摘要: 裂縫是結構健康的重要隱患,傳統人工巡檢耗時耗力且易遺漏。本文將帶您利用當前最先進的YOLO12實例分割模型,構建一個高效、準確、更高精度的裂縫檢測系統。我們將從數據準備、模型訓練到結果可視化,手把手實現一個完整的項目,代碼開源,開箱即用!
關鍵詞: YOLO12, 實例分割, 裂縫檢測, 計算機視覺, 深度學習, PyTorch, OpenCV
【圖像算法 - 14】精準識別路面墻體裂縫:基于YOLO12與OpenCV的實例分割智能檢測實戰(附完整代碼)
1. 引言:裂縫檢測的挑戰與AI的機遇
橋梁、道路、建筑墻體等基礎設施的裂縫是評估其安全狀況的關鍵指標。及時發現并量化裂縫信息對于預防性維護至關重要。然而,傳統的人工目視檢查方法存在效率低、主觀性強、危險性高等缺點。
近年來,深度學習,特別是目標檢測和語義/實例分割技術,為自動化裂縫檢測提供了強大的工具。相比于目標檢測只能給出裂縫的邊界框,實例分割能夠精確到像素級別,不僅能定位裂縫,還能描繪其精確的輪廓、長度、寬度甚至面積,為后續的損傷評估提供更豐富的信息。
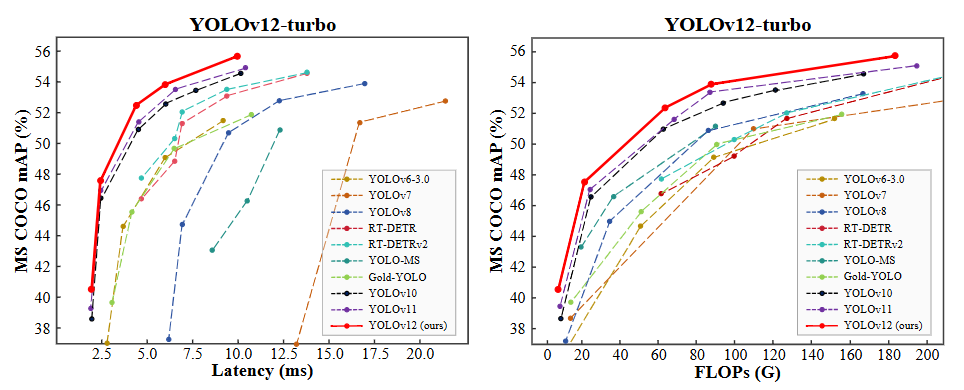
在眾多先進的模型中,YOLO12憑借其速度快、精度高、易于部署的特點脫穎而出。其暫無內置的分割模型。在保持YOLO系列高效推理速度的同時,實現了卓越的分割性能,非常適合部署在無人機、巡檢機器人或邊緣設備上進行實時檢測。
本文將詳細介紹如何使用 YOLO12 網絡來訓練一個專門用于裂縫檢測的實例分割模型。

2. 技術選型:為什么是YOLO12實例分割?
- YOLO12 (You Only Look Once 12): 是YOLO系列的最新迭代。YOLO12 引入了一種以注意力為中心的架構,它脫離了之前 YOLO 模型中使用的傳統 CNN 方法,但保留了許多應用所必需的實時推理速度。該模型通過在注意力機制和整體網絡架構方面的創新方法,實現了最先進的目標檢測精度,同時保持了實時性能。
- 實例分割 (Instance Segmentation): 不僅區分前景(裂縫)和背景,還能區分不同個體的裂縫(即使它們靠得很近)。這對于密集裂縫場景(如混凝土表面)尤為重要。
- Ultralytics庫: 提供了極其簡潔的API,使得數據準備、模型訓練、驗證和推理變得異常簡單,大大降低了開發門檻。
3. 數據準備:高質量標注是成功的關鍵
數據是深度學習的基石。對于裂縫分割,我們需要帶有像素級掩碼標注的數據集。(資源下載)
本次使用的裂縫分割數據集分為三個子集:
- 訓練集: 包含 3717 張帶有相應注釋的圖像。
- 測試集:112 張帶有相應注釋的圖像。
- 驗證集:包含 200 張帶有相應注釋的圖像。

3.1 數據集獲取
- 公開數據集:
- Crack500: 常用的裂縫檢測數據集,包含500張圖像。
- CFD (Crack Forest Dataset): 包含200張高分辨率圖像,常用于裂縫分割和密度估計。
- DeepCrack: 包含3000+張圖像,規模較大。
- Concrete Crack Images for Classification: 雖然主要用于分類,但可作為補充。
- 自建數據集: 使用無人機、相機拍攝真實場景的裂縫圖片,更具實際應用價值。
3.2 數據標注
- 工具推薦: LabelMe, CVAT, Roboflow。
- labelme數據標注保姆級教程:從安裝到格式轉換全流程,附常見問題避坑指南(含視頻講解)
- 標注要求: 為每一張圖像中的每一條裂縫繪制精確的多邊形輪廓(Polygon)。標注工具會生成對應的JSON或COCO格式的標注文件。
- 數據格式: YOLO12支持 COCO格式 或其自定義的 YOLO格式(文本文件,每行代表一個實例:
class_id center_x center_y width height+ 多個x y坐標對表示分割點)。我們通常使用COCO格式。
3.3 數據集劃分與組織 將數據集劃分為訓練集(train)、驗證集(val)和測試集(test)。典型的劃分比例是 70%:15%:15% 或 80%:10%:10%。
組織目錄結構如下:
crack_dataset/
├── images/
│ ├── train/ # 訓練集圖像
│ ├── val/ # 驗證集圖像
│ └── test/ # 測試集圖像
└── labels/├── train/ # 訓練集標簽 (COCO JSON 或 YOLO txt)├── val/ # 驗證集標簽└── test/ # 測試集標簽
3.4 數據增強 (Data Augmentation) Ultralytics YOLO12在訓練時默認應用了強大的數據增強策略(如Mosaic, MixUp, 隨機旋轉、縮放、裁剪、色彩抖動等),這有助于提高模型的泛化能力,防止過擬合,尤其在數據量有限時效果顯著。
- Mosaic
- 當你看到 mosaic: 1.0,這意味著在數據增強過程中使用了 Mosaic 技術,并且其強度或概率設置為最大值(1.0)。Mosaic 數據增強方法通過將四張圖片隨機裁剪并拼接成一張圖片來創建新的訓練樣本。這有助于模型學習如何在不同的環境中識別目標,特別是當對象只占據了圖像的一部分時。
- MixUp
- 對于 mixup: 0.0,這表示不使用 Mixup 方法或者該方法的應用概率為最低(0.0)。Mixup 是一種更溫和的數據增強策略,它通過線性插值的方式在兩張圖片及其標簽之間生成新的訓練樣本。例如,如果你有兩張圖片 A 和 B,Mixup 可能會生成一個新的圖片 C,其中 C 的像素是 A 和 B 像素的加權平均值。
4. 模型訓練:使用YOLO12
4.1 環境搭建
【圖像算法 - 01】保姆級深度學習環境搭建入門指南:硬件選型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安裝全流程(附版本匹配秘籍+文末有視頻講解)
4.2 配置文件 (data.yaml) 創建一個 crack_segmentation.yaml 文件,描述數據集路徑和類別信息:
# 數據集路徑
path: ./crack_dataset # 數據集根目錄
train: images/train # 訓練集圖像相對路徑
val: images/val # 驗證集圖像相對路徑
test: images/test # 測試集圖像相對路徑 (可選)# 類別信息
names:0: crack # 類別名稱,索引從0開始
4.3 開始訓練 使用一行命令即可啟動訓練!Ultralytics提供了豐富的參數供調整。
from ultralytics import YOLO# 加載已訓練的YOLO12分割模型
model = YOLO('yolo12-seg.yaml') # 推薦使用s或m版本在精度和速度間平衡# 開始訓練
results = model.train(data='crack_segmentation.yaml', # 指定數據配置文件epochs=100, # 訓練輪數imgsz=640, # 輸入圖像尺寸batch=16, # 批次大小 (根據GPU顯存調整)name='crack_seg_v1', # 實驗名稱,結果保存在 runs/segment/crack_seg_v1/device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下為可選高級參數# optimizer='AdamW', # 優化器# lr0=0.01, # 初始學習率# lrf=0.01, # 最終學習率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增強 (默認True)# fraction=1.0, # 使用數據集的比例# project='my_projects', # 結果保存的項目目錄
)
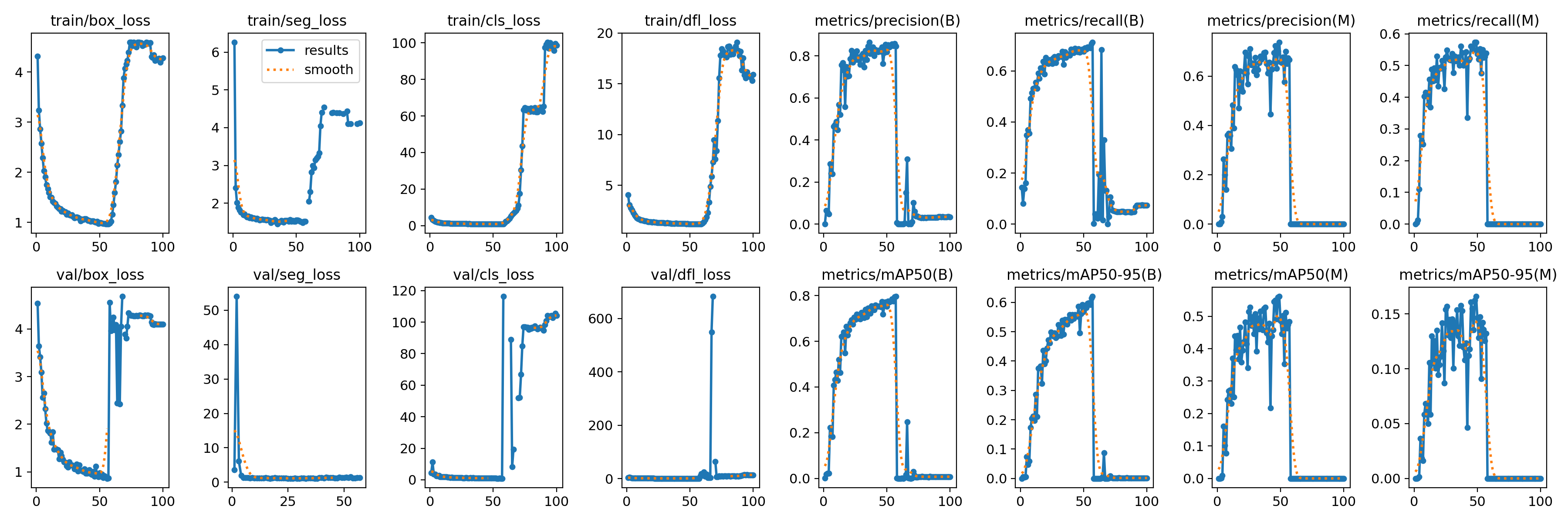
4.4 訓練過程監控
- 訓練過程中,Ultralytics會實時打印損失值(
box_loss,seg_loss,cls_loss,dfl_loss)和評估指標(precision,recall,mAP50,mAP50-95)。 - 在
runs/segment/crack_seg_v1/目錄下會生成詳細的訓練日志、指標曲線圖(如results.png)和最佳權重文件(weights/best.pt)。
5. 模型驗證與推理
5.1 驗證模型性能 訓練完成后,使用驗證集評估模型:
# 加載訓練好的最佳模型
model = YOLO('runs/segment/crack_seg_v1/weights/best.pt')# 在驗證集上評估
metrics = model.val()
print(metrics.box.map) # mAP50 for detection
print(metrics.seg.map) # mAP50 for segmentation
print(metrics.box.map50_95) # mAP50-95 for detection
print(metrics.seg.map50_95) # mAP50-95 for segmentation
5.2 進行推理 (檢測新圖像)
# 加載模型
model = YOLO('runs/segment/crack_seg_v1/weights/best.pt')# 對單張圖像進行預測
results = model('path/to/your/test_image.jpg', imgsz=640, conf=0.25) # conf: 置信度閾值# 結果可視化
for r in results:# 方法1: 使用Ultralytics內置的plot方法 (快速顯示)im_array = r.plot() # 繪制邊界框、分割掩碼、標簽im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBim.show() # 顯示圖像# 方法2: 獲取分割掩碼進行自定義處理masks = r.masks # Segmentation masks objectif masks is not None:mask_array = masks.data.cpu().numpy() # 形狀: (num_instances, H, W)# 對mask_array進行后續處理,如計算裂縫長度、寬度、面積等# 例如,計算每條裂縫的像素面積:for i, mask in enumerate(mask_array):area = mask.sum() # 像素面積print(f"Crack {i} area: {area} pixels")

5.3 批量推理
# 對整個文件夾進行預測
results = model.predict(source='path/to/test_images_folder/', save=True, save_txt=True, imgsz=640, conf=0.25)
# save=True: 保存帶標注的圖像
# save_txt=True: 保存預測結果到txt文件 (可選)
6. 結果分析與應用
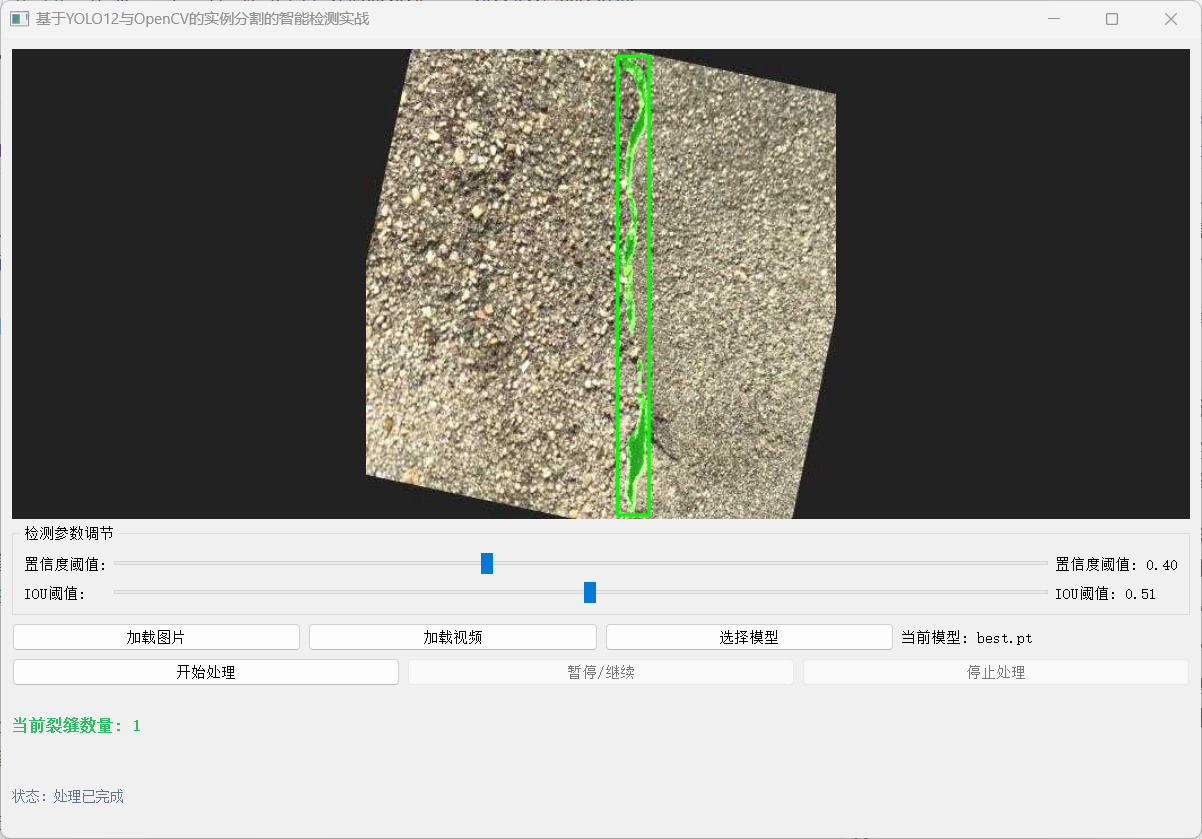
- 可視化效果: 訓練好的模型能清晰地分割出裂縫的精確輪廓,即使裂縫非常細長或相互交叉。
-
量化分析:
基于分割出的掩碼,可以計算:
- 裂縫長度: 通過骨架化或主成分分析(PCA)估算。
- 裂縫寬度: 在垂直于長度的方向上測量。
- 裂縫面積: 直接統計掩碼內像素總數。
- 裂縫密度: 單位面積內的裂縫長度或面積。
-
應用場景:
- 無人機自動巡檢橋梁、大壩、風電葉片。
- 隧道、地鐵墻體的自動化檢測。
- 混凝土結構的健康監測系統。
- 與BIM模型結合,進行數字孿生管理。
7. 總結與展望
本文詳細介紹了如何利用 YOLO12實例分割模型 構建一個高效的裂縫檢測系統。通過高質量的數據標注、合理的模型選擇和參數配置,我們能夠訓練出精度高、魯棒性強的模型。
優勢:
- 精度高: 像素級分割提供精確的裂縫輪廓。
- 速度快: YOLO12保證了實時或近實時的檢測速度。
- 易用性: Ultralytics API 極大簡化了開發流程。
- 可擴展: 框架可輕松遷移到其他分割任務。
挑戰與改進方向:
- 小裂縫檢測: 極細的裂縫可能難以檢測,可嘗試更高分辨率輸入或專用小目標檢測技術。
- 復雜背景: 陰影、污漬、紋理可能被誤檢,需要更豐富的訓練數據和更強的特征提取能力。
- 泛化能力: 模型在不同光照、材質、拍攝角度下的表現需持續優化。
- 3D信息: 結合深度信息(如RGB-D相機)可估計裂縫深度。
未來展望: 隨著YOLO系列和Transformer架構的不斷發展,裂縫檢測的精度和效率將進一步提升。結合邊緣計算和5G技術,實時、大規模的基礎設施智能巡檢將成為現實。





)





)
)
:GPIO 輸入之光敏傳感器控制蜂鳴器)





