概述
目標檢測作為計算機視覺領域的核心任務,傳統方法依賴于 YOLO 等視覺模型對預定義類別進行位置預測。然而,此類方法受限于預訓練類別體系,難以實現靈活的視覺交互。視覺語言模型(Vision-Language Models, VLMs)的問世打破了這一局限,其具備跨模態理解能力,能夠實現圖像與自然語言的雙向交互,為目標檢測領域帶來范式革新。本文系統探討基于 VLM 的目標檢測技術,重點研究 Qwen2.5-VL 模型的技術特性與應用方法。
Qwen 2.5 VL 模型架構與技術特性
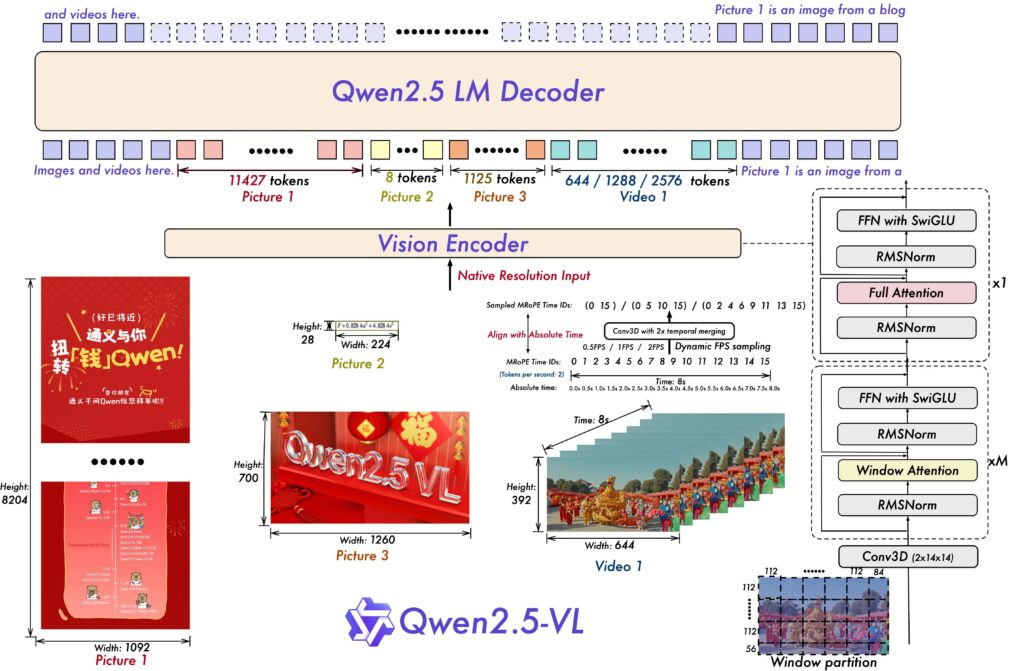
視覺語言模型作為連接視覺感知與語義理解的關鍵技術,目前已形成多樣化的模型體系。本研究聚焦 Qwen2.5-VL 模型,該模型由阿里巴巴集團 Qwen 團隊研發,作為開源模型實現了與 GPT-4o 等閉源模型相媲美的性能,為學術研究與工程應用提供了高質量的基礎模型支持。
Qwen2.5-VL 的技術優勢體現在以下方面:
-
高分辨率視覺感知能力:不同于傳統模型的固定尺寸輸入限制,該模型支持原始分辨率圖像處理,有效保留圖像細節信息,避免因強制縮放導致的特征丟失,尤其適用于精細紋理分析與小目標檢測任務。
-
精確空間定位機制:模型具備像素級坐標理解能力,能夠輸出精確的目標位置信息,為基于 VLM 的關鍵點檢測提供技術支撐,其空間感知精度顯著優于采用相對位置描述的傳統模型。
-
多模態文檔解析能力:通過大規模多樣化數據集訓練,模型能夠處理包含表格、圖表、手寫筆記及化學公式的復雜文檔,不僅實現文本識別,更能理解文檔的結構化信息。
-
時空聯合建模能力:模型采用多模態旋轉位置嵌入(MRoPE)機制,將時間維度的絕對時間戳與內部時間 ID 關聯,實現對視頻序列的動態特性理解,超越了傳統幀序感知的局限。
Qwen2.5-VL 在 4.1 萬億多樣化數據標記上的預訓練過程,使其具備從簡單圖像標注到復雜代理交互的全方位理解能力,為基于 VLM 的對象理解提供了堅實基礎。
VLM 中的目標檢測與空間理解層級
基于 VLM 的目標檢測是一套多層次的視覺理解體系,呈現為由淺入深的能力階梯。Qwen2.5-VL 模型能夠在各層級實現高效處理,體現出強大的視覺認知能力。
該層級結構可類比于偵探推理能力的進階過程:從基礎線索識別到復雜情境分析,逐步提升理解深度。
層級 1:零樣本目標檢測(基礎識別能力)
此層級對應基礎檢測能力,模型能夠基于通用類別知識識別圖像中的目標對象。該過程無需針對特定任務進行微調,體現出強大的遷移學習能力。
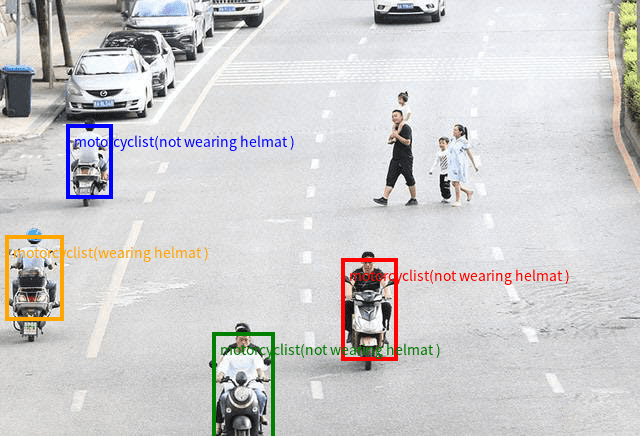
提示示例:“檢測圖像中所有摩托車手,并以坐標形式返回其位置。輸出格式應為 {“bbox_2d”: [x1, y1, x2, y2],“label”:“motorcyclist”,“sub_label”:“wearing helmat”# or"not wearing helmat”}。"
在復雜場景中,模型能夠準確識別并標記所有符合類別定義的目標對象,展現出零樣本學習的顯著優勢。這種能力使得模型無需針對每種新對象類型準備定制數據集,極大擴展了其應用范圍。
層級 2:精確視覺定位與目標計數(精細識別能力)
該層級體現模型將文本描述與視覺特征精確匹配的能力,屬于基于 VLM 的視覺定位研究范疇。模型不僅能夠識別目標,還能根據特征描述進行篩選與定位。
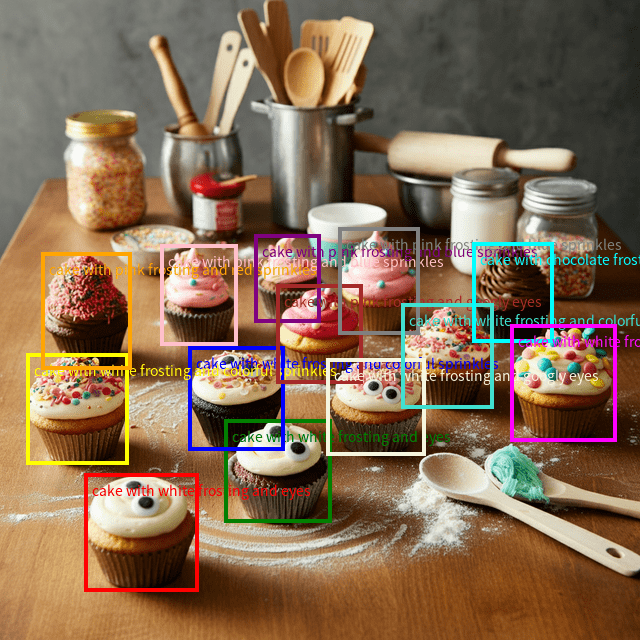
提示示例:“定位每個蛋糕并描述其特征,以 JSON 格式輸出 bbox 坐標。”
此任務要求模型超越簡單的類別識別,實現對目標特征(如 “巧克力碎”)的理解與匹配,體現了視覺 - 語言跨模態映射的精確性。
關鍵點檢測擴展
視覺定位可進一步細化至關鍵點級別,即基于 VLM 的關鍵點檢測。該任務要求模型精確定位目標的特定特征點,而非整體邊界框。

提示示例:“識別籃球運動員并檢測其手和頭部等關鍵點。”
Qwen2.5-VL 憑借其絕對坐標理解能力,能夠實現像素級精度的關鍵點定位,為體育分析、人機交互及增強現實等領域提供技術支持。
層級 3:關系理解與情境推理(高級認知能力)
該層級代表基于 VLM 的對象理解的最高水平,模型能夠分析目標間的關系與交互,實現場景級別的情境理解。

提示示例:“定位表現勇敢的人,以 JSON 格式報告 bbox 坐標。”
此類任務要求模型完成多步驟推理:
-
識別圖像中的人物目標
-
分析人物與其他對象的交互關系
-
基于常識推理理解 “勇敢” 的抽象概念
-
結合視覺證據與語義知識進行綜合判斷
該過程充分體現了 VLM 的跨模態優勢:視覺模塊負責場景感知,語言模塊提供常識推理,二者協同實現高級認知任務,為復雜場景分析與智能交互系統奠定基礎。
實驗方法與代碼實現
本節詳細闡述基于 Qwen2.5-VL 的目標檢測實驗流程,包括模型加載、推理過程與結果可視化的完整實現方案。實驗系統以圖像與文本提示作為輸入,輸出標注圖像與結構化響應,實現端到端的視覺語言交互。
代碼獲取 為便于復現實驗,本文提供完整 Python 腳本與實現細節,可通過以下方式獲取:
1. 模型與處理器加載
實驗系統的核心組件包括 Qwen2.5-VL 模型與對應的處理器,前者負責推理計算,后者處理多模態輸入的預處理與后處理。
from transformers import (AutoProcessor,Qwen2_5_VLForConditionalGeneration,
)
import supervision as sv# --- Config ---
model_qwen_id = "Qwen/Qwen2.5-VL-3B-Instruct"# Load the main model
model_qwen = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_qwen_id, torch_dtype="auto", device_map="auto"
)# Load the processor
min_pixels = 224 * 224
max_pixels = 1024 * 1024
processor_qwen = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
-
模型組件(Qwen2_5_VLForConditionalGeneration):通過 from_pretrained 方法加載 Hugging Face Hub 中的 Qwen2.5-VL-3B-Instruct 模型。參數 torch_dtype=“auto” 與 device_map=“auto” 實現自動數據類型選擇與設備分配,優化計算效率。
-
處理器組件(AutoProcessor):作為多模態輸入的處理接口,負責將原始圖像與文本轉換為模型可接受的格式。通過 min_pixels 與 max_pixels 參數設置動態分辨率范圍,充分利用 Qwen 模型的原生動態分辨率處理能力,避免固定尺寸帶來的信息損失。
2. 推理函數實現(detect_qwen)
推理函數構成實驗系統的核心邏輯,實現從輸入到輸出的完整處理流程,包括輸入格式化、預處理、模型推理、結果解碼與可視化準備等步驟。
def detect_qwen(image, prompt):# Step 1: Format the inputsmessages = [{"role": "user","content": [{"type": "image", "image": image},{"type": "text", "text": prompt},],}]# Step 2: Preprocess with the processortext = processor_qwen.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor_qwen(text=[text],images=image_inputs,# ...return_tensors="pt",).to(model_qwen.device)# Step 3: Run inferencegenerated_ids = model_qwen.generate(**inputs, max_new_tokens=1024)# Step 4: Decode the output# ... (trimming and decoding logic)output_text = processor_qwen.batch_decode(generated_ids_trimmed,# ...)[0]# Step 5: Get processed dimensions for scalinginput_height = inputs["image_grid_thw"][0][1] * 14input_width = inputs["image_grid_thw"][0][2] * 14# Step 6: Create the annotated imageannotated_image = create_annotated_image(image, output_text, input_height, input_width)return annotated_image, output_text, # ...
-
步驟 1:JSON 解析:提取模型輸出中的 JSON 數據并轉換為 Python 對象,為后續可視化提供結構化數據。
-
步驟 2:標注繪制:利用 supervision 庫的 VLM 專用接口創建檢測對象,通過注釋器在圖像上繪制邊界框與標簽,實現檢測結果的可視化呈現。
實驗系統還提供 Gradio 交互界面,便于用戶上傳圖像、輸入提示并實時查看結果:
def create_annotated_image(image, json_data, height, width):# Step 1: Parse the JSON responsetry:parsed_json_data = json_data.split("```json")[1].split("```")[0]bbox_data = json.loads(parsed_json_data)except Exception:return image # Return original image if parsing fails# Step 2: Handle both bounding boxes and keypoints using 'supervision'annotated_image = np.array(image.convert("RGB"))# For Bounding Boxesdetections = sv.Detections.from_vlm(vlm=sv.VLM.QWEN_2_5_VL,result=json_data,resolution_wh=(width, height), # Use the model's processed dimensions)bounding_box_annotator = sv.BoxAnnotator()label_annotator = sv.LabelAnnotator()annotated_image = bounding_box_annotator.annotate(scene=annotated_image, detections=detections)annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)# For Keypoints# ... (code to extract and annotate points) ...return Image.fromarray(annotated_image)
硬件要求說明:由于模型計算量較大,建議使用顯存大于 16GB 的 GPU 運行實驗,CPU 環境可運行但推理速度顯著降低。
實驗結果與分析
用例 1:特定目標視覺定位
該實驗驗證模型基于特征描述進行目標定位的能力,要求模型在復雜場景中識別符合特定顏色與位置特征的目標。

輸入圖像
- 任務:視覺定位與目標檢測
- 提示:檢測此圖像中位于組頂部的藍色糖果,并返回其位置和標簽。
結果分析:模型成功實現基于 VLM 的視覺精確定位,準確理解 “藍色” 屬性與 “頂部位置” 的空間描述,過濾無關目標并輸出單一精確的邊界框。實驗表明模型具備將復合文本描述映射至視覺特征的能力,驗證了其跨模態理解的精確性。

用例 2:關鍵點檢測精度驗證
本實驗測試模型對目標局部特征的定位能力,要求識別特定目標并標記其關鍵部位。

輸入圖像
-
任務:視覺定位與關鍵點檢測
-
提示:識別此圖像中的紅色汽車,檢測其關鍵點,并以點的形式返回其位置。
結果分析:模型展現出優異的基于 VLM 的關鍵點檢測能力,從邊界框級檢測切換至像素級特征定位,準確標記紅色汽車的關鍵部位。這一結果得益于模型對絕對坐標系的精確理解,為需要精細特征分析的應用場景提供了技術支撐。

用例 3:目標計數與邏輯推理
該實驗評估模型的數量認知與邏輯推理能力,測試其超越簡單檢測的高級認知能力。

輸入圖像
-
任務:目標計數
-
提示:數一數貓頭鷹的眼睛數量
結果輸出:
圖像顯示兩只貓頭鷹棲息在樹枝上。每只貓頭鷹有兩只眼睛,所以圖片中總共有四只眼睛。
結果分析:模型輸出體現出多步驟推理過程:首先識別貓頭鷹數量,然后調用常識知識(每只貓頭鷹有兩只眼睛),最后執行數學計算(2×2=4),最終以自然語言形式呈現結果。這一過程驗證了基于 VLM 的對象理解已超越單純的視覺感知,具備邏輯推理能力。

用例 4:抽象概念檢測與關系理解
本實驗測試模型對非物理實體(如影子)的檢測能力,評估其對對象間關系與物理現象的理解水平。

輸入圖像
-
任務:目標檢測
-
提示:定位紙狐貍的影子,以 JSON 格式報告 bbox 坐標。
結果分析:“影子” 作為物理對象的光學現象,本身不具備獨立的視覺特征,其檢測依賴于對光源方向、對象形狀與投影關系的綜合理解。實驗結果表明,Qwen2.5-VL 能夠通過多步推理定位紙狐貍的影子,驗證了模型對抽象視覺現象的理解能力,體現了基于 VLM 的對象理解在復雜場景分析中的優勢。

研究總結
本文系統研究了基于視覺語言模型的目標檢測技術,通過 Qwen2.5-VL 模型驗證了 VLM 在跨模態視覺理解中的顯著優勢。主要結論如下:
-
視覺語言模型實現圖像交互理解:基于 VLM 的目標檢測突破了傳統方法的類別限制,通過自然語言交互實現靈活的視覺查詢,支持細致入微的圖像分析需求。
-
視覺理解呈現層級結構:從基礎的零樣本目標檢測,到精確視覺定位,再到高級關系理解,視覺語言模型展現出逐步深入的視覺認知能力。
-
工具鏈支持加速技術落地:Hugging Face 的 transformers 庫與 supervision 工具包為 VLM 應用提供了便捷接口,簡化了從模型加載到結果可視化的全流程實現。
-
提示工程影響模型性能:精心設計的提示詞(包含任務描述、對象細節與輸出格式)是引導 VLM 生成高質量結果的關鍵因素,值得進一步研究優化。
結論
視覺語言模型的發展正在重塑計算機視覺的研究范式。Qwen2.5-VL 作為當前先進的開源 VLM,其高分辨率處理、精確坐標理解與跨模態推理能力,為目標檢測與空間理解提供了全新解決方案。從特定目標識別到抽象概念推理,VLM 展現出的多層次視覺理解能力,為電子商務、輔助技術、創意工具等領域開辟了新的應用前景。
未來研究可進一步探索提示工程優化、領域自適應方法及模型效率提升等方向,推動 VLM 技術在更廣泛場景中的實用化落地。
參考文獻
Qwen2.5 VL 技術博客 (Qwen 團隊)
基于 Qwen 2.5 的目標檢測與視覺定位 (Pyimagesearch)
代碼參考:HF 團隊的 Gradio 應用
Object Detection and Spatial Understanding with VLMs ft. Qwen2.5-VL















![[機器學習]08-基于邏輯回歸模型的鳶尾花數據集分類](http://pic.xiahunao.cn/[機器學習]08-基于邏輯回歸模型的鳶尾花數據集分類)



