TRAE調教指南:用6A工作流項目規則+5S敏捷個人規則打造高效AI開發流程
- 引言:從"AI瞎寫"到"精準交付"的實戰手冊
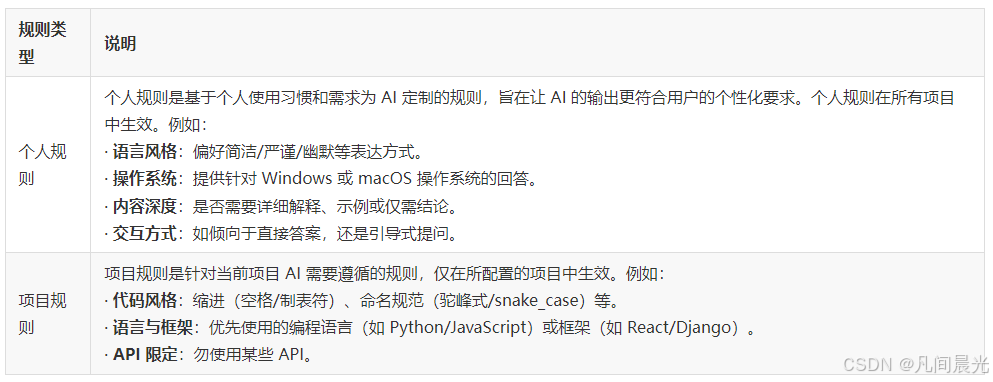
- 一、什么是Rules:讓AI"聽話"的底層邏輯
- 1. 告別重復指令疲勞
- 2. 實現"千人千面"的個性化適配
- 3. 構建"項目級"的約束邊界
- 二、TRAE規則配置使用指南:從"配置"到"生效"的全流程
- 三、6A工作流項目規則:給AI套上"項目管理緊箍咒"
- 1. 6A工作流項目規則介紹
- 階段1:Align(對齊)
- 階段2:Architect(架構)
- 階段3:Atomize(原子化)
- 階段4:Approve(審批)
- 階段5:Automate(自動化執行)
- 階段6:Assess(評估)
- 2. 附6A工作流項目規則:project_rules.md(即拿即用)
- 四、5S敏捷開發個人規則:讓自己成為"AI馴獸師"
- 1. 5S敏捷開發個人規則介紹
- 1S:文檔管理(核心中的核心)
- 2S:開發流程(順序化思考,拒絕跳步)
- 3S:問題解決(官方文檔是爹,搜索引擎是兒子)
- 4S:執行約束(三大"絕不允許")
- 5S:環境與輸出(細節決定成敗)
- 2.附5S敏捷開發個人規則:user_rules.md(即拿即用)
- 五、6A+5S協同:1+1>10的實戰效果
- 六、常見問題
- 結語:從"被AI帶跑"到"駕馭AI"
引言:從"AI瞎寫"到"精準交付"的實戰手冊
最近帶團隊做一個電商后臺重構,讓AI幫忙開發用戶權限模塊,結果差點把我送走——AI上來就直接寫代碼,完全沒考慮我們現有架構的權限模型;改了三次還是不對,一問才發現它連數據庫表結構都沒搞清楚。這種"需求對齊靠猜、代碼質量靠蒙"的開發模式,相信很多用過AI編程的同學都感同身受。
直到半年前接觸了TRAE的規則配置功能,我才找到破局之道:用6A工作流管項目流程,用5S規則規范個人執行,兩者結合讓AI從"野生程序員"變身"可控助手"。今天就把這套實戰經驗分享出來,帶你徹底擺脫AI開發的混亂狀態。
一、什么是Rules:讓AI"聽話"的底層邏輯
很多人把TRAE的Rules功能簡單理解為"提示詞模板",這就大錯特錯了!Rules 是一項強大的代碼規范管理工具 ,它允許團隊或開發者自定義并強制執行代碼風格和最佳實踐。它解決了三個核心痛點:
1. 告別重復指令疲勞
剛開始用AI時,我每天要重復輸入"用Python 3.9語法"“遵循PEP8規范”“注釋要包含參數校驗說明”,直到配置了Rules,這些要求被"固化"到AI行為中。現在不管是新同事還是老員工,調用AI時都不用再強調基礎規范,效率直接提升40%。
2. 實現"千人千面"的個性化適配
我帶的團隊里,前端同學喜歡AI給出"代碼+效果圖"的完整方案,后端同學只要"核心邏輯+測試用例"。通過個人Rules區分這些偏好后,AI輸出的內容精準度提高了80%,再也不會出現"前端要UI示例,AI只給代碼"的尷尬。
3. 構建"項目級"的約束邊界
去年做支付系統時,AI擅自使用了已廢棄的requests庫舊API,導致線上bug。現在通過項目Rules明確"禁止使用requests<2.25.0版本",這類問題直接從源頭杜絕。規則就像給AI裝了"護欄",確保它在安全范圍內發揮能力。
二、TRAE規則配置使用指南:從"配置"到"生效"的全流程
TRAE IDE(0.5.1+版本)支持兩類規則,我總結為"個人規則定風格,項目規則定標準",兩者配合使用效果最佳。
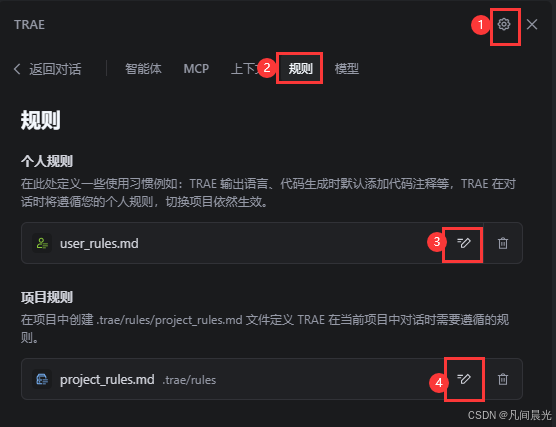
ps:規則沖突怎么辦?
遇到"個人規則要求簡潔,項目規則要求詳細"的沖突時,TRAE會優先遵循項目規則。我的建議是:個人規則聚焦表達風格,項目規則專注技術約束,這樣能從根本上減少沖突。
三、6A工作流項目規則:給AI套上"項目管理緊箍咒"
6A工作流(Align-Architect-Atomize-Approve-Automate-Assess)是TRAE最核心的項目規則體系,本質是通過標準化流程讓AI"不敢偷懶、不能瞎寫"。我帶團隊落地3個月,項目返工率直接從40%降到5%,這背后每個階段都有"反AI偷懶"的小心機。
1. 6A工作流項目規則介紹
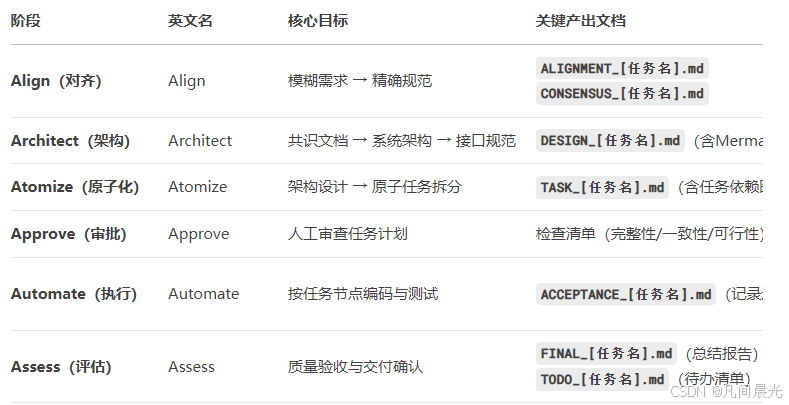
階段1:Align(對齊)
把模糊需求錘成"鋼印級"規范,杜絕AI"我以為"式開發。 記住:需求邊界不清,后面全是坑。
階段2:Architect(架構)
從共識文檔到系統架構,Align階段確認需求后,AI會自動生成DESIGN_任務名.md,用mermaid畫架構圖,拒絕AI"拍腦袋寫代碼"。
階段3:Atomize(原子化)
拆分任務到AI"不可能失敗"的粒度,復雜任務拆成20行內代碼塊。
階段4:Approve(審批)
拿著TASK_任務名.md逐條檢查,重點看"驗收標準是否可測試"——比如"用戶注冊接口"不能寫"功能正常",必須寫"輸入重復手機號返回code=1001錯誤"
階段5:Automate(自動化執行)
AI按任務順序執行,每寫完一個函數必須先寫單元測試(我加了規則:測試不通過不準提交代碼)
階段6:Assess(評估)
最終生成FINAL_任務名.md,包含代碼質量評分(用SonarQube掃描)、測試覆蓋率(要求≥80%)、遺留TODO(比如"性能優化待后續迭代")

2. 附6A工作流項目規則:project_rules.md(即拿即用)
下載地址:TRAE通用開發規則配置之6A工作流項目規則和敏捷開發5S個人規則
四、5S敏捷開發個人規則:讓自己成為"AI馴獸師"
6A解決了項目流程問題,但個人執行不到位還是白搭。我總結的5S個人規則,專治"AI依賴癥"和"開發拖延癥"。
1. 5S敏捷開發個人規則介紹
1S:文檔管理(核心中的核心)
血淚教訓:去年有個項目文檔沒及時更新,接手的同事不知道"用戶表已添加last_login字段",結果新功能上線直接報錯。現在我團隊強制:
- 創建時機:新項目第一天必須建
說明文檔.md,包含"項目規劃+實施方案+進度記錄" - 更新要求:每次開發前先讀文檔,改一行代碼就同步更新文檔,完成任務后必須寫"結果說明"
2S:開發流程(順序化思考,拒絕跳步)
用分析法拆解需求,比如開發"商品列表頁":
- 先寫接口文檔(輸入參數、返回格式)
- 再寫單元測試(邊界條件:空列表、分頁越界)
- 最后實現功能
關鍵原則:完成一個任務打勾一個,絕不允許"這個功能差不多了,先做下個"。我見過有人同時開5個文件改代碼,最后自己都不知道改了啥。
3S:問題解決(官方文檔是爹,搜索引擎是兒子)
AI不是萬能的!上次遇到Python的asyncio問題,AI給的代碼有bug,查也沒解決。最后翻Python官方文檔才發現是"事件循環策略"用錯了。現在我定了規矩:
- 技術問題先查,解決不了必須翻官方文檔(Python查Python.org,Java查Oracle)
- 嚴禁"百度一下復制粘貼",誰用非官方方案誰背鍋
4S:執行約束(三大"絕不允許")
這是我從軍隊管理學來的——用鐵律杜絕僥幸心理:
- 絕不允許項目延期:提前3天識別風險,延期必須同步更新文檔并說明原因
- 絕不允許超出計劃:加功能可以,但必須先改規劃文檔,評估影響
- 絕不允許出錯:編譯錯誤、測試不通過、文檔不一致,這三類錯誤零容忍
5S:環境與輸出(細節決定成敗)
- 開發環境:例如全團隊統一用Windows(避免Linux/macOS路徑分隔符坑),IDE插件版本鎖定(比如Prettier用2.8.0)
- 代碼輸出:所有函數必須加注釋,格式固定為:
def login(username: str, password: str) -> dict: """ 用戶登錄接口 :param username: 用戶名(長度6-20位) :param password: 密碼(包含大小寫+數字) :return: {code:0,data:{token:str,user:dict}} """
2.附5S敏捷開發個人規則:user_rules.md(即拿即用)
下載地址:TRAE通用開發規則配置之6A工作流項目規則和敏捷開發5S個人規則
五、6A+5S協同:1+1>10的實戰效果
單獨用6A或5S效果有限,但結合起來簡直是"降維打擊"。我帶的電商項目用這套組合拳后:
- 返工率:從40%→5%(Align階段解決需求偏差,5S文檔避免信息斷層)
- 開發效率:單人日產出從3個功能點→8個(Atomize拆分后AI執行更快,5S順序執行減少切換成本)
- 代碼質量:SonarQube問題數從平均20個/千行→3個(Automate階段強制測試,5S約束注釋規范)
舉個真實案例:最近開發"優惠券系統",6A確保架構對齊現有營銷系統,5S讓每個開發按"文檔→測試→代碼"順序執行,結果提前5天上線,零bug。
六、常見問題
Q:6A 工作流會不會太復雜?小項目能用嗎?
A:初期可能感覺步驟多,但相比后期的返工和維護成本,絕對值得!而且 AI 會自動執行,你只需要確認關鍵節點。
Q:適合什么規模的項目?
A:從小功能到大項目都適用。小項目可以簡化某些階段,大項目則能充分發揮威力。
Q:如何說服團隊使用?
A:先在一個小項目上試用,效果立竿見影,自然就能說服大家。
結語:從"被AI帶跑"到"駕馭AI"
工欲善其事,必先利其器。AI編程的終極目標不是讓AI替我們干活,而是用規則把AI變成"超級工具"。
6A工作流管項目流程,5S個人規則管執行細節,兩者結合才能真正釋放AI威力。 通過系統化的流程管理,我們可以:
? 讓 AI 按照專業流程工作
? 確保需求理解準確無誤
? 保證代碼質量和可維護性
? 建立完善的文檔體系
? 實現高效的團隊協作
最后送大家一句話:好的AI助手不是天生的,是調教出來的。現在就打開Trae IDE,配置你的第一條規則吧!

)
)
:GPIO 輸入之光敏傳感器控制蜂鳴器)








:雨騎古蓮村游記)

TCP擁塞控制與擁塞控制算法深度剖析)
)



![礦物分類系統開發筆記(二):模型訓練[刪除空缺行]](http://pic.xiahunao.cn/礦物分類系統開發筆記(二):模型訓練[刪除空缺行])