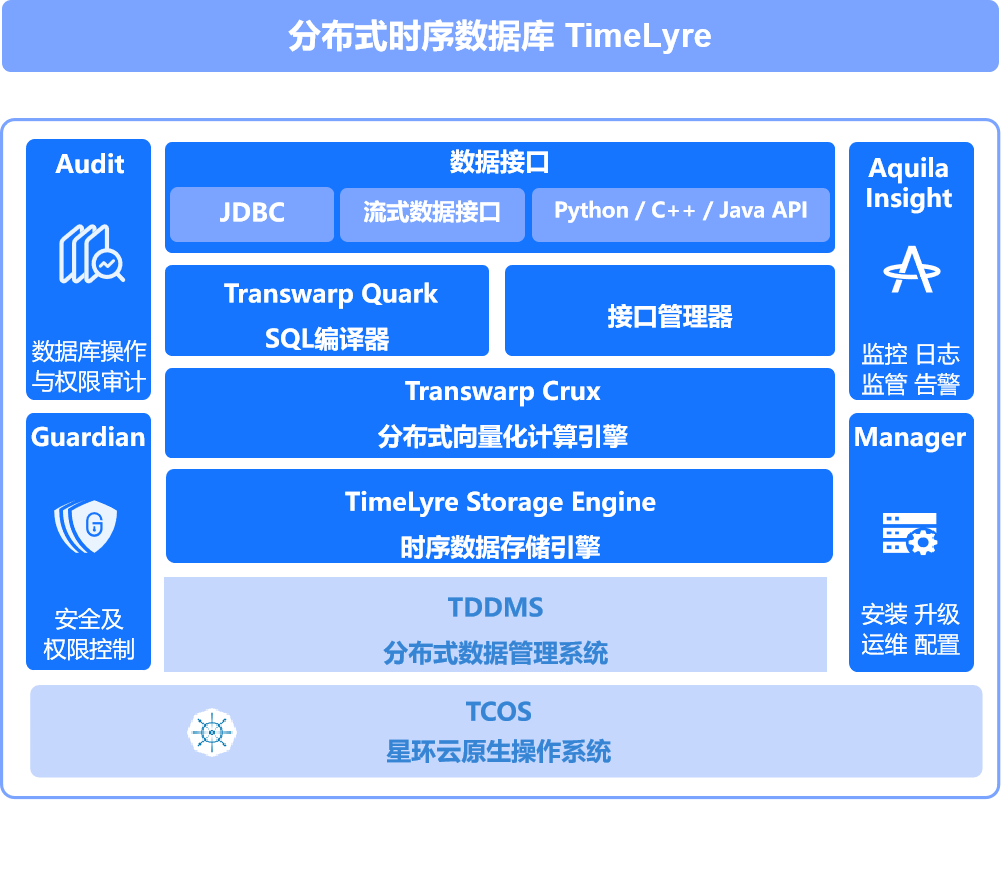
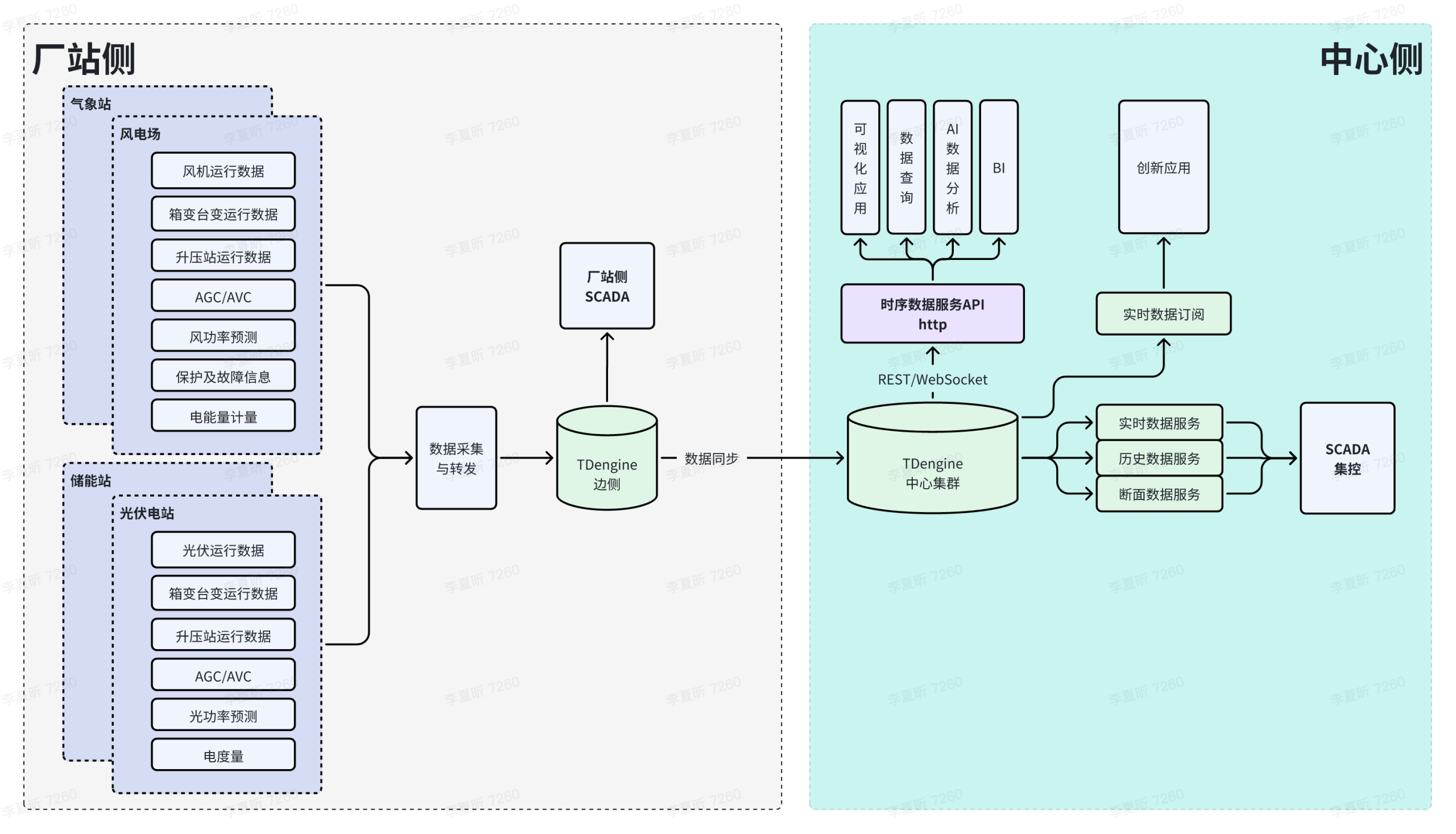
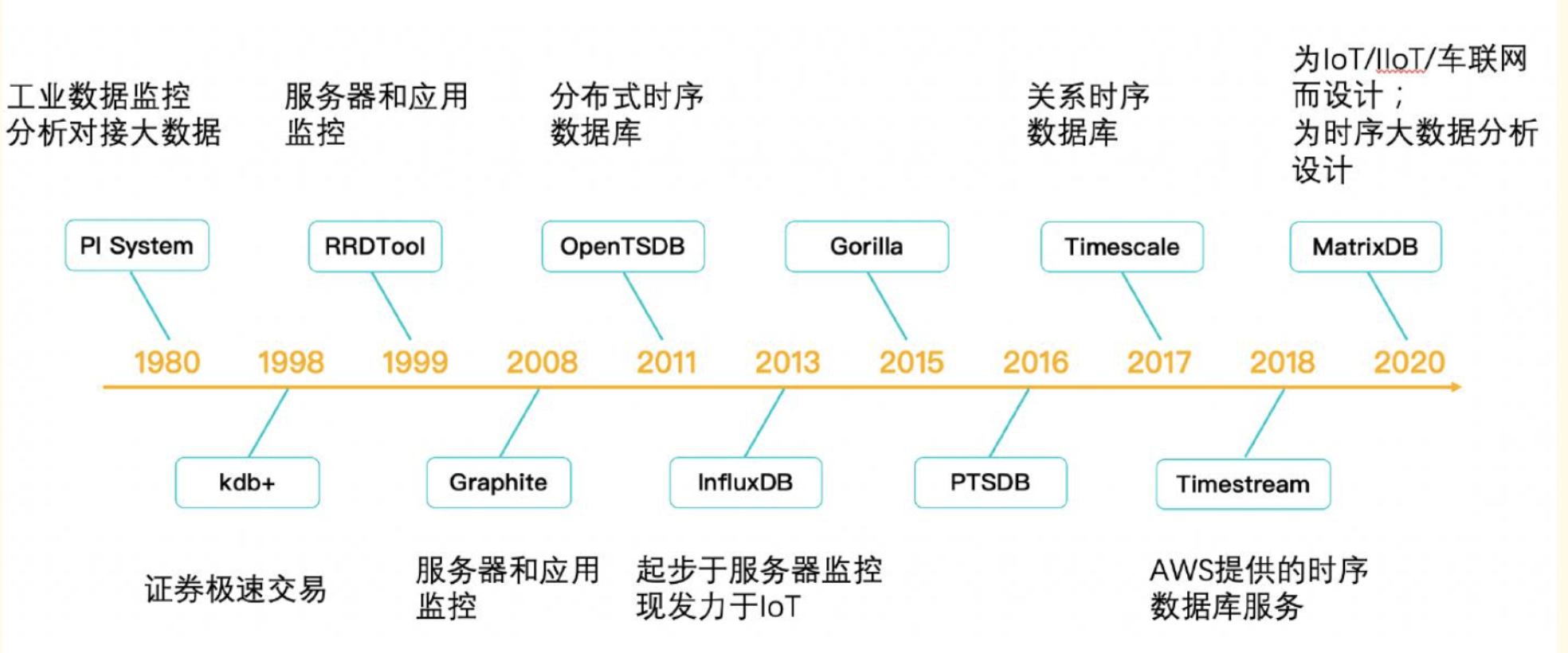
摘要:時序數據庫在大數據時代迎來爆發式增長,IoTDB作為Apache頂級開源項目展現出顯著優勢:1. 性能卓越:支持千萬級數據點/秒寫入,18:1高壓縮比,查詢延遲低至500ms;2. 創新架構:采用樹形數據模型適配工業設備層級管理,端邊云協同實現高效數據處理;3. 行業應用:已在能源電力(省級電網秒級故障追溯)、智能制造(汽車工廠存儲成本降82%)等領域成功落地;4. 生態完善:支持Hadoop/Spark等大數據生態,與Grafana等可視化工具無縫集成。相比InfluxDB和TimescaleDB,IoTDB在寫入性能、壓縮效率和工業協議支持方面更具優勢,是處理海量時序數據的理想選擇。
目錄???????
一、時序數據庫的崛起
1.1 大數據時代的數據洪流
1.2 傳統數據庫的困境
1.3 時序數據庫應運而生
1.4 時序數據庫下載與安裝使用
(一)下載 IoTDB
(二)安裝 IoTDB
(三)使用 IoTDB
二、深入剖析時序數據庫
2.1 什么是時序數據
2.2 時序數據庫的獨特之處
2.3 關鍵特性大揭秘
高寫入性能
高效壓縮
靈活查詢
分布式架構
三、選型的關鍵維度
3.1 性能指標是核心
3.2 數據模型要適配
3.3 擴展性決定未來
3.4 生態兼容性不可少
3.5 運維復雜度需考量
四、IoTDB 的獨特優勢
4.1 強大的性能表現
4.2 靈活的數據模型
4.3 端邊云協同架構
4.4 豐富的生態集成
4.5 開源與社區支持
五、與國外產品的全面對比
5.1 架構設計對比
5.2 核心性能實測
5.3 生態集成差異
5.4 代碼案例分享
六、行業應用案例
6.1 能源電力行業
6.2 智能制造行業
6.3 其他行業應用
車聯網
智慧城市
邊緣計算
七、選型實踐建議
7.1 需求分析是基礎
7.2 概念驗證要點
7.3 部署策略規劃
7.4 長期演進考慮
八、總結與展望
8.1 IoTDB 的價值總結
8.2 未來發展趨勢展望
8.3 行動呼吁
?8.4 IoTDB官網、下載、開源地址
一、時序數據庫的崛起
1.1 大數據時代的數據洪流
在當今這個數字化飛速發展的大數據時代,數據正以前所未有的速度和規模爆發式增長。從互聯網應用到傳統工業領域,從智能設備到金融交易,各行各業都在源源不斷地產生海量數據。
以物聯網(IoT)領域為例,據國際數據公司(IDC)預測,到 2025 年,全球物聯網設備數量將達到 295 億,這些設備產生的數據量將達到 79.4ZB ,其中絕大部分都是時序數據。在智能家居場景中,智能傳感器實時采集室內溫度、濕度、空氣質量等數據,每個傳感器每天可能產生數千條數據記錄。而在智能工廠里,生產線上的各類設備更是不停地生成設備運行狀態、生產進度、質量檢測等時序數據,一個中等規模的工廠每天產生的數據量就能輕松達到 TB 級別。
金融行業同樣是數據的高產領域。股票市場每秒鐘都在產生海量的交易數據,包括股票價格的波動、成交量的變化、投資者的買賣行為等。據統計,全球主要證券交易所每天的交易數據量高達 PB 級別。以我國的 A 股市場為例,每天的交易數據記錄數以億計,這些數據不僅反映了市場的實時動態,還蘊含著豐富的投資決策信息。
再看能源領域,隨著智能電網的建設和普及,電網中的各類設備,如變壓器、開關、電表等,都在持續產生大量的運行狀態數據和電力計量數據。這些數據對于電網的安全穩定運行、電力調度和能源管理至關重要。一個省級電網每天產生的時序數據量可達數十 TB,并且隨著電網規模的擴大和智能化程度的提高,數據量還在不斷攀升。
1.2 傳統數據庫的困境
面對如此海量的時序數據,傳統的關系型數據庫逐漸顯露出諸多困境。
在寫入性能方面,傳統關系型數據庫采用的是行式存儲結構,每次寫入操作都需要對整行數據進行更新和存儲,這在處理高頻寫入的時序數據時效率極低。例如,在物聯網場景中,大量傳感器的數據需要實時寫入數據庫,如果使用傳統關系型數據庫,很容易出現寫入延遲甚至寫入失敗的情況,無法滿足數據實時性的要求。據測試,在高并發寫入場景下,傳統關系型數據庫的寫入吞吐量僅為時序數據庫的幾十分之一。
存儲成本也是傳統關系型數據庫的一大痛點。由于時序數據具有高頻采集、數據量大的特點,使用傳統關系型數據庫存儲會占用大量的存儲空間。而且,傳統關系型數據庫對時序數據的壓縮效果較差,進一步增加了存儲成本。以某智能工廠為例,使用傳統關系型數據庫存儲一年的設備運行數據,所需的存儲成本是使用時序數據庫的 5 倍以上。
查詢效率同樣不盡人意。當需要對大量時序數據進行復雜查詢,如時間窗口查詢、聚合查詢時,傳統關系型數據庫需要掃描大量的數據行,查詢速度極慢。在金融市場的實時交易分析中,對交易數據的查詢要求毫秒級響應,而傳統關系型數據庫往往需要數秒甚至數十秒才能返回結果,根本無法滿足金融交易的實時性需求。
1.3 時序數據庫應運而生
為了應對傳統數據庫在處理時序數據時的種種困境,時序數據庫應運而生。時序數據庫是一種專門為處理時間序列數據而設計的數據庫,它針對時序數據的特點進行了優化,在寫入性能、存儲效率和查詢速度等方面都具有顯著優勢。

在寫入性能上,時序數據庫采用了優化的寫入算法和存儲結構,如 LSM 樹(Log-Structured Merge Tree),能夠實現高效的批量寫入和快速的寫入響應。在物聯網場景中,時序數據庫可以輕松應對每秒數百萬條數據的寫入壓力,確保數據的實時采集和存儲。
存儲效率方面,時序數據庫利用數據的時序相關性,采用了高效的壓縮算法,如差分編碼、游程編碼等,能夠將數據壓縮到原來的幾分之一甚至幾十分之一,大大降低了存儲成本。同時,時序數據庫還支持數據的分級存儲,將熱數據存儲在高速存儲介質中,冷數據存儲在低成本的存儲介質中,進一步優化了存儲資源的利用。
查詢速度上,時序數據庫針對時序數據的查詢特點,建立了高效的索引結構,如時間索引、標簽索引等,能夠快速定位和查詢所需的數據。在進行時間窗口查詢和聚合查詢時,時序數據庫可以在毫秒級甚至微秒級內返回結果,滿足了實時監控和數據分析的需求。
1.4 時序數據庫下載與安裝使用
如果你已經被 IoTDB 的魅力所吸引,迫不及待地想要親自體驗一番,那么接下來就為你詳細介紹 IoTDB 的下載與使用方法。
(一)下載 IoTDB
你可以通過 IoTDB 官方下載鏈接:發行版本 | IoTDB Website ,獲取最新版本的 IoTDB。在下載頁面,你會看到針對不同操作系統的下載選項,包括 Windows、Linux 等。根據你的系統類型,選擇對應的壓縮包進行下載。
(二)安裝 IoTDB
- Windows 系統安裝:下載完成后,解壓下載的壓縮包到你希望安裝的目錄,比如 C:\IoTDB\apache-iotdb-x.x.x-all-bin 。為了方便后續操作,你可以設置 %IoTDB_HOME% 環境變量,指向解壓后的根目錄,并將其添加到系統的 PATH 變量中。這樣,你就可以在任意命令行位置調用 IoTDB 的相關腳本。進入 IoTDB 的 sbin 子目錄,執行 start-standalone.bat 腳本,即可啟動 IoTDB 獨立模式服務。啟動過程中,你可以在控制臺看到服務器初始化的相關信息,這表明 IoTDB 正在正常啟動。
- Linux 系統安裝:在 Linux 系統中,同樣先解壓下載的壓縮包。使用命令 unzip apache-iotdb-x.x.x-all-bin.zip (如果是 tar.gz 格式,則使用 tar -zxvf apache-iotdb-x.x.x-all-bin.tar.gz )。解壓后,進入解壓目錄,執行啟動腳本 bash sbin/start-standalone.sh 來啟動 IoTDB 服務。啟動完成后,你可以使用命令 netstat -nplt 檢查默認端口(6667 和 10710)是否正常開啟,以確保 IoTDB 服務已經成功啟動。
Windows 單機版 IoTDB 安裝全流程(2025-05 官方版)
一、準備
系統:Windows 10/11 64 bit
依賴:JDK 8u211+ 或 JDK 11(官網推薦),已配置 JAVA_HOME 并加入 PATH
路徑:安裝目錄 不能含空格或中文,例如:
D:\iotdb\apache-iotdb-1.3.0-all-bin二、下載
官網最新包:
IoTDB Website → Download → 選apache-iotdb-1.3.0-all-bin.zip解壓到
D:\iotdb\得到D:\iotdb\apache-iotdb-1.3.0-all-bin三、配置(單機 1C1D 可跳過,默認即可)
如要調內存:用文本編輯器打開
conf\confignode-env.bat與conf\datanode-env.bat
把MEMORY_SIZE改成想要的堆大小,例如:set MEMORY_SIZE=2G四、啟動
啟動 ConfigNode
打開 CMD(以管理員身份),依次執行:cd /d D:\iotdb\apache-iotdb-1.3.0-all-bin sbin\start-confignode.bat -d啟動 DataNode
sbin\start-datanode.bat -d驗證
sbin\start-cli.bat -h 127.0.0.1 -p 6667CLI 出現
IoTDB>提示符后執行:SHOW CLUSTER;看到兩個節點狀態都是
Running即安裝成功 。五、常見快捷命令
停止所有節點
sbin\stop-standalone.bat重啟
sbin\stop-standalone.bat sbin\start-confignode.bat -d sbin\start-datanode.bat -d六、訪問
CLI:如上
Workbench(可選):解壓
iotdb-workbench-*.zip,雙擊sbin\start.bat -d,瀏覽器打開 http://127.0.0.1:9190 即可圖形化操作 。至此,Windows 單機版 IoTDB 已就緒,可開始建庫、寫數據、跑查詢。
(三)使用 IoTDB
- 連接數據庫:IoTDB 啟動成功后,你可以通過命令行界面(CLI)連接到數據庫。在 sbin 目錄下,執行 start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root (Windows 下為 start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root ),其中 -h 表示主機地址, -p 表示端口號, -u 表示用戶名, -pw 表示密碼。默認情況下,主機地址為 127.0.0.1 ,端口號為 6667 ,用戶名和密碼均為 root 。成功連接后,你將看到 IoTDB 的命令行提示符 IoTDB> ,此時你就可以開始執行各種 IoTDB 命令了。
- 創建數據庫:在 IoTDB 中,使用 CREATE DATABASE 語句來創建數據庫。例如,要創建一個名為 test_db 的數據庫,可以執行 CREATE DATABASE test_db 。創建成功后,你可以使用 SHOW DATABASES 命令查看當前所有的數據庫,確認 test_db 已經被創建。
- 插入數據:插入數據是使用 IoTDB 的重要操作之一。IoTDB 支持多種插入數據的方式,這里介紹一種常用的基于 SQL 的插入方式。假設你已經創建了一個數據庫 test_db ,并且在該數據庫下有一個設備 device1 ,設備上有一個測量點 temperature ,你可以使用以下語句插入數據:INSERT INTO root.test_db.device1(timestamp, temperature) VALUES(1630000000000, 25.5) ,其中 1630000000000 是時間戳(單位為毫秒), 25.5 是溫度值。你可以根據實際需求,插入不同時間戳和測量值的數據。
- 查詢數據:數據插入后,就可以進行查詢操作了。使用 SELECT 語句可以查詢 IoTDB 中的數據。例如,要查詢 root.test_db.device1 設備在某個時間范圍內的溫度數據,可以執行 SELECT temperature FROM root.test_db.device1 WHERE timestamp >= 1630000000000 AND timestamp <= 1630000010000 ,這條語句將返回指定時間范圍內的溫度數據。你還可以使用聚合函數,如 AVG (求平均值)、 SUM (求和)、 MAX (求最大值)、 MIN (求最小值)等,對查詢結果進行統計分析。例如, SELECT AVG(temperature) FROM root.test_db.device1 可以查詢該設備所有溫度數據的平均值。
如果你對 IoTDB 的企業版感興趣,想要了解更多關于企業版的功能、優勢以及應用案例等信息,可以訪問企業版官網:Apache IoTDB_國產開源時序數據庫_時序數據管理服務商-天謀科技Timecho 。
 在官網上,你將獲取到關于 IoTDB 企業版的詳細資料,包括產品介紹、技術文檔、客戶案例等,幫助你更好地評估 IoTDB 企業版是否適合你的企業需求。
在官網上,你將獲取到關于 IoTDB 企業版的詳細資料,包括產品介紹、技術文檔、客戶案例等,幫助你更好地評估 IoTDB 企業版是否適合你的企業需求。
通過以上步驟,你已經初步掌握了 IoTDB 的下載、安裝和基本使用方法。在實際應用中,你可以根據具體的業務場景和需求,進一步探索 IoTDB 的更多功能和特性,讓 IoTDB 為你的數據管理和分析工作提供強大的支持。
二、深入剖析時序數據庫
2.1 什么是時序數據
時序數據,簡單來說,就是按照時間順序排列的數據點序列。每一個數據點都帶有一個時間戳,用于標記數據產生的時間。這些數據點通常反映了某個實體或現象在不同時間點上的狀態或變化。
以智能工廠中的設備監控為例,生產線上的傳感器會實時采集設備的運行參數,如溫度、壓力、轉速等。這些參數隨著時間不斷變化,形成了一系列的時序數據。假設一臺工業機器人的關節溫度傳感器,每 5 秒采集一次溫度數據,在一天的生產過程中,就會產生 17280 個溫度數據點,這些數據按照采集時間的先后順序排列,就構成了該機器人關節溫度的時序數據。通過分析這些時序數據,工程師可以及時發現設備是否存在過熱等異常情況,提前進行維護,避免生產故障的發生。
在能源領域,電力系統中的電表會實時記錄用戶的用電量。每一分鐘,電表都會將當前的用電量數據上傳到電力公司的數據庫中。這些用電量數據隨著時間的推移不斷積累,形成了用戶用電量的時序數據。電力公司可以根據這些時序數據,分析用戶的用電習慣,進行電力調度和需求響應,提高電力系統的運行效率。
金融市場中的股票價格也是典型的時序數據。股票的價格在每個交易日內不斷波動,證券交易所會實時記錄股票的開盤價、收盤價、最高價、最低價等數據。這些數據按照時間順序排列,反映了股票價格的走勢。投資者可以通過分析股票價格的時序數據,預測股票價格的未來變化,制定投資策略。
2.2 時序數據庫的獨特之處
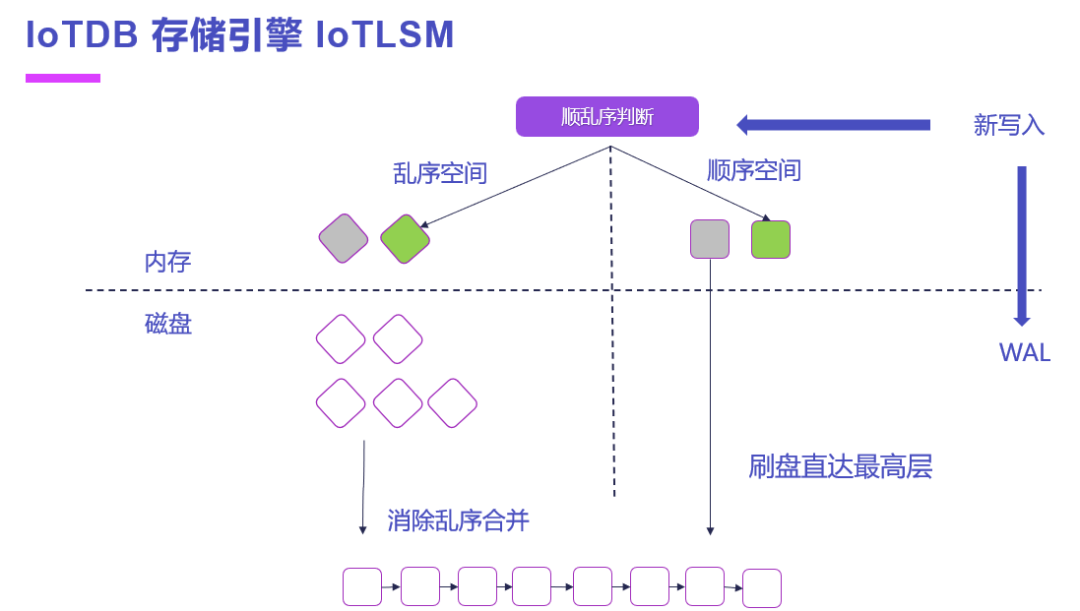
時序數據庫與傳統數據庫相比,在多個方面具有獨特之處。
在設計理念上,傳統數據庫注重數據的完整性、一致性和事務處理能力,以滿足企業級應用中復雜的業務邏輯和數據關系。而時序數據庫則專注于時間序列數據的高效處理,強調高寫入性能、高效存儲和快速查詢,以滿足對實時數據的處理需求。
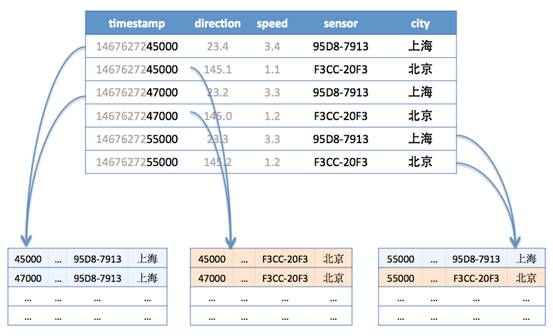
數據模型方面,傳統關系型數據庫采用的是二維表結構,將數據存儲在表中,每一行代表一個記錄,每一列代表一個屬性。這種數據模型適合處理結構化數據,但對于時序數據的處理并不高效。時序數據庫則采用了更適合時序數據的模型,通常以時間戳作為主鍵,將數據按照時間順序進行存儲。例如,InfluxDB 采用的是時間線模型,將數據按照時間序列進行組織,每個時間序列由一個或多個標簽進行標識,方便對數據進行分類和查詢。
存儲方式上,傳統數據庫多采用行式存儲,將同一記錄的所有數據存儲在同一行中。這種存儲方式在處理結構化數據時效率較高,但在處理大量時序數據時,由于查詢通常需要跨多個記錄檢索數據,效率較低。時序數據庫則多采用列式存儲,將相同時間戳的數據存儲在同一列中。這樣在進行時間范圍查詢或聚合查詢時,可以大大減少數據的掃描范圍,提高查詢效率。同時,時序數據庫還利用數據的時序相關性,采用高效的壓縮算法,如差分編碼、游程編碼等,將數據壓縮到原來的幾分之一甚至幾十分之一,大大降低了存儲成本。
2.3 關鍵特性大揭秘
高寫入性能
時序數據庫專為高頻寫入設計,采用了優化的寫入算法和存儲結構,如 LSM 樹(Log-Structured Merge Tree)。LSM 樹通過將寫入操作先記錄在內存中的日志結構中,然后再異步地將日志合并到磁盤上,大大減少了磁盤 I/O 操作,提高了寫入性能。在物聯網場景中,大量傳感器的數據需要實時寫入數據庫,時序數據庫可以輕松應對每秒數百萬條數據的寫入壓力,確保數據的實時采集和存儲。例如,在一個擁有 10 萬個傳感器的智能城市項目中,每個傳感器每秒產生 10 條數據,使用時序數據庫可以在短時間內完成這些數據的寫入,而傳統數據庫則可能因為寫入性能不足而導致數據丟失或延遲。
高效壓縮
由于時序數據具有高頻采集、數據量大的特點,存儲成本是一個重要的考慮因素。時序數據庫利用數據的時序相關性,采用了高效的壓縮算法。以差分編碼為例,它通過記錄相鄰數據點之間的差值來減少數據的存儲空間。假設一個傳感器采集的溫度數據序列為 25、25.5、26、26.2,使用差分編碼后,存儲的數據為 25、0.5、0.5、0.2,大大減少了數據量。游程編碼則是對于連續重復的數據,只記錄數據和重復的次數。如對于連續出現 10 次的溫度值 25,使用游程編碼只需要記錄 25 和 10,進一步降低了存儲成本。通過這些壓縮算法,時序數據庫能夠將數據壓縮到原來的幾分之一甚至幾十分之一,大大降低了存儲成本。
靈活查詢
時序數據庫針對時序數據的查詢特點,建立了高效的索引結構,如時間索引、標簽索引等,能夠快速定位和查詢所需的數據。在進行時間窗口查詢時,例如查詢某一天內設備的運行數據,時序數據庫可以利用時間索引快速定位到該時間范圍內的數據,而不需要掃描整個數據庫。在進行聚合查詢時,如計算某段時間內設備的平均溫度,時序數據庫可以通過預先計算好的聚合索引,快速得出結果。同時,時序數據庫還支持各種復雜的查詢操作,如滑動窗口分析、數據插值等,滿足了不同用戶對于時序數據的分析需求。
分布式架構
隨著數據量的不斷增長和應用場景的不斷擴展,分布式架構成為了時序數據庫的重要特性。分布式架構可以將數據分布存儲在多個節點上,實現數據的水平擴展,提高系統的吞吐量和容量。例如,在一個大規模的工業物聯網項目中,可能需要存儲和處理來自數百萬個設備的時序數據,單機的時序數據庫無法滿足這樣的需求。采用分布式架構的時序數據庫可以將這些數據分布存儲在多個服務器節點上,每個節點負責存儲和處理一部分數據,從而實現數據的高效存儲和查詢。同時,分布式架構還具有高可用性和容錯性,當某個節點出現故障時,系統可以自動將請求轉發到其他正常節點上,確保數據的可靠性和系統的穩定性。
三、選型的關鍵維度
3.1 性能指標是核心
性能指標無疑是選擇時序數據庫時最為關鍵的考量因素之一,它直接關乎系統在實際應用中的表現和效率。
在寫入性能方面,時序數據的產生往往具有高頻、連續的特點。以智能電網中的電表數據采集為例,每個電表可能每隔 15 分鐘就會上傳一次用電量數據,一個中等規模的城市電網可能擁有數百萬個電表,這就意味著每秒都有大量的數據需要寫入數據庫。如果時序數據庫的寫入性能不足,就會導致數據積壓、丟失,無法滿足實時監控和分析的需求。在這種高并發寫入場景下,優秀的時序數據庫應具備高效的寫入算法和存儲結構,能夠實現每秒數十萬甚至數百萬條數據的寫入,確保數據的及時存儲。
查詢性能同樣至關重要。當企業需要對歷史數據進行分析,如查詢某段時間內設備的運行狀態、統計用戶的用電習慣時,快速的查詢響應是必不可少的。在金融領域,對股票交易數據的查詢要求毫秒級響應,以便投資者能夠及時做出決策。一個高效的時序數據庫應具備優化的查詢引擎和索引機制,能夠在短時間內返回復雜查詢的結果,滿足用戶對數據實時分析的需求。例如,在處理海量的物聯網設備數據時,能夠在秒級甚至毫秒級內完成時間窗口查詢和聚合查詢,為企業的決策提供有力支持。
壓縮性能則直接關系到存儲成本。由于時序數據具有高頻采集、數據量大的特點,如果不進行有效的壓縮,將會占用大量的存儲空間。以某智能工廠為例,其設備運行數據在未壓縮的情況下,每月需要占用數 TB 的存儲空間,而使用具有高效壓縮性能的時序數據庫后,通過差分編碼、游程編碼等壓縮算法,能夠將數據壓縮到原來的幾分之一甚至幾十分之一,大大降低了存儲成本。同時,良好的壓縮性能還能減少數據傳輸的帶寬需求,提高系統的整體性能。
3.2 數據模型要適配
不同的時序數據庫采用了不同的數據模型,選擇適配業務場景的數據模型對于系統的性能和易用性至關重要。
IoTDB 采用的是樹形數據模型,這種模型將設備和測點以樹形結構進行組織,非常貼合工業物聯網中設備的層級管理體系。在一個大型工廠中,設備通常按照車間、生產線、設備單元等層級進行組織,每個設備又包含多個測點,如溫度、壓力、轉速等。使用 IoTDB 的樹形模型,可以直觀地對這些設備和測點進行管理和查詢。例如,通過簡單的路徑表達式 “root.factory.area1.line1.device1.temperature”,就可以快速定位到特定設備的溫度測點,方便進行數據的存儲和查詢。這種模型還支持通配符查詢,如 “root.factory..device1.”,可以查詢所有工廠中設備 1 的所有測點數據,大大提高了查詢的靈活性。
InfluxDB 則采用了 Tag - Set 模型,數據點由時間戳、測量名稱、標簽集和字段集組成。標簽集用于對數據進行分類和索引,字段集則存儲實際的數值數據。這種模型在處理具有豐富標簽信息的數據時具有優勢,能夠方便地進行多維度的查詢和分析。在監控系統中,可以通過標簽對不同的服務器、服務進行分類,然后根據標簽查詢特定服務器或服務的性能指標。但是,當標簽的基數過高,即標簽的取值種類過多時,會導致索引膨脹,影響查詢性能。
在選擇數據模型時,需要根據業務場景的特點進行權衡。如果業務場景中設備的層級關系明顯,如工業物聯網、智能建筑等領域,IoTDB 的樹形模型可能更為合適;如果數據具有豐富的標簽信息,且需要進行多維度的分析,如監控系統、金融數據分析等領域,InfluxDB 的 Tag - Set 模型可能更能發揮其優勢。
3.3 擴展性決定未來
隨著業務的發展和數據量的不斷增長,系統的擴展性成為了時序數據庫選型中不可忽視的因素。一個具有良好擴展性的時序數據庫能夠輕松應對數據量的爆發式增長,保證系統的性能和可用性。
在物聯網領域,隨著設備數量的不斷增加,數據量會呈現指數級增長。在一個智能城市項目中,可能會涉及數百萬個傳感器,每天產生的數據量可達 PB 級別。如果時序數據庫不具備良好的擴展性,當數據量超過系統的承載能力時,就會出現性能下降、服務中斷等問題。因此,選擇具有分布式架構的時序數據庫至關重要。
IoTDB 的端邊云協同架構在擴展性方面具有顯著優勢。在邊緣端,IoTDB 可以部署在資源受限的設備上,實現數據的本地存儲和初步處理,減少數據傳輸的壓力。邊緣設備產生的數據可以通過異步同步的方式傳輸到云端的 IoTDB 集群中。云端的 IoTDB 集群采用分布式架構,通過增加節點可以實現水平擴展,輕松應對海量數據的存儲和處理需求。這種架構不僅保證了現場控制的實時性,又滿足了中心化分析的需求,為企業的數字化轉型提供了有力的支持。
3.4 生態兼容性不可少
生態兼容性是指時序數據庫與其他相關技術和工具的集成能力,它對于提高系統的整體效能和降低開發成本具有重要意義。
在大數據生態系統中,IoTDB 與 Hadoop、Spark、Flink 等大數據處理框架實現了良好的集成。IoTDB 可以作為 Hadoop 的數據源,將存儲在 IoTDB 中的時序數據導入到 Hadoop 中進行大規模的數據處理和分析。通過與 Spark 的集成,可以利用 Spark 強大的計算能力對 IoTDB 中的數據進行實時分析和機器學習模型訓練。在能源領域,電力公司可以將電網設備的運行數據存儲在 IoTDB 中,然后通過與 Spark 的集成,對這些數據進行實時分析,預測設備故障,優化電力調度。
IoTDB 與可視化工具的兼容性也為數據的展示和監控提供了便利。以 Grafana 為例,它是一款廣泛使用的開源可視化工具,IoTDB 與 Grafana 實現了無縫集成。用戶可以通過 Grafana 輕松地連接到 IoTDB,將存儲在 IoTDB 中的時序數據以各種圖表的形式展示出來,如折線圖、柱狀圖、餅圖等,直觀地監控設備的運行狀態和數據趨勢。在智能工廠中,管理人員可以通過 Grafana 實時監控生產線上設備的運行參數,及時發現異常情況,提高生產效率和質量。
3.5 運維復雜度需考量
運維復雜度是影響項目成功實施和長期穩定運行的重要因素之一。一個復雜的運維環境不僅會增加運維成本,還會提高系統出現故障的風險,影響業務的正常開展。
在傳統的數據庫系統中,復雜的配置、繁瑣的管理操作以及難以排查的故障往往給運維人員帶來巨大的挑戰。在一些大型企業中,運維人員需要花費大量的時間和精力來維護數據庫系統,一旦出現問題,可能需要數小時甚至數天才能恢復,給企業帶來嚴重的損失。
IoTDB 在設計上充分考慮了降低運維復雜度的需求。它采用了類 SQL 語法,對于熟悉 SQL 的開發人員和運維人員來說,幾乎不需要額外的學習成本,就能夠輕松地進行數據的操作和管理。IoTDB 還提供了一體化監控平臺,內置了 300 多個監控指標,涵蓋了數據庫的性能、資源使用情況、數據存儲等各個方面。運維人員可以通過監控平臺實時了解數據庫的運行狀態,及時發現潛在的問題。當數據庫出現性能下降時,運維人員可以通過監控平臺查看 CPU 使用率、內存使用情況、磁盤 I/O 等指標,快速定位問題的根源。IoTDB 還提供了智能調參工具,能夠根據系統的運行狀態自動優化內存、線程等配置,進一步降低了運維的難度。
四、IoTDB 的獨特優勢
4.1 強大的性能表現
IoTDB 在性能方面表現卓越,其寫入、查詢和壓縮等關鍵性能指標展現出顯著優勢。
在寫入性能上,IoTDB 單機版可達千萬級數據點 / 秒,這一數據令人驚嘆。在一個擁有 10 萬個傳感器的智能城市項目中,每個傳感器每秒產生 10 條數據,IoTDB 可以輕松應對這樣的高并發寫入場景,確保數據的實時采集和存儲,而不會出現數據積壓或丟失的情況。分布式版本的 IoTDB 支持水平擴展,能夠滿足超大規模數據采集需求。通過增加節點,可以線性地提升系統的寫入吞吐量,輕松應對數據量的爆發式增長。
查詢性能同樣出色。IoTDB 支持按時間范圍、設備 ID、指標標簽快速檢索。在處理海量的物聯網設備數據時,能夠在秒級甚至毫秒級內完成時間窗口查詢和聚合查詢。例如,在查詢某一天內所有設備的運行數據時,IoTDB 可以利用高效的索引機制,快速定位到所需的數據,大大提高了查詢效率,為企業的實時監控和決策提供了有力支持。
IoTDB 采用了自研的時序文件格式 TsFile,結合先進的編碼技術與時序友好的索引結構,大大提高了數據存儲效率。針對不同類型的數據,如整數、浮點數、字符串等,IoTDB 采用了自適應壓縮算法,能夠將存儲空間減少 80% 以上,實現了 10:1 的壓縮比 。這意味著在存儲相同數量的數據時,IoTDB 所需的存儲空間僅為其他數據庫的十分之一,大大降低了存儲成本。
4.2 靈活的數據模型
IoTDB 采用了獨特的樹形時序數據模型,這種模型將設備和測點以樹形結構進行組織,非常貼合工業物聯網中設備的層級管理體系。
在一個大型工廠中,設備通常按照車間、生產線、設備單元等層級進行組織,每個設備又包含多個測點,如溫度、壓力、轉速等。使用 IoTDB 的樹形模型,可以直觀地對這些設備和測點進行管理和查詢。例如,通過簡單的路徑表達式 “root.factory.area1.line1.device1.temperature”,就可以快速定位到特定設備的溫度測點,方便進行數據的存儲和查詢。這種模型還支持通配符查詢,如 “root.factory..device1.”,可以查詢所有工廠中設備 1 的所有測點數據,大大提高了查詢的靈活性。
在智能建筑領域,IoTDB 的樹形數據模型同樣發揮著重要作用。一座大型商業建筑中,包含多個樓層,每個樓層又有多個房間,每個房間內配備了各種智能設備,如空調、照明、安防傳感器等。使用 IoTDB,我們可以將建筑的樓層、房間和設備構建成一個樹形結構。通過路徑表達式 “root.building.floor1.room1.airConditioner.temperature”,可以輕松獲取到特定房間內空調的溫度數據。這種直觀的模型使得數據管理和查詢變得簡單高效,提高了建筑智能化管理的效率。
4.3 端邊云協同架構
IoTDB 的端邊云協同架構是其一大亮點,這種架構充分考慮了物聯網場景中數據處理的多樣性和復雜性。
在邊緣端,IoTDB 可以部署在資源受限的設備上,如樹莓派、工業網關等,實現本地數據緩存和預處理。這不僅減少了數據傳輸的壓力,還提高了數據處理的實時性。在工業生產現場,設備產生的數據量巨大,如果全部上傳到云端進行處理,不僅會消耗大量的網絡帶寬,還可能導致數據處理的延遲。通過在邊緣端部署 IoTDB,可以對數據進行初步的過濾、聚合和分析,只將關鍵數據上傳到云端,大大降低了數據傳輸的成本和延遲。
云端的 IoTDB 集群采用分布式架構,支持水平擴展,可以輕松應對海量數據的存儲和處理需求。IoTDB 可以與 HDFS、對象存儲(如 S3)集成,實現海量數據的長期存儲。在智能電網中,電力公司需要存儲和分析大量的電力數據,包括電網設備的運行狀態、用戶的用電量等。通過 IoTDB 的端邊云協同架構,邊緣端的設備可以實時采集電力數據,并進行初步處理,然后將處理后的數據同步到云端的 IoTDB 集群中。云端的 IoTDB 集群可以利用其強大的計算能力和存儲能力,對這些數據進行深度分析,為電力調度、設備維護等提供決策支持。
在工業斷網場景下,IoTDB 的端邊云協同架構也能發揮重要作用。當工廠與云端的網絡連接中斷時,邊緣端的 IoTDB 可以繼續存儲和處理本地設備產生的數據。一旦網絡恢復,邊緣端的 IoTDB 可以將緩存的數據同步到云端,確保數據的完整性和一致性。
4.4 豐富的生態集成
IoTDB 與大數據生態系統、可視化工具、工業協議等實現了豐富的集成,展現了強大的生態兼容性。
在大數據生態系統方面,IoTDB 與 Hadoop、Spark、Flink 等大數據處理框架實現了無縫集成。IoTDB 可以作為 Hadoop 的數據源,將存儲在 IoTDB 中的時序數據導入到 Hadoop 中進行大規模的數據處理和分析。通過與 Spark 的集成,可以利用 Spark 強大的計算能力對 IoTDB 中的數據進行實時分析和機器學習模型訓練。在能源領域,電力公司可以將電網設備的運行數據存儲在 IoTDB 中,然后通過與 Spark 的集成,對這些數據進行實時分析,預測設備故障,優化電力調度。
IoTDB 與可視化工具的集成也為數據的展示和監控提供了便利。以 Grafana 為例,它是一款廣泛使用的開源可視化工具,IoTDB 與 Grafana 實現了無縫集成。用戶可以通過 Grafana 輕松地連接到 IoTDB,將存儲在 IoTDB 中的時序數據以各種圖表的形式展示出來,如折線圖、柱狀圖、餅圖等,直觀地監控設備的運行狀態和數據趨勢。在智能工廠中,管理人員可以通過 Grafana 實時監控生產線上設備的運行參數,及時發現異常情況,提高生產效率和質量。
IoTDB 還支持多種工業協議,如 OPC-UA、MQTT 等,方便與工業設備進行對接。在智能制造場景中,IoTDB 可以通過 OPC-UA 協議與工業自動化設備進行通信,實時采集設備的運行數據,實現對生產過程的實時監控和優化。
4.5 開源與社區支持
IoTDB 是 Apache 頂級項目,這意味著它具有完全開源的優勢,企業可以自由使用和定制,無需擔心商業限制。
IoTDB 擁有一個活躍的社區,由清華大學團隊和全球開發者共同維護。社區的活躍性體現在多個方面,首先是版本迭代速度快,能夠及時推出新的功能和優化性能。其次,社區對用戶的問題響應迅速,用戶在使用 IoTDB 的過程中遇到問題,可以通過社區的郵件列表、論壇等渠道尋求幫助,通常能夠得到及時的解答和支持。
社區還積極開展各種活動,如技術交流、代碼貢獻等,鼓勵開發者參與到 IoTDB 的開發和改進中來。通過社區的力量,IoTDB 不斷完善和發展,為用戶提供更好的服務和體驗。
五、與國外產品的全面對比
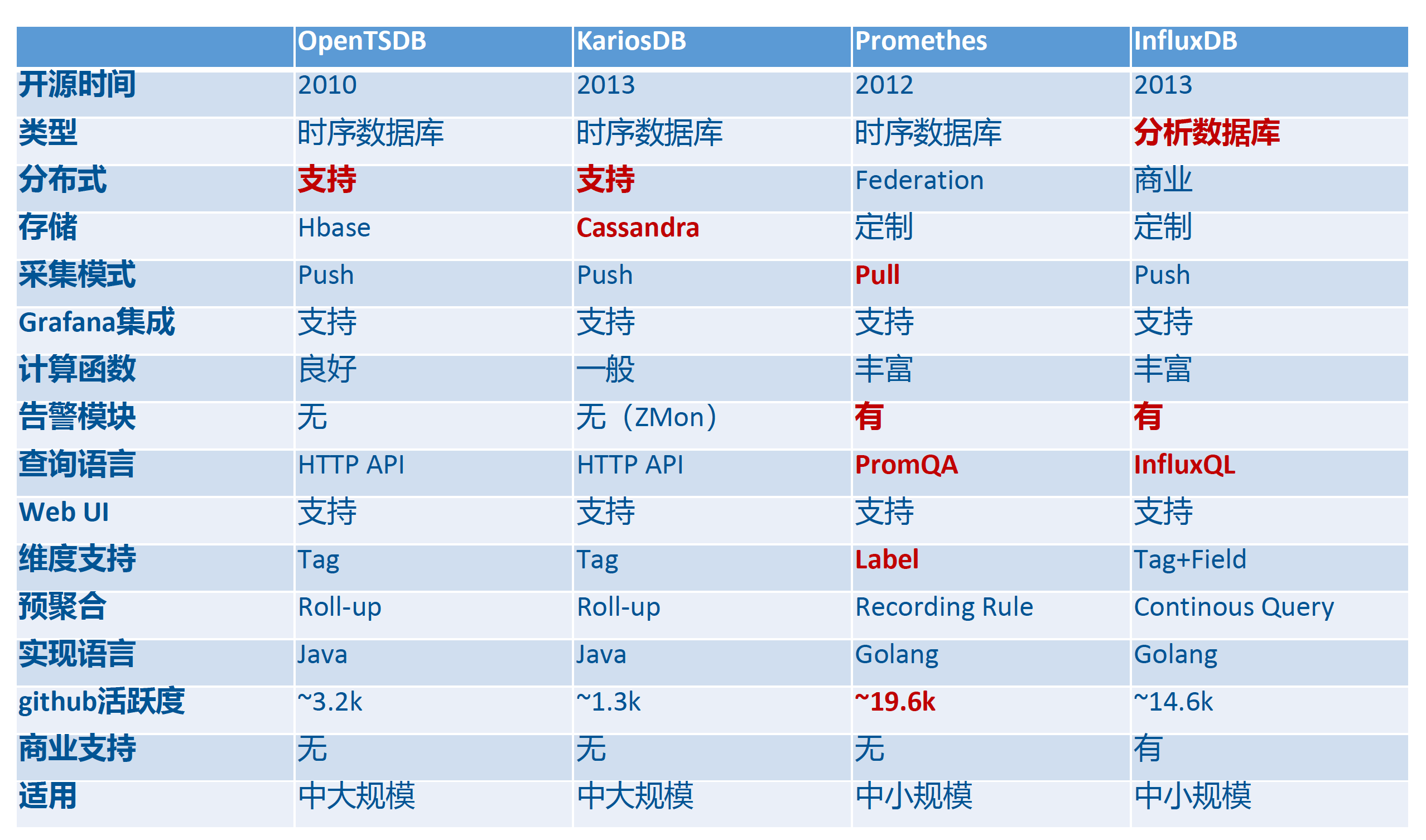
5.1 架構設計對比
IoTDB 采用樹狀數據模型與分布式時序引擎架構,專為工業設備層級化管理設計。樹狀數據模型將設備和測點以樹形結構進行組織,非常貼合工業物聯網中設備的層級管理體系。在一個大型工廠中,設備通常按照車間、生產線、設備單元等層級進行組織,每個設備又包含多個測點,如溫度、壓力、轉速等。使用 IoTDB 的樹形模型,可以直觀地對這些設備和測點進行管理和查詢。通過簡單的路徑表達式 “root.factory.area1.line1.device1.temperature”,就可以快速定位到特定設備的溫度測點,方便進行數據的存儲和查詢。這種模型還支持通配符查詢,如 “root.factory..device1.”,可以查詢所有工廠中設備 1 的所有測點數據,大大提高了查詢的靈活性。
InfluxDB 采用基于標簽(Tag)的扁平化結構,數據點由時間戳(Timestamp)、測量(Measurement)、標簽集(Tag Set)和字段集(Field Set)組成。這種結構在處理具有豐富標簽信息的數據時具有優勢,能夠方便地進行多維度的查詢和分析。在監控系統中,可以通過標簽對不同的服務器、服務進行分類,然后根據標簽查詢特定服務器或服務的性能指標。但是,當標簽的基數過高,即標簽的取值種類過多時,會導致索引膨脹,影響查詢性能。InfluxDB 開源版僅支持單機部署,企業版雖提供集群功能,但元數據管理依賴獨立節點,運維復雜度較高。
TimescaleDB 基于 PostgreSQL 擴展,采用 Hypertables 實現時間分片。這種架構使得 TimescaleDB 能夠兼容 PostgreSQL 的生態,支持 SQL 語法,適合需要關系型數據庫功能的場景。但是,由于其是在 PostgreSQL 基礎上的擴展,在處理億級測點時易出現索引膨脹問題,對時序數據的深度優化不足。
5.2 核心性能實測
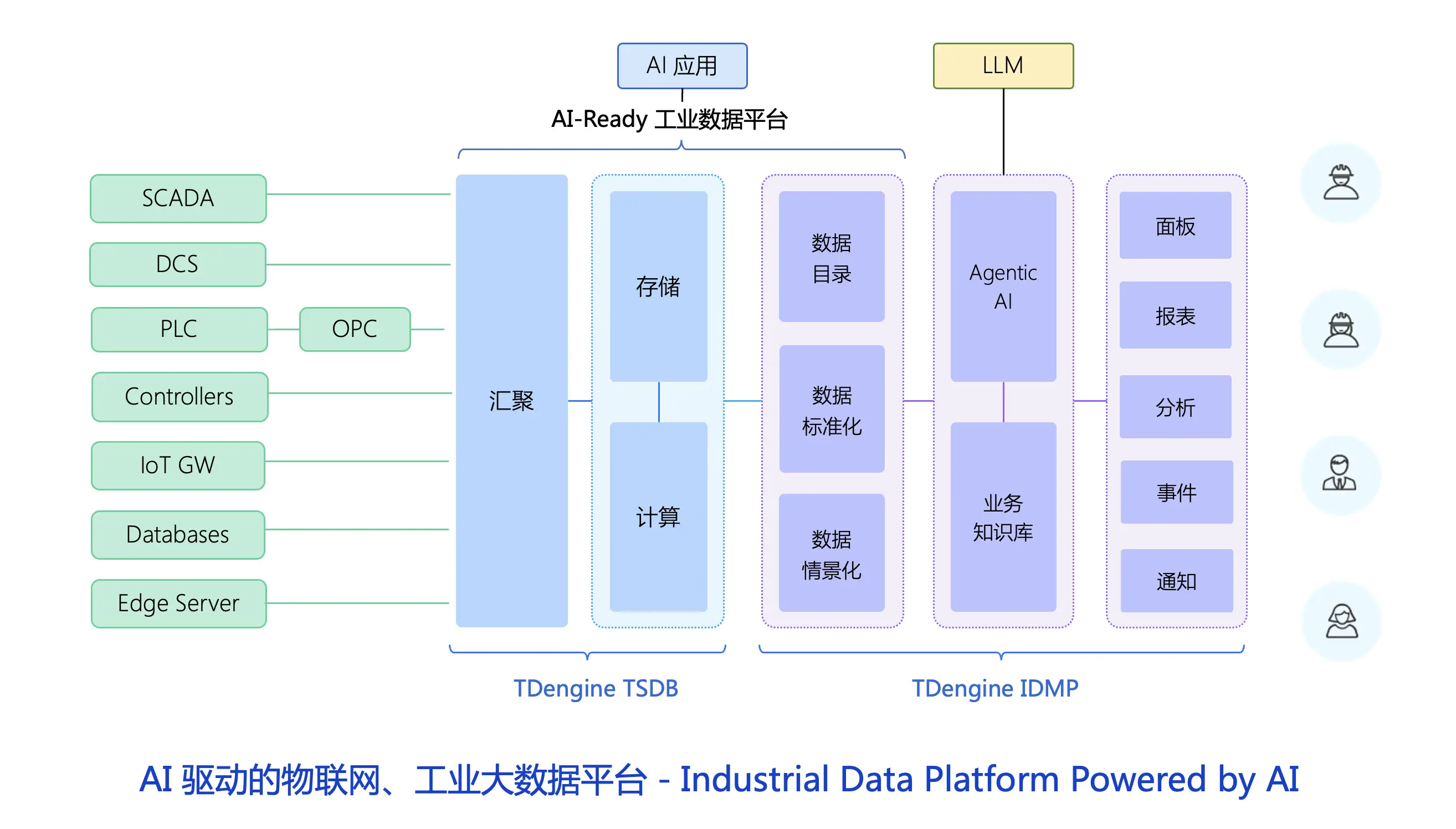
在核心性能方面,我們通過實際測試來對比 IoTDB 與其他產品的差異。在相同硬件配置(8C/32G/SSD)下,對 IoTDB、InfluxDB 和 TimescaleDB 進行性能測試,結果如下:
- 寫入性能:IoTDB 單機寫入性能表現出色,可達 50 萬 TPS ,能夠滿足高并發寫入的需求。在物聯網場景中,大量傳感器的數據需要實時寫入數據庫,IoTDB 的高寫入性能可以確保數據的及時存儲,不會出現數據積壓或丟失的情況。InfluxDB 2.7 版的寫入性能為 10 萬 TPS ,在高并發場景下可能會出現寫入延遲的問題。TimescaleDB 的寫入性能為 15 萬 TPS ,相對來說也無法與 IoTDB 的高寫入性能相媲美。
- 壓縮效率:IoTDB 通過 Gorilla 編碼 + 二階差分算法實現了 18:1 的高壓縮比,能夠將存儲空間減少到原來的十八分之一,大大降低了存儲成本。在某儲能電站案例中,IoTDB 將 4.8TB 原始數據壓縮至 267GB,月度存儲成本從 5760 元降至 1015 元 。InfluxDB 的壓縮比為 8:1 ,在存儲大量數據時,存儲成本相對較高。TimescaleDB 的壓縮比為 12:1 ,雖然也有一定的壓縮效果,但與 IoTDB 相比仍有差距。
- 查詢延遲:在 10 萬測點、10 年跨度數據查詢中,IoTDB P99 延遲小于 500ms,能夠快速響應用戶的查詢請求,滿足實時監控和分析的需求。InfluxDB 的查詢延遲為 3.2s ,在需要快速獲取數據的場景下,可能無法滿足用戶的需求。TimescaleDB 的查詢延遲為 1.1s ,雖然比 InfluxDB 有所改善,但與 IoTDB 相比,查詢速度仍較慢。
5.3 生態集成差異
IoTDB 與大數據生態系統、可視化工具、工業協議等實現了豐富的集成,展現了強大的生態兼容性。在大數據生態系統方面,IoTDB 與 Hadoop、Spark、Flink 等大數據處理框架實現了無縫集成。IoTDB 可以作為 Hadoop 的數據源,將存儲在 IoTDB 中的時序數據導入到 Hadoop 中進行大規模的數據處理和分析。通過與 Spark 的集成,可以利用 Spark 強大的計算能力對 IoTDB 中的數據進行實時分析和機器學習模型訓練。在能源領域,電力公司可以將電網設備的運行數據存儲在 IoTDB 中,然后通過與 Spark 的集成,對這些數據進行實時分析,預測設備故障,優化電力調度。
IoTDB 與可視化工具的集成也為數據的展示和監控提供了便利。以 Grafana 為例,它是一款廣泛使用的開源可視化工具,IoTDB 與 Grafana 實現了無縫集成。用戶可以通過 Grafana 輕松地連接到 IoTDB,將存儲在 IoTDB 中的時序數據以各種圖表的形式展示出來,如折線圖、柱狀圖、餅圖等,直觀地監控設備的運行狀態和數據趨勢。在智能工廠中,管理人員可以通過 Grafana 實時監控生產線上設備的運行參數,及時發現異常情況,提高生產效率和質量。
IoTDB 還支持多種工業協議,如 OPC-UA、MQTT 等,方便與工業設備進行對接。在智能制造場景中,IoTDB 可以通過 OPC-UA 協議與工業自動化設備進行通信,實時采集設備的運行數據,實現對生產過程的實時監控和優化。
InfluxDB 的生態聚焦監控領域,與 Prometheus、Grafana 無縫集成,在監控場景中具有廣泛的應用。但是,InfluxDB 缺乏工業協議(如 OPC UA)原生支持,在工業物聯網場景中,需要額外開發插件或進行復雜的配置才能與工業設備進行對接。
TimescaleDB 依賴 PostgreSQL 生態,適合混合分析場景,但在處理時序數據時,需要額外開發時序數據預處理模塊,以滿足時序數據處理的特殊需求。
5.4 代碼案例分享
(1)java
package org.apache.iotdb;import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;import java.util.ArrayList;
import java.util.List;public class SessionExample {private static Session session;public static void main(String[] args)throws IoTDBConnectionException, StatementExecutionException {session =new Session.Builder().host("172.0.0.1").port(6667).username("root").password("root").build();session.open(false);List<MeasurementSchema> schemaList = new ArrayList<>();schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));Tablet tablet = new Tablet("root.db.d1", schemaList, 10);tablet.addTimestamp(0, 1);tablet.addValue("s1", 0, 1.23f);tablet.addValue("s2", 0, 1.23f);tablet.addValue("s3", 0, 1.23f);tablet.rowSize++;session.insertTablet(tablet);tablet.reset();try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {while (dataSet.hasNext()) {System.out.println(dataSet.next());}}session.close();}
}
(2)python
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tabletip = "127.0.0.1"
port = "6667"
username = "root"
password = "root"
session = Session(ip, port, username, password)
session.open(False)measurements = ["s_01", "s_02", "s_03", "s_04", "s_05", "s_06"]
data_types = [TSDataType.BOOLEAN,TSDataType.INT32,TSDataType.INT64,TSDataType.FLOAT,TSDataType.DOUBLE,TSDataType.TEXT,
]
values = [[False, 10, 11, 1.1, 10011.1, "test01"],[True, 100, 11111, 1.25, 101.0, "test02"],[False, 100, 1, 188.1, 688.25, "test03"],[True, 0, 0, 0, 6.25, "test04"],
]
timestamps = [1, 2, 3, 4]
tablet = Tablet("root.db.d_03", measurements, data_types, values, timestamps
)
session.insert_tablet(tablet)with session.execute_statement("select ** from root.db"
) as session_data_set:while session_data_set.has_next():print(session_data_set.next())session.close()
(3)C++
#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>int main(int argc, char **argv) {Session *session = new Session("127.0.0.1", 6667, "root", "root");session->open();std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;schemas.push_back({"s0", TSDataType::INT64});schemas.push_back({"s1", TSDataType::INT64});schemas.push_back({"s2", TSDataType::INT64});int64_t val = 0;Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);tablet.rowSize++;tablet.timestamps[0] = 0;val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);session->insertTablet(tablet);tablet.reset();std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");while (res->hasNext()) {std::cout << res->next()->toString() << std::endl;}res.reset();session->close();delete session;return 0;
}
(4) Go
package mainimport ("fmt""log""github.com/apache/iotdb-client-go/client"
)func main() {config := &client.Config{Host: "127.0.0.1",Port: "6667",UserName: "root",Password: "root",}session := client.NewSession(config)if err := session.Open(false, 0); err != nil {log.Fatal(err)}defer session.Close() // close session at end of main()rowCount := 3tablet, err := client.NewTablet("root.db.d1", []*client.MeasurementSchema{{Measurement: "restart_count",DataType: client.INT32,Encoding: client.RLE,Compressor: client.SNAPPY,}, {Measurement: "price",DataType: client.DOUBLE,Encoding: client.GORILLA,Compressor: client.SNAPPY,}, {Measurement: "description",DataType: client.TEXT,Encoding: client.PLAIN,Compressor: client.SNAPPY,},}, rowCount)if err != nil {fmt.Errorf("Tablet create error:", err)return}timestampList := []int64{0, 1, 2}valuesInt32List := []int32{5, -99999, 123456}valuesDoubleList := []float64{-0.001, 10e5, 54321.0}valuesTextList := []string{"test1", "test2", "test3"}for row := 0; row < rowCount; row++ {tablet.SetTimestamp(timestampList[row], row)tablet.SetValueAt(valuesInt32List[row], 0, row)tablet.SetValueAt(valuesDoubleList[row], 1, row)tablet.SetValueAt(valuesTextList[row], 2, row)}session.InsertTablet(tablet, false)var timeoutInMs int64timeoutInMs = 1000sql := "select ** from root.db"dataset, err := session.ExecuteQueryStatement(sql, &timeoutInMs)defer dataset.Close()if err == nil {for next, err := dataset.Next(); err == nil && next; next, err = dataset.Next() {record, _ := dataset.GetRowRecord()fields := record.GetFields()for _, field := range fields {fmt.Print(field.GetValue(), "\t")}fmt.Println()}} else {log.Println(err)}
}
六、行業應用案例

6.1 能源電力行業
在能源電力行業,IoTDB 展現出了強大的實力,為省級電網的高效運行提供了有力支持。以某省級電網為例,該電網采用 IoTDB 后,取得了顯著的成效。
在數據規模方面,成功接入了 200 萬 + 采集點,日新增數據量高達 50TB 。如此龐大的數據規模,對數據庫的存儲和處理能力提出了極高的挑戰。IoTDB 憑借其高效的存儲結構和強大的處理能力,輕松應對了這一挑戰,確保了數據的穩定存儲和高效處理。
查詢性能上,IoTDB 的表現同樣出色。以往,該省級電網在進行故障追溯時,需要花費數小時才能完成數據的查詢和分析,這對于及時發現和解決電網故障來說,時間成本過高。而采用 IoTDB 后,故障追溯時間從小時級降至秒級 。這意味著當電網出現故障時,運維人員可以在極短的時間內獲取相關數據,快速定位故障點,采取有效的解決措施,大大提高了電網的可靠性和穩定性。
IoTDB 還具備網閘穿透、斷點續傳等工業特性,有效解決了能源電力行業中數據傳輸和安全隔離的難題。在電力系統中,為了確保生產網和辦公網的安全,通常會架設網閘進行隔離。IoTDB 通過協議優化、網閘適配等方式,實現了跨網數據傳輸,確保了數據的安全和高效流轉。在數據傳輸過程中,當出現網絡中斷等異常情況時,IoTDB 的斷點續傳功能能夠保證數據的完整性,避免數據丟失。
6.2 智能制造行業
在智能制造行業,IoTDB 也發揮著重要作用,為汽車工廠的智能化生產提供了關鍵支持。以某汽車工廠為例,該工廠擁有 5000 + 設備,這些設備的采樣頻率高達 100ms ,每天產生的數據量巨大。
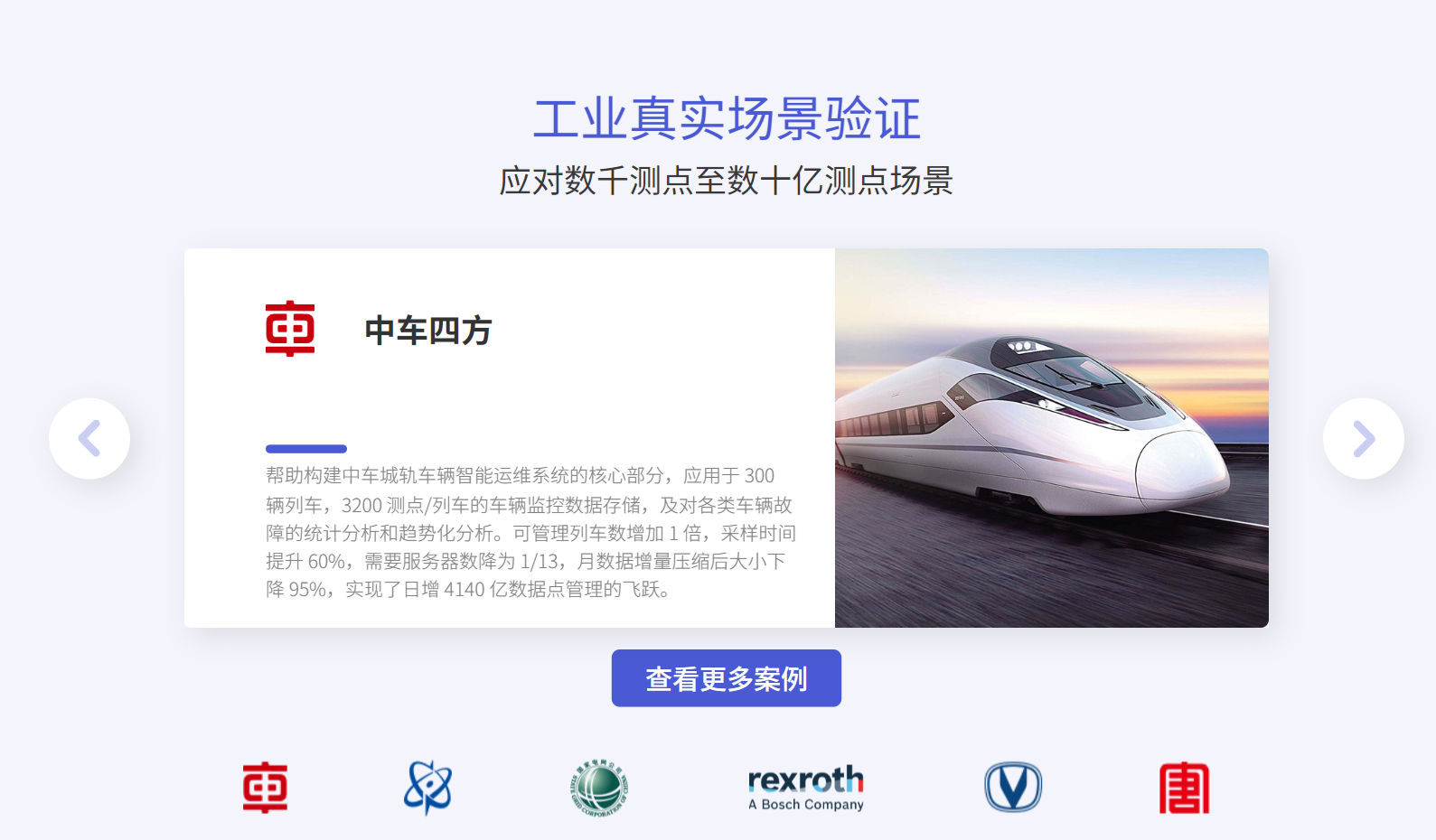
在采用 IoTDB 之前,該汽車工廠面臨著存儲成本高昂、數據處理效率低下等問題。而引入 IoTDB 后,這些問題得到了有效解決。IoTDB 通過其高效的壓縮算法,實現了存儲成本降低 82% ,為企業節省了大量的資金。在數據處理方面,IoTDB 支持邊緣預處理,能夠在設備端對數據進行初步處理和分析,減少了 90% 的網絡傳輸 。這不僅降低了網絡帶寬的壓力,還提高了數據處理的實時性,使得工廠能夠及時獲取設備的運行狀態,做出相應的生產決策。
IoTDB 的樹形數據模型與汽車工廠的設備層級管理體系完美契合。在汽車生產線上,設備通常按照生產線、工位、設備等層級進行組織,每個設備又包含多個測點,如溫度、壓力、轉速等。使用 IoTDB 的樹形模型,可以直觀地對這些設備和測點進行管理和查詢。通過簡單的路徑表達式 “root.factory.productionLine1.workstation1.device1.temperature”,就可以快速定位到特定設備的溫度測點,方便進行數據的存儲和查詢。這種模型還支持通配符查詢,如 “root.factory..workstation1.device1.”,可以查詢所有生產線中工位 1 上設備 1 的所有測點數據,大大提高了查詢的靈活性。
6.3 其他行業應用

車聯網
在車聯網領域,長安汽車選擇 IoTDB 作為車聯網平臺的核心數據存儲引擎,實現了千萬級車輛的穩定接入和千萬點每秒的數據并發處理 。IoTDB 的高并發處理能力和強大的存儲功能,確保了車輛實時數據的高效采集和存儲,為車輛的遠程控制、故障預警等功能提供了有力支持。通過 IoTDB,長安汽車能夠實時獲取車輛的位置、行駛狀態、故障信息等數據,及時為用戶提供服務,提升了用戶的用車體驗。
智慧城市
北斗智慧物聯在智慧城市建設中,利用 IoTDB 構建了智慧環衛、智慧園林、智慧市政等多個應用平臺 。IoTDB 用于存儲和處理環衛車輛的位置、狀態、作業數據等時序數據,以及園林傳感器的數據、市政設施的運行數據等。通過 IoTDB 的高效寫入和快速查詢功能,實現了對城市設施的實時監控和智能化管理,提高了城市管理的效率和質量。在智慧環衛平臺中,IoTDB 能夠實時跟蹤環衛車輛的行駛路線和垃圾清運情況,優化垃圾轉運和處理流程,提升環衛工作的效率和效果。
邊緣計算

EdgeX Foundry 與 IoTDB 集成,實現了邊緣側持久化存儲 。IoTDB 的邊緣版本具有體量更輕、性能高、易使用的特點,適用于工業物聯網應用中海量時間序列數據高速寫入和復雜分析查詢的需求。通過與 EdgeX Foundry 的集成,IoTDB 能夠將采集到的數據自動轉儲到邊緣版實例中,實現了數據的本地存儲和初步處理,減少了數據傳輸的壓力,提高了數據處理的實時性。在工業生產現場,IoTDB 的邊緣版本可以實時采集設備數據,并進行初步的分析和處理,為現場控制提供了有力支持。
七、選型實踐建議
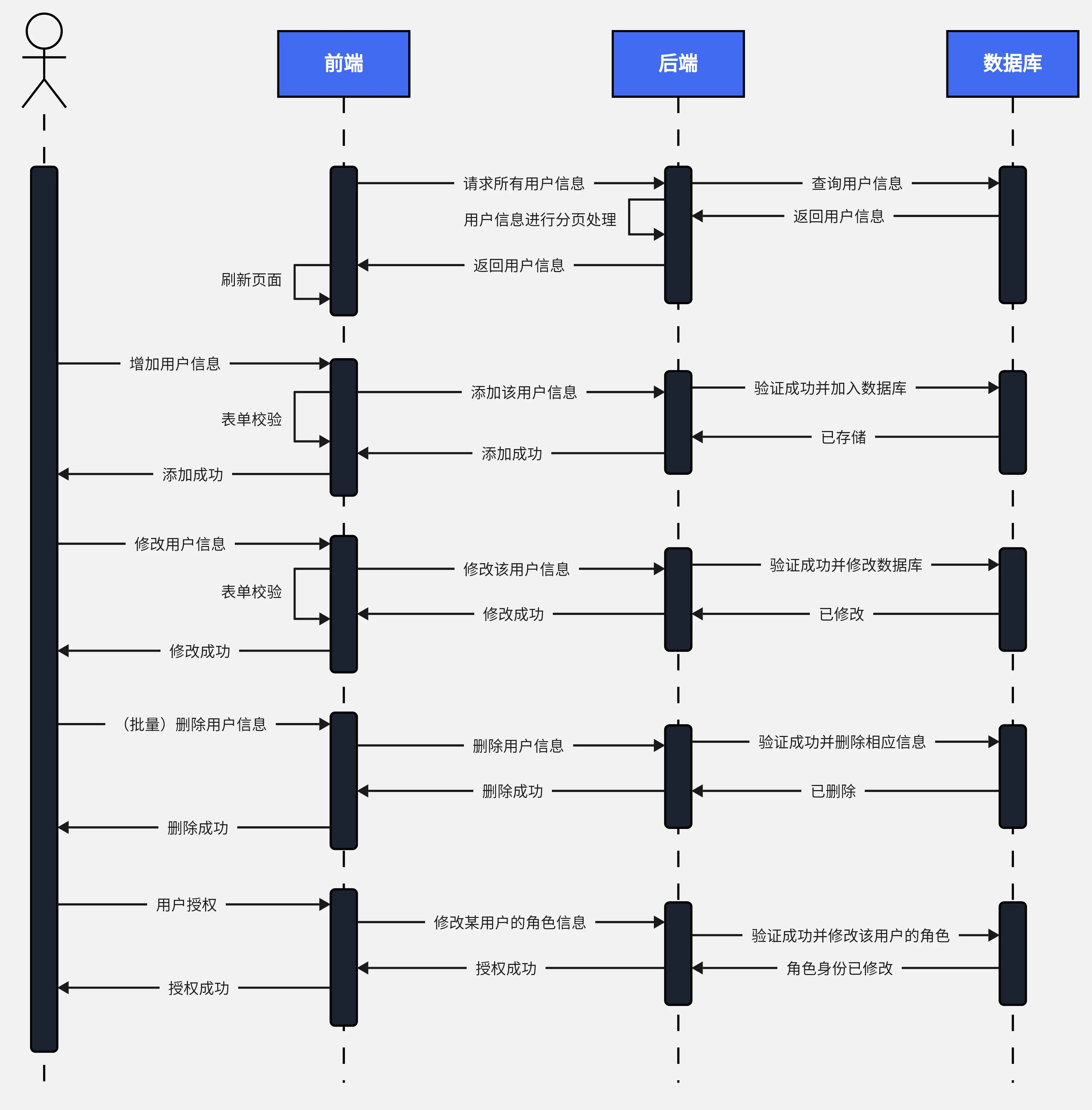
7.1 需求分析是基礎
在進行時序數據庫選型之前,深入的需求分析是至關重要的基礎步驟。首先,需要準確評估數據規模,這包括設備數、測點數以及數據采集頻率。在一個大型的智能工廠中,可能擁有數千臺設備,每臺設備又包含數十個甚至數百個測點,且數據采集頻率可能達到毫秒級。通過計算設備數 × 測點數 × 頻率,能夠預估出數據的產生量和增長趨勢,以便選擇能夠承載相應數據規模的時序數據庫。
明確查詢模式也是關鍵。查詢模式主要包括實時監控和歷史分析。在實時監控場景中,需要數據庫能夠快速返回最新的數據,以滿足對設備運行狀態的即時了解。例如,在電力系統中,監控人員需要實時獲取電網設備的電壓、電流等參數,以便及時發現異常情況。而歷史分析則側重于對過去一段時間內的數據進行統計和分析,以發現數據的趨勢和規律。在工業生產中,通過對歷史生產數據的分析,可以優化生產流程,提高生產效率。
確定 SLA(服務級別協議)要求同樣不可或缺。SLA 要求包括可用性、延遲指標等。對于一些關鍵業務系統,如金融交易系統、航空交通管制系統等,對數據庫的可用性要求極高,需要保證系統能夠 7×24 小時不間斷運行,且延遲指標要控制在毫秒級甚至微秒級。在選擇時序數據庫時,需要確保其能夠滿足這些嚴格的 SLA 要求,以保障業務的正常運行。
7.2 概念驗證要點
在確定候選的時序數據庫后,進行概念驗證(POC)是確保其滿足實際需求的重要環節。首先,要測試真實數據集的壓縮率。由于時序數據量通常較大,高效的壓縮能夠顯著降低存儲成本。通過使用真實的業務數據集進行測試,可以準確了解數據庫在實際數據特征下的壓縮效果。以某風電企業為例,在測試不同時序數據庫時,發現 IoTDB 通過自適應編碼算法和列式存儲結構,實現了極高的壓縮比,存儲空間僅為原方案的 1/20,年節省存儲成本超 300 萬元。
模擬峰值寫入壓力也是 POC 的要點之一。在實際應用中,可能會出現數據突發增長的情況,如在智能城市項目中,當遇到重大活動或突發事件時,傳感器的數據采集量可能會瞬間大幅增加。通過模擬峰值寫入壓力,能夠測試數據庫在高并發寫入場景下的性能表現,確保其能夠穩定運行,不會出現寫入延遲或數據丟失的情況。
驗證關鍵查詢性能同樣重要。根據業務需求,確定關鍵的查詢場景,如時間窗口查詢、聚合查詢等,并對這些查詢進行性能測試。在一個監控系統中,經常需要查詢某段時間內設備的平均性能指標,通過對不同時序數據庫的查詢性能測試,可以選擇出能夠快速響應這類查詢的數據庫,提高系統的實時性和分析效率。
7.3 部署策略規劃
在部署時序數據庫時,合理的部署策略規劃能夠確保系統的穩定運行和高效擴展。首先,可以進行小規模試點,在一個較小的業務范圍內部署時序數據庫,如在一個車間或一個部門內部,對數據庫的性能、功能和兼容性進行初步驗證。通過小規模試點,可以及時發現問題并進行調整,降低大規模部署的風險。
隨著業務的發展和對數據庫性能的信心增強,可以逐步擴展部署范圍。在擴展過程中,要建立多級存儲機制,將熱數據存儲在高速的 SSD 中,以滿足高頻訪問的需求;將溫數據存儲在 SATA 硬盤中,平衡存儲成本和訪問速度;將冷數據存儲在對象存儲中,如 AWS S3、MinIO 等,以實現低成本的長期存儲。在能源電力行業,電網設備的近期運行數據屬于熱數據,需要快速查詢和分析,可存儲在 SSD 中;而過去幾年的歷史數據訪問頻率較低,可存儲在對象存儲中。
規劃備份恢復策略也是部署策略的重要組成部分。可以采用跨機房備份的方式,將數據備份到不同地理位置的機房,以防止因自然災害、火災等不可抗力因素導致的數據丟失。設置 TTL(Time-To-Live)自動轉存機制,根據數據的重要性和使用頻率,自動將過期的數據轉存到低成本的存儲介質中,同時刪除原始數據,以節省存儲空間和管理成本。
7.4 長期演進考慮
在選擇時序數據庫時,不僅要考慮當前的業務需求,還要關注長期演進的可能性。隨著業務的發展,時序數據分析需求可能會不斷變化和深化。在工業物聯網領域,最初可能只需要對設備的運行狀態進行簡單的監控和報警,而隨著數字化轉型的推進,可能需要進行更深入的數據分析,如設備故障預測、生產效率優化等。因此,選擇的時序數據庫應具備良好的擴展性和靈活性,能夠支持未來可能出現的復雜數據分析需求。
預留 AI 集成能力也十分重要。人工智能技術在數據分析和預測方面具有強大的能力,未來許多業務場景都可能會引入 AI 技術。在智能電網中,通過將 AI 技術與時序數據庫相結合,可以實現對電力負荷的精準預測,優化電力調度。因此,選擇的時序數據庫應能夠方便地與 AI 框架進行集成,如 TensorFlow、PyTorch 等,為未來的 AI 應用提供支持。
考慮多云部署可能性也是長期演進的重要因素。隨著云計算技術的發展,多云部署逐漸成為一種趨勢。多云部署可以提高系統的可用性和靈活性,降低對單一云服務提供商的依賴。在選擇時序數據庫時,應考慮其是否支持多云部署,以及在多云環境下的性能和兼容性。一些時序數據庫提供了云原生的解決方案,能夠輕松地在不同的云平臺上進行部署和管理,滿足企業對多云部署的需求。
八、總結與展望
8.1 IoTDB 的價值總結
在時序數據庫的選型中,IoTDB 展現出了多方面的獨特價值。其強大的性能表現,無論是高并發寫入、高效壓縮還是快速查詢,都能滿足各類復雜業務場景的需求。靈活的數據模型與工業物聯網中設備的層級管理體系完美契合,使得數據的組織和查詢更加直觀高效。端邊云協同架構充分考慮了物聯網場景中數據處理的多樣性和復雜性,實現了數據的高效流轉和處理。豐富的生態集成能力讓 IoTDB 能夠與多種大數據處理框架、可視化工具以及工業協議無縫對接,拓展了其應用邊界。作為 Apache 頂級項目,IoTDB 的開源性質和活躍的社區支持,為用戶提供了自由定制和持續優化的空間。
8.2 未來發展趨勢展望
展望未來,時序數據庫將朝著更加智能化、高效化和專業化的方向發展。隨著物聯網、工業互聯網等技術的不斷普及,數據量將持續爆發式增長,對時序數據庫的性能和擴展性提出了更高的要求。人工智能與時序數據庫的融合也將成為重要趨勢,通過 AI 技術實現數據的智能分析、預測和決策,將為各行業帶來更大的價值。在這樣的發展趨勢下,IoTDB 憑借其強大的技術實力和不斷創新的精神,有望在未來的時序數據庫市場中占據重要地位。IoTDB 將繼續優化其性能,提升數據處理能力,拓展生態集成,加強與 AI 技術的融合,為用戶提供更加全面、高效的時序數據管理解決方案。
8.3 行動呼吁
如果你的業務涉及海量時序數據的處理,無論是工業物聯網、智能電網、車聯網還是智慧城市等領域,IoTDB 都值得你嘗試。你可以通過下載鏈接:發行版本 | IoTDB Website 獲取 IoTDB,體驗其強大的功能。如果你有企業級的需求,也可以訪問企業版官網鏈接:Apache IoTDB_國產開源時序數據庫_時序數據管理服務商-天謀科技Timecho ,了解更多企業版的優勢和服務。相信 IoTDB 會成為你時序數據管理的得力助手,助力你的業務發展。
?8.4 IoTDB官網、下載、開源地址
Apache IoTDB_國產開源時序數據庫_時序數據管理服務商-天謀科技Timecho天謀科技Timecho提供行業領先的物聯網時序數據庫管理系統及服務,是專業的時序數據管理服務商,致力于圍繞物聯網原生的Apache IoTDB,以高吞吐,高壓縮,高可用的開源時序數據庫-國產數據庫IoTDB,為工業用戶解決數據"存,查,用"難題![]() https://timecho.com/發行版本 | IoTDB Website發行版本 歷史版本下載:https://archive.apache.org/dist/iotdb/ 環境配置 推薦修改的操作系統參數 將 somaxconn 設置為 65535 以避免系統在高負載時出現
https://timecho.com/發行版本 | IoTDB Website發行版本 歷史版本下載:https://archive.apache.org/dist/iotdb/ 環境配置 推薦修改的操作系統參數 將 somaxconn 設置為 65535 以避免系統在高負載時出現 ![]() https://iotdb.apache.org/zh/Download/
https://iotdb.apache.org/zh/Download/
官方開源地址![]() https://github.com/apache/iotdb
https://github.com/apache/iotdb
:雨騎古蓮村游記)

TCP擁塞控制與擁塞控制算法深度剖析)
)



![礦物分類系統開發筆記(二):模型訓練[刪除空缺行]](http://pic.xiahunao.cn/礦物分類系統開發筆記(二):模型訓練[刪除空缺行])









)
-CPU單核高速數據處理)
任務調度)