目錄
一、什么是 TF-IDF?
1.語料庫概念理解
二、TF-IDF 的計算公式
1. 詞頻(TF)
2. 逆文檔頻率(IDF)
3. TF-IDF 值
三、關鍵詞提取之中文分詞的實現
四、TF-IDF簡單案例實現
(1)數據集展示及解釋
(2)代碼實現
1.調庫讀取文件
?2.實例化,并調用fit_transform()
3.為了方便觀察數據,將tfidf的值轉化為稀疏矩陣
4.對df數據集進行排序,我們可以利用pd的特性,利用索引一列一列的取出排序
五、TF-IDF 的優勢與適用場景
六、總結
在自然語言處理(NLP)領域,如何將文本數據轉化為計算機可理解的數值特征是一個核心問題。TF-IDF 作為一種經典的文本加權技術,因其簡單高效的特性,被廣泛應用于文本分類、信息檢索、關鍵詞提取等任務中。本文將從理論原理到代碼實現,全面解析 TF-IDF 的工作機制。
一、什么是 TF-IDF?
TF-IDF(Term Frequency-Inverse Document Frequency,詞頻 - 逆文檔頻率)是一種用于評估一個詞對一個文檔集或語料庫中某個文檔重要性的統計方法。其核心思想是:
- 一個詞在文檔中出現的次數越多,對文檔的重要性越高(詞頻 TF);
- 一個詞在整個語料庫的文檔中出現的次數越少,對區分文檔的重要性越高(逆文檔頻率 IDF)。
- 最終,一個詞的 TF-IDF 值為TF 值 × IDF 值,值越高則該詞對當前文檔的代表性越強。
1.語料庫概念理解
(1)語料庫中存放的是在語言的實際使用中真實出現過的語言材料。
(2)語料庫是以電子計算機為載體承載語言知識的基礎資源。
(3)真實語料需要經過加工(分析和處理),才能成為有用的資源。
舉例理解:假設有一個文件夾,文件夾里面有2000篇文章,想要提取出每篇文章中的關鍵詞。
這里的文件夾內的文件就是一個語料庫 ,而關鍵詞要具有代表性,能夠作為本文章與其他文章之間區分開來
二、TF-IDF 的計算公式
1. 詞頻(TF)
詞頻表示某個詞在當前文檔中出現的頻率,計算公式為:
? ? ? ? ? ? ? ? ? ? ??
例如:一篇文檔總共有 100 個詞,其中 “蘋果” 出現了 5 次,則 “蘋果” 在該文檔中的 TF 值為?(5/100 = 0.05)。
2. 逆文檔頻率(IDF)
逆文檔頻率衡量詞的普遍重要性,計算公式為:
? ? ? ? ? ? ? ? ? ? ?
- 分母加 1 是為了避免 “包含詞 w 的文檔數為 0” 時出現除以 0 的錯誤(平滑處理);
- 若一個詞在多數文檔中都出現(如 “的”“是” 等停用詞),其 IDF 值會很低;
- 若一個詞僅在少數文檔中出現,其 IDF 值會很高。
例如:語料庫有 1000 篇文檔,其中 “蘋果” 出現在 100 篇文檔中,則 “蘋果” 的 IDF 值為? ? ? ? ? ? ??![]()
3. TF-IDF 值
最終,詞w在文檔d中的 TF-IDF 值為兩者的乘積:
? ?![]()
三、關鍵詞提取之中文分詞的實現
英文每個單詞之間都有空格分開,中文之間則不存在這樣的分隔符。
jieba分詞的原理:
jieba是一個人工智能算法,jieba是基于隱馬爾可夫鏈實現的,jieba分詞的內部有點像辭海,分詞的原理(以“我們在學Python辦公自動化”為例)先找到’我‘,然后找到’我們’,其中'自動'和‘自動化都可以是一個詞’。
lcut():jieba庫里的一個方法,用來分詞;cut_all是lcut中的一個參數,將參數設置為True,則函數會返回某一個句子的所有可能的切分結果。
add_word():向jieba的辭海中添加新的詞,那么,我們下次進行分詞時就能將句子中的詞按照你添加的詞進行分詞。
load_userdict():將詞庫文件加載到jieba的辭海中,對文件的要求是一個詞在文件中占一行,函數的參數是需要添加詞庫文件的路徑。
lcut()方法:分詞的結果
![]()
cut():分詞的結果
![]()
四、TF-IDF簡單案例實現
(1)數據集展示及解釋
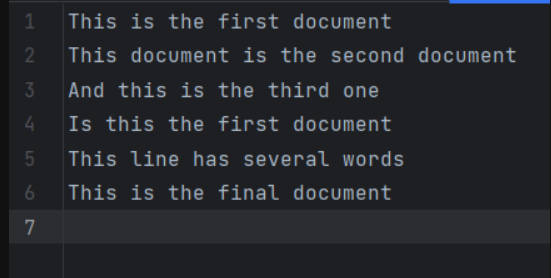
數據集總共有6行數據,整個數據集(即遮條數據)可以看成一個語料庫,每一行可以看成一篇文章,每篇文章中有若干個詞。
調用TF-IDF包,來計算每一行的關鍵詞的TF-IDF的值,最終目標是實現把所有文章中的關鍵詞都進行排序,并將排名前五的關鍵詞都打印出來
(2)代碼實現
1.調庫讀取文件
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
inFile = open(r"task2_1.txt", "r")
corpos = inFile.readlines()????????cospos的數據類型及數據展示
?2.實例化,并調用fit_transform()
fit _transform作用:
fit 步驟:此步驟會分析輸入的文本語料庫(即 corpos),從中學習詞匯表以及每個詞的逆文檔頻率(IDF)值。詞匯表涵蓋了語料庫中所有不同的詞,而 IDF 值體現了每個詞在整個語料庫中的重要程度。
transform 步驟:在學習到詞匯表和 IDF 值之后,該步驟會把輸入的文本語料庫轉換為 TF-IDF 特征矩陣。TF-IDF 是一種衡量詞在文檔中重要性的統計方法,它綜合考慮了詞在文檔中的出現頻率(TF)以及詞在整個語料庫中的稀有程度(IDF)。
vectorizer=TfidfVectorizer()
tfidf=vectorizer.fit_transform(corpos)#打印tfidf的值
print(tfidf)get_feature_names()?方法的作用就是返回這些特征(詞匯)的名稱,即這個數據集中所有單詞,去重后的詞匯集合
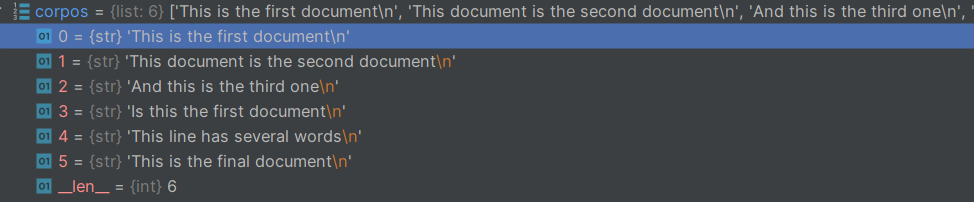
wordlist=vectorizer.get_feature_names()
print(wordlist)wordlist的值,這里可以看出,它以列表的形式存儲了所有詞
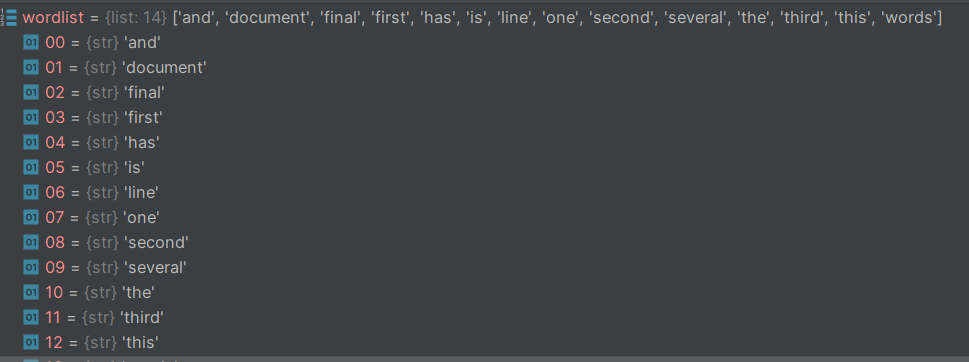
tfidf值數據如下:
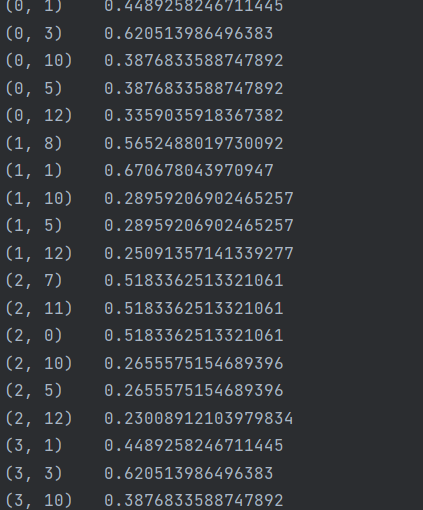
解釋其含義:
![]()
以這個為例,(0,1)其中0是指這個詞在數據集中處于那個文章中,這里是代表數據集的第一條數據“This is the first document”,這里的1是指在關鍵詞列表(即wordlist)中的位置,可見這里的1對應word list中的第二個值document,0.4489258246711445這個數則是document的TF-IDF的值,表示這個詞的重要程度。
3.為了方便觀察數據,將tfidf的值轉化為稀疏矩陣
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)效果如下
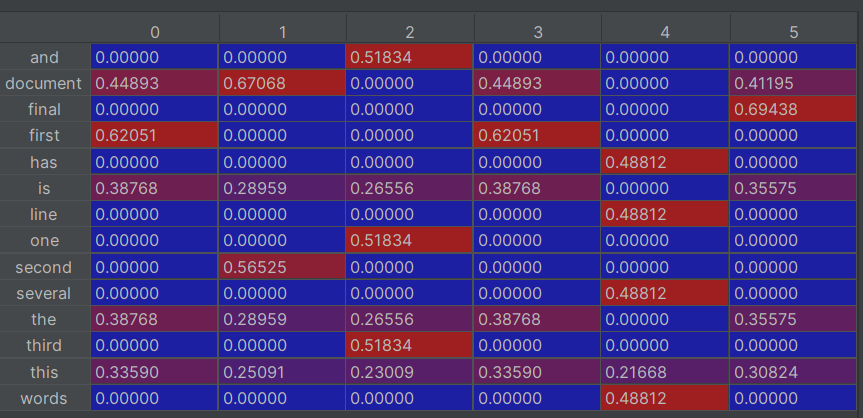
這里的行是指每個單詞,列是指這個單詞位于那個文章中。
4.對df數據集進行排序,我們可以利用pd的特性,利用索引一列一列的取出排序
df.sort_value()排序,pandas類型數據排序,對值進行排序,因為pandas的數據有索引列
for i in range(len(corpos)):featurelist=df[[i]]feature_rank=featurelist.sort_values(by=i,ascending=False) #對featurelist按數值排序,降序print(feature_rank.head(5))
#打印前五行的內容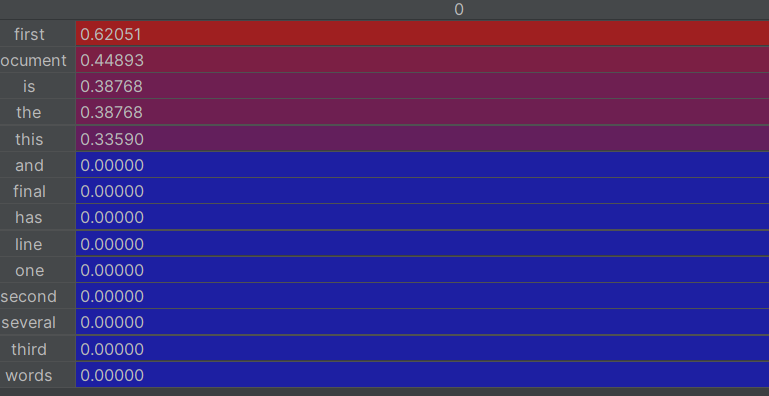
這樣就實現了對關鍵詞進行排序,輸出每篇文章前五的關鍵詞
五、TF-IDF 的優勢與適用場景
優勢:
- 簡單直觀:原理易于理解,計算成本低;
- 效果穩定:在文本分類、關鍵詞提取等任務中表現可靠;
- 可解釋性強:權重直接反映詞對文檔的重要性。
適用場景:
- 文本分類、情感分析;
- 信息檢索(如搜索引擎排序);
- 關鍵詞提取(如文章摘要生成);
- 文檔相似度計算。
六、總結
TF-IDF 作為一種經典的文本特征提取方法,以其簡單高效的特點在 NLP 領域經久不衰。它通過詞頻和逆文檔頻率的加權,有效突出文檔中的關鍵信息,為后續的文本分析任務奠定基礎。
盡管近年來詞向量(如 Word2Vec)、預訓練模型(如 BERT)在語義理解上表現更優,但 TF-IDF 在輕量化場景、可解釋性要求高的任務中仍不可替代。掌握 TF-IDF 的原理和實現,是入門文本處理的重要一步。
希望本文能幫助你理解 TF-IDF 的核心思想,歡迎在實際項目中嘗試并優化這一方法!
)






(超詳細!)Vscode+espidf 攝像頭拍攝視頻實時傳輸到LCD,文末附源碼)
)
)
|變量、函數與控制流)
![【渲染流水線】[幾何階段]-[圖元裝配]以UnityURP為例](http://pic.xiahunao.cn/【渲染流水線】[幾何階段]-[圖元裝配]以UnityURP為例)







