
OneEval官網地址:http://OneEval.OpenKG.cn
OneEval文章鏈接:https://arxiv.org/abs/2506.12577
要點導讀

? ? 今年4月,OpenKG發布“大模型+知識庫”融合能力評估榜單OneEval v1.0。近期,OpenKG在此基礎上,組織撰寫了OneEval評測白皮書,并對OneEval榜單進行了升級和更新,包括新增GPT5, Claude4等多個新模型,并引入更多評測數據集。白皮書部分要點如下:
在需要結合外部知識進行深度推理時,大模型普遍「不及格」:即使是GPT-5、Claude-4等頂級模型,綜合得分也僅有60%左右,在難題上的表現更是斷崖式下跌至30%以下。
大模型在知識推理上集體「偏科」:在處理表格、代碼等結構化知識時性能尚可,但一旦面對復雜的知識圖譜、邏輯規則和專業文檔,模型的能力會迅速失效。
被寄予厚望的GPT-5并未展現出突破性優勢,其與前代版本的微小差距,暴露出GPT系列在知識增強路徑上的優化仍面臨重大挑戰。
1. 引言
OneEval 是由OpenKG發起并組織的中立、公益、專業的大模型評測榜單。區別于多數聚焦于“LLM”基礎能力評測的現有榜單,OneEval 更加側重于 “大模型 + 知識庫(LLM+KB)” 的融合能力評估,重點考察知識增強驅動下大模型的慢思維能力(即模型在復雜問題上的深度思考與分步推理能力)與神經符號混合推理能力(結合神經網絡與符號邏輯的知識推理能力),助力大模型向“知識深、思維強”的方向持續演進。
隨著大語言模型(LLMs)的快速發展,最新一代推理型模型在自然語言理解與推理任務中表現出顯著進步。盡管已有多項研究[1-4]從不同維度對 LLM 能力展開評估,但這些評測體系主要集中在通用理解和基礎推理層面,缺乏模型在處理多類型異構知識與跨領域復雜推理任務中的系統性評估。特別是在知識增強場景下,模型如何有效利用外部知識源進行高質量推理的能力評估仍是研究空白。
在此背景下,2025年4月,OpenKG 推出 OneEval V1.0,希望為知識增強場景下的大模型綜合能力評估提供一個系統化框架。OneEval V1.0包含十個典型任務,涉及四類知識載體和六大關鍵領域,深入衡量大模型對多種知識形態與多領域語境中的知識理解、知識利用與知識推理能力。
在V1.0的基礎上,OpenKG 現正式發布全面升級的 OneEval V1.1。新版本在評測的廣度和深度上均實現了顯著擴展:
1)模型更廣:評測對象從16個翻倍至32個,新增包括GPT-5、Claude4在內的10個最新的大語言模型。
2)數據更深:評測數據集擴充至15個,新增了包括稅務推理、知識沖突、學術理解等任務的高質量數據集。
OneEval V1.1 致力于更全面、及時地追蹤大模型在知識增強領域的前沿能力,為行業發展提供更具時效性與參考價值的評測基準。整體評測框架如圖1所示。
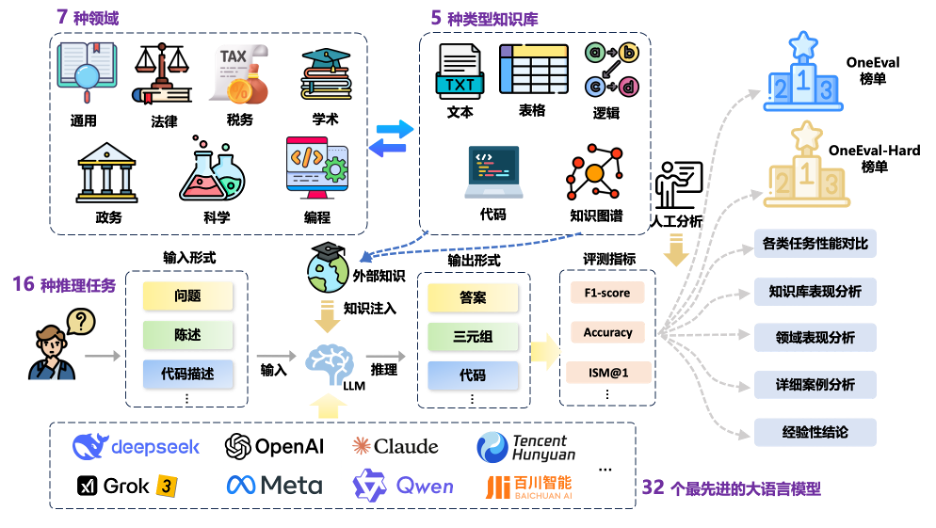
圖1 OneEval評測框架示意圖
OneEval 由 OpenKG SIGEval 工作組持續維護,評測數據與結果將定期更新,評測流程也將逐步引入多元防作弊機制,包括樣本變體生成、模型輸出標準化、多次采樣驗證、時效性驗證以及對抗性問題構建等技術手段,并在可行范圍內公開評測細節,努力保障評測的科學性、透明性與公平性。
2. 相關工作
在LLM的能力評估方面,已有許多國內外基準測試和排行榜對廣泛的任務進行了探索與測試。大多數現有的基準測試可以被分為四個類別:(1) 知識考察型:以客觀選擇題和問答題等形式測試模型的學科知識掌握水平,包括MMLU[1]、CMMLU[2]、CEval[3]、AGIEval[4]等。(2) 指令遵循型:以問答等形式評估模型對用戶指令的遵循能力,包括LLMBAR[5]、Flan[6]、NaturalInstructions[7]等基準測試。(3) 聊天對話型:使用多輪交互的問答數據測試模型的上下文理解和對話能力,包括CoQA[8]、MMDialog[9]、MT-Bench[10]和OpenAssistant[11]等。(4) 安全風險型:以選擇題和問答題等形式評估模型的安全與幻覺風險,例如DecodingTrust[12]、AdvGLUE[13]、StrongReject[14]、HarmBench[15]等。
與單一基準測試不同,現有的知名排行榜通過整合多個評測任務、整理廣泛評估場景,采用多維度、多任務的評估方法,構建更全面的大模型能力畫像。HuggingFace 的 Open LLM Leaderboard 整合了 MMLU-Pro、GPQA、MuSR、MATH、IFEval 和 BBH 等六個基準測試,綜合考核模型在知識理解、推理、數學解題、信息抽取和復雜任務處理等方面的能力。上海AI Lab的OpenCompass(司南)[17]構建了包括考試、知識、語言、理解、推理和安全六個維度的評測框架,通過引入動態更新的評測數據集確保評估的時效性和廣度。來自北京智源的FlagEval(天秤)整合了30多項能力維度與30個基準測試,構建了超10萬條評測樣本的大規模評測庫,包含文本、圖像、音頻等多模態信息。除基于標準化數據集的評測外,基于人類偏好的比較性評測近年來也獲得廣泛關注。來自UCB的Chatbot Arena Leaderboard(聊天競技場)[18]創新性地采用眾包+Elo排名機制,讓人類評估者對模型回復質量進行兩兩比較,累積得出模型間的相對實力排名。斯坦福大學的AlpacaEval[19]則引入“LLM-as-a-Judge”方法,利用大模型作為評判,通過比較待測模型與參考模型回復的優劣,將相對勝率作為排名依據,大幅提升了評測的規模與效率[20]。
然而,現有的基準測試體系仍存在一些不足:1) 缺乏對復雜知識庫推理能力的評估;2)知識載體單一,尚未全面涵蓋如知識圖譜、代碼、表格結構化知識的測試維度。針對上述問題,OneEval 首次構建了統一的跨知識源、多領域復雜知識庫推理任務評測框架,力求在評估大模型知識增強能力方面實現更高的覆蓋性與科學性。
3. OneEval評測數據集
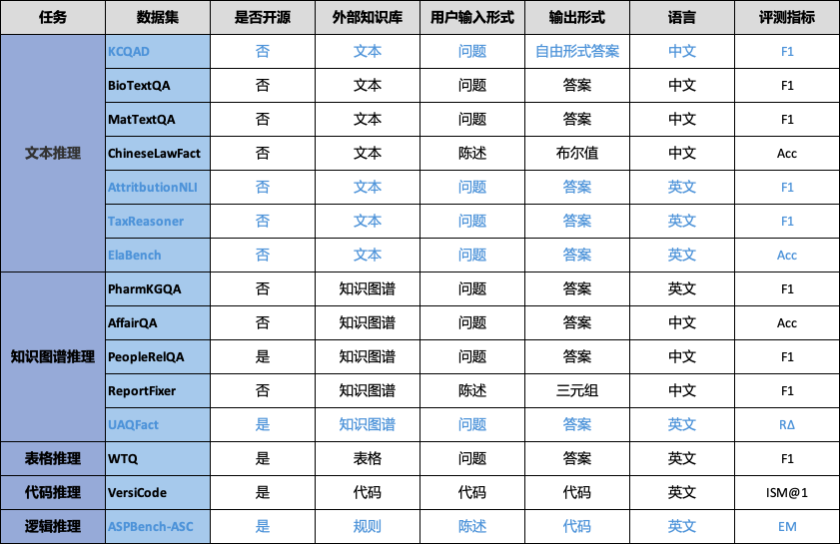
OneEval主要基于OpenKG自建或整理的公開數據資源,并將周期性增加和更新。OneEval V1.1 包含15個面向多類型知識庫的推理評測數據集,覆蓋結構化與非結構化、顯性與隱性等多種知識形態,具有更高的知識特異性與任務復雜度。其中每個數據集包含約200條推理問題,相較于 MMLU、BigBench 等側重通識能力的評測基準,OneEval 更聚焦于大模型在多源異構知識庫中的深層理解與綜合推理能力評估,以更貼近真實應用場景的方式推動知識增強型模型能力評測。評測數據集來源信息如表1所示。
表1 OneEval評測數據集來源信息
數據集 | 來源 |
BioTextQA | OpenKG自建,數據來源自biorxiv,生物學 |
MatTextQA | OpenKG自建,數據來源自arxiv,材料學 |
ChineseLawFact | OpenKG自建,數據來源真實中國法律文書 |
PharmKGQA? | https://pubmed.ncbi.nlm.nih.gov/33341877/ |
AffairQA | OpenKG自建,源自浙大政務知識圖譜 |
PeopleRelQA | https://tianchi.aliyun.com/competition/entrance/532196/ |
ReportFixer | OpenKG自建,源自內部研報數據 |
WTQ | https://arxiv.org/abs/1508.00305 |
VersiCode | OpenKG成員發布,版本敏感的代碼生成,https://arxiv.org/abs/2406.07411 |
UAQFact | 根據Wikidata中抽樣事實三元組作為事實知識構建 |
TaxReasoning | 基于中國稅法政策文件構建,用于評測模型的數學推理與邏輯規則推理能力 |
ElaBench | OpenKG自建,根據AI領域頂會頂刊論文進行人工標注,涉及的細粒度學術知識 |
ASPBench-ASC | OpenKG成員發布,答案集編程,https://arxiv.org/abs/2507.19749 |
AttritbutionNLI | OpenKG成員發布,https://arxiv.org/abs/2401.14640,評測模型回答問題的歸因能力 |
KCQAD | OpenKG自建,評測模型在面臨知識沖突時的推理能力 |
3.1 評測任務
給定用戶查詢 Q 和可訪問的知識庫 S,目標是利用 S 中的信息生成所需答案 A。形式化地,任務是讓一個大模型 f_θ 計算 A = f_θ(Q, S)。這里,查詢 Q 可以以多種格式呈現,包括自然語言的問題、陳述、描述或代碼片段。知識庫 S 來自一組預先定義的不同類型(下面的小節將詳細說明)。答案 A 應當是基于所給 Q 和 S 的有效推導或推理,其格式可以多樣,涵蓋自由形式文本、像三元組這樣的結構化輸出、布爾值或代碼片段。
3.2 知識庫類型
OneEval V1.1 基準涉及以下5種類型的知識庫,后續還將增強更多的知識庫類型:
文本知識庫:涵蓋非結構化文獻與文檔,測試模型在文本型知識的理解,以及復雜語境下的語義建構、信息抽取等能力。
表格知識庫:以結構化表格數據為基礎,考查模型在結構化知識的理解,以及對數值、分類與層級信息的處理、比較與邏輯計算能力。
知識圖譜:基于實體-關系三元組構建的結構化語義網絡,評估模型在圖結構知識的理解,以及多跳推理、實體對齊與關系識別等任務中的表現。
代碼知識庫:包含函數文檔、源代碼與API說明,聚焦模型在程序型知識的理解,以及代碼補全、自然語言到代碼生成等能力。
邏輯知識庫:邏輯庫是對一個領域進行概念化的形式化、顯式規范。它通常包括三項內容:概念集(即類),屬性集(即概念間的關系),以及一組用于定義約束和邏輯關系的公理或規則。
表2 OneEval評測數據集任務類型與統計信息
3.3 領域類別
OneEval V1.1 覆蓋通用、政務、科學、法律,編程,稅務,學術六大關鍵知識領域,重點強調多源異構知識的廣泛性與專業性,系統性評估LLM在復雜知識驅動任務中的推理與應用能力。具體類別信息如圖2所示。
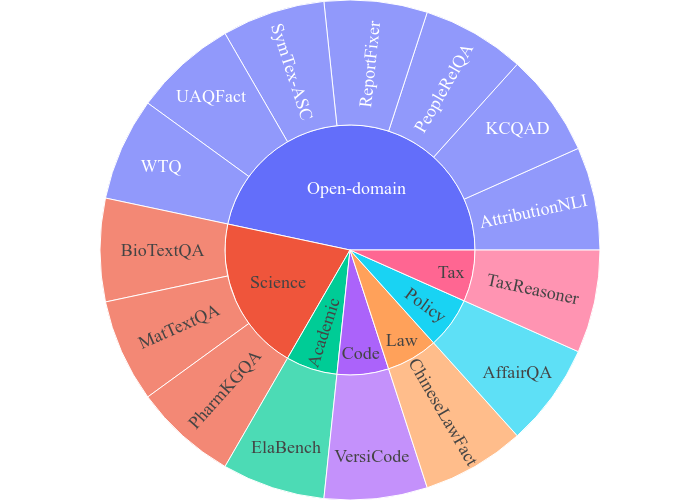
圖2 OneEval評測數據集領域信息
通用(Open-domain):基于百科全書與綜合性知識資源,涵蓋來自各類百科知識庫的開放領域知識,考察模型對跨主題背景知識的理解與遷移能力。
政務(Politics):基于中文政務文件與政府官網信息,聚焦政策條文、行政流程等結構化與半結構化知識,考驗模型對規章制度的精準解析與政策應用能力。
科學(Science):整合來自生物、材料科學公開文獻及生物醫藥知識圖譜的專業知識,涵蓋實驗事實、領域術語與科學推理模式,測試模型的科學推理與知識整合能力。
法律(Law):源自真實法律文書,包含判決書、裁定書等法律事實與規則,突出模型對法律條文邏輯與案例事實的結合推理能力。
編程(Code):來自GitHub的海量開源代碼庫,跨越300+依賴庫和2000+ API 版本,強調模型對程序語言、函數接口及語義執行的深入理解與生成能力。
稅務(Tax):基于中國稅法政策文件構建,用于評測模型的數學推理與邏輯規則推理能力。
學術(Academic):收集來自AI領域的頂會頂刊論文,組織擁有論文發表經驗的碩士和博士生根據論文提出具有迷惑性的選擇題,考驗模型對細粒度的專業知識的理解、推理和判斷能力。
3.4 OneEval-Hard
為更精準地評估LLM在高難度推理場景下的表現,我們基于多輪篩選和專家評審人工構建了一個困難樣本子集——OneEval-Hard,其中每個數據集選擇約50個樣本,專門聚焦于模型在多步推理、隱式知識關聯和跨域知識整合等推理任務中的薄弱環節。該子集不僅具備更高的判別性和難度,也為深入剖析LLM的知識盲區與推理瓶頸提供了重要測試依據,有助于推動更有針對性的LLM優化與能力提升。
4. OneEval評測框架
OneEval 評測框架(見圖1)旨在系統化評估LLM在借助外部知識庫完成推理任務時的表現,重點考察模型對各類知識庫的理解能力及其有效運用方式。整個評測過程保持 LLM 參數不變,通過結合用戶輸入與檢索到的外部知識構建提示,引導模型進行推理并按照任務的目標形式生成答案。
4.1 外部知識檢索范式
由于本評測框架重點在于評估LLM在對各種類型的知識理解和運用能力,而非檢索知識的能力,因此,對于涉及外部知識的任務,采用統一的檢索范式,獲取與測試樣本相關的上下文信息。具體而言,基于Dense Retrieval的思路,其核心在于按用戶輸入與知識片段(文本片段、代碼片段、三元組子圖等)的稠密向量(q,K)之間的相似度S進行排序,選取top-k知識片段作為知識上下文。S的計算公式如下:
S(q, K) = cos(q, K)
其中,q和K分別表示由SentenceBERT模型編碼得到的用戶輸入向量和知識向量。需要注意的是,通過上述方式檢索獲得的外部知識上下文中可能包含噪聲。這種設置更貼近真實應用場景,為評估模型在面對不完美或冗余知識時的魯棒性提供了有效的測試環境。
4.2 評測對象
本次版本的評測選擇了多個國內外領先的研究團隊和企業,涵蓋開源與閉源、不同參數規模及不同技術路線的代表性LLM,詳細信息如表3所示(按首字母排序)。新發布的 OneEval V1.1 版本進一步擴展了評測陣容,新增了 18 個最新或備受關注的大模型,其中包括 GPT-5、Qwen-3 和 Claude-4 等前沿模型。詳細的模型列表請參見表3(按首字母排序),其中新增模型已用藍色標出。
表3 評測對象統計信息
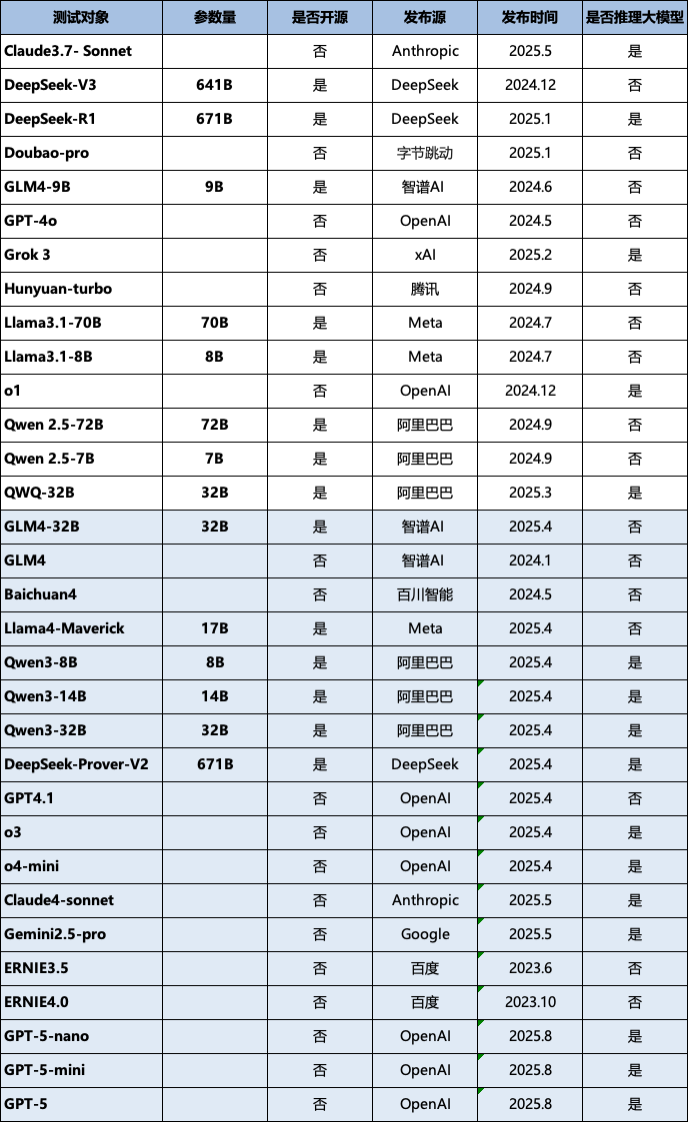
鑒于評測資源與時間成本的限制,目前仍有部分表現優異的大語言模型尚未納入 OneEval 榜單。隨著 OneEval 評測工作的持續推進,未來將逐步覆蓋更多主流及前沿的大語言模型,從而實現更全面、系統的性能對比與能力分析。
4.3 評測指標
評測采用多維度指標體系,包括:
各任務評測指標:準確率(Accuracy,用于分類任務)、F1分數(平衡精確率與召回率,用于抽取和生成任務)、ISM@1(Identifier Sequence Match,用于代碼生成任務),R?(衡量模型在面對無法回答的問題時的能力)。具體指標分配詳見表2。
綜合評分:為了均衡考慮模型在不同任務上的綜合表現,我們規定:一個模型的總體評分(Overall Score)為該模型在每個評測數據集得分的平均值。
4.4 總體評分
表4 OneEval總體榜單
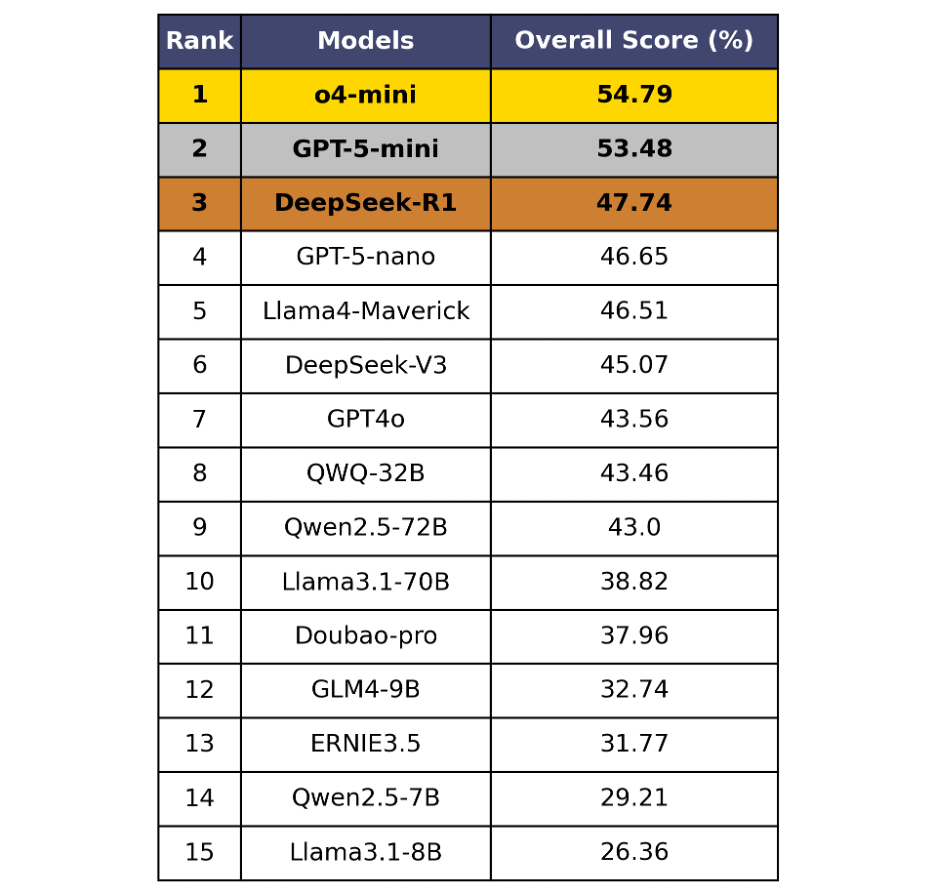
表5 OneEval-Hard總體榜單
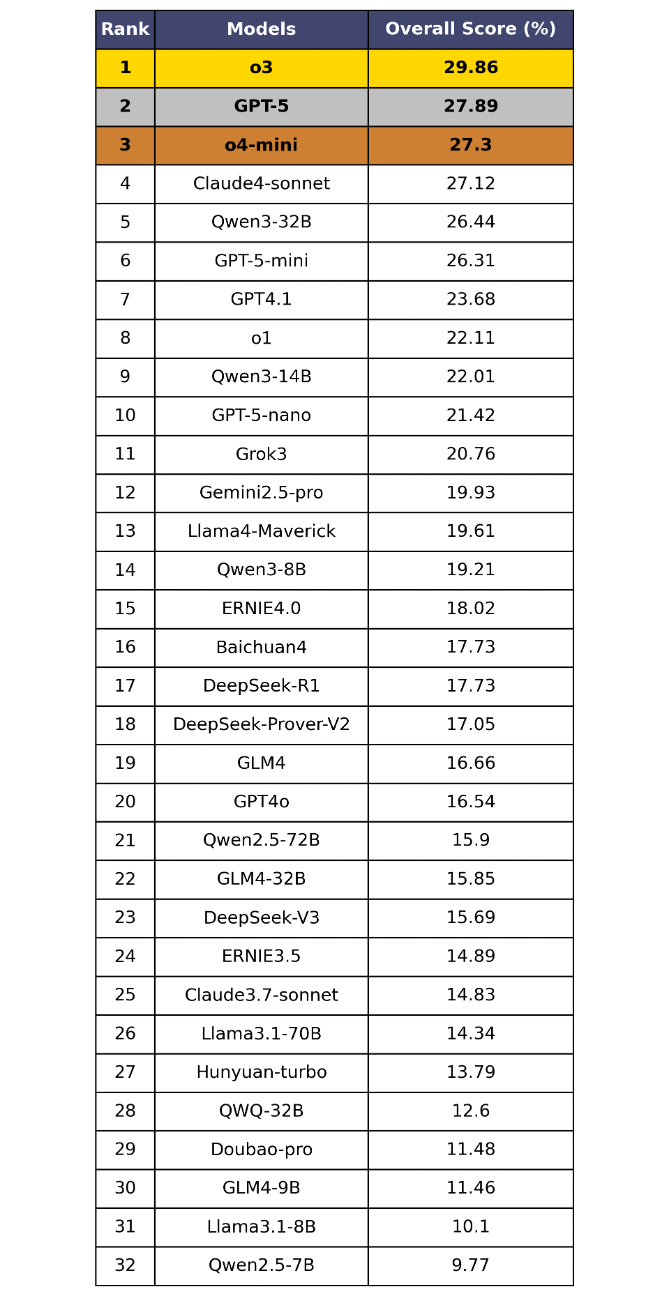
OneEval V1.1 的總體評測結果(表4和表5)清晰地揭示了當前大模型在知識增強推理場景下的能力現狀與核心挑戰,從中可以發現:
當前的LLM普遍在知識增強場景下的推理能力不足,離實用化差距巨大。在標準的OneEval評測中,即便是GPT-5、o4-mini等頂尖模型,得分也僅徘徊在50%左右,未能及格。這表明將大模型與知識庫(LLM+KB)融合以解決復雜問題的能力,遠未達到成熟和實用的水平。在更能體現深度思考能力的OneEval-Hard難題集上,性能更是出現斷崖式下跌,榜首模型得分不足30%,暴露了當前LLM技術的嚴重短板。
GPT-5并未展現突破性優勢,知識增強場景下的推理能力演進停滯。備受矚目的GPT-5及其系列模型,在OneEval評測中并未展現出與市場預期相符的統治力,其與前代版本的得分差距極小。這強烈暗示,單純依賴擴大模型規模和通用語料的路徑,在提升模型真實的知識應用與推理能力方面已進入瓶頸期。GPT系列在OneEval所考驗的知識增強任務上,演進幅度十分有限。
“小模型”表現亮眼,參數規模并非唯一解。評測結果顯示,部分“mini”版本或經過特定優化的模型(如o4-mini)在總榜上的排名甚至超越了更大規模的通用模型。這說明在知識增強這類任務上,高效的知識調用與整合能力,其重要性不亞于模型的參數規模。這為行業指明了一條更具潛力的技術路徑:優化模型與知識的協同方式,可能比無盡的“堆參數”更有效。
OneEval-Hard成為“慢思維”試金石,可以有效篩選深度推理模型。OneEval-Hard難題集極大地改變了模型的排名。o3、GPT-5等在底層推理上更具潛力的模型排名躍升,而一些在OneEval上表現尚可的模型(如DeepSeek-R1)則排名大幅下滑。這種顯著分化證明了OneEval-Hard能有效地區分出模型的“快思考”(依賴模式匹配)與“慢思維”(依賴深度推理),成功篩選出在復雜問題上具備更強魯棒性和深度思考潛力的模型,指明了“知識深、思維強”的演進方向。
4.5 各類知識庫推理性能對比
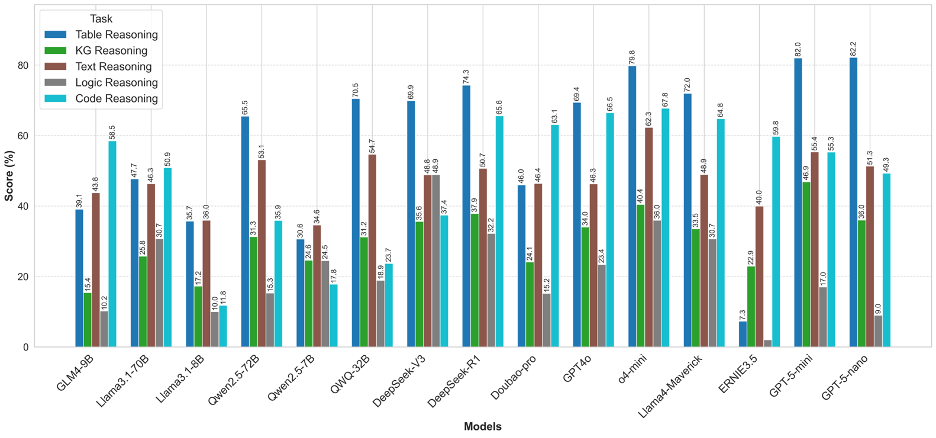
圖3 OneEval不同類型知識庫推理性能對比
OneEval的評測結果清晰地描繪了當前大模型在不同知識形態上的能力圖譜。模型普遍在表格推理(Table Reasoning)和代碼推理(Code Reasoning)上表現出較好的性能,以GPT-5系列和o4-mini為代表的頂尖模型在這些任務上能夠達到70%-80%的高分。這表明,對于結構化或半結構化、規則相對明確的知識載體,現有模型架構已具備較強的理解和應用能力。相比之下,知識圖譜推理(KG Reasoning)和邏輯推理(Logic Reasoning)則構成了所有模型的共同短板,得分普遍偏低。這揭示了一個核心挑戰:模型雖然擅長處理序列化的文本和數據,但在需要進行多跳符號推理(KG)或遵循嚴格形式化公理(Logic)時,其能力顯著不足,反映出當前模型在深度、抽象推理方面仍有巨大的提升空間。
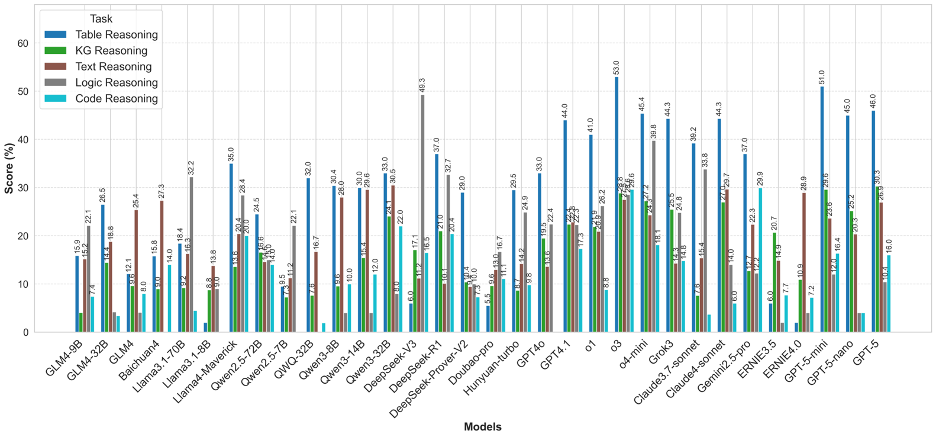
圖4 OneEval-Hard不同類型知識庫推理性能對比
OneEval-Hard的分析則如同一面“放大鏡”,將模型在復雜任務中的能力邊界和內在缺陷暴露無遺。首先,最顯著的特征是所有模型在所有知識庫類型上的性能都出現了斷崖式下跌,這有力地證明了深度、多步推理是當前技術的普遍瓶頸。其次,能力分化變得更為極端:在知識圖譜和文本推理上,絕大多數模型的性能幾乎崩潰,得分趨近于零,說明當推理鏈條變長、語義語境變復雜時,模型的推理能力會迅速失效。在邏輯推理任務上,DeepSeek系列模型(尤其是DeepSeek-V3)展現出不錯的性能。
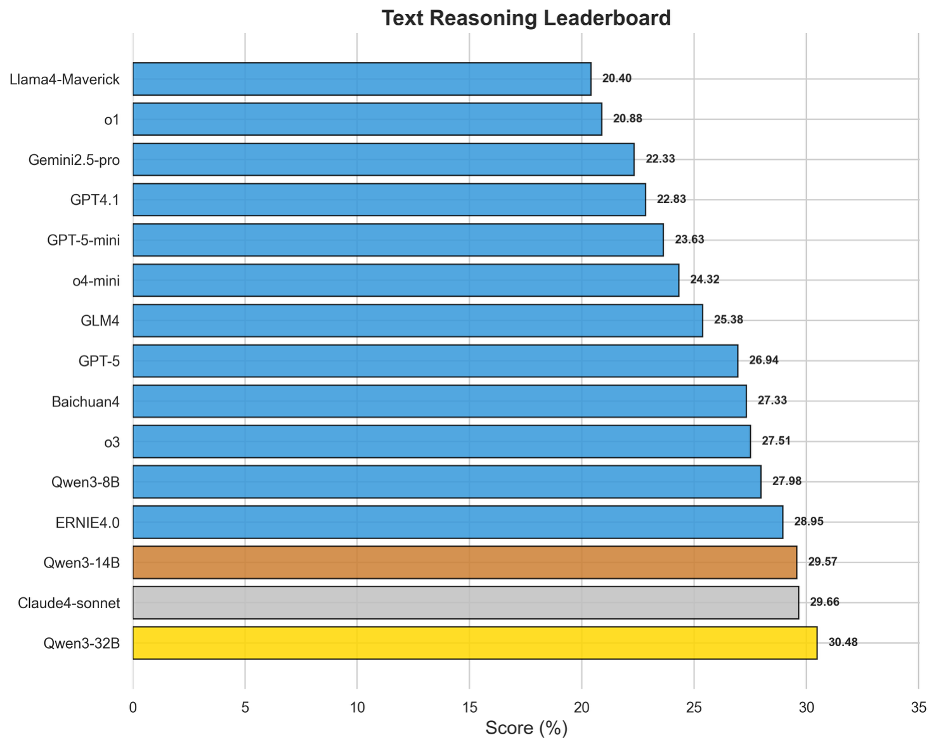
圖5 OneEval-Hard文本推理表現排名
盡管文本是LLM的“母語”,但基于文本知識庫的深度推理得分卻普遍偏低,榜首Qwen3-32B的得分僅為30.48%。這有力地證明了OneEval評測的深度:它考察的并非簡單的信息檢索或摘要,而是對復雜文檔(如學術論文、法律文書)進行深度語義建構和上下文推理的能力。榜單頂部模型非常密集,Qwen系列、Claude4-sonnet、ERNIE4.0和o3等模型得分十分接近,這表明在深度文本理解這個核心任務上,各類旗艦模型競爭異常激烈,但尚未有任何一家取得決定性優勢,如何讓模型真正“讀懂、想透”復雜文本,依然是LLM發展的根本性課題。
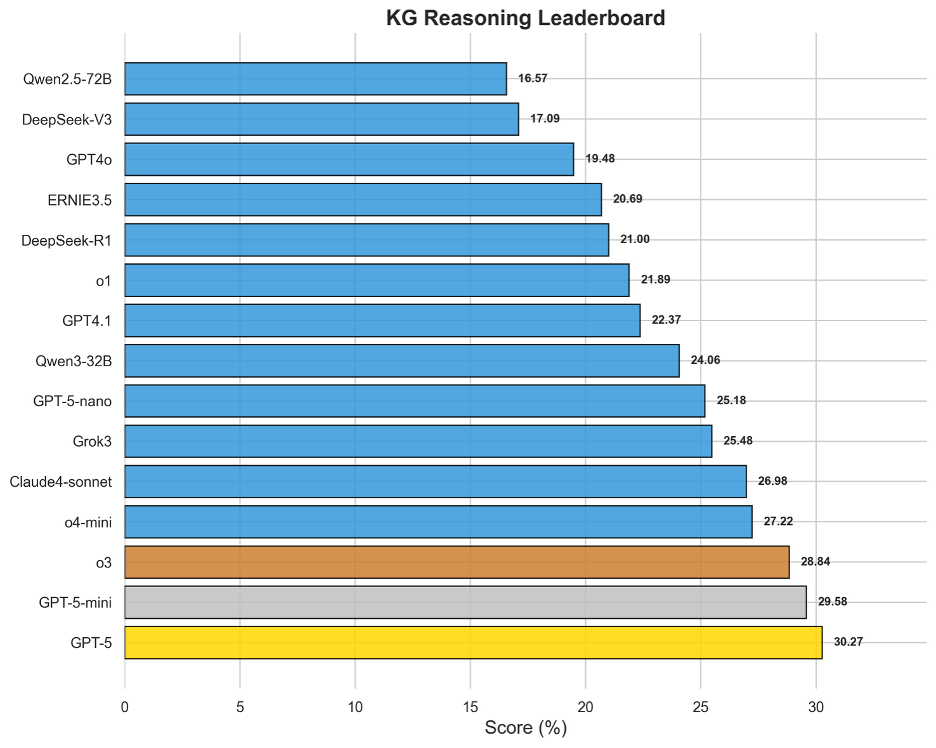
圖6 OneEval-Hard知識圖譜推理表現排名
知識圖譜推理能力是衡量模型結構化知識理解與多步推理能力的關鍵。評測結果顯示,這對于當前所有大模型都是一個顯著的挑戰,榜首模型GPT-5的得分也僅為30.27%。這一普遍偏低的表現,直接反映出在圖結構數據中進行多跳推理、識別復雜關系和路徑發現的內在困難。領先的模型如GPT-5、GPT-5-mini和o3在該榜單上占據前列,表明強大的通用推理核心是駕馭知識圖譜的基礎。然而,整體得分不高也預示著,如何讓模型從本質上理解并高效導航符號化的語義網絡,而非僅僅進行表面上的文本匹配,是“LLM+KG”融合技術亟待突破的瓶頸。
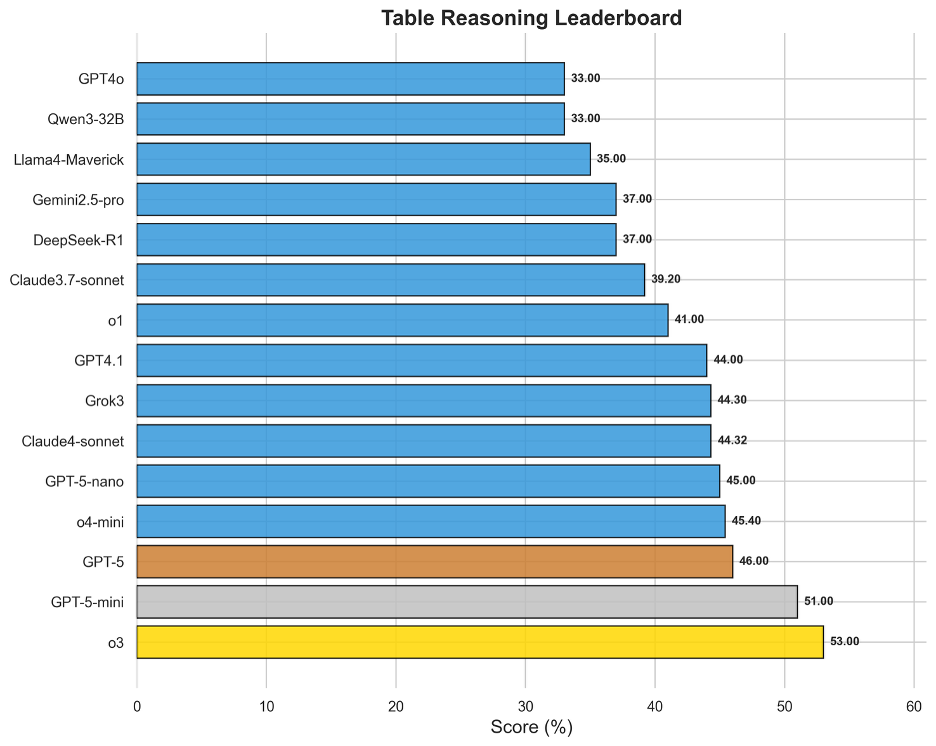
圖7 OneEval-Hard表格推理表現排名
在所有知識庫類型中,表格推理是當前大模型表現最為成熟的領域。o3以53.00%的得分奪魁,成為唯一在單項知識庫評測中突破50%大關的模型。表格作為一種融合了自然語言(表頭、單元格文本)和結構化數據(行列、數值)的知識載體,似乎與現有LLM的“世界模型”更為契合。榜單上,o3、GPT-5系列、o4-mini等頂級模型的得分普遍較高且差距不大,說明領先模型已基本掌握了在表格上進行查找、比較、排序和簡單計算的能力。
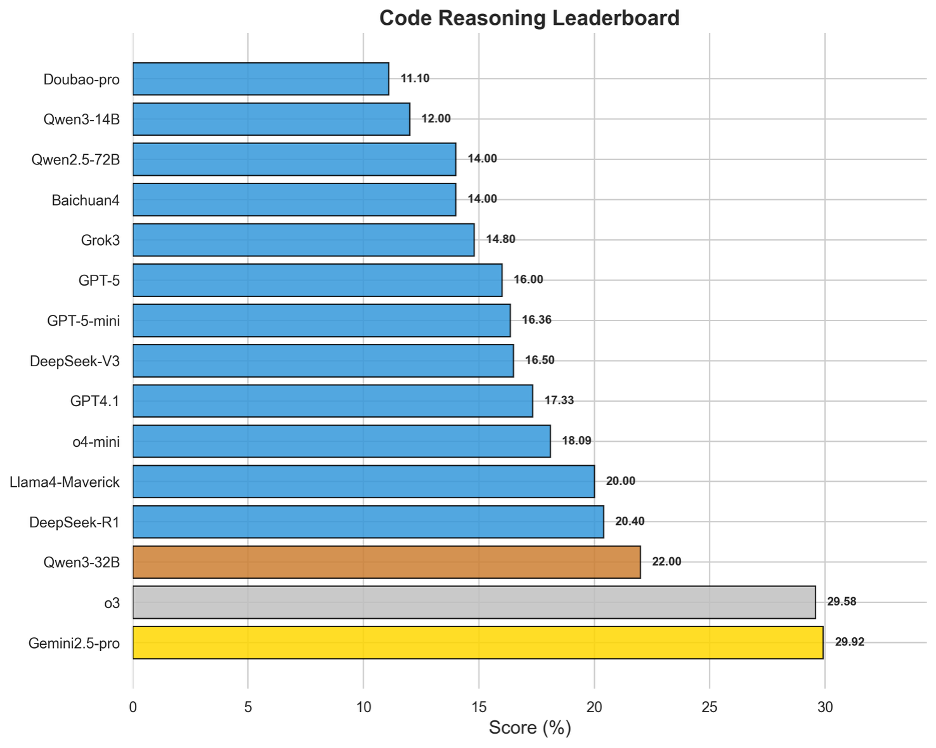
圖8 OneEval-Hard代碼推理表現排名
代碼作為一種形式化的、邏輯嚴謹的知識庫,其深度推理能力評測結果揭示了模型的另一塊“硬骨頭”。榜單呈現出清晰的“斷層”現象:Gemini2.5-pro(29.92%)與o3(29.58%)以微弱差距共同領跑,并與后續模型拉開了顯著距離。這表明頂尖的代碼推理能力(如理解復雜算法邏輯、API依賴關系等)是少數頂尖模型的專屬優勢。整體得分與知識圖譜同樣處于低位,這說明模型將自然語言指令精確轉化為程序邏輯,并對現有代碼庫進行深度分析和調試的能力還未成熟,是模型在專業化、高精度應用場景中的核心短板。
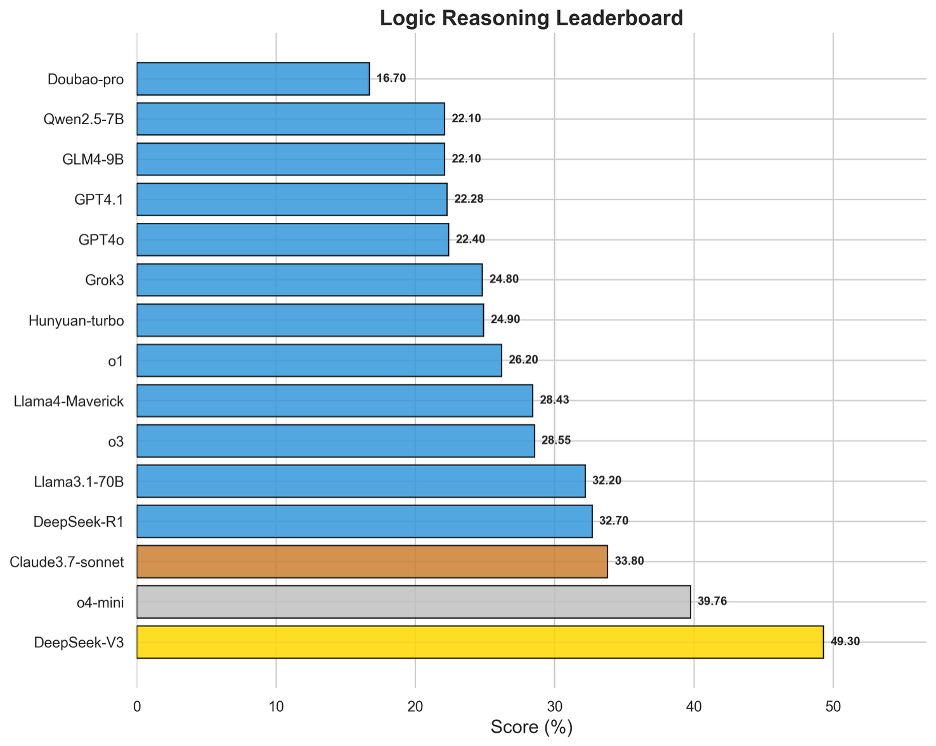
圖9 OneEval-Hard邏輯推理表現排名
邏輯推理榜單的結果比較出人意料。DeepSeek-V3以49.30%領先,與第二名o4-mini(39.76%)拉開了近10個百分點的巨大差距。這表明,在遵循形式化、顯式規則進行推演這一特定能力上,新模型并沒有具備更強的推理性能。DeepSeek-V3的邏輯推理性能,很可能源于其在架構設計或預訓練階段對符號推理和邏輯規則的特定強化。
4.6 不同領域推理性能對比
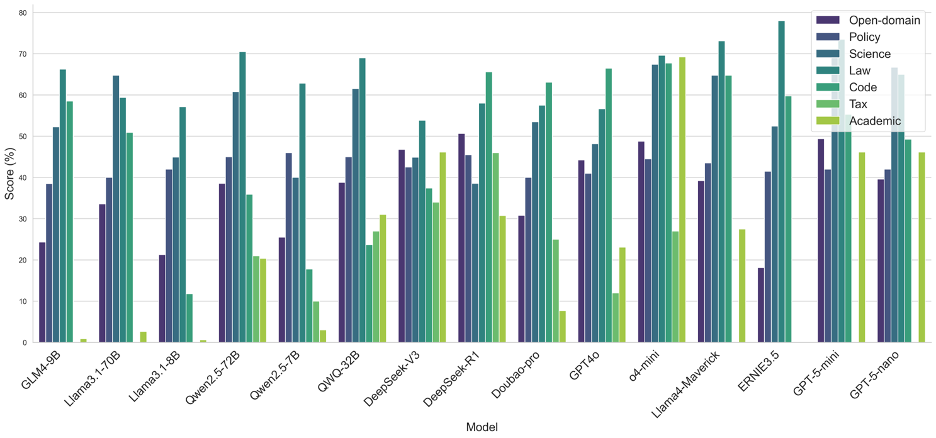
圖10 OneEval不同領域的模型表現性能對比
從OneEval的領域性能分布來看,當前大模型的能力呈現出明顯的領域偏向性。絕大多數模型在法律(Law)、代碼(Code)和科學(Science)領域表現突出,這表明模型對于結構化、邏輯性強、事實明確的知識領域具有更強的理解和應用能力,這可能得益于預訓練語料中該類數據的高質量和大規模覆蓋。相比之下,幾乎所有模型在學術(Academic)和政務(Policy)領域的表現均顯著偏低。從中可以看出,模型在處理需要深度、專業領域知識解讀(學術文獻)或涉及復雜社會背景與細微語義理解(政策文件)的任務時,能力尚有不足。
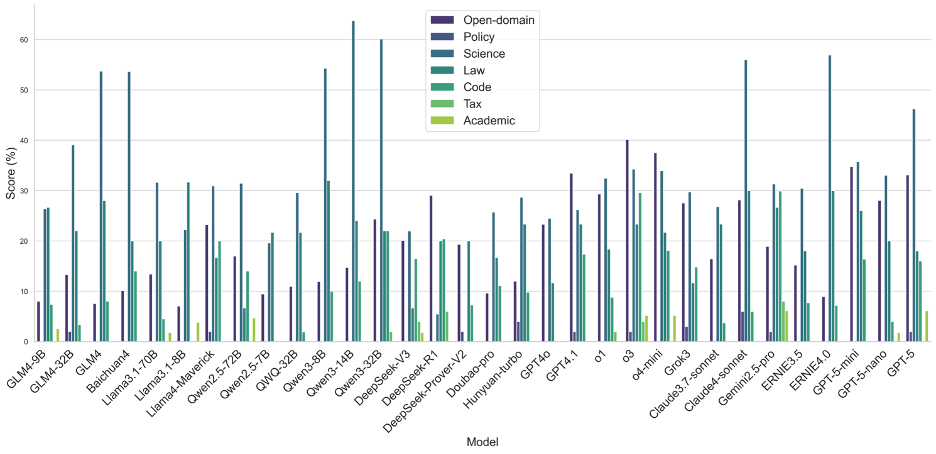
圖11 OneEval-Hard不同領域的模型表現性能對比
OneEval-Hard的領域分析則更深刻地揭示了模型在深度推理任務中的“能力短板”。與Full Set相比,OneEval-Hard上各模型在所有領域的性能均大幅下降,且領域的強弱分化愈發極端。在學術(Academic)和稅務(Tax)這兩個知識密集且推理鏈條長的領域,絕大多數模型的性能幾乎崩潰,得分趨近于零,這證明了在面對真正復雜的知識推理挑戰時,現有模型架構的魯棒性嚴重不足。一個值得注意的現象是,在Hard Set中,政務(Policy)和通用域(Open-domain)成為了少數頂尖模型(如Qwen-32B, o3)的相對優勢領域。這可能說明,這些領先模型具備了更強的抽象推理和復雜信息整合能力,使其在處理邏輯判斷而非純粹知識檢索的難題時,能更好地維持其性能,這也反映了OneEval評測體系在篩選具有“慢思維”潛質模型方面的有效性。
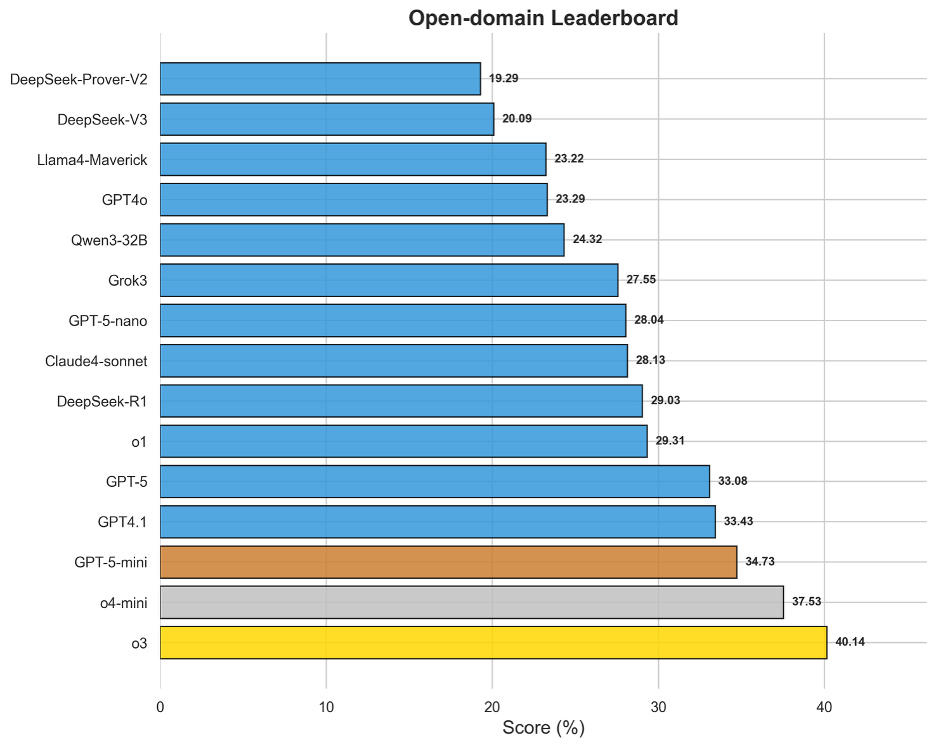
圖12 OneEval-Hard通用領域模型排名
通用域的評測結果有效地衡量了模型在無特定領域限制下的通用復雜推理能力。該榜單的領先模型,如o3(40.14%)、o4-mini(37.53%)和GPT-5-mini(34.73%),普遍是那些在行業內被認為具備強大底層邏輯和“慢思維”潛力的模型。值得注意的是,即便對于榜首的o3,其得分也剛過40%,表明在處理需要多步推演、信息整合和創造性問題解決的通用難題時,所有模型仍有提升空間。
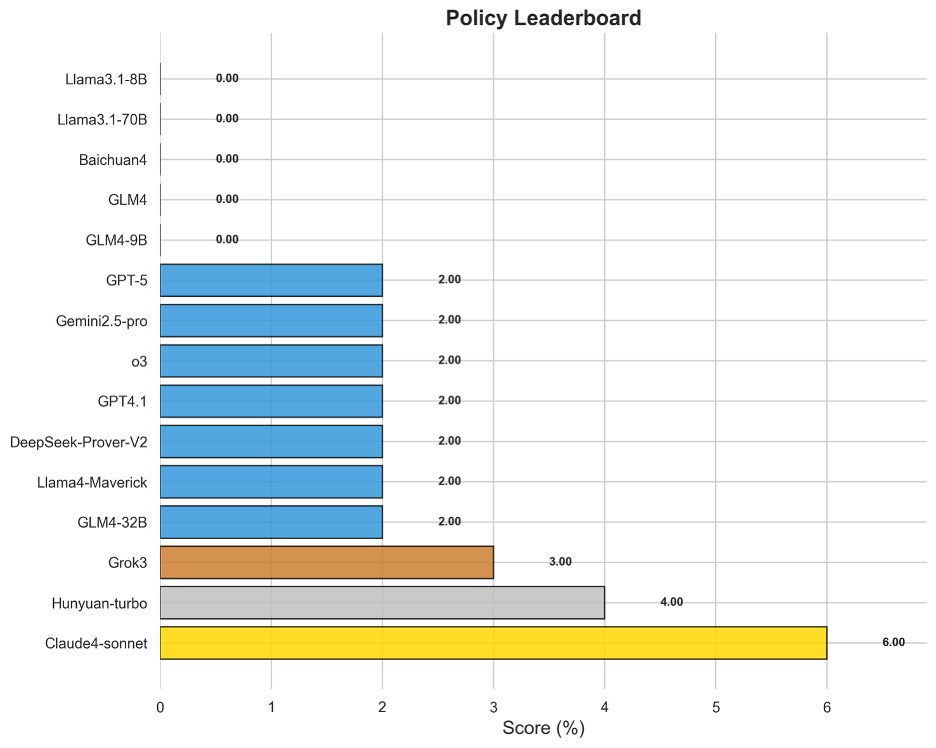
圖13 OneEval-Hard政務領域模型排名
中文政務領域的評測結果最為嚴峻,堪稱當前大模型能力的“試金石”。絕大多數模型在此項得分接近于零,即便是表現最好的Claude4-sonnet也僅獲得6.00%的得分。這毀滅性的結果有力地證明,模型在理解充滿社會背景、微妙語氣和復雜條件的政策文本方面存在根本性缺陷。政策推理不僅需要文本理解,更需要對意圖、影響和潛在沖突進行高階解讀,這種高度依賴中文語境和常識的“軟”推理能力,是當前模型架構最薄弱的環節。
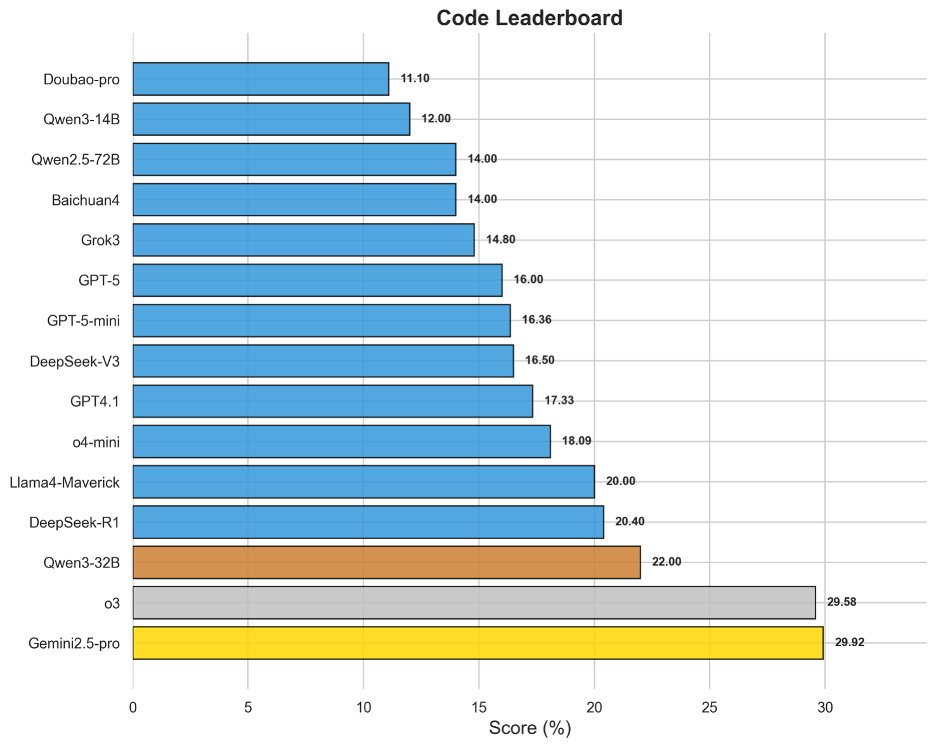
圖14 OneEval-Hard編程領域模型排名
代碼領域專注于評估模型在復雜算法理解、邏輯調試和代碼庫層面的推理能力,尤其注重模型理解各種代碼版本的細微差異,難度遠超簡單的代碼生成。Gemini2.5-pro(29.92%)和o3(29.58%)以顯著優勢位居榜首,與后續模型拉開了較大差距。Gemini系列在代碼領域的傳統優勢與o3的強大通用推理能力在此得到共同驗證。該領域榜單整體得分較低,說明將代碼作為一種形式化語言進行深度理解和操作,仍然是當前大模型技術的一大瓶頸。
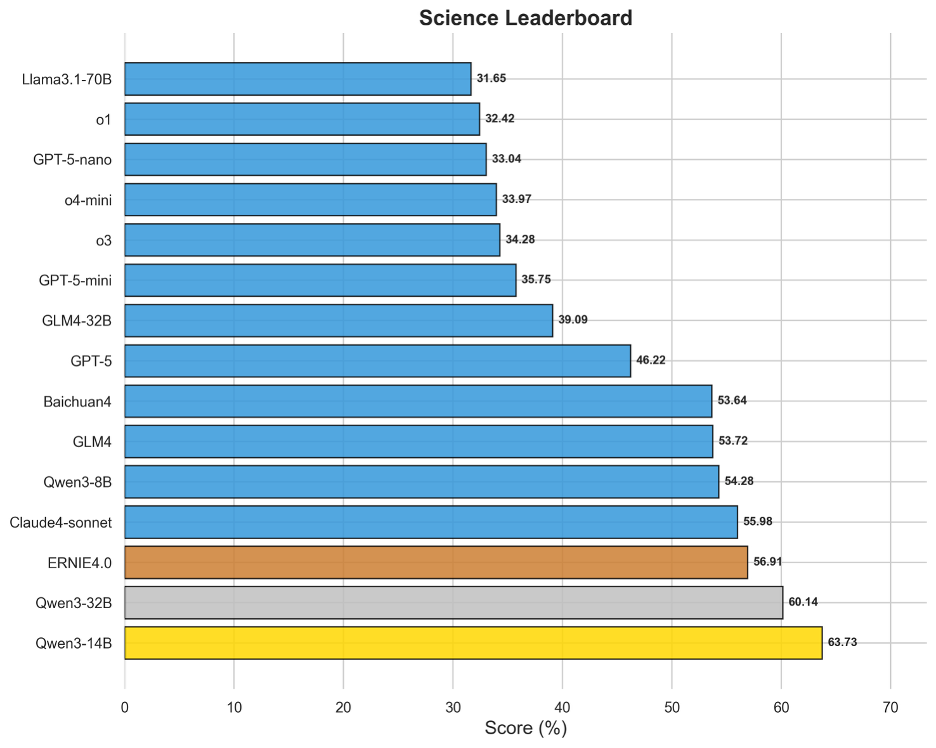
圖15 OneEval-Hard科學領域模型排名
與政策、稅務等領域形成鮮明對比,科學領域是Hard Set中模型表現最好的部分。Qwen3-14B(63.73%)和Qwen3-32B(60.14%)等模型取得了超過60%的高分,展現出強大的實力。這表明,對于基于事實、數據和嚴謹邏輯的科學問題,即使難度很高,當前領先的模型也已具備較強的解決能力。這可能得益于預訓練語料中海量的科學文獻、教科書和數據集,使得模型在理解材料學、生物學概念等定律進行推理時更為可靠。
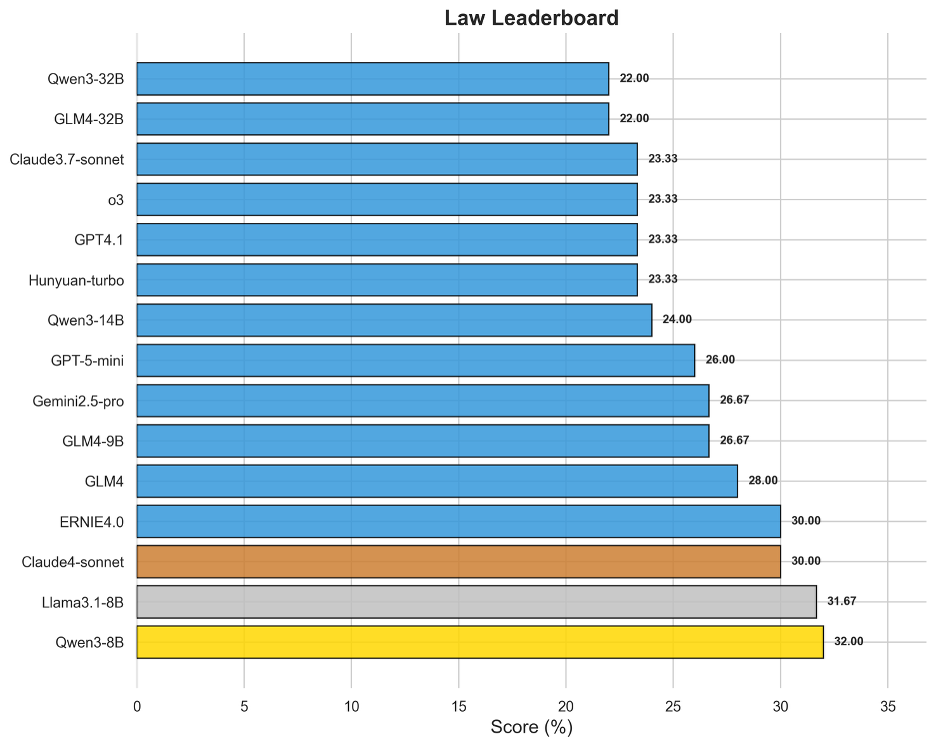
圖16 OneEval-Hard法律領域模型排名
法律領域的Hard Set評測揭示了模型在處理復雜法律條文、案例情景和邏輯悖論時的能力極限。出人意料的是,Qwen3-8B(32.00%)和Llama3.1-8B(31.67%)等規模相對較小的模型在此領域表現突出,甚至超越了許多更大規模的旗艦模型。這一現象可能表明,對于法律這種高度結構化、規則明確的領域,模型對特定語料的精深理解和對邏輯關系的精準捕捉,其重要性超過了單純的參數規模。榜單上分數普遍不高(最高僅32%)且模型間差距較小,說明深度法律推理對所有模型都是一個普遍性難題。
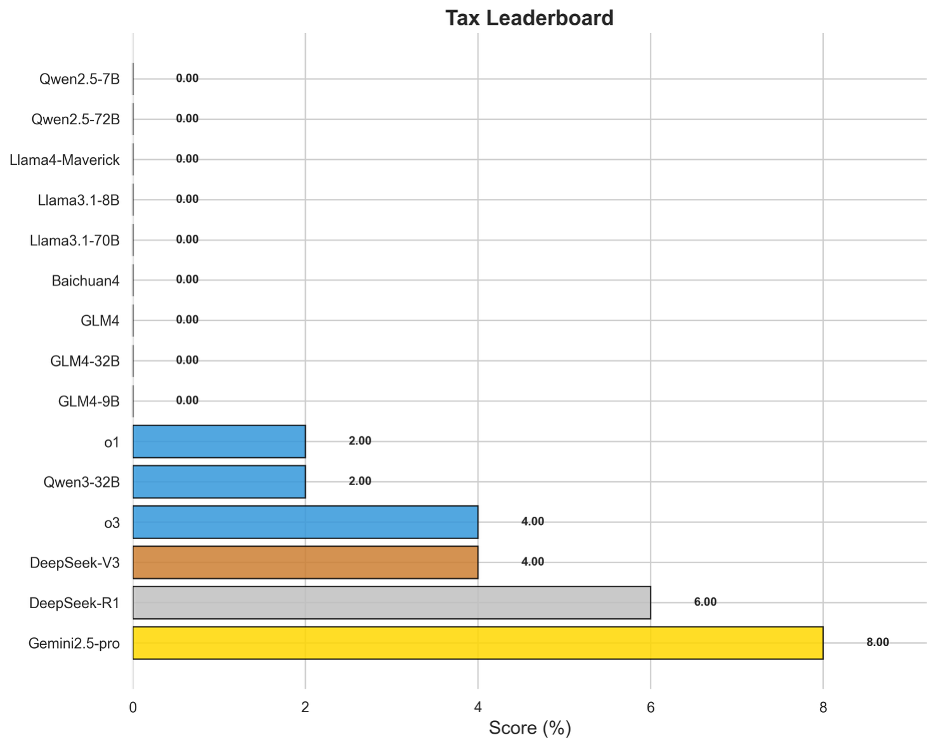
圖17 OneEval-Hard稅務領域模型排名
稅務領域的評測結果與政策領域類似,揭示了模型的另一個重大短板。榜首的Gemini2.5-pro得分僅為8.00%,而絕大多數模型無法得分。稅務任務要求模型將法律條文般的精確規則與具體的數值計算相結合,并處理大量的例外條款和前提條件。這種神經符號混合推理(結合文本理解與符號計算)的失敗表明,模型難以在長推理鏈中穩定地、精確地應用一個復雜的規則系統,這是未來模型發展需要攻克的核心技術難題。
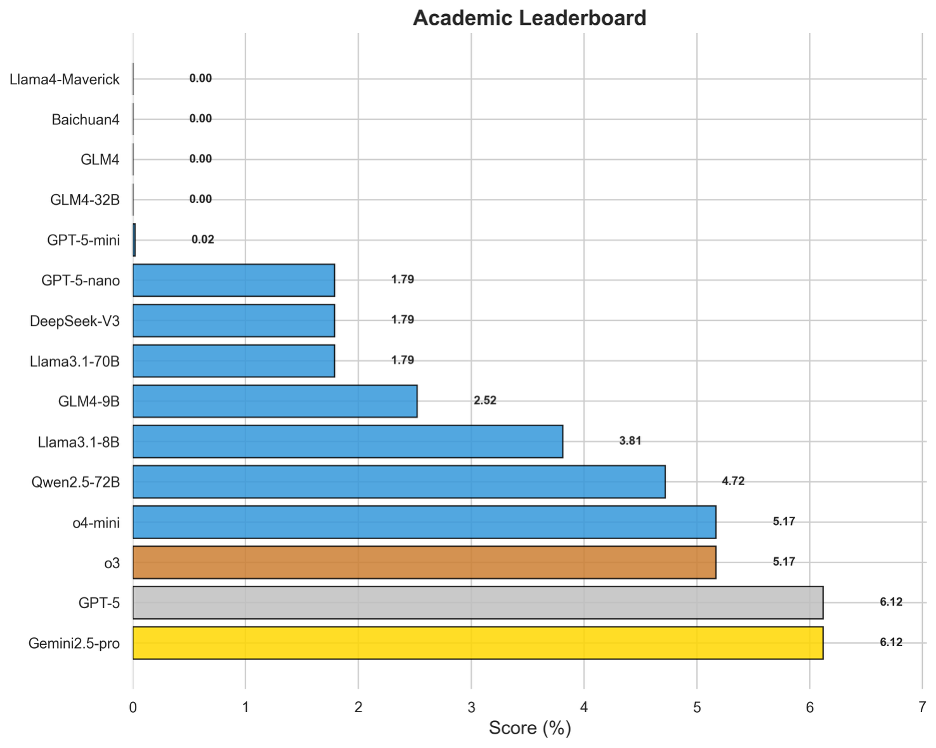
圖18 OneEval-Hard學術領域模型排名
學術領域的評測旨在考察模型對前沿、高度專業化知識的理解和推理能力。與稅務和政策領域相似,該領域的得分也極低,Gemini2.5-pro和GPT-5以6.12%并列第一。這說明,當面對最新研究論文中提出的新概念、復雜實驗和精微論證時,模型無法像人類專家那樣進行有效的“即時學習”和深度思辨。它們更多地依賴于預訓練知識的“召回”,而非真正的“理解”與“推理”,這限制了它們在科研創新輔助等前沿場景中的應用潛力。
4.7 GPT-5系列模型性能對比
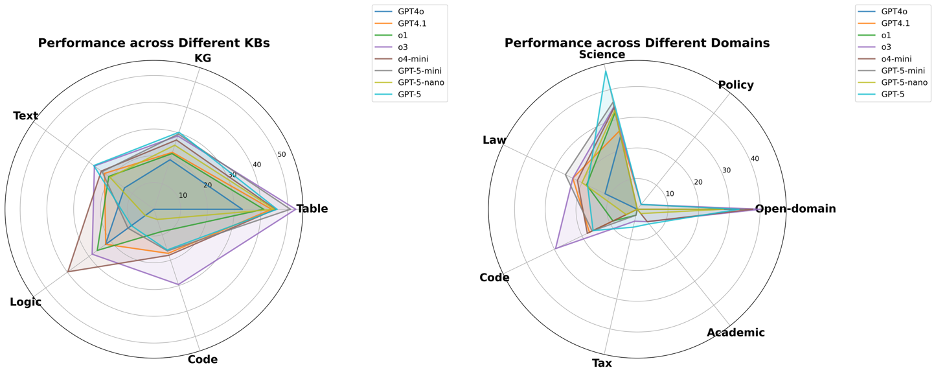
圖19 GPT系列模型性能對比
從圖19中可以看出,GPT-5系列(GPT-5, GPT-5-mini, GPT-5-nano)展現了清晰的家族化特征,即它們的性能輪廓(相對強弱項)高度相似,僅在整體能力半徑上有所區別。
GPT-5性能呈現非均衡性,并未在所有知識類型上取得領先。雷達圖顯示,旗艦模型GPT-5(淺藍色線)在文本(Text)和知識圖譜(KG)推理任務上,確實達到了OpenAI系列中的領先水平。然而,這種優勢并未延續到所有知識類型。在邏輯(Logic)、代碼(Code)和表格(Table)推理上,其表現并未顯示出決定性優勢,尤其是在邏輯和代碼知識庫的評測中,其得分甚至低于GPT-4o等部分早期版本。這表明GPT-5的能力提升并非全面性的,而是在特定推理類型上有所側重。
專業知識領域的“能力黑洞”揭示行業共同瓶頸。一個跨模型的普遍性短板是,在政務(Policy)、稅務(Tax)和學術(Academic)三個專業領域,幾乎所有頂尖模型(包括GPT-5系列)的得分都極低。這一現象揭示了當前大模型技術的共同瓶頸:即便是參數規模龐大的頂尖模型,在處理需要深度理解社會語境、遵循復雜規則進行精確演算,或對前沿專業知識進行細粒度解讀的任務時,其能力仍顯不足。
“大”不等于“強”,規模優勢在知識增強場景的推理任務上未能完全體現。一個值得關注的現象是,規模較小的GPT-5-mini在某些任務上的表現反超了旗艦級的GPT-5。具體而言,在處理邏輯(Logic)、表格(Table)、代碼(Code)等類型的知識庫,以及在法律(Law)等特定領域中,GPT-5-mini取得了更高的分數。這表明,GPT-5的巨大參數規模和通用能力,并不能直接等同于在所有專業和復雜的知識增強任務上的性能優勢。這一結果進一步佐證,提升模型的真實推理能力可能需要超越單純增加模型規模的路徑,而更需要在模型架構或訓練范式上進行更具針對性的創新。
5. 總結與展望
OneEval是一個側重于“大模型 + 知識庫(LLM+KB)”融合能力評估的評測體系。本次發布的V1.1 版本涵蓋了五種知識庫類型和七大關鍵領域,旨在全面衡量大模型的知識增強推理能力。
不同于那些一旦發布就內容固定的靜態評測集(如高考、資格考試等),大模型可以通過針對性的數據“刷題”來提升分數,OneEval從根本上挑戰了這種“應試”模式。我們的核心優勢在于評測體系的多維度動態性,這使得模型無法通過簡單的記憶或數據覆蓋來“背答案”,從而更精準地“照”出其真實的推理能力瓶頸。
展望未來,OneEval將致力于打造一個與技術發展同步演進的“活”的評測基準(Living Benchmark),其動態性主要體現在以下三個方面:
1)數據集數量的動態增加:我們將持續納入由OpenKG及社區自主研發的新評測數據集,不斷擴展評測的廣度與維度。
2)存量數據集的動態更新:我們將對現有數據集進行周期性的內容迭代與刷新,引入新的案例、數據和問題變體,確保評測的時效性。
3)基于知識圖譜的動態生成:我們將引入從大規模知識圖譜中動態采樣和生成評測樣本的機制。這意味著評測問題本身就是實時演化的,從根本上杜絕了模型“刷題”的可能性。
這種多層次的動態設計,將迫使大模型從“記憶知識”轉向“理解和運用知識”,真正考驗其在知識增強驅動下的慢思維與神經符號混合推理能力。我們期望通過這一努力,支持大模型向“知識深、思維強”的方向不斷演進。
當然,構建一個完全客觀、公正、可重復的大模型評測榜單本身就是一項極具挑戰的工作。我們充分意識到當前評測框架仍有很多不足,并在防作弊策略等方面有待進一步完善。我們期待未來能與更多研究者攜手,共同推進評測體系的持續優化,促進大模型在知識增強與推理能力方面不斷進步。
6. 評測組織
OneEval 評測由 OpenKG.SIGEval(官網:http://openkg.cn/sigeval/)組織發起,參與單位包括東南大學認知智能研究所、浙江大學知識引擎實驗室、同濟大學知識計算實驗室以及蘇州大學自然語言處理實驗室、東南大學未來法治與數智技術創新實驗室。詳細人員列表如下所示:
組織人:
漆桂林 教授 東南大學
陳華鈞 教授 浙江大學
王昊奮 教授 同濟大學
陳文亮 教授 蘇州大學
主要評測人員:
陳永銳 博士后 東南大學
丁科炎 研究員 浙江大學
王奕淞 碩士 同濟大學
評測報告校對人:
吳天星 副教授 東南大學
張文 副教授 浙江大學
畢勝 講師 東南大學
技術支持與維護:
鄧鴻杰 浙江大學
數據貢獻與實驗:
劉治強 浙江大學
喻靖 浙江大學
吳桐桐 Monash University
胡楠 東南大學
戴鑫邦 東南大學
任林 東南大學
康家溱 東南大學
劉佳俊 東南大學
談川源 蘇州大學
參考文獻
[1] Hendrycks D, Basart S, MuJavidy M, et al. Measuring Massive Multitask Language Understanding[C]//?ICLR. 2021.
[2] Li H, Zhang Z, Zhang B, et al. CMMLU: Measuring massive multitask language understanding in Chinese[C]//?ACL. 2023.
[3] Huang Y, Yue Y, Yuan Z, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models[C]//?NeurIPS. 2023.
[4] Zhong W, Zhou S, Yao J, et al. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models[C]//?NAACL. 2024.
[5] Zeng Z, Shen K, Liu Z, et al. Evaluating Large Language Models at Evaluating Instruction Following[C]//?ICLR. 2024.
[6] Longpre S, Hou L, Beever A, et al. The flan collection: Designing data and methods for effective instruction tuning[C]//?ICML PMLR. 2023.
[7] Mishra S, Khashabi D, Baral C, et al. Cross-Task Generalization via Natural Language Crowdsourcing Instructions[C]//?ACL. 2022.
[8] Reddy S, Chen D, Manning C D. Coqa: A conversational question answering challenge[J].?TACL. 2019.
[9] Feng J, Zhang Z, Li X, et al. MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation[C]//?ACL. 2023.
[10] Zheng L, Chiang W, Ying H, et al. Judging llm-as-a-judge with mt-bench and chatbot arena[C]//?NeurIPS. 2023.
[11] K?pf A, Kilcher Y, von Werra L, et al. Openassistant conversations-democratizing large language model alignment[C]//?NeurIPS. 2023.
[12] Wang B, Chen H, Zhang Z, et al. DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models[C]//?NeurIPS. 2023.
[13] Wang B, Chen H, Xu C, et al. Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models[C]//?NeurIPS. 2023.
[14] Souly A, Sreedhar K, Das S. A StrongREJECT for Empty Jailbreaks[C]//?ICLR?Workshop. 2024.
[15] Mazeika M, Phan L, Stoker A, et al. HarmBench: a standardized evaluation framework for automated red teaming and robust refusal[C]//?ICML. 2024.
[16] Fourrier, Clémentine, et al. Open LLM Leaderboard v2. 2024, Hugging Face,https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard.
[17] OpenCompass Contributors. OpenCompass: A Universal Evaluation Platform for Foundation Models. 2023, https://github.com/open-compass/opencompass.
[18] Chiang, Wei-Lin, et al. "Chatbot arena: An open platform for evaluating llms by human preference."?ICML. 2024.
[19] Dubois, Yann, et al. "Length-controlled alpacaeval: A simple way to debias automatic evaluators." arXiv preprint arXiv:2404.04475 (2024).
[20] Li, Yijiang, et al. "Core knowledge deficits in multi-modal language models."?arXiv preprint arXiv:2410.10855?(2024).
OpenKG
OpenKG(中文開放知識圖譜)旨在推動以中文為核心的知識圖譜數據的開放、互聯及眾包,并促進知識圖譜算法、工具及平臺的開源開放。

點擊閱讀原文,進入 OpenKG 網站。




技術支持高速串行數據傳輸,支持1080p/60Hz高分辨率傳輸)


)
 ——通用端口)



=>UAC+STM32 ADC+PWM實現錄音和播放)
)




)
