小亦平臺會持續給大家科普一些運維過程中常見的問題解決案例,運維朋友們可以在常見問題及解決方案專欄查看更多案例
問題概述:
- 故障:?pg數據庫備節點狀態異常
- 現象:?一般為集群間心跳超時導致,現象為集群有fail-count失敗數告警,備節點狀態為stop或alone。
問題分析:
- 直接原因:?集群間心跳超時。
- 故障表現:
- 集群有fail-count失敗數告警。
- 備節點狀態為stop或alone。
解決方案:
1. 用root用戶登錄數據庫集群任一節點;
2. 檢查集群狀態:?cls_status;
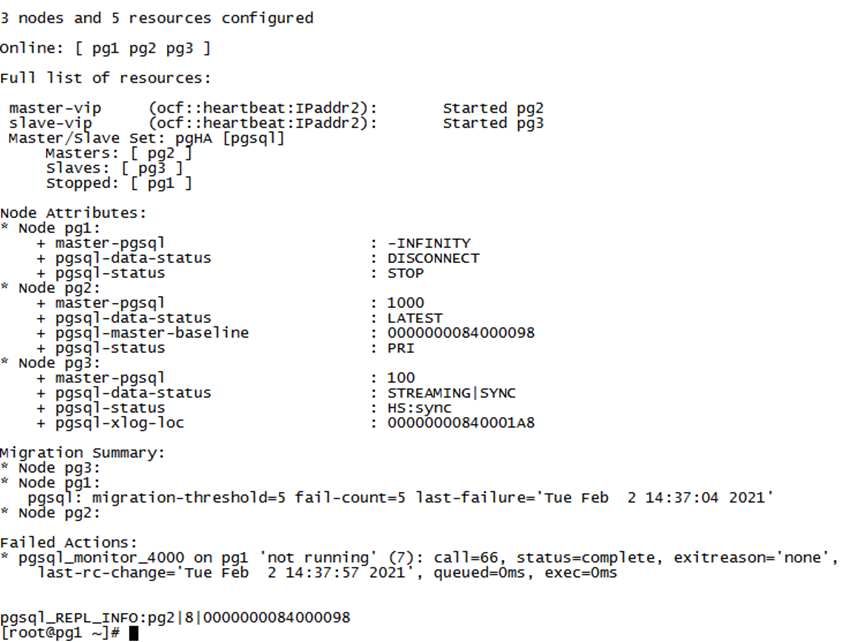
3.一般情況下會有fail-count告警,可以嘗試通過resource cleanup 恢復異常節點的集群狀態:
pcs resource cleanup pgsql --node 節點名;
4. 如果異常節點集群狀態未恢復,可能為集群主備發生切換,需要清理異常節點的鎖文件,可? 以嘗試刪除鎖文件后再執行第3步的命令:
rm -f /var/lib/pgsql/tmp/PGSQL.lock;
pcs resource cleanup pgsql --node 節點名;
5. 如果還是不成功,則可能是數據庫的baseline發生變化,或主節點的wal日志文件以及歸檔,備節點啟動時無法找到文件,可以查看數據庫日志分析具體原因,
數據庫日志目錄:
pg10.5:/pgdb/pgdata/log
pg11.6:/pglog
則需要重構異常備節點:
rm -rf /pgdb/pgdata
cls_rebuild_slave
立即查看更多postgresql的相關內容
運維工作中遇到難題?立即提交工單。小亦平臺工程師火速響應,助您快速修復故障!


--反射率通過率計算復雜度優化25/8/17)










)
 除了傅里葉變換和離散余弦變換)




