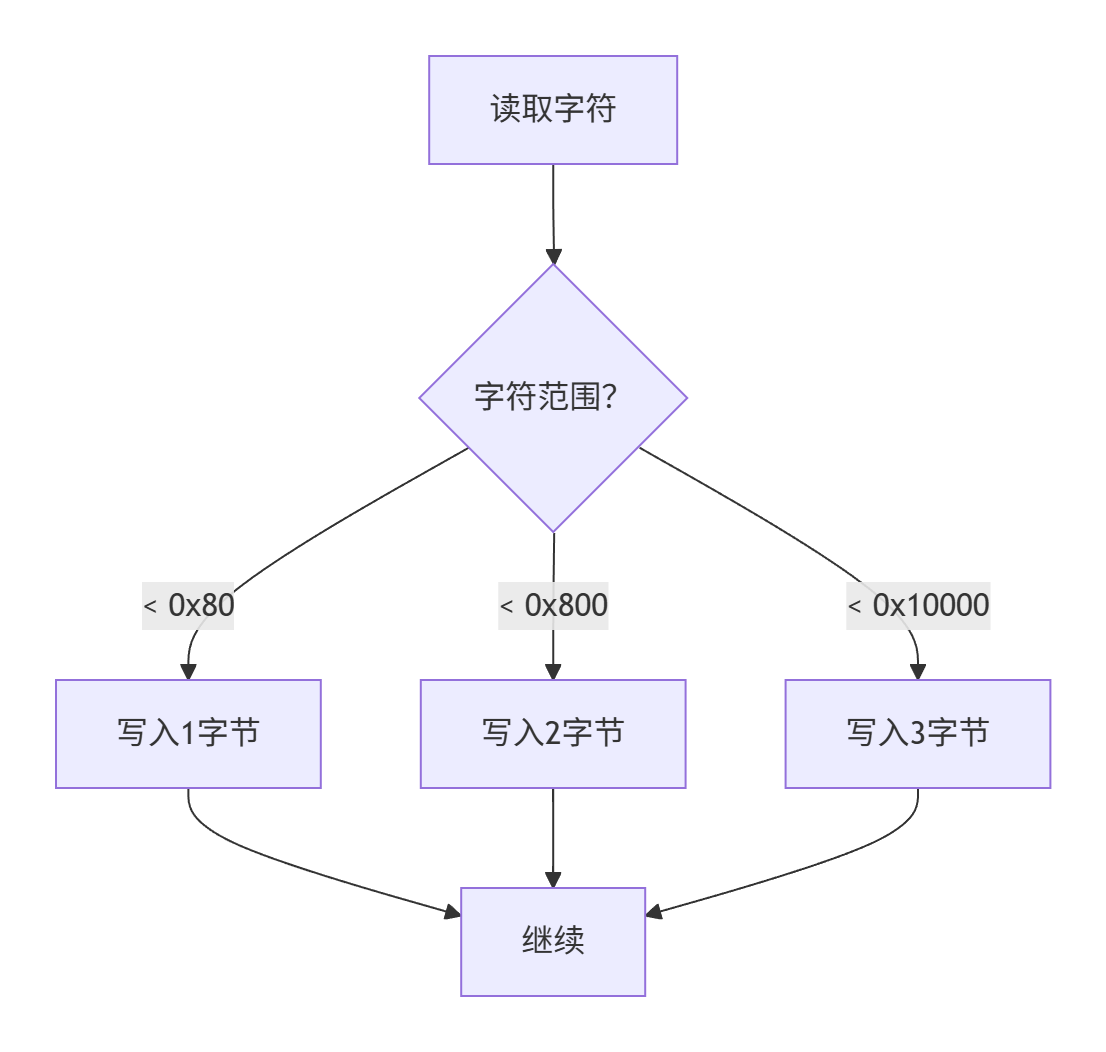
fixed (byte* p = buf) { // 固定內存地址(避免 GC 移動)while (i < s.Length) {char ch = s[i++];// 1 字節編碼(ASCII)if (ch < 0x80) p[k++] = (byte)(ch & 0xFF); // 2 字節編碼(拉丁字母擴展)else if (ch < 0x800) {p[k++] = (byte)(((ch >> 6) & 0x1F) | 0xC0); // 110xxxxxp[k++] = (byte)((ch & 0x3F) | 0x80); // 10xxxxxx}// 3 字節編碼(中/日/韓文字符)else if (ch < 0x10000) {p[k++] = (byte)(((ch >> 12) & 0x0F) | 0xE0); // 1110xxxxp[k++] = (byte)(((ch >> 6) & 0x3F) | 0x80); // 10xxxxxxp[k++] = (byte)((ch & 0x3F) | 0x80); // 10xxxxxx}}
}
- 位操作解析:
?? 4. 算法局限性
- 不支持代理對(Surrogate Pairs):
無法處理U+10000以上的字符(如 emoji 𠮷),需補充 4 字節編碼邏輯。 - 緩沖區浪費:多分配 3 字節(可通過精確計算優化)。
📝 5. 完整代碼(含逐行注釋)
public static byte[] GetUTF8StringBuffer(string s, out int count)
{count = 0; // 初始化輸出參數if (s == null){throw new ArgumentNullException("s"); // 空字符串檢查}byte[] buf = null; // 存儲結果的字節數組int k = 0; // 臨時計數器(字節數/寫入位置)int i = 0; // 字符串遍歷索引// === 步驟 1:計算 UTF-8 編碼所需字節數 ===while (i < s.Length){char ch = s[i++]; // 逐個讀取字符if (ch < 0x80) // ASCII 字符(0x00 ~ 0x7F){k++; // 占 1 字節}else if (ch < 0x800) // 0x80 ~ 0x7FF(拉丁字母擴展){k += 2; // 占 2 字節}else if (ch < 0x10000) // 0x800 ~ 0xFFFF(CJK 字符等){k += 3; // 占 3 字節}}// === 步驟 2:分配緩沖區(額外 +3 字節) ===buf = new byte[(count = k) + 3]; // count 賦值為 k,總長度 = k+3// === 步驟 3:編碼轉換(不安全代碼塊) ===unsafe // 啟用不安全代碼{fixed (byte* p = buf) // 固定緩沖區內存地址{i = 0; // 重置字符串索引k = 0; // 重置字節數組索引while (i < s.Length){char ch = s[i++]; // 讀取下一個字符// --- 1 字節編碼 ---if (ch < 0x80){p[k++] = (byte)(ch & 0xFF); // 直接存儲低 8 位}// --- 2 字節編碼 ---else if (ch < 0x800){// 構造首字節:110xxxxx (0xC0 | 高 5 位)p[k++] = (byte)(((ch >> 6) & 0x1F) | 0xC0);// 構造次字節:10xxxxxx (0x80 | 低 6 位)p[k++] = (byte)((ch & 0x3F) | 0x80);}// --- 3 字節編碼 ---else if (ch < 0x10000){// 構造首字節:1110xxxx (0xE0 | 高 4 位)p[k++] = (byte)(((ch >> 12) & 0x0F) | 0xE0);// 構造次字節:10xxxxxx (0x80 | 中 6 位)p[k++] = (byte)(((ch >> 6) & 0x3F) | 0x80);// 構造尾字節:10xxxxxx (0x80 | 低 6 位)p[k++] = (byte)((ch & 0x3F) | 0x80);}}}}return buf; // 返回 UTF-8 字節數組
}
🎯 6. 總結
- 核心價值:高效實現 Unicode 到 UTF-8 的轉換,適用于網絡傳輸或跨語言交互。
- 優化方向:
- 支持 4 字節編碼(代理對)
- 移除多余緩沖區分配
- 使用
Span<byte>提升性能

添加建筑glb模型,添加陰影效果,設置陰影顏色和透明度)





)






![【URP】[法線貼圖]為什么主要是藍色的?](http://pic.xiahunao.cn/【URP】[法線貼圖]為什么主要是藍色的?)


)

