閱讀 WiscKey 論文時隨手記錄一些筆記。
這篇論文的核心思想理解起來還是很簡單的,但是具體涉及到實現還有一些想不明白的地方,后來看到 TiKV 的 Titan 實現也很有趣,索性把這些問題都記錄下來并拋出來。
本文中和論文相關的內容,斜體均為我個人的主觀想法,關于 Titan 的實現,我只看過幾篇公開文章以及粗淺的掃過一遍代碼,如果這兩部分的內容有理解錯誤歡迎指出,感謝!
背景
基于 LSM 樹(Log-Structured Merge-Trees)的鍵值存儲已經廣泛應用,其特點是保持了數據的順序寫入和存儲,利用磁盤的順序 IO 得到了很高的性能(在 HDD 上尤其顯著)。但是同一份數據會在生命周期中寫入多次,隨之帶來高額的寫放大。
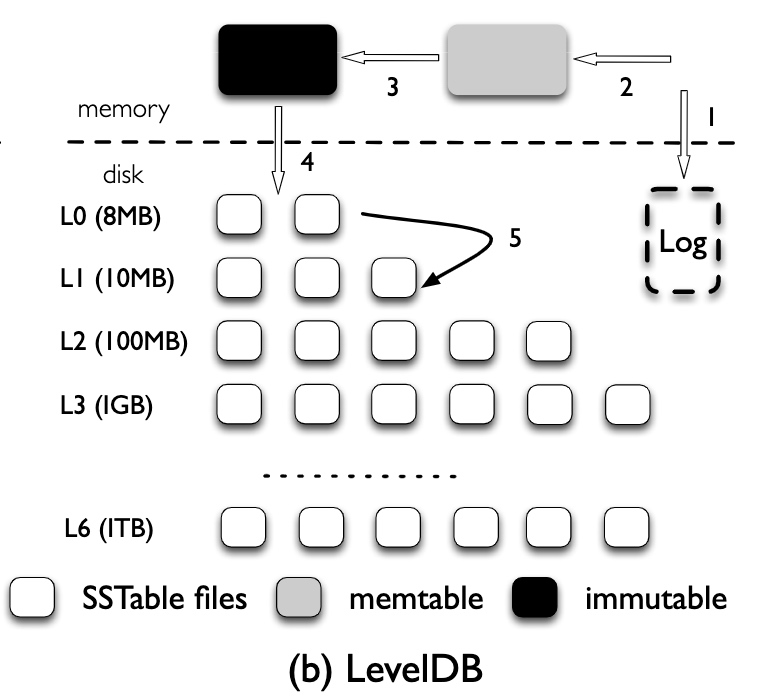
以 LevelDB 為例,數據寫入的整個流程為:
- 數據首先會被寫入 memtable 和 WAL
- 當 memtable 達到上限后,會轉換為 immutable memtable,之后持久化到 L0(稱為 flush),L0 中每個文件都是一個持久化的 immutable memtable,多個文件間可以有相互重疊的 Key
- 當 L0 中的文件達到一定數量時,便會和 L1 中的文件進行合并(稱為 compaction)
- 自 L1 開始所有文件都不會再有相互重疊的 Key,并且每個文件都會按照 Key 的順序存儲。每一層通常是上一層大小的 10 倍,當一層的大小超過限制時,就會挑選一部分文件合并到下一層
由此可以計算出 LevelDB 的寫放大比率:
- 由于每一層是上一層大小的 10 倍,所以在最壞情況下,上一層的一個文件可能需要和下一層的十個文件進行合并,所以合并的寫放大是 10
- 假設每行數據經過一系列 compaction 最終都會落入最終層,每層都需要重新寫一次,那么從 L1 到 L6 的寫放大為 5
- 加上 WAL 和 L0,最終寫放大可能會超過 50
另一方面,由于數據在 LevelDB 中的每一層(memtable/L0/L1~L6)都有可能存在,所以對于讀請求,也會有一定的讀放大:
- 由于 L0 的多個文件允許有數據重疊,所以最壞情況需要查詢所有文件
- 對于 L1 到 L6,因為數據有序且不重疊,所以每層需要查詢一個文件
- 為了確認 Key 是否存在,對于每個文件都需要讀取 index block、bloom-filter blocks 和 data block
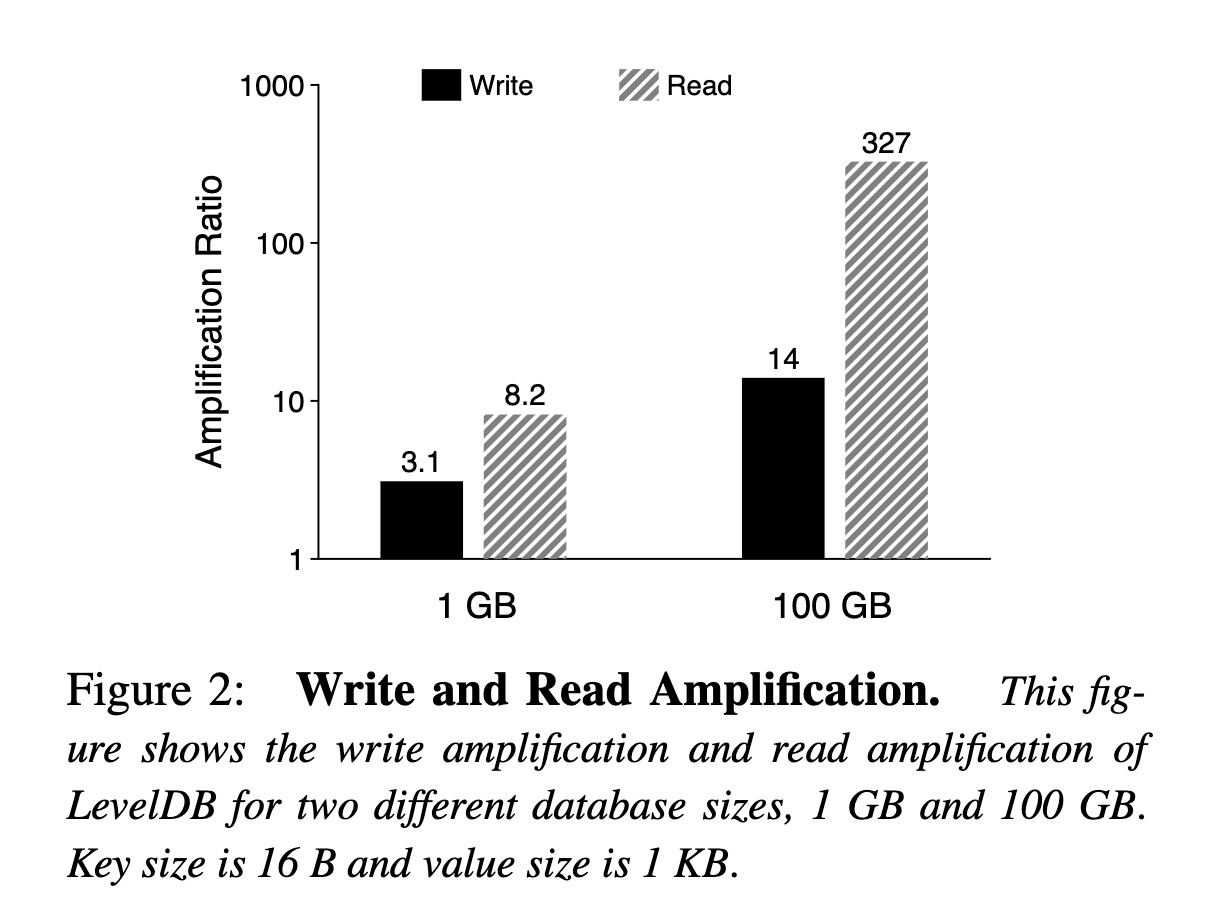
論文中提供了一個實際的數據:
WiscKey 介紹
設計目標
WiscKey 的核心思想是將數據中的 Key 和 Value 分離,只在 LSM-Tree 中有序存儲 Key,而將 Value 存放在單獨的 Log 中。這樣帶來了兩點好處:
- 當 LSM-Tree 進行 compaction 時,只會對 Key 進行排序和重寫,不會影響到沒有改變的 Value,也就顯著降低了寫放大
- 將 Value 分離后,LSM-Tree 本身會大幅減小,所以對應磁盤中的層級會更少,可以減少查詢時從磁盤讀取的次數,并且可以更好的利用緩存的效果
另外,WiscKey 的設計很大一部分還建立在 SSD 的普及上,相比 HDD,SSD 有一些變化:
- SSD 的隨機 IO 和順序 IO 的性能差距并不像 HDD 那么大,所以 LSM-Tree 為了避免隨機 IO 而采用了大量的順序 IO,反而可能會造成了帶寬浪費
- SSD 擁有內部并行性,但 LSM-Tree 并沒有利用到該特性
- SSD 會因為大量的重復寫入而產生硬件損耗,LSM-Tree 的高寫入放大率會降低設備的壽命
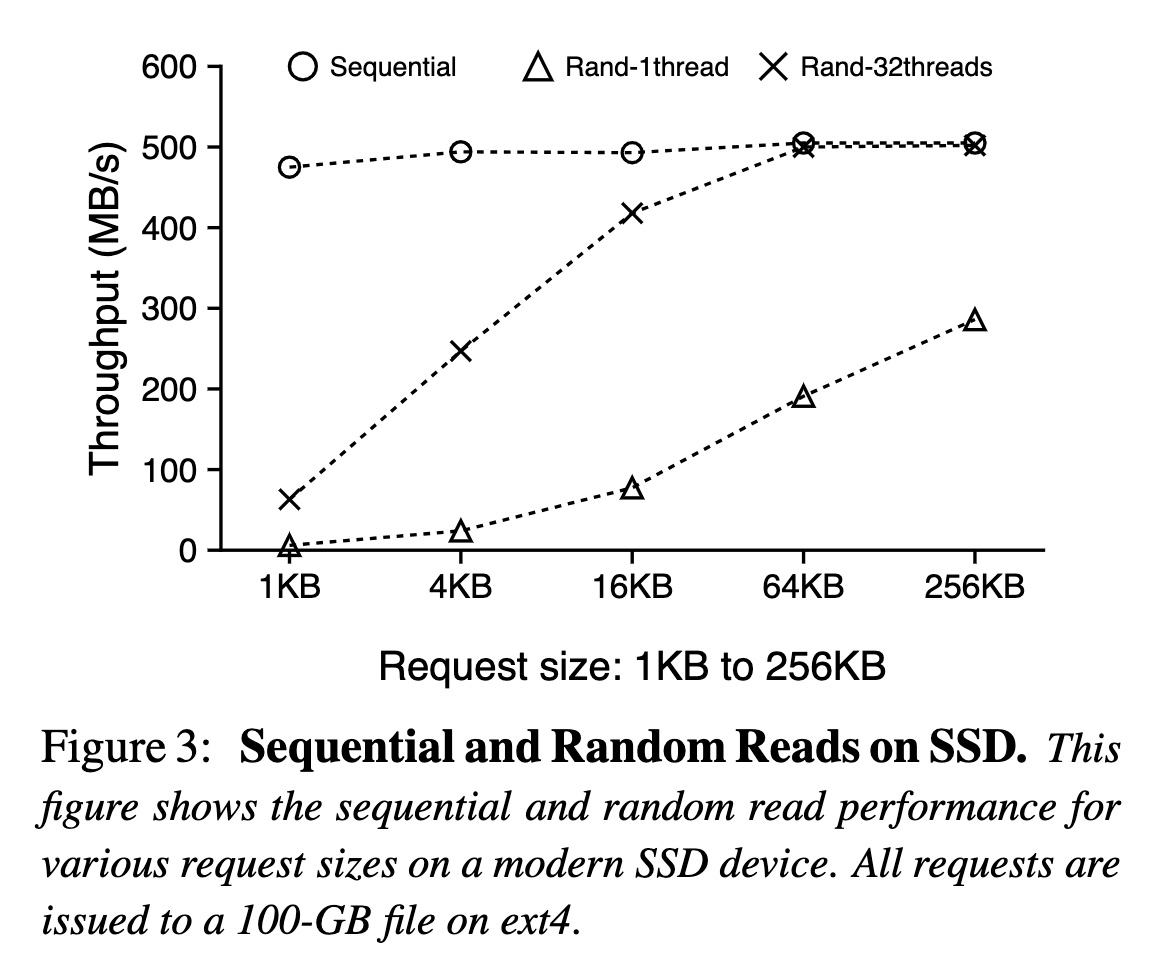
下圖展示了在不同請求大小和并發度時,隨機讀和順序讀的吞吐量,可以看到在請求大于 16KB 時,32 線程的隨機讀已經接近了順序讀的吞吐:
實現
在 LSM-Tree 的基礎上,WiscKey 引入了一個額外的存儲用于存儲分離出的值,稱為 Value Log。整體的讀寫路徑為:
- 當用戶添加一個 KV 時,WiscKey 會先將 Value 寫入到 Value-Log 中(順序寫),然后將 Key 和 Value 在 Value Log 中的地址寫入 LSM-Tree
- 當用戶刪除一個 Key 時,僅在 LSM-Tree 中刪除 Key 的記錄,之后通過 GC 清理掉 Value Log 中的數據
- 當用戶查詢一個 Key 時,會先從 LSM-Tree 中查詢到 Value 的地址,再根據地址將 Value 真正從 Value-Log 中讀取出來(隨機讀)
假設 Key 的大小為 16 Bytes,Value 的大小為 1KB,優化后的效果為:
- 如果在 LSM-Tree 中的單層的寫放大率是 10,那么使用 WiscKey 后單層的寫放大率將變為 ((16 x 10) + (1024 x 1)) / (16 + 1024) = 1.14,遠小于之前的 10 倍
- 如果一個標準的 LSM-Tree 的大小為 100G,那么將 Value 分離后 LSM-Tree 本身的大小將會減少到 2G,層級會減少 1~2 級,并且緩存到內存中的比例會更高,從而降低讀放大
看上去實現很簡單,效果也很好,但是背后也存在了一些挑戰和優化。
挑戰一:范圍查詢
在標準的 LSM-Tree 中,由于 Key 和 Value 是按照順序存儲在一起的,所以范圍查詢只需要順序讀即可遍歷整個 SSTable 的所有數據。但是在 WiscKey 中,每個 Key 都需要額外的一次隨機讀才能讀取到對應的 Value,因此效率會很差。
論文中的解決方案是利用上文中所提到的 SSD 內部的并行能力。WiscKey 內部會有一個 32 線程的線程池,當用戶使用迭代器迭代一行時,迭代器會預先取出多個 Key,并放入到一個隊列中,線程池會從隊列中讀取 Key 并行的查找對應的 Value。
疑問:
- 預取在某些場景是否會有浪費?(用戶不準備迭代完所有數據的場景,例如 Limit 或是 Filter)
- 為什么用線程池 + 隊列,而不是直接用異步 IO?
挑戰二:垃圾收集(GC)
上文中提到了,當用戶刪除一個 Key 時,WiscKey 只會將 LSM-Tree 中的 Key 刪除掉,所以需要一個額外的方式清理 Value-Log 中的值。
最簡單的方法是定期掃描整個 LSM-Tree,獲得所有還有引用的 Value 地址,然后將沒有引用的 Value 刪除,但是這個邏輯非常重。

論文中介紹的方式是通過維護一個 Value Log 的有效區間(由 head 和 tail 兩個地址組成),通過不斷地搬運有效數據來達到淘汰無效數據。整個流程為:
- 對于 Value-Log 中的每個值,需要額外存儲 Key,為了方便從 LSM-Tree 中進行反查(相對 Value,Key 會比較小,所以寫入放大不會增加太多)
- 從 tail 的位置讀取 KV,通過 Key 在 LSM-Tree 中查詢 Value 是否還在被引用
- 如果 Value 還在被引用,則將 Value 寫入到 head,并將新的 Value 地址寫回 LSM-Tree 中
- 如果 Value 已經沒有被引用,則跳過這行數據,接著讀取下一個 KV
- 當已經確認數據寫入 head 之后,就可以將 tail 之后的數據都刪除掉了
因為需要重新寫入一次 Value,并且需要將 Key 回填到 LSM-Tree 中,所以這個 GC 策略會造成額外的寫放大。并且即使不做 GC,也只會影響到空間放大(刪除的數據沒有真正清理),所以感覺可以配置一些策略:
- 根據磁盤負載和 LSM-Tree 的負載計算,僅在低峰期執行
- 計算每一段數據中被刪除的比例有多少,當空洞變得比較大的時候才觸發 GC
挑戰三:崩潰一致性
當系統崩潰時,LSM-Tree 可以保證數據寫入的原子性和恢復的有序性,所以 WiscKey 也需要保證這兩點。
WiscKey 通過查詢時的容錯機制保證 Key 和 Value 的原子性:
- 當用戶查詢時,如果在 LSM-Tree 中找不到 Key,則返回 Key 不存在
- 如果在 LSM-Tree 中可以找到 Key,但是通過地址在 Value-Log 中無法找到匹配的 Value,則說明 Value 在寫入時丟失了,同樣返回不存在
這個前提建立在于 WiscKey 通過一個 Write Buffer 批量提交 Value Log(下面有詳細介紹),所以才會出現 Key 寫入成功后 Value 丟失的場景,用戶也可以通過設置同步寫入,這樣在刷新 Value Log 之后,才會將 Key 寫入 LSM-Tree 中。
另外,WiscKey 通過現代的文件系統的特性保證了寫入的有序性,即寫入一個字節序列 b1, b2, b3…bn,如果 b3 在寫入時丟失了,那么 b3 之后的所有值也一定會丟失。
優化一:Write Buffer
為了提高寫入效率,WiscKey 首先會將 Value 寫入到 Write Buffer 中,等待 Write Buffer 達到一定大小再一起刷新到文件中。所以查詢時首先也要先從 WriteBuffer 中查詢。當崩潰時,Write Buffer 中的數據會丟失,此時的行為就是上文中的崩潰一致性。
疑問:
- 根據這個描述,Value-Log 似乎是異步寫入?結合上文中崩潰一致性的介紹,會有給用戶返回成功但是數據丟失的情況?
優化二:WAL 優化
LSM-Tree 通過 WAL 保證了在系統崩潰時 memtable 中的數據可恢復,但是也帶來了額外的一倍寫放大。
而在 WiscKey 中,Value-Log 和 WAL 都是基于用戶的寫入順序進行存儲的,并且也具備了恢復數據的所有內容(前提是基于上文中的 GC 實現,Value Log 里存有 Key),所以理論上 Value-Log 是可以同時作為 WAL 的,從而減少 WAL 的寫放大。
由于 Value Log 的 GC 比 WAL 更加低頻,并且包含了大量已經持久化的數據,直接通過 Value-Log 進行恢復的話可能會導致回放大量已經持久化到 SST 的數據。所以 WiscKey 會定期將已經持久化到 SST 的 head 寫入到 LSM-Tree 中,這樣當恢復時只需要從最新持久化的 head 開始恢復即可。
疑問:
- Delete 操作只需要寫 LSM-Tree,但如果需要 Value Log 作為 WAL,則 Delete 也需要寫入到 Value Log 中
- 如果不應用這個優化,則可以做到只將大 Value 分離出 LSM-Tree,應用此優化后,小 Value 也必須要額外存到 Value Log 中了
- 與其說是用 Value Log 替代 WAL,不如說是讓 WAL 支持讀 Value…
效果
說完實現再看看效果,論文中有 db_bench 和 YCSB 的數據,為了節約篇幅,只貼一部分 db_bench 的數據。
db_bench 的場景分兩種,一種是所有 Key 按順序寫入(這樣寫放大會更低,數據在每一層會更緊湊),另一種是隨機寫入(寫放大更高,數據在每一層分布更均勻)。
順序寫入
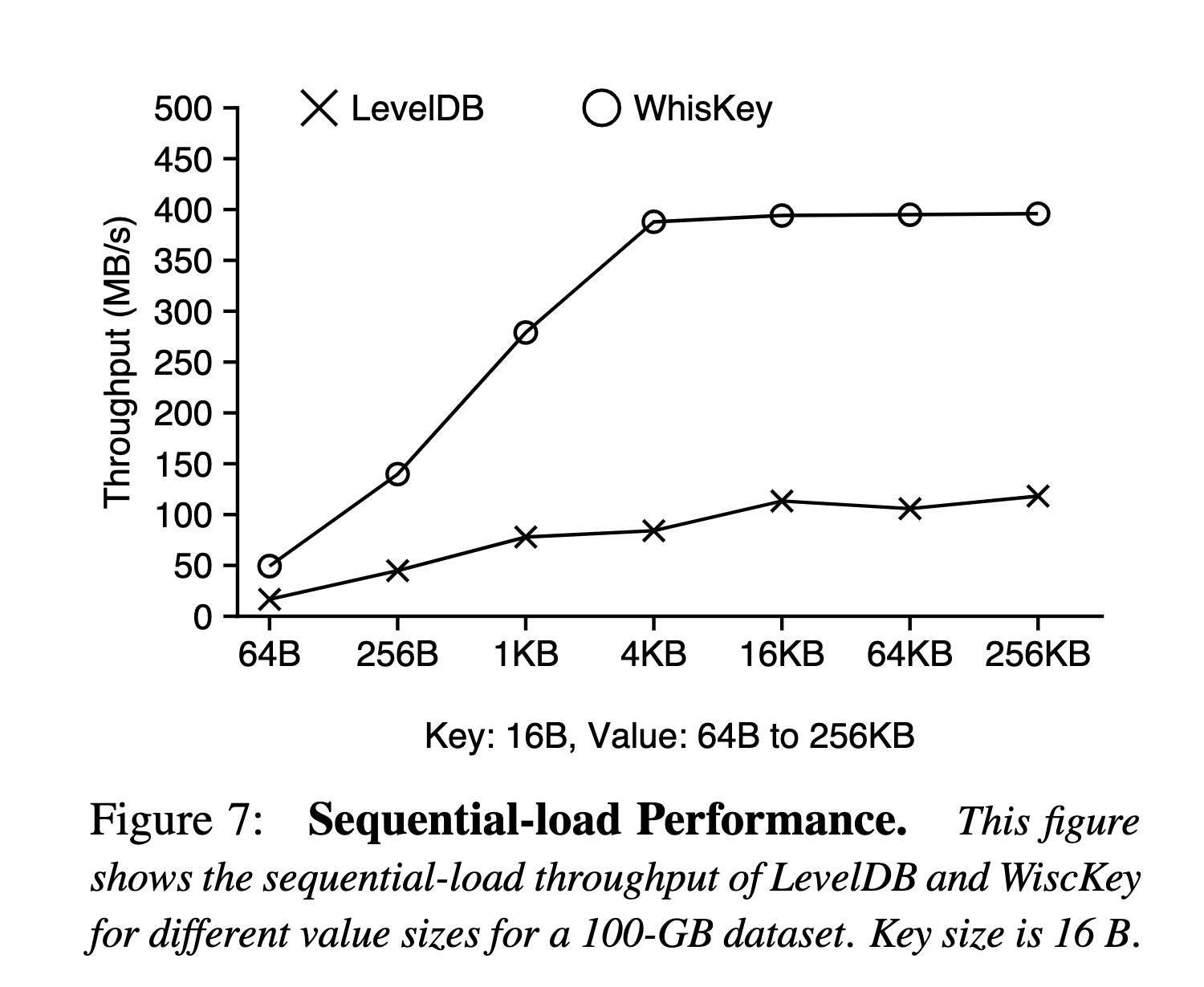
效果應該來自兩部分:
- WAL 沒了直接省了一倍寫放大
- 順序寫入,每一層合并可以認為沒有寫放大,但是數據依舊要在每一層寫一次,100 G 可能是 4~5 次(對應 L5 的大小)
隨機寫入
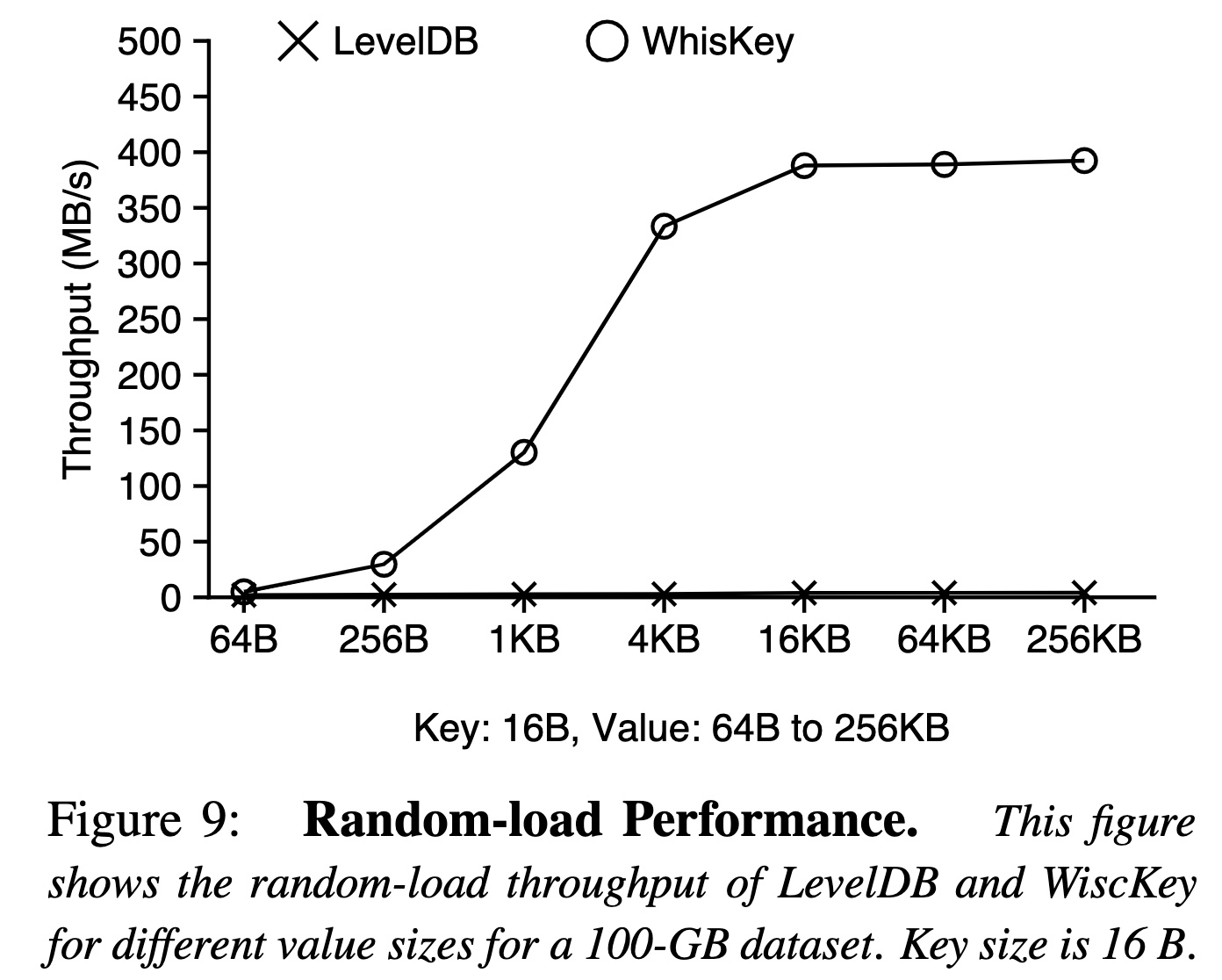
效果對比順序寫入,如果說為什么差距會這么大,只有可能是每一層合并造成的寫放大了。
點查
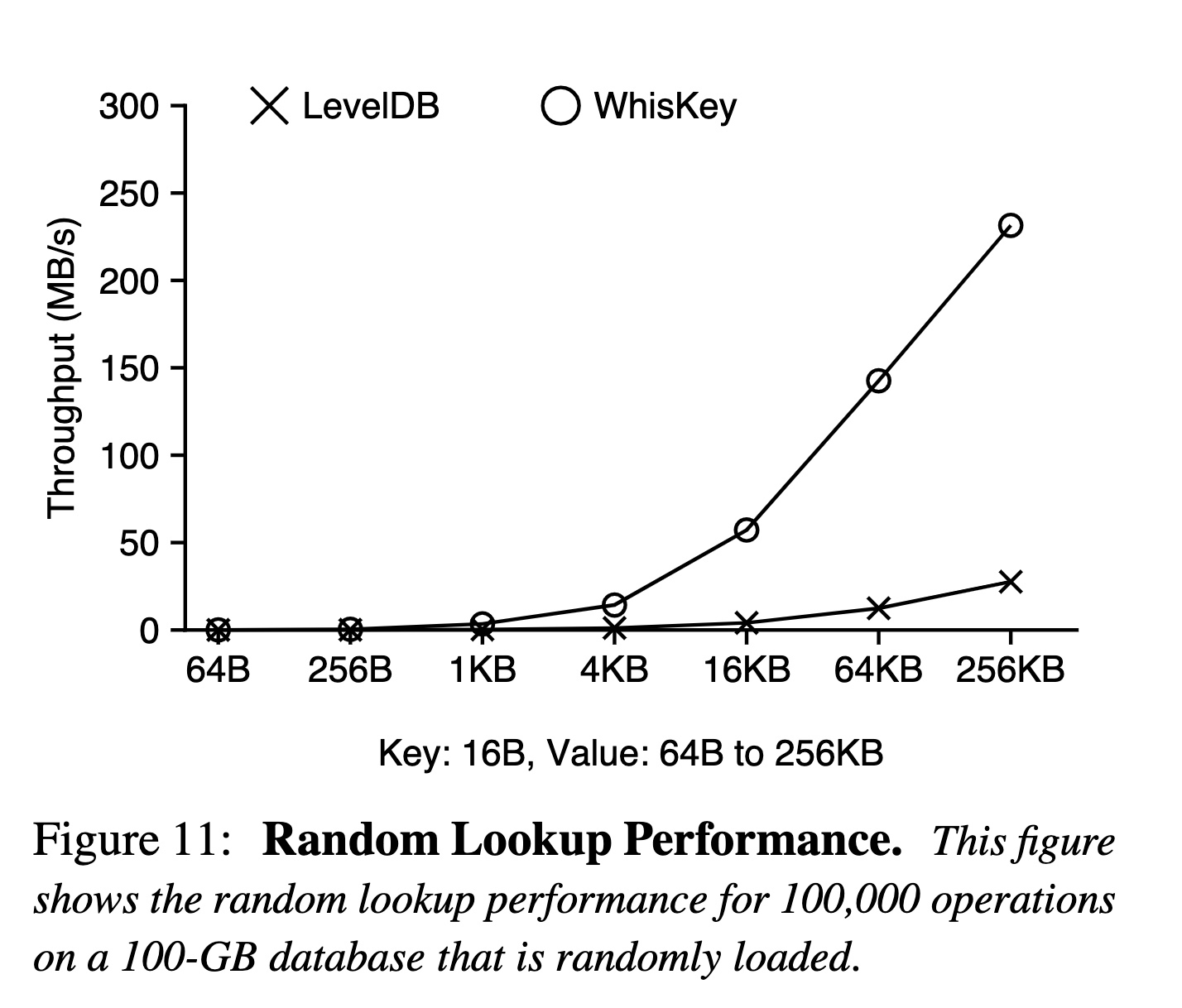
- 當 Value 比較小時,WiscKey 的劣勢在于額外的一次隨機讀,而 LevelDB 的劣勢在于讀放大。當 Value 變得更大時,基于 SSD 內部的并行能力,隨機讀依舊能讀滿帶寬,但是 LevelDB 讀放大造成的帶寬浪費卻沒有改善。
- 另外這個測試場景是數據庫大小為 100G,對于 LevelDB 來說,層級和 KV 大小掛鉤,對于 WiscKey 來說,層級和 Key 大小掛鉤,所以當 Value 越大,WiscKey 中的 LSM-Tree 反而更小,層級也就更低,甚至可能僅在內存中 (例如 Value 為 256KB 時,Key 加起來才 100G / (16 + 256?1024)?16 ~= 610KB)
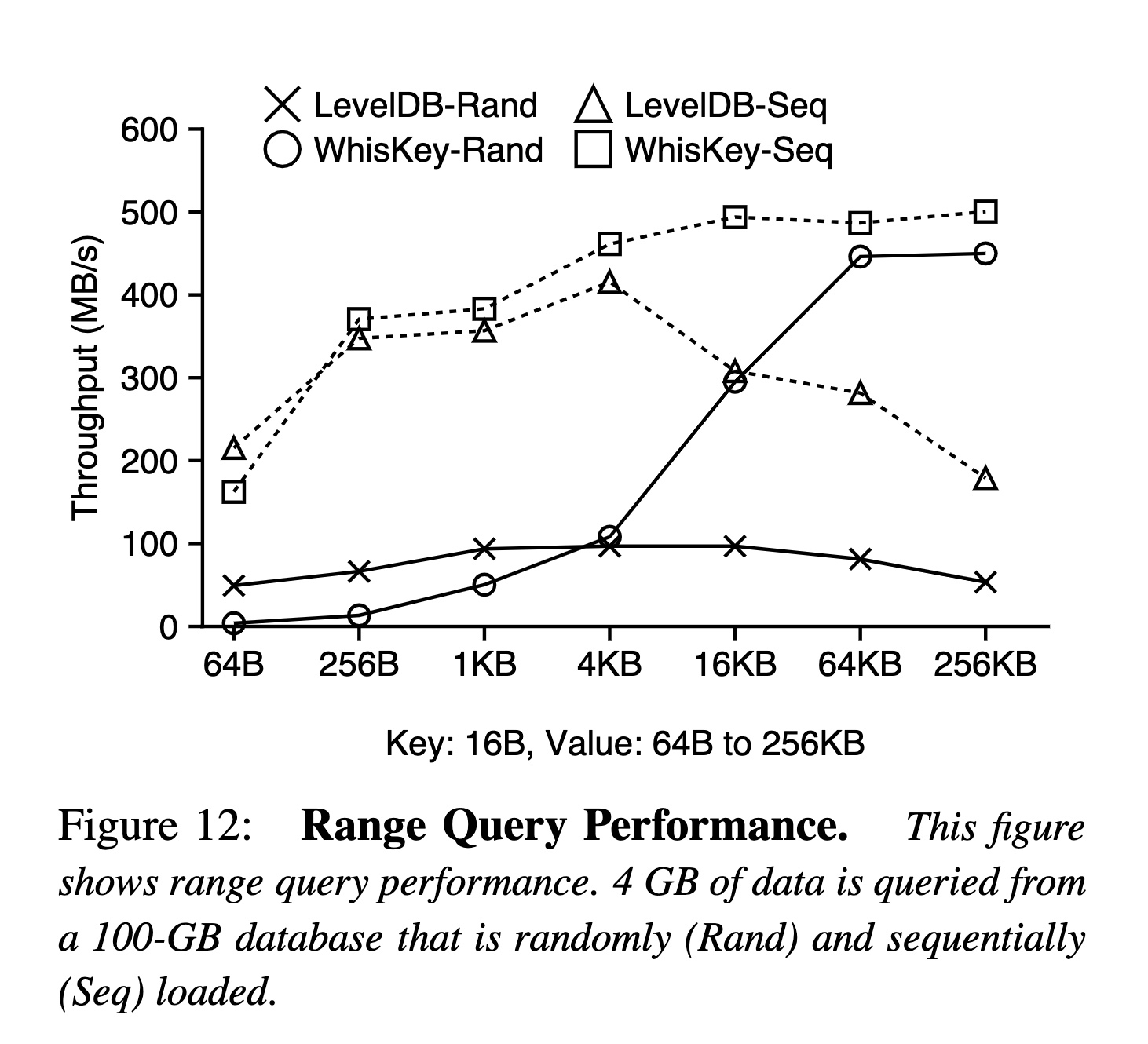
這個有點看不懂…:
- 在數據集是順序寫的場景下,LevelDB 的性能隨著 Value 的增大反而降低了,這個不太理解原因(理論上讀放大不會很大,而且是順序讀,很容易就能讀滿帶寬),WiscKey 因為是隨機讀,并且有上文中提到的 LSM-Tree 本身很小,隨著 Value 變大性能越高是符合預期的
- 在數據集是隨機寫的場景下,一開始 WiscKey 性能低是因為隨機讀的延遲,隨著 Value 增大,優勢應該和點查類似
GC
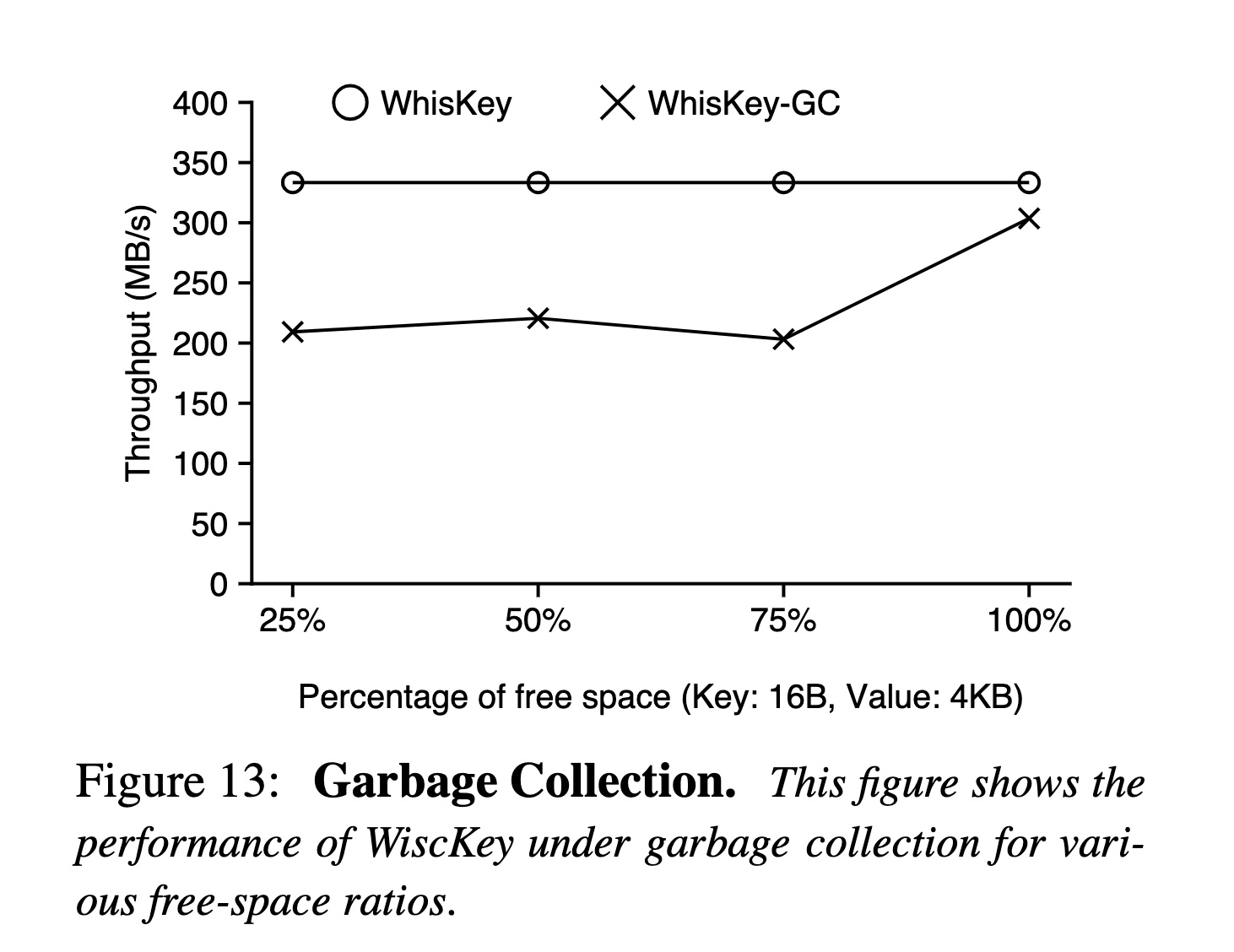
上文提到了 GC 會重寫 Value 以及寫回 LSM-Tree,造成額外的寫入。當空余空間的占比越高時(大部分數據都已經被刪了),回寫的數據越少,對性能的影響也就越小。
Titan 的實現
BlobDB 和 Badger 的實現都和論文比較接近,并且也都是玩具。反而 TiKV 的 Titan 有一些獨特的設計可以學習和討論,所以下面只介紹這一案例。
核心實現
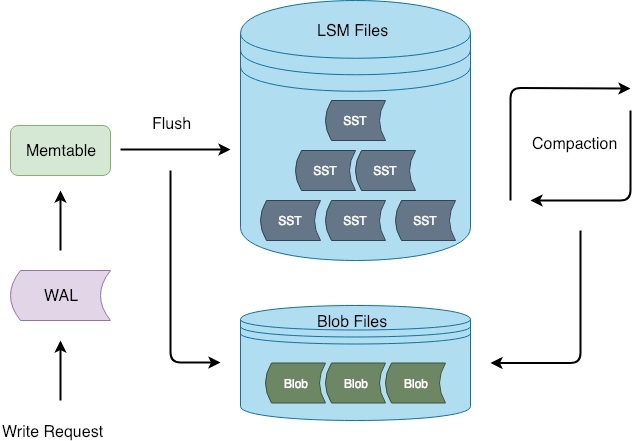
和 WiscKey 的主要區別在于:Titan 在 flush/compaction 時才開始分離鍵值,并且用于存儲分離后 Value 的文件(BlobFile)會按照 Key 的順序存儲,而不是寫入的順序(其實在這個階段,已經沒有寫入順序了)。
因此導致實現上的差異有:
- 范圍查詢:由于 Value-Log 沒有按照 Key 排序,所以 WiscKey 需要將一個范圍查詢拆解為多個隨機讀。而 Titan 保證了局部有序,在單個 BlobFile 內部可以順序讀,但是會有多個 BlobFile 的范圍有重疊,需要額外做歸并。另外對于預取策略,WiscKey 建立在 SSD 并行的優勢上,可以靠增加并發預取增加吞吐,而 Titan 暫時沒有如此激進的預取策略
- WAL 優化:在 WiscKey 的實現中通過 Value Log 替代 WAL 減少了一倍寫放大,而 Titan 在 flush/compaction 時才進行鍵值分離,肯定是沒辦法做這個優化的,不過這一點在 Titan 的設計文檔里也提到了:「假設 LSM-tree 的 max level 是 5,放大因子為 10,則 LSM-tree 總的寫放大大概為 1 + 1 + 10 + 10 + 10 + 10,其中 Flush 的寫放大是 1,其比值是 42 : 1,因此 Flush 的寫放大相比于整個 LSM-tree 的寫放大可以忽略不計。」,個人覺得還是還比較信服的
- GC 策略:Titan 目前有兩個版本的 GC 策略,會在下面詳細介紹
GC 策略
第一種策略(傳統 GC):
- 首先挑選一些需要合并的 BlobFile,在 flush/compaction 時可以統計出每個 BlobFile 中已經刪除的數據大小,從而挑選出空洞較大的文件
- 迭代這些 BlobFile,通過 Key 查詢 LSM-Tree,判斷 Value 是否還在被引用
- 如果 Value 還在被引用就寫到新的 BlobFile 中,并把更新后的地址回填到 LSM-Tree 中
這個實現和論文中的 GC 方案類似,只不過論文為了 WAL 需要寫入一條完整的 Value Log,所以需要維護 head 和 tail。Titan 的實現只需要每次都生成新的 BlobFile 即可。
不同點在于:WiscKey 是隨機讀,Value Log 的大小不會影響到讀 Value 的成本。GC 策略在于寫放大和空間放大的權衡,所以 GC 可以更加低頻。而 BlobFile 是順序讀,如果 BlobFile 中的無效數據太多,會影響到預取的效率,間接也會影響到讀的性能。
第二種策略(Level-Merge):
- 不存在單獨的 GC,由 LSM-Tree 的 compaction 觸發
- compaction 時,如果遍歷到的值已經是一個 BlobIndex(代表值已經寫入了某個 BlobFile),依舊將其讀出來重新寫入新的 BlobFile,也就是說每次 compaction 都會生成一批與新的 SST 完全對應的 BlobFile
- 目前 Level Merge 只在最后兩層開啟
開啟 Level Merge 后相當于 GC 頻率和 compaction 頻率持平了(GC 頻率最多也只能和 compaction 持平),并且在這個基礎上,直接在 compaction 里做 GC,可以減少一次回寫 LSM-Tree 的成本(因為在 compaction 的過程中就能將老的 Value 地址替換掉)。
這種策略的優點在于 BlobFile 中不再有無效數據,可以用更加激進的預取策略提高范圍查詢的性能,缺點是寫放大肯定會比之前更大(個人覺得開啟后,寫放大就和標準 LSM-Tree 完全一樣了吧(一次 compaction 需要合并的 Key 和 Value 都需要重寫一遍)?),所以只在最后兩層開啟。
效果
Titan 的性能測試結果摘自官網的文章,大部分結論都和 WiscKey 類似,并且文章中也分析了原因,就不在此贅述了。
因為文章是 19 年初的,所以還沒有上文中的 Level Merge GC,不過 GC 策略理論上只影響范圍查詢的性能,所以在此貼一下范圍查詢的性能:
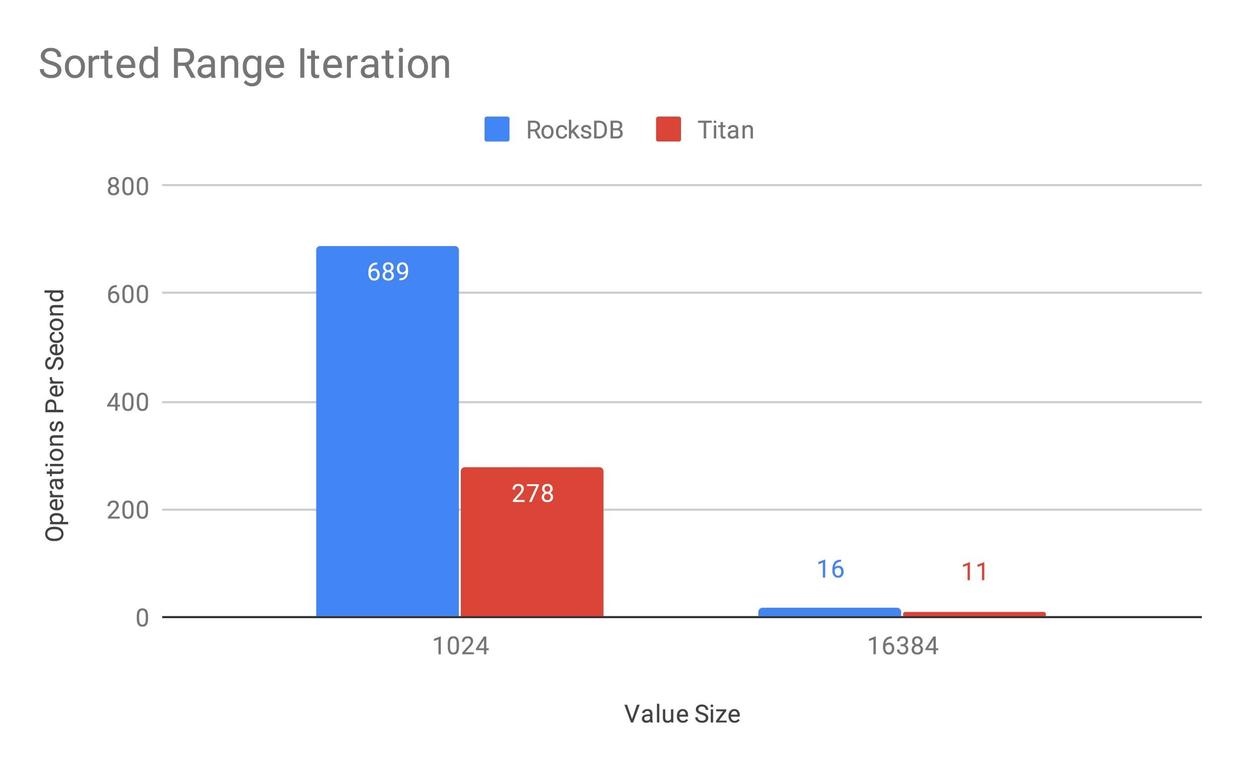
在實現 Level Merge GC 的策略之前,Titan 的范圍查詢只有 RocksDB 的 40%,主要原因應該還是分離后需要額外讀一次 Value,以及沒辦法并行預取增加吞吐。 這點文章最后也提到了:
我們通過測試發現,目前使用 Titan 做范圍查詢時 IO Util 很低,這也是為什么其性能會比 RocksDB 差的重要原因之一。因此我們認為 Titan 的 Iterator 還存在著巨大的優化空間,最簡單的方法是可以通過更加激進的 prefetch 和并行 prefetch 等手段來達到提升 Iterator 性能的目的。
另外在?TiDB in Action?也提到了 Level Merge GC 可以「大幅提升 Titan 的范圍查詢性能」,不知道除了完全去掉無效數據之外,是否還有其他的優化,還需要再看下代碼。
感受
個人認為 WiscKey 的核心思想還是比較有意義的,畢竟適用的場景很典型而且還比較常見:大 Value、寫多讀少、點查多范圍查詢少,只要業務場景命中一個特點,效果應該就會非常顯著了。
對于論文中的具體實現是否能套用在一個真實的工業實現中,我覺得大部分實現還是簡單有效的,但是也有一些設計個人不太喜歡,例如使用 Value Log 替代 WAL 的方案,感覺有些過于追求減少寫放大了,可能反而會引入其他問題,以及默認的 GC 策略還要寫回 LSM-Tree 也有些別扭。
在和其他同事討論內部項目的實現時,也暢想過一些其他玩法,例如只將 Value 中的一部分分離出來單獨存儲,或是一個分布式的 WAL 是否也能轉換為 Value Log,會有哪些問題。包括看到 Titan 的實現時,我也很好奇設計成 BlobFile 這種順序讀的方式是否有什么深意(畢竟論文都把利用 SSD 寫到標題里了),或者只是因為從 compaction 才開始分離鍵值最簡單的做法就是按順序存儲 KV。
總之,期待將來能有更多工業實現落地,看到更多有趣的案例。
參考資料
- WiscKey: Separating Keys from Values in SSD-conscious Storage
- https://nan01ab.github.io/2018/07/WiscKey.html
- Titan 的設計與實現
- Titan 原理介紹
![week1-[循環嵌套]畫正方形](http://pic.xiahunao.cn/week1-[循環嵌套]畫正方形)





)
-大模型推理部署(分布式推理與量化部署)-大模型評估測試(OpenCompass))






及線程(1))


)
—條件結構)
