了解機器學習
1、什么是機器學習
機器學習是一門通過編程讓計算機從數據中進行學習的科學
通用定義:機器學習是一個研究領域讓計算機無須進行明確編程就具備學習能力
工程化定義:一個計算機程序利用經驗E來學習任務T,性能是P,如果針對任務T的性能P隨著經驗E不斷增長,則稱為機器學習
系統用來學習的樣例稱為訓練集
每個訓練樣例稱為訓練實例(或樣本)
機器學習系統中學習和做出預測的部分稱為模型
正例:垃圾郵件過濾器,可以根據給定的垃圾郵件(由用戶標記)和普通電子郵件(非垃圾郵件)學習標記垃圾郵件。
在這個示例中,任務T:標記新郵件是否為垃圾郵件,
經驗E:訓練數據(之前大量的數據郵件),需要定義性能度量P
例如,可以使用正確分類電子郵件的比率,這種性能指標稱為精度,用于分類任務。
反例:可以下載所有百度百科文章到電腦,這樣計算機會擁有很多數據,但它不會擅長任何任務,這不是機器學習
2、傳統流程和機器學習開發流程對比
| 傳統開發流程 | 機器學習的開發流程 |
|---|---|
| 明確需求和規則(但一般情況下規則寫不全) | 收集數據 |
| 寫程序 | 預處理數據 |
| 測試調試(難以泛化,容易誤判) | 訓練模型(自動從數據中學習規則) |
| 修復bug(高誤判/漏判風險) | 調整模型參數、估計性能(從多樣化樣本中學習泛化特征) |
| 上線維護(難以維護,需要反復更新) | 部署模型,收集反饋再訓練(模型再訓練,自我改進) |
3、總結
機器學習非常適合:
1. 現有解決方案需要大量微調或一長串規則來解決的問題 (通過訓練模型簡化代碼,而且比傳統方法執行的更好)
2. 使用傳統方法無法解決的復雜問題,但機器學習技術可能可以找到解決方法 (識別圖片里是否有行人;自動標出圖片里行人出現的區域)
3. 變化的環境(機器學習系統可以很容易地根據新數據重新訓練,保持最新的狀態)
4. 定義明確的復雜問題(不是通過定義規則能解決的),且有大量數據
機器學習的類型
一、按數據反饋形式分類
定義模型如何從數據中學習
1、無監督學習
無監督學習的訓練數據是未標記的(也就是沒有任何標簽、明確分類的信息)發現數據內在結構,以下是幾種無監督學習的任務和例子:
(1)聚類算法(層次聚類算法)
假設你有大量關于博客訪客的數據。你可能想要運行聚類算法來檢測相似訪客的分組。你不會告訴算法訪客屬于哪個組:它無須你的幫助即可找到這種關聯。
例如,它可能會注意到40%的訪客是喜歡漫畫書的青少年,通常在放學后閱讀你的博客,而20%的訪客是喜歡科幻小說的成年人,并通常在周末訪問。如果你使用層次聚類算法,它還可以將每個組細分為更小的組。這可以幫助你針對不同的組來發布博客內容。
(2)可視化算法
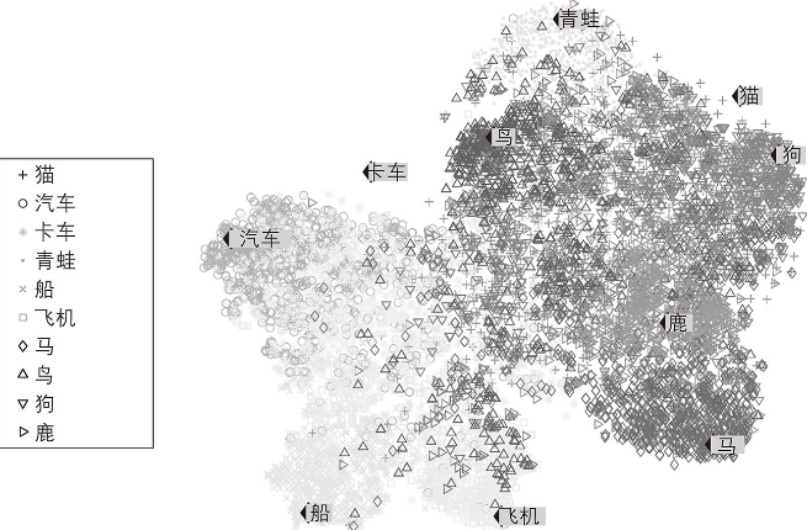
你提供大量復雜且未標記的數據,算法輕松繪制輸出2D或3D的數據表示。這些算法試圖盡可能多地保留結構(例如,試圖防止輸入空間中的單獨集群在可視化中重疊),以便于你可以了解數據的組織方式,并可能識別出一些未知的模式、趨勢和異常。
這張圖相當于將詞轉化為空間中的向量,通過可視化看出詞與詞之間的相似程度,但沒有具體將他們區分出來
(3)降維
降維,其目標是在不丟失太多信息的情況下簡化數據。一種方法是將幾個相關的特征合并為一個。
例如,一輛汽車的行駛里程可能與其車齡有很強的相關性,因此降維算法會將它們合并為一個代表汽車磨損的特征。這稱為特征提取。
在將訓練數據提供給另一個機器學習算法(例如監督學習算法)之前,先使用降維算法減少訓練數據的維度通常是個好主意。算法會運行得更快,數據會占用更少的磁盤和內存空間,并且在某些情況下,它還可能表現得更好。
(4)異常檢測
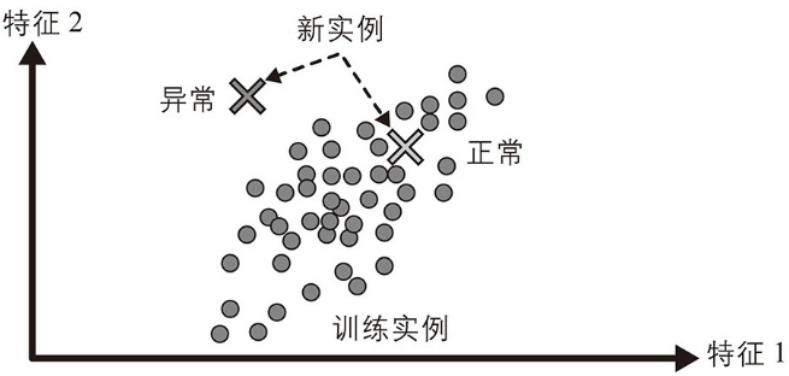
異常檢測是一種識別數據中顯著偏離正常模式的樣本或事件的技術。這些異常可能是由錯誤、欺詐、故障、罕見事件或其他特殊原因引起的。
例如,檢測異常的信用卡交易來防止欺詐、發現制造缺陷,或者在將數據集提供給另一個學習算法之前自動從數據集中刪除異常值。系統在訓練期間主要使用正常實例,因此它會學習識別它們。然后,當看到一個新實例時,系統可以判斷這個新實例看起來是正常的還是異常的。
(5)新穎性檢測
它旨在檢測看起來與訓練集中所有實例不同的新實例。這需要有一個非常“干凈”的訓練集,沒有任何你希望算法能夠檢測到的實例。
例如,如果你有幾千張狗的照片,其中1%代表吉娃娃犬,那么新穎性檢測算法不應將吉娃娃犬的新圖片視為新穎,將貓的照片視為新穎。但是,異常檢測算法可能認為這些狗非常稀有并且與其他狗如此不同,以至于可能會將它們歸類為異常。
(6)關聯規則學習
其目標是挖掘大量數據并發現屬性之間有趣的關系。
例如,假設你開了一家超市,在銷售日志上運行關聯規則可能會發現購買燒烤醬和薯片的人也傾向于購買牛排。因此,你可能希望將這幾樣商品擺放得更近一些。
2、監督學習
監督學習的核心特點是理由帶有標簽的數據訓練模型,學習從輸入特征到輸出標簽的映射關系。以下是監督學習的主要任務:
(1)分類(Classification)
其目標是學習輸入的特征和標簽之間的關系,從而能夠根據新輸入的特征,得到正確的分類結果。
文章開頭所介紹的垃圾郵件分類就是典型的分類任務,根據已經有的數據學習垃圾郵件的特征,之后判斷一封郵件是垃圾郵件還是正常郵件
常用的算法:邏輯回歸(logisitic)、決策樹、支持向量機、隨機森林、神經網絡
評估指標:精確率、召回率、F1分數、ROC曲線
(2)回歸(Regression)
回歸任務的目標是預測連續的數值,而不是離散類別。
典型的應用場景是:房價的預測。根據房屋面積、位置、型號等特征來預測房價。
常用的算法:線性回歸(linear)、嶺回歸(Ridge)、套索回歸(Lasso)、支持向量機回歸(SVR)、梯度提升數
評估指標:均方誤差(MSE)、均方根誤差(RMSE)、平均絕對誤差(MAE)、分數(越接近)越好
(3)結構化輸出
結構化輸出任務的輸出不是簡單的類別或數值,而是復雜的結構化數據。(例如:序列、圖結構、空間結構)
典型的應用場景及方法:從文本中識別人名、地點等(條件隨機場(CRF))機器翻譯(Seq2Seq)、目標檢測(YOLO、SSD)、語音識別(RNN+CTC)
評估方法:序列任務:使用BLEU(機器翻譯)、PER(語音識別)、F1(NER)。目標檢測:使用mAP(Mean Average Precision)衡量檢測精度。
3、自監督學習
機器學習的另一種方法可以是從完全未標記的數據集生成完全標記的數據集。同樣,一旦標記了整個數據集,就可以使用任何監督學習算法。這種方法稱為自監督學習。
例如,如果你有一個很大的未標記圖像數據集,你可以隨機屏蔽每個圖像的一小部分,然后訓練一個模型來恢復出原始圖像。在訓練期間,屏蔽的圖像用作模型的輸入,原始圖像用作標簽。生成的模型本身可能非常有用。例如,修復損壞的圖像或從圖片中刪除不想要的對象。但通常情況下,使用自監督學習訓練的模型并不是你的最終目標。你通常需要針對稍微不同的任務(你真正關心的任務)來調整和微調模型。
例如,假設你真正想要的是一個寵物分類模型:給定一張寵物的照片,模型會告訴你這只寵物屬于什么物種。如果你有大量未標記的寵物照片數據集,則可以先使用自監督學習來訓練一個圖像修復模型。如果模型表現良好,則它應該能夠區分不同的寵物種類:當它修復一張蒙著臉的貓的圖像時,它必須知道不要添加狗的臉。假設你的模型架構允許,那么你就可以調整模型,使它能預測寵物種類而不是修復圖像。最后一步是在已標記的數據集上微調模型:模型已經知道貓、狗和其他寵物的樣子,因此只需要這個步驟,模型就可以學習它已知的物種和我們期望從中得到的標簽之間的映射。

有些人認為自監督學習是無監督學習的一部分,因為它處理的是未標記的數據集。但是 自監督學習在訓練期間是使用(生成的)標簽的,因此在這方面它更接近于監督學習。在處理聚類、降維或異常檢測等任務時,通常會使用術語“無監督學習”?,而自監督學習側重于與監督學習相同的任務,主要是分類和回歸。最好將自監督學習視為一個單獨的類別。
4、強化學習
其核心思想是智能體通過與環境交互 學習最優策略。
強化學習沒有靜態的標注數據集,而是通過觀察環境,選擇和執行動作,并獲得回報(或負回報形式的懲罰)。然后,它必須自行學習什么是最好的方法,稱為策略。以便隨著時間的推移獲得最大的回報。策略定義了智能體在給定情況下應該選擇的動作。
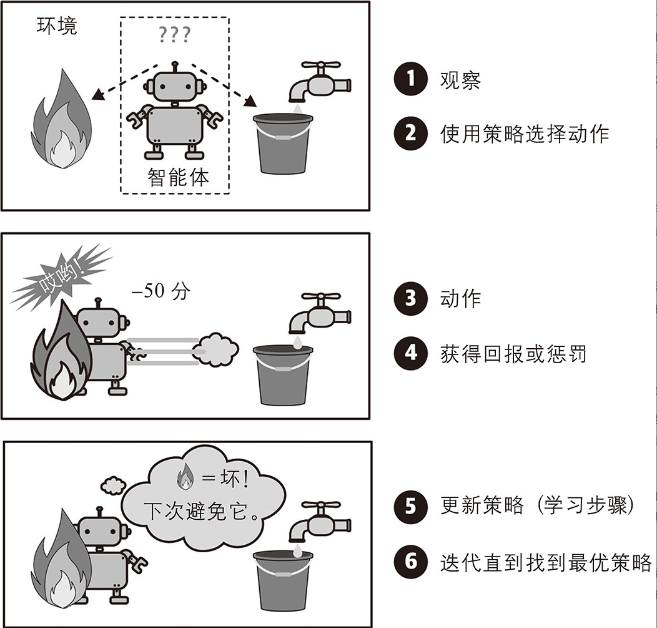
例如,許多機器人采用強化學習算法來學習如何走路。DeepMind的AlphaGo程序也是強化學習的一個很好的示例:它在2017年5月的圍棋比賽中打敗了當時世界排名第一的柯潔。它通過分析數百萬場比賽,然后與自己進行多次對弈,從而習得了獲勝策略。請注意,在與人類冠軍的比賽中學習過程是被關閉的,AlphaGo只是在應用它已經學到的策略。
二、按數據使用方式分類
1、批量學習&離線學習
在批量學習中,系統無法進行增量學習:它必須一次性使用所有可用的數據進行訓練,這成為批量學習。這通常會占用大量的時間和計算資源,因此通常需要離線完成。對系統進行訓練后,將其投入生產環境運行,就不再學習了。它只是應用它學到的東西,無法后續更新,這也稱為離線學習。
不幸的是,模型的性能往往會隨著時間的推移而慢慢變差,因為世界在不斷演進發展,而模型卻保持不變。這種現象通常稱為模型腐爛或數據漂移。解決方案是定期根據最新的數據重新訓練模型。你需要多久做一次取決于用例:如果模型對貓和狗的圖片進行分類,它的性能會衰減得很慢,但如果模型處理快速變化的系統,例如對金融市場進行預測,那么它很可能會衰減得相當快。
即使是經過訓練可以對貓和狗的圖片進行分類的模型也可能需要定期重新訓練,這不是因為貓和狗會在一夜之間發生變化,而是因為相機會不斷變化,圖像格式、清晰度、亮度和大小比例也在不斷變化。
如果想讓批量學習系統理解新數據(比如新型垃圾郵件),需要在完整數據集(不僅是新數據,還有舊數據)上從頭開始訓練新版系統,然后用新模型替換舊模型。幸運的是,訓練、評估和啟動機器學習系統的整個過程可以相當容易地自動化,因此即使是批量學習系統也可以適應變化。只需要經常更新數據并從頭開始訓練新版系統。
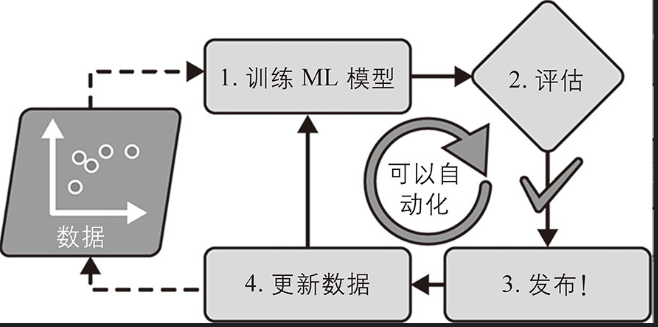
這個解決方案很簡單,而且通常效果很好,但使用完整數據集進行訓練可能需要花費很多小時,因此通常每24小時甚至每周訓練一次新系統。如果你的系統需要適應快速變化的數據(例如,預測股票價格),那么你需要一個更具反應性的解決方案。
此外,在完整的數據集上進行訓練需要大量的計算資源(CPU、內存空間、磁盤空間、磁盤I/O、網絡I/O等)。如果你有大量的數據,并且你讓系統每天從頭開始訓練,那么最終會花費你很多錢。如果數據量巨大,那么甚至可能無法使用批量學習算法。最后,如果系統需要能夠自動學習并且它的資源有限(例如,智能手機應用程序或火星上的漫游機器人)?,那么攜帶大量訓練數據并占用大量資源來每天訓練數小時是不太可能的。在這些情況下,更好的選擇是使用能夠增量學習的算法。
2、增量學習&在線學習&核外學習
增量學習是機器學習中的一種動態學習范式,其核心目標是讓模型能夠在不遺忘舊知識的前提下,持續從新數據中學習。而以數據以流式(逐條或者逐批次)輸入,實時更新模型,就是在線學習。在線學習都是增量學習,反之不成立。
如果你的計算資源有限,例如,模型是在移動設備上訓練的,那么在線學習是一個不錯的選擇。
此外,對于超大數據集——超出一臺計算機的主存儲器所能容納的數據,在線學習算法也同樣適用[這稱為核外(out-of-core)學習],主要是解決硬件限制,而非數據動態性。該算法加載部分數據,在該數據上運行一個訓練步驟,然后重復該過程,直到它在所有數據上運行完,這就是核外學習。
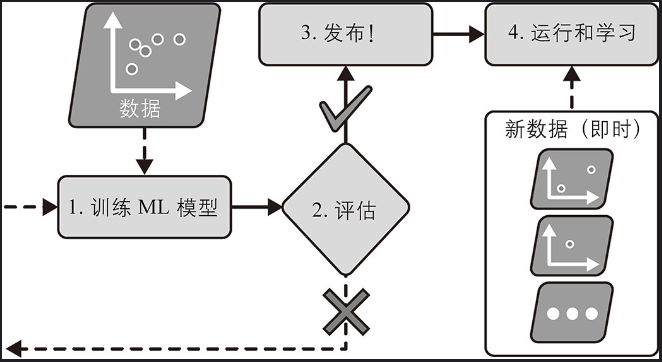
在線學習系統的一個重要參數是它們適應不斷變化的數據的速度:這稱為學習率。如果設置的學習率很高,那么系統會快速適應新數據,但它也會很快忘記舊數據(并且你也不希望垃圾郵件過濾器只標記最新類型的垃圾郵件)。反之,如果設置的學習率很低,那么系統會有更多的惰性,也就是說,它會學習得更慢,但它對新數據中的噪聲或非典型數據點(異常值)序列的敏感度也會降低。
核外學習通常是離線(即不在實時系統上)完成的,因此在線學習可能是一個容易混淆的名字。將其視為增量學習會更合適。在線學習≈增量學習,核外學習≠增量學習。核外學習是數據處理技術,增量學習、在線學習是模型更新策略
在線學習的一大挑戰是,如果將不良數據輸入系統,系統的性能可能會迅速下降(取決于數據的質量和學習率)。如果它是實時系統,那么你的客戶會注意到這個現象。不良數據的來源可能是機器人的傳感器故障,或者有人對搜索引擎惡意刷屏以提高搜索結果排名等。為降低這種風險,你需要密切監控系統,并在檢測到性能下降時立即關閉學習(并盡量恢復到之前的工作狀態)。你可能還想監控輸入數據并對異常數據做出反應。例如,使用異常檢測算法。
三、按模型構建方式分類
對機器學習系統進行分類的另一種方法是根據它們的泛化方式。
大多數機器學習任務都與做出預測有關。這意味著在給定大量訓練樣例的情況下,系統需要能夠對它以前未見到過的樣例做出良好的預測(泛化)。在訓練數據上有很好的性能是好的,但還不夠,真正的目標是在新實例上表現良好。
泛化方法主要有兩種:基于實例的學習和基于模型的學習。
1、基于實例的學習
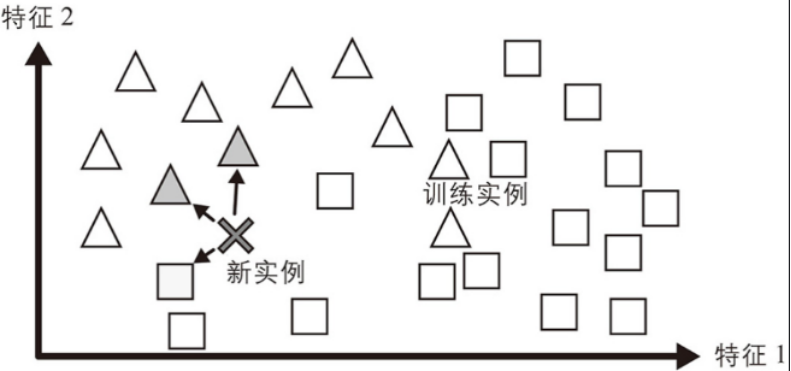
如果你以這種方式來創建垃圾郵件過濾器,那么它只會標記所有與用戶已標記的電子郵件相同的電子郵件——這雖然不是最壞的解決方案,但肯定不是最好的。垃圾郵件過濾器不僅可以標記與已知垃圾郵件相同的電子郵件,還可以對其進行編程來標記與已知垃圾郵件非常相似的電子郵件。這需要衡量兩封電子郵件之間的相似性。兩封電子郵件之間的(非常基本的)相似性度量可以是計算它們共有的單詞數。如果一封電子郵件與已知的垃圾郵件有很多相同單詞,那么系統會將其標記為垃圾郵件。
這稱為基于實例的學習:系統學習樣例,然后通過使用相似性度量將它們與學習到的樣例(或它們的子集)進行比較來泛化到新實例。例如,在圖中,新實例被歸類為三角形,因為大多數最相似的實例都屬于該類。
2、基于模型的學習
對于一組樣例進行泛化的另一種方法是為這些樣例構建一個模型(先假設模型,之后訓練模型得到較好的參數,實現理想的效果),然后使用該模型進行預測,這稱為基于模型的學習。
基于模型的學習的過程:研究數據 →選擇模型→使用訓練數據進行訓練→引用該模型對新實例進行預測(希望得到很好的泛化效果)
四、其他分類
1、半監督學習
由于標記數據通常既耗時又昂貴,因此你通常會有很多未標記的實例而很少有已標記的實例。一些算法可以處理一部分已標記的數據。這稱為半監督學習。
一些照片托管服務(例如Google相冊)就是很好的示例。一旦你將所有的家庭照片上傳到該服務,它會自動識別出同一個人A出現在照片1、5和11中,而另一個人B出現在照片2、5和7中。這是算法(聚類)的無監督部分。現在系統只需要你告訴它這些人是誰。你只需為每個人添加一個標簽,系統就可以為每張照片中的每個人命名,這對于搜索照片非常有用。
大多數半監督學習算法是無監督和監督算法的組合。例如,可以使用聚類算法將相似的實例分組在一起,然后每個未標記的實例都可以用其集群中最常見的標簽進行標記。一旦標記了整個數據集,就可以使用任何監督學習算法。
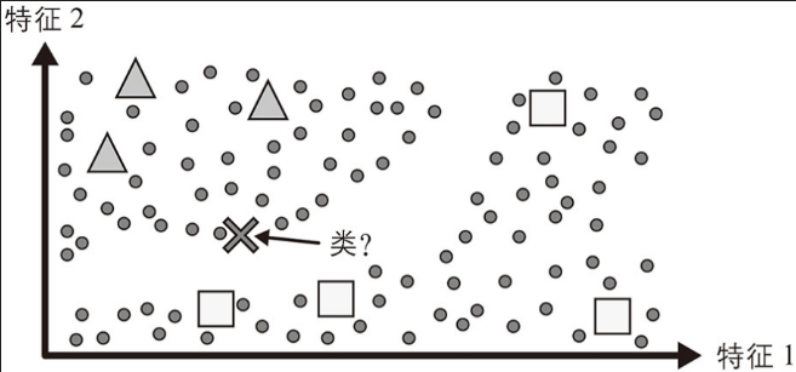
????????這張圖中先是將數據分為兩類(無監督學習的聚類算法),之后分別給他們打上▲和?的標簽,之后就是監督學習了。?X 通過監督學習到了▲一類,之后被標記成▲。
2、遷移學習
遷移學習的核心是知識復用,將從一個任務(源領域,source domain)中學到的知識遷移到另一個相關任務(目標領域,target domain),以提升目標任務的性能。其核心假設是:
源任務和目標任務之間存在共享的知識或模式(如底層特征、統計規律)。
源領域的知識可以減少目標領域對數據或計算資源的需求。
遷移學習典型的方法:預訓練+微調、特征提取、領域自適應、多任務學習













)


——資料分析、數量關系(40%-70%正確率的題目))


