RAG初步實戰:從 PDF 到問答:我的第一個輕量級 RAG 系統
項目背景與目標
在大模型逐漸普及的今天,Retrieval-Augmented Generation(RAG,檢索增強生成)作為連接“知識庫”和“大語言模型”的核心范式,為我們提供了一個高效、實用的路徑。為了快速學習RAG的原理,并掌握它的使用方法,我在這開發了一個pdf問答項目
這個項目的初衷,就是以“本地知識問答系統的動手實踐”為目標,系統學習并串聯以下幾個關鍵知識模塊:
? 學習目標
| 模塊 | 學習重點 |
|---|---|
| 文檔解析 | 如何從 PDF 文檔中提取結構化文本,并保留元數據(如頁碼) |
| 文本向量化 | 使用中文 embedding 模型,將自然語言轉為向量表征 |
| 向量存儲與檢索 | 搭建本地 FAISS 向量數據庫,掌握向量的存儲、檢索與匹配機制 |
| 前端交互 | 使用 Streamlit 構建簡單前端,實現交互式問答體驗 |
📌 項目特色
無需翻墻、全本地運行:選用了國內可用的向量化模型和 API 服務,便于部署。
完整鏈路閉環:從 PDF → Chunk → 向量化 → 檢索 → 語言模型生成,一步不落。
結構清晰、易于拓展:代碼結構模塊化,方便后續更換模型、接入多個文檔等。
🧩 項目適合人群
想學習 RAG 工作流程的開發者或學生
需要本地構建問答系統但不方便翻墻的用戶
想搭建個人知識庫搜索問答助手的 AI 學習者
技術架構概覽
↓ 文本切分
📜 Chunk 文本 + 元信息↓ 向量化 Embedding(中文模型)
🔍 FAISS 向量數據庫↓ 向量相似度匹配(Top-K)
🔁 提取匹配段落(內容 + 元數據)↓ 拼接上下文 Prompt
🧠 百煉智能體 API(對話生成)↓
🧾 用戶界面展示(Streamlit)
模塊拆解與組件說明
| 模塊 | 使用組件 | 功能說明 |
|---|---|---|
| 文檔解析 | PyMuPDF(或 fitz) | 從 PDF 中按頁讀取文本,并保留頁碼信息等元數據 |
| 文本切分 | LangChain | 將每頁文本按段落或長度切分為小塊,提高語義粒度 |
| 向量化 | bge-small-zh 模型(HuggingFace) | 將 Chunk 文本轉為 512 維向量,用于語義匹配 |
| 向量存儲 | FAISS 本地向量庫 | 構建并保存索引,實現快速相似度搜索 |
| 前端交互 | Streamlit | 提供簡單直觀的問答界面,支持用戶輸入與響應展示 |
模塊之間的關系
向量數據庫只保存向量 + 元數據,不保存完整語義;
每次用戶輸入時,實時提取向量、進行檢索并構造上下文 Prompt;
構造后的 Prompt 被送入百煉智能體模型進行回復生成;
Streamlit 前端實時展示問答結果,形成閉環。
核心工具與模型選型
在本項目中,為了實現從 PDF 文檔中提取段落,并基于語義進行匹配和問答的功能,選用了以下核心工具鏈與模型組件,確保系統具有較高的效率、準確性以及良好的可擴展性。
🧠 1. Embedding 模型:BAAI/bge-small-zh
| 項目 | 內容 |
|---|---|
| 模型名稱 | BAAI/bge-small-zh |
| 模型來源 | HuggingFace @ BAAI |
| 是否開源 | ? 是 |
| 支持語言 | 中文(優化) |
| 部署方式 | 本地部署(無需聯網,免翻墻) |
| 模型體積 | 小型(約 120MB) |
| 向量維度 | 512 |
| 優勢亮點 | 輕量、高速、適配中文語義匹配任務 |
| 調用方式 | 封裝在 embedding.py 文件中,定義了 EmbeddingModel.embed_texts() 接口用于段落向量化處理 |
🧮 2. 向量數據庫:FAISS
| 項目 | 內容 |
|---|---|
| 名稱 | FAISS(Facebook AI Similarity Search) |
| 作用 | 存儲并檢索高維向量(用于語義匹配) |
| 部署方式 | 本地離線,使用 .index 和 .meta 文件存儲數據 |
| 使用方式 | 在 vector_store.py 中封裝了 VectorStore 類,實現:? add() 向數據庫添加向量與原始文本? save()/load() 存儲與加載? search() 執行相似度檢索 |
| 匹配方式 | L2 距離(歐氏距離)索引器 IndexFlatL2 |
📚 3. 文本切分工具:LangChain TextSplitter
| 項目 | 內容 |
|---|---|
| 工具模塊 | RecursiveCharacterTextSplitter |
| 來源 | LangChain |
| 作用 | 將原始 PDF 文檔內容切分成多個適配 embedding 的小段(chunk) |
| 分段策略 | 使用換行符、標點符號等多級分隔符,避免語義斷裂 |
| 使用方式 | 在 rag_chain.py 的 load_and_split_pdf() 中使用 |
🖼 5. 可視化界面框架:Streamlit
| 項目 | 內容 |
|---|---|
| 框架名稱 | Streamlit |
| 用途 | 構建簡潔交互式 Web 應用界面 |
| 使用方式 | 主入口文件 app.py,支持用戶輸入問題、展示檢索段落與大模型生成回復 |
核心功能實現詳解
📄 1. PDF 文檔加載與切分
文件:rag_chain.py
函數:load_and_split_pdf()
? 實現目標:
將整本 PDF 文檔切分為可用于語義匹配的文本段(chunk),避免段落過長或斷句不清導致 embedding 表達質量下降。
🔍 2. 文本向量化(Embedding)
文件:embedding.py
類名:EmbeddingModel
? 實現目標:
將每段文本轉為稠密語義向量(float32),便于后續進行語義匹配檢索。
? 模型選型:
使用 HuggingFace 上的 BAAI/bge-small-zh 本地模型,支持中文語義精度較高。
🧠 3. 向量數據庫構建與檢索
文件:vector_store.py
類名:VectorStore
? 實現目標:
將文本對應的向量存入 FAISS 數據庫;
支持向量相似度檢索,返回與用戶 query 最相近的段落及其元信息。
? 數據結構:
.index 文件:存儲 FAISS 索引(支持快速相似度查詢)
.meta 文件:存儲 chunk 原文與元數據(如頁碼)
? 核心方法:
add(texts, vectors, metadatas)
save() / load()
search(query, top_k)
🤖 4. 問答生成:接入百煉智能體 API
文件:baichuan_llm.py
類名:DashScopeChatBot
? 實現目標:
組合用戶問題與匹配段落,通過大模型生成符合上下文的回答。
項目目錄結構說明
rag_demo/
├── app.py # 主入口,基于 Streamlit 的問答交互界面
├── embedding.py # 文本向量化模塊,封裝 BGE-small-zh 模型
├── vector_store.py # 自定義向量數據庫類,基于 FAISS 實現
├── rag_chain.py # 文檔加載與切分工具,支持 PDF 預處理
├── baichuan_llm.py # 調用百煉智能體(Bailian)生成問答內容
├── docs/ # 存放用戶上傳或處理的 PDF 文檔
│ └── example.pdf # 示例 PDF 文件
├── faiss_index.index # FAISS 索引文件(自動生成,保存向量索引)
├── faiss_index.meta # FAISS 元信息文件(保存每段文本及頁碼)
└── README.md # 項目說明文檔
📌 各模塊說明
| 文件 / 目錄 | 類型 | 作用描述 |
|---|---|---|
app.py | 主程序 | 啟動 Streamlit 應用,支持用戶輸入與問答 |
embedding.py | 模型封裝 | 加載本地 BAAI/bge-small-zh 模型,并執行文本向量化 |
vector_store.py | 數據管理 | 構建、查詢、保存 FAISS 向量數據庫 |
rag_chain.py | 工具模塊 | 加載 PDF 并使用智能分段切割為 chunk |
baichuan_llm.py | 模型調用 | 調用百煉智能體 API,生成基于文檔內容的回答 |
docs/ | 文檔目錄 | 存放所有待處理的 PDF 文件 |
faiss_index.index | 索引數據 | FAISS 保存的向量索引二進制文件 |
faiss_index.meta | 元信息 | 存儲每段文本的原文及其元數據(如頁碼) |
README.md | 文檔 | 項目的功能與使用說明 |
主要文件內容
app.py
import streamlit as st
from vector_store import VectorStore
import os# 設置頁面標題
st.set_page_config(page_title="RAG 問答助手", layout="wide")# 標題
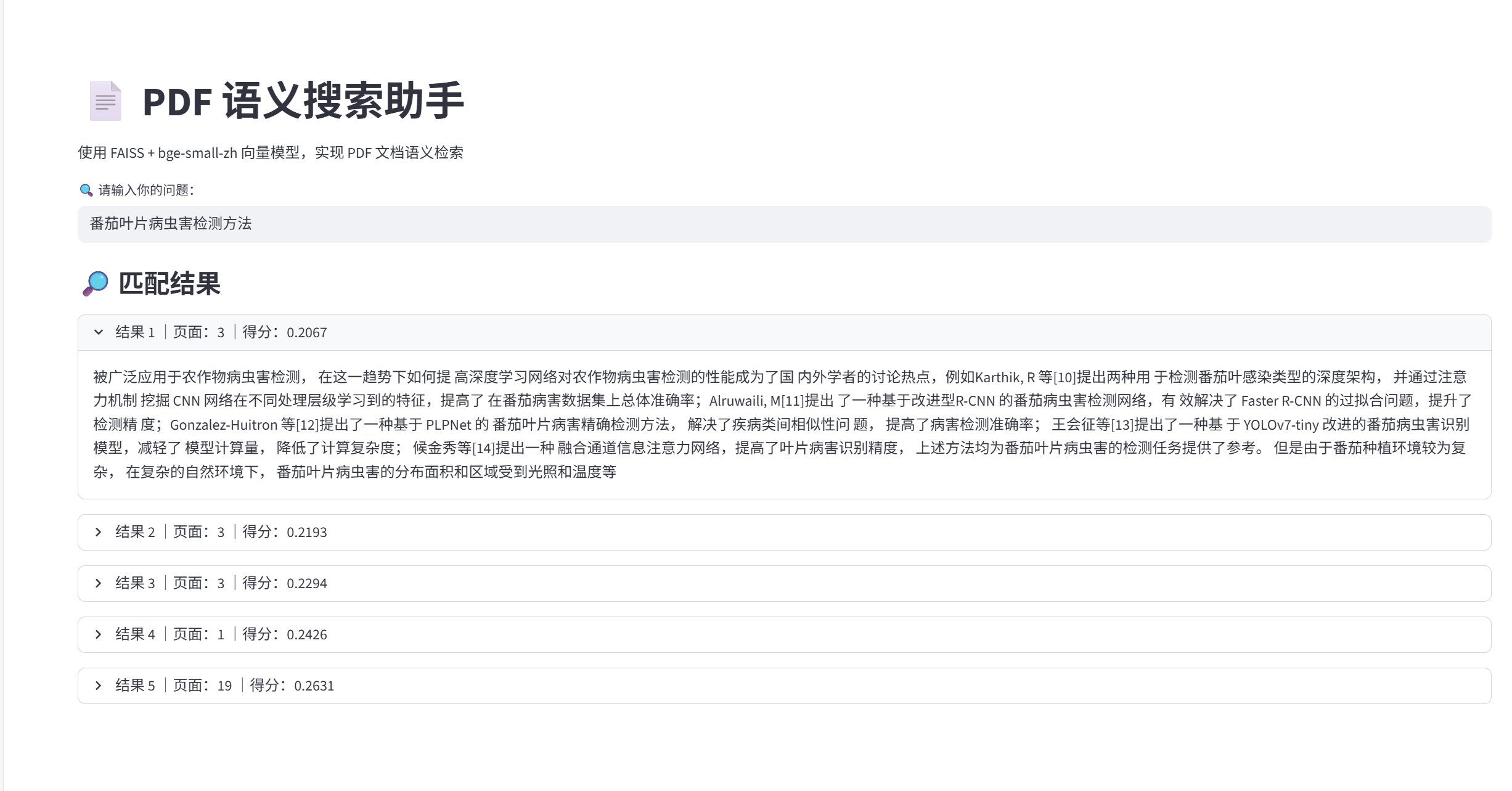
st.title("📄 PDF 語義搜索助手")
st.markdown("使用 FAISS + bge-small-zh 向量模型,實現 PDF 文檔語義檢索")# 加載向量庫
@st.cache_resource
def load_vector_store():store = VectorStore()store.load()return store# 主入口
def main():store = load_vector_store()# 用戶輸入user_query = st.text_input("🔍 請輸入你的問題:", placeholder="例如:番茄葉片檢測方法有哪些?")# 查詢結果if user_query:results = store.search(user_query, top_k=5)st.subheader("🔎 匹配結果")for i, (text, meta, score) in enumerate(results):with st.expander(f"結果 {i+1} |頁面:{meta.get('page_label', '未知')} |得分:{score:.4f}"):st.write(text)# 運行主程序
if __name__ == "__main__":main()embedding.py
from sentence_transformers import SentenceTransformer
from typing import List
import osclass EmbeddingModel:def __init__(self, model_name: str = "BAAI/bge-small-zh"):print("? 正在加載 embedding 模型,請稍候...")self.model = SentenceTransformer(model_name)print("? 模型加載完成:", model_name)def embed_texts(self, texts: List[str]) -> List[List[float]]:# 進行批量編碼(text → vector)embeddings = self.model.encode(texts, show_progress_bar=True)return embeddings# ? 示例調用代碼
if __name__ == "__main__":# 示例文本sample_texts = ["人工智能正在改變世界。","番茄葉片病蟲害檢測方法研究","LangChain 是一個強大的 RAG 框架。"]# 實例化模型embedder = EmbeddingModel()# 獲取向量vectors = embedder.embed_texts(sample_texts)for i, vec in enumerate(vectors):print(f"\n🔹 文本 {i + 1} 的向量維度: {len(vec)},前 5 維預覽: {vec[:5]}")rag_chain.py
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import osdef load_and_split_pdf(pdf_path: str, chunk_size=500, chunk_overlap=50):# 加載 PDF 文檔(每一頁為一個 Document)loader = PyPDFLoader(pdf_path)pages = loader.load()# 使用遞歸切割器分段(可按字符長度+換行符智能分段)splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlap,separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""])# 對每一頁內容進行切割,保留 metadatadocuments = splitter.split_documents(pages)return documents# ? 測試運行入口
if __name__ == "__main__":test_pdf_path = r"D:\Desktop\AI\rag_demo\docs\RT-TLTR番茄葉片病蟲害檢測方法研究_胡成峰.pdf" # 請確保路徑正確if not os.path.exists(test_pdf_path):print(f"? 文件未找到:{test_pdf_path}")else:chunks = load_and_split_pdf(test_pdf_path)print(f"? 共切分出 {len(chunks)} 個段落\n")# 打印前 3 個 chunk 的內容與元信息for i, chunk in enumerate(chunks[:3]):print(f"🔹 Chunk {i + 1}")print("內容片段:", chunk.page_content[:200].replace("\n", " ") + "...")print("元信息:", chunk.metadata)print("-" * 60)vector_store.py
import faiss
import os
import numpy as npimport pickle
from typing import List, Tuple
from embedding import EmbeddingModel
from langchain_core.documents import Documentclass VectorStore:def __init__(self, dim: int = 512, db_path: str = "faiss_index"):self.dim = dimself.db_path = db_pathself.index = faiss.IndexFlatL2(dim) # L2 距離索引器self.texts = [] # 存儲 chunk 原文self.metadatas = [] # 存儲 chunk 的元信息def add(self, texts: List[str], vectors: List[List[float]], metadatas: List[dict]):self.index.add(np.array(vectors).astype("float32"))self.texts.extend(texts)self.metadatas.extend(metadatas)def save(self):faiss.write_index(self.index, f"{self.db_path}.index")with open(f"{self.db_path}.meta", "wb") as f:pickle.dump({"texts": self.texts, "metadatas": self.metadatas}, f)print(f"? 向量數據庫已保存到:{self.db_path}.index / .meta")def load(self):self.index = faiss.read_index(f"{self.db_path}.index")with open(f"{self.db_path}.meta", "rb") as f:meta = pickle.load(f)self.texts = meta["texts"]self.metadatas = meta["metadatas"]print("? 向量數據庫已加載")def search(self, query: str, top_k: int = 3) -> List[Tuple[str, dict, float]]:embedder = EmbeddingModel()query_vec = embedder.embed_texts([query])[0]D, I = self.index.search(np.array([query_vec]).astype("float32"), top_k)results = []for idx, dist in zip(I[0], D[0]):results.append((self.texts[idx], self.metadatas[idx], dist))return results# ? 測試入口
if __name__ == "__main__":import numpy as npfrom rag_chain import load_and_split_pdf# 1. 加載 PDF 并切分docs: List[Document] = load_and_split_pdf(r"D:\Desktop\AI\rag_demo\docs\RT-TLTR番茄葉片病蟲害檢測方法研究_胡成峰.pdf")texts = [doc.page_content for doc in docs]metadatas = [doc.metadata for doc in docs]# 2. 向量化embedder = EmbeddingModel()vectors = embedder.embed_texts(texts)# 3. 存入 FAISS 向量庫store = VectorStore()store.add(texts, vectors, metadatas)store.save()# 4. 進行語義搜索store.load()results = store.search("番茄葉片檢測方法")for i, (txt, meta, score) in enumerate(results):print(f"\n🔍 匹配結果 {i + 1}:")print("得分:", score)print("頁面:", meta.get("page_label", "N/A"))print("內容片段:", txt[:200], "...")查詢算法解析:基于 FAISS 的 L2 距離向量檢索
query_vec = embedder.embed_texts([query])[0]功能:將用戶輸入的自然語言 query 通過 embedding 模型轉化為一個向量(query_vec)。
底層模型:你使用的是 BAAI/bge-small-zh,輸出的是一個 512 維的向量。
D, I = self.index.search(np.array([query_vec]).astype("float32"), top_k)功能:調用 FAISS.IndexFlatL2 的 search() 方法,返回:
D:每個候選結果與 query 向量之間的 L2 距離(歐氏距離平方);
I:每個距離對應的原始文本在庫中的索引位置。
底層算法:暴力遍歷全部向量,通過 歐幾里得距離(L2) 找出最近的 top_k 個向量
項目成果演示
📌 項目成果演示
本項目最終實現了一個可交互的 PDF 文檔語義問答系統,集成了 Streamlit 頁面、FAISS 向量數據庫、中文 embedding 模型(bge-small-zh)和文檔切分等組件,具備了完整的 RAG(Retrieval-Augmented Generation)基礎架構。以下為演示亮點:
總結與思考
📌 項目總結
本項目以“從0搭建一個輕量級 RAG(Retrieval-Augmented Generation)語義搜索原型系統”為目標,圍繞 LangChain 的文檔處理工具鏈,結合 HuggingFace 本地向量化模型 BAAI/bge-small-zh 和高效的向量數據庫 FAISS,完成了一個完整閉環的流程:
? 從 PDF 文檔中提取文本并進行智能切分;
? 使用本地 embedding 模型對文本塊進行向量化;
? 構建 FAISS 本地向量數據庫,實現高效查詢;
? 使用 Streamlit 實現簡單而直觀的交互頁面;
? 支持全中文處理,部署門檻低、響應速度快、成本接近為零。
該項目在結構上清晰、功能上實用,非常適合初學者上手 RAG 系統構建,同時也具備進一步拓展 LLM 調用、問答生成、多文檔多模態處理等能力的基礎。
💡 學習思考
向量檢索系統構建并不復雜,但細節決定效果:
文本的切分策略對匹配質量有很大影響;
向量化模型選擇直接決定語義召回質量;
搜索算法(如使用 FAISS 的 L2 距離)雖簡單,但結果解釋性差,需合理展示。
本地部署是理解 RAG 的最好方式:
避免過度依賴 API,提升系統理解力;
便于調試 embedding 模型、切分器、檢索邏輯等各個組件;
有助于構建對 embedding 語義空間的直覺認識。
國產 embedding 模型正在崛起:
像 bge-small-zh、acge_text_embedding、FlagEmbedding 等模型已經在中文語義匹配上達到非常好的效果;
對于輕量級任務,small 版本完全夠用,延遲低、精度可接受。
向量數據庫并不是黑盒:
像 FAISS 支持查看索引結構、手動添加/查詢/刪除向量;
元數據(如頁面編號)可以與結果綁定,極大增強可解釋性。
🚀 后續方向
集成 LLM,構建基于召回結果的回答生成(即真正的 RAG 問答);
支持多文檔、多格式(txt/doc/html)的語義索引;
引入關鍵詞過濾、正則抽取等補充匹配方式;
調整 UI,支持多輪對話式語義問答。

- 連接)















)

