文章目錄
-
目錄
文章目錄
前言
一、unordered_set和unordered_map介紹
二、哈希表的介紹
三、哈希沖突的解決方法
1.開放定址法
2.鏈地址法
四、兩種哈希表代碼實現
總結

前言
? ? ? ? 前面我們學習了紅黑樹,紅黑樹就是map和set的底層,本篇文章帶來的是unordered_map和unordered_set的底層,也就是哈希表。本節重點講解哈希表的實現。
一、unordered_set和unordered_map介紹
簡介:
- unordered_set和unordered_map是在C++11中才引入的,早年C++庫中只有set和map,也就是已經有Key和Key:Value這兩種查找的數據結構了并且效率不差,后來因為前兩者的查找效率很高,因此就將其引入C++庫。
- 因為set和map這種Key和Key:Value結構已經存在,所以新set和新map取名就在前面加上了unordered,這個單詞的意思是無序的。暗示了unorder_set和unorder_map存儲的數據是無序的,這點就和set、map存儲的數據有序不一樣了。
1.unordered_set
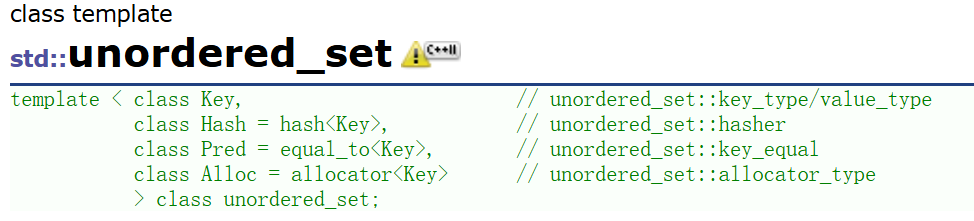
- unordered_set的聲明如下,Key就是unordered_set底層關鍵字的類型:
- unordered_set默認要求Key支持轉換為整形,如果不支持或者想按自己的需求走可以自行實現支持將Key轉成整形的仿函數傳給第二個模板參數Hash。
- unordered_set默認要求Key支持比較相等,如果不支持或者想按自己的需求走可以自行實現支持將Key比較相等的仿函數傳給第三個模板參數Pred。
- unordered_set底層存儲數據的內存是從空間配置器申請的,如果需要可以自己實現內存池,傳給第四個參數Alloc。
- 一般情況下,我們都不需要傳后三個模板參數。
2.unordered_set和set的使用差異
- 查看文檔我們會發現unordered_set的支持增刪查且跟set的使用?模?樣,關于使用我們這里就不再贅述和演示了,可參考前面文章:
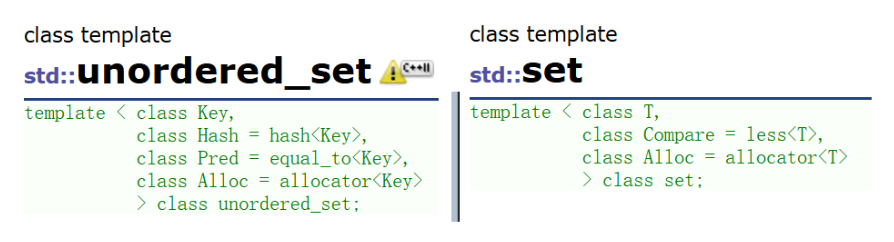
- unordered_set和set的第一個差異是對key的要求不同,set要求Key支持小于比較,而unordered_set要求Key支持轉成整形且支持等于比較,要理解unordered_set的這個兩點要求得后續我們結合下文哈希表底層實現才能真正理解,也就是說這本質是哈希表的要求。可以參考unordered_set的Hash、Pred參數和set的Compare參數:
- unordered_set和set的第二個差異是迭代器的差異,set的iterator是雙向迭代器,unordered_set 是單向迭代器,其次set底層是紅黑樹,紅黑樹是二叉搜索樹,走中序遍歷是有序的,所以set迭代器遍歷是有序+去重。而unordered_set底層是哈希表,迭代器遍歷是無序+去重。
- unordered_set和set的第三個差異是性能的差異,整體而言大多數場景下,unordered_set的增刪查改更快?些,因為紅黑樹增刪查改效率是 O(log n),而哈希表增刪查平均效率是 O(1),其實,實際上,O(log n) 和 O(1) 在數據量不是特別大的時候差別不是很大,因為就是10億個數據也就是2的30次方,對于log n也就是查找30次,但總體上,O(1)還是要更優一點。具體可以參考下面的代碼演示:
unordered_set和set的效率對比:
#include <iostream>
#include <unordered_set>
#include <set>
using namespace std;void test()
{const int N = 1000000;//測試數據個數srand((unsigned int)time(0));set<int> s;unordered_set<int> us;//測插入數據時間vector<int> v;v.reserve(N);for (int i = 0; i < N; i++){v.push_back(rand() + i);}int begin1 = clock();for (auto& e : v){s.insert(e);}int end1 = clock();int begin2 = clock();for (auto& e : v){us.insert(e);}int end2 = clock();cout << "set insert: " << end1 - begin1 << "(毫秒)" << endl;cout << "unordered_set insert: " << end2 - begin2 << "(毫秒)" << endl << endl;//測查找個數和時間int begin3 = clock();int m1 = 0;for (auto& e : v){auto ret = s.find(e);if (ret != s.end()){++m1;}}int end3 = clock();int begin4 = clock();int m2 = 0;for (auto& e : v){auto ret = us.find(e);if (ret != us.end()){++m2;}}int end4 = clock();cout << "set find: " << end3 - begin3 << "(毫秒)" << "->" << m1 << "(個數)" << endl;cout << "unordered_set find: " << end4 - begin4 << "(毫秒)" << "->" << m2 << "(個數)" << endl << endl;//測刪除數據時間int begin5 = clock();for (auto& e : v){s.erase(e);}int end5 = clock();int begin6 = clock();for (auto& e : v){us.erase(e);}int end6 = clock();cout << "set erase: " << end5 - begin5 << "(毫秒)" << endl;cout << "unordered_set erase: " << end6 - begin6 << "(毫秒)" << endl;
}int main()
{test();return 0;
}測試結果(Release x64):
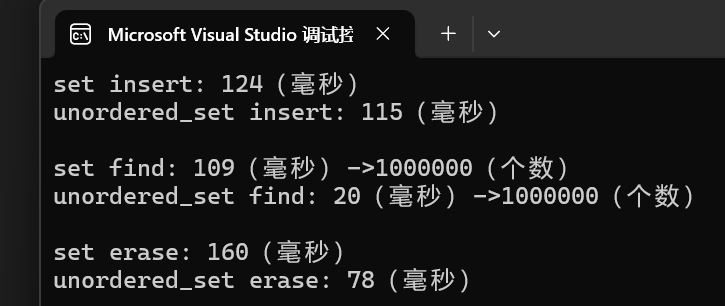
- 很明顯,在增刪查的效率上,unordered_set是更優于set的。
3.unordered_map
- unordered_map聲明如下,參數的Key和T決定map的K:V類型
- unordered_map也默認要求Key支持轉換為整形,如果不支持或者想按自己的需求走可以自行實現支持將Key轉成整形的仿函數傳給第二個模板參數Hash。
- unordered_map也默認要求Key支持比較相等,如果不支持或者想按自己的需求走可以自行實現支持將Key比較相等的仿函數傳給第三個模板參數Pred。
- unordered_map底層存儲數據的內存是從空間配置器申請的,如果需要可以自己實現內存池,傳給第四個參數Alloc。
- 一般情況下,我們都不需要傳后三個模板參數。
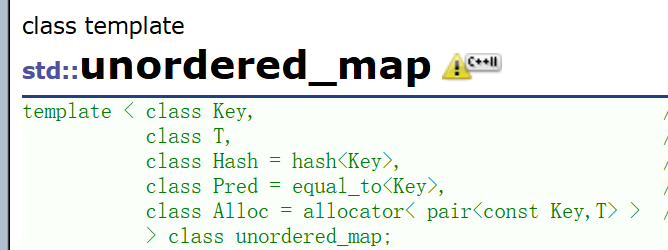
3.unordered_map和map的使用差異
- 查看文檔我們會發現unordered_map的支持增刪查改且跟map的使用一模一樣,關于使用我們這里就不再贅述和演示了,可參考主頁map的使用文章。
- unordered_map和map的第一個差異是對key的要求不同,map要求Key支持小于比較,而unordered_map要求Key支持轉成整形且支持等于比較,要理解unordered_map的這個兩點要求得后續我們結合哈希表底層實現才能真正理解,也就是說這本質是哈希表的要求。比如參考兩者的Hash、Pred參數和Compare參數:
- unordered_map和map的第?個差異是迭代器的差異,map的iterator是雙向迭代器, unordered_map是單向迭代器,其次map底層是紅黑樹,紅黑樹是二叉搜索樹,走中序遍歷是有序的,所以map迭代器遍歷是Key有序+去重。而unordered_map底層是哈希表,迭代器遍歷是 Key無序+去重。
- unordered_map和map的第三個差異是性能的差異,整體而言大多數場景下,unordered_map的增刪查改更快?些,因為紅黑樹增刪查改效率是 O(logN) ,而哈希表增刪查平均效率是O(1) , 具體可以參看下面代碼的演示的對比差異。

unordered_map和map增刪查效率對比:
#include <iostream>
#include <unordered_map>
#include <map>
using namespace std;void test()
{const int N = 1000000;srand((unsigned int)time(0));vector<int> v;v.reserve(N);for (int i = 0; i < N; i++){v.push_back(rand() + i);}map<int, int> m;unordered_map<int, int> um;int begin1 = clock();for (auto& e : v){m.insert({ e,e });}int end1 = clock();int begin2 = clock();for (auto& e : v){um.insert({ e,e });}int end2 = clock();cout << "map insert: " << end1 - begin1 << "(毫秒)" << endl;cout << "unordered_map insert: " << end2 - begin2 << "(毫秒)" << endl << endl;int begin3 = clock();int m1 = 0;for (auto& e : v){auto ret = m.find(e);if (ret != m.end()){++m1;}}int end3 = clock();int begin4 = clock();int m2 = 0;for (auto& e : v){auto ret = um.find(e);if (ret != um.end()){++m2;}}int end4 = clock();cout << "map find: " << end3 - begin3 << "(毫秒)" << "->" << m1 << "(個數)" << endl;cout << "unordered_map find: " << end4 - begin4 << "(毫秒)" << "->" << m2 << "(個數)" << endl << endl;int begin5 = clock();for (auto& e : v){m.erase(e);}int end5 = clock();int begin6 = clock();for (auto& e : v){um.erase(e);}int end6 = clock();cout << "map erase: " << end5 - begin5 << "(毫秒)" << endl;cout << "unordered_map erase: " << end6 - begin6 << "(毫秒)" << endl << endl;
}int main()
{test();return 0;
}測試結果(Release x64):
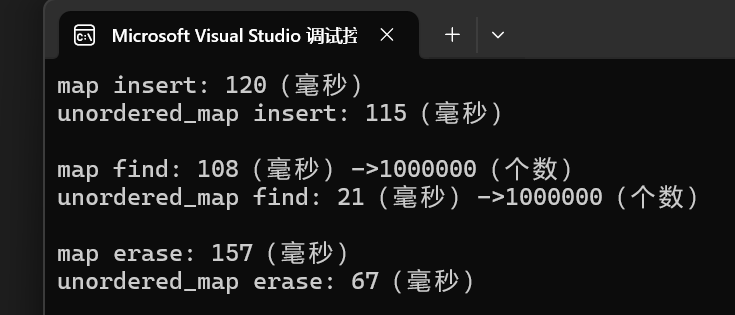
- 在插入效率上,unordered_map和map差不多,但是查找和刪除上,明顯unordered_map更優。
- 關于unordered_set,unordered_map和set,map最后再說一點。
- 前面不是提到set和map底層是紅黑樹嗎,所以set和map的數據是有序和去重的,而unordered_set和unordered_map底層是哈希表(桶),所以unordered_set和unordered_map的數據是無序和去重的。
代碼演示:
#include <iostream>
#include <set>
#include <unordered_set>
#include <map>
#include <unordered_map>
using namespace std;void test()
{set<int> s1({ 5,2,6,3,4,8,1,9,7 });map<int, int>m1;m1.insert({ 5,5 });m1.insert({ 2,2 });m1.insert({ 1,1 });m1.insert({ 4,4 });m1.insert({ 3,3 });for (auto e : s1){cout << e << " ";}cout << endl;for (auto e : m1){cout << e.first << ":" << e.second << " ";}cout << endl << endl;unordered_set<int> s2({ 5,2,6,3,4,8,1,9,7 });unordered_map<int, int>m2;m2.insert({ 5,5 });m2.insert({ 2,2 });m2.insert({ 1,1 });m2.insert({ 4,4 });m2.insert({ 3,3 });for (auto e : s2){cout << e << " ";}cout << endl;for (auto e : m2){cout << e.first << ":" << e.second << " ";}cout << endl;
}int main()
{test();return 0;
}運行結果:
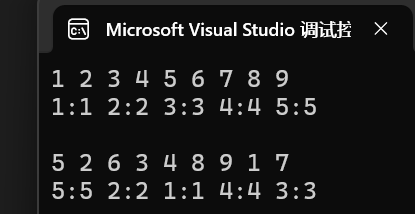
- 綜合上面性能測試以及unordered_set,unordered_map和set,map接口得相似性,所以我們大多數情況下,一般是使用unordered_set或者unordered_map即可。除非你有數據排序的需要或其他特殊需求。
二、哈希表的介紹
1.哈希概念
- 哈希(hash)又稱散列,是一種組織數據的方式。從譯名來看,有散亂排列的意思。本質就是通過哈希函數把關鍵字Key跟存儲位置建立?個映射關系,查找時通過這個哈希函數計算出Key存儲的位置,進行快速查找。
2.直接定址法
- 直接定值法是最簡單的一種哈希,可以讓我們初步了解什么是哈希。
- 該方法其實我們很早就使用過,比如下面這道題:
題目鏈接:387. 字符串中的第一個唯一字符 - 力扣(LeetCode)

題解:
class Solution {
public:int firstUniqChar(string s){//先開辟26個空間(26個字母)int count[26] = { 0 };//將每個字母減去a映射到數組中for (auto e : s){count[e - 'a']++;}//通過映射關系,遍歷數組找到最前面的單個字母即可for (size_t i = 0; i < s.size(); i++){if (count[s[i] - 'a'] == 1){return i;}}return -1;}
};
- 上面這題也可以看成是計數排序,將每個字母減去a,從而映射到0-25的空間上,每個位置對應一個字母,比如字母a,其減去a映射的位置就是數組count[0],以此類推,不僅可以計數,也能排序。
- 將 字母-'a' 來計算字母的映射位置的函數,可以看成一種哈希函數,因為方法比較直接,計算出來的位置比較絕對,所以稱為直接定址法。
- 直接定址法優點:當關鍵字的范圍比較集中時,直接定址法就是非常簡單高效的方法,比如一組關鍵字都在[0,99]之間, 那么我們開?個100個數的數組,每個關鍵字的值直接就是存儲位置的下標。再比如?組關鍵字值都在 [a,z]的小寫字母,那么我們開?個26個數的數組,每個關鍵字acsii碼-a = ascii碼就是存儲位置的下標。 也就是說直接定址法本質就是用關鍵字計算出一個絕對位置或者相對位置。
3.哈希沖突
- 直接定址法的缺點也非常明顯,當關鍵字的范圍比較分散時,就很浪費內存甚至內存不夠用。假設我們只有數據范圍是[0,9999]的N個值,我們要映射到一個M個空間的數組中(一般情況下M>=N),那么 就要借助哈希函數(hashfunction)hf,關鍵字key被放到數組的h(key)位置,這里要注意的是h(key)計算出的值必須在[0,M)之間。
- 這里存在的一個問題就是,兩個不同的key可能會映射到同?個位置去,這種問題我們叫做哈希沖突, 或者哈希碰撞。理想情況是找出一個好的哈希函數避免沖突,但是實際場景中,沖突是不可避免的, 所以我們盡可能設計出優秀的哈希函數,減少沖突的次數,同時也要去設計出解決沖突的方案。
補充:
- 簡單點說,哈希就是將N個值通過哈希函數,映射到M個空間內。哈希函數下面會講到,常見點的哈希函數就是取模,做 % 運算得到的結果映射到M空間中的某一個位置上,哈希沖突就是2個及以上的數據進行取模后映射的位置相同,哈希沖突盡量避免但是無法消除,如遇到需要進一步確認映射位置解決哈希沖突,這一步也叫線性探測。
- 將關鍵字轉為整數:這里有一個點需要注意,我們將關鍵字映射到數組中位置,一般是整數好做映射計算,比如取模運算,如果不是整數,我們要想辦法轉換成整數。這就是unordered_set和unordered_map的模板中,Hash參數的意義,Hash就是將非整形數據通過某種計算轉為整形的仿函數。具體細節在下文實現哈希表中會詳細介紹。
- 總的來說,直接定址法有著巨大的缺陷,所以哈希一般不考慮直接定址法,具體的哈希函數參考下文。
4.哈希函數
- 沖突雖不可避免,但是我們可以設計出優秀的哈希函數來減少沖突。
- 一個好的哈希函數應該讓N個關鍵字被等概率的均勻的散列分布到哈希表的M個空間中,但是實際中卻很難做到,但是我們要盡量往這個方向去考量設計。
- 以下是介紹幾種常見的哈希函數,其實最主要的就是第一種:
?(1)除留余數法(除法散列法)*
- 除法散列法也叫做除留余數法,顧名思義,假設哈希表的大小為M,那么通過key除以M的余數作為映射位置的下標,也就是哈希函數為:h(key) = key % M。
- 當使用除法散列法時,要盡量避免M為某些值,如2的冪,10的冪等。如果是 ,那么key%
本質相當于保留key的后X位,那么后x位相同的值,計算出的哈希值都是?樣的,就沖突了。如: {63 , 31}看起來沒有關聯的值,如果M是16,也就是
,那么計算出的哈希值都是15,因為63的? 進制后8位是00111111,31的?進制后8位是00011111。如果是?
,就更明顯了,保留的都是 10進值的后x位,如:{112,12312},如果M是100,也就是
,那么計算出的哈希值都是12。
- 關于除數是
- 因此,當使用除法散列法時,建議M取不太接近2的整數次冪的一個質數(素數)。
- 需要說明的是,實踐中也是八仙過海,各顯神通,Java的HashMap采用除法散列法時就是2的整數次冪做哈希表的大小M,這樣玩的話,就不用取模,而可以直接位運算,相對而言位運算比模更高效一些。但是他不是單純的去取模,比如M是2^16次方,本質是取后16位,那么用key’= key>>16,然后把key和key'異或的結果作為哈希值。也就是說我們映射出的值還是在[0,M)范圍 內,但是盡量讓key所有的位都參與計算,這樣映射出的哈希值更均勻?些即可。所以我們上面建議M取不太接近2的整數次冪的一個質數的理論是大多數數據結構書籍中寫的理論,但是實踐中, 靈活運用,抓住本質,而不能死讀書。(了解)
- 那么C++中具體是這么設計除數的呢,其實就是使用一張質數表,具體我們在下文中講解:

(2)乘法散列法(了解)
- 乘法散列法對哈希表大小M沒有要求,他的大思路第一步:用關鍵字K乘上常數A(0<A<0),并抽取出k*A的小數部分。第二步:后再用M乘以k*A的小數部分,再向下取整。
,其中floor表示對表達式進行向下取整,
,這里最重要的是A的值應該如何設定,Knuth認為:
(黃金分割點)比較好。
- 乘法散列法對哈希表大小M是沒有要求的,假設M為1024,key為1234,A=0.6180339887,A*key = 762.6539420558,取小數部分為0.6539420558, M×((A×key)%1.0)=0.6539420558*1024= 669.6366651392,那么h(1234)=669。
- 乘法散列法用的比較少,但也是一種思路。
(3)全域散列法(了解)
- 如果存在?個惡意的對手,他針對我們提供的散列函數,特意構造出一個發生嚴重沖突的數據集, 比如,讓所有關鍵字全部落入同一個位置中。這種情況是可以存在的,只要散列函數是公開且確定的,就可以實現此攻擊。解決方法自然是見招拆招,給散列函數增加隨機性,攻擊者就無法找出確定可以導致最壞情況的數據。這種方法叫做全域散列。
,P需要選一個足夠大的質數,a可以隨機選[1,P-1]之間的任意整數,b可以隨機選[0,P-1]之間的任意整數,這些函數構成了一個P*(P-1)組全域散列函數組。假設P=17,M=6,a=3,b=4,則
。
- 需要注意的是每次初始化哈希表時,隨機選取全域散列函數組中的一個散列函數使用,后續增刪查改都固定使用這個散列函數,否則每次哈希都是隨機選一個散列函數,那么插入是一個散列函數, 查找又是另一個散列函數,就會導致找不到插入的key了。
- 簡單點說,會隨機生成一個哈希函數,因為隨機,所以連設計者都不知道具體的哈希函數,因此就不容易被惡意攻擊,在安全性方面有一定作用。本質來說還是除留余數法,只不過在除數上做到一定隨機性。
(4)關于其他哈希函數
- 其他哈希函數可參考:《殷人昆 數據結構:用面向對象方法與C++語言描述(第二版)》和《[數據結構(C語言版)].嚴蔚敏_吳偉民》等教材型書籍。
- 其中講解的哈希函數包括但不限于:平方取中法、折疊法、隨機數法、數學分析法等。大家感興趣可以前去學習。
5.負載因子
- 我們知道哈希表也是要存儲數據的,既然存儲數據就避免不了擴容的問題,因此負載因子就是決定是否需要擴容的判斷依據。這一點具體體現在下文的代碼實現中,我們先了解知道。
- 假設哈希表中已經映射存儲了N個值,哈希表的大小為M,那么負載因子 =?
(也就是N 和 M 的比值),負載因子有些地方也翻譯為載荷因子/裝載因子等,他的英文為loadfactor。負載因子越大,哈希沖突的概率越高,空間利用率越高;負載因子越小,哈希沖突的概率越低,空間利用率越低;
- 一般情況下,比值等于0.7時就需要擴容了,因為比值過大,可用空間越小,哈希沖突的概率就越大,對性能的影響也就越大。
查看負載因子接口:
#include <iostream>
#include <unordered_map>
using namespace std;int main()
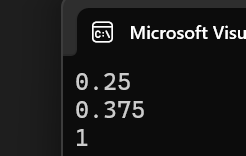
{unordered_map<int, int> m1;m1.insert({ 1,1 });m1.insert({ 54,54 });cout << m1.load_factor() << endl;//查看當前負載因子大小m1.insert({ 2,2 });cout << m1.load_factor() << endl;cout << m1.max_load_factor() << endl;//查看最大負載因子值return 0;
}運行結果:
- unordered_set同理。
三、哈希沖突的解決方法
- 因為哈希沖突無法避免,那么就需要解決方法,主要的解決方法有兩種:
- 開放定址發
- 鏈地址法(哈希桶)
- 這兩種方法后續代碼中都會進行實現
1.開放定址法
- 在開放定址法中所有的元素都放到哈希表里,當一個關鍵字key用哈希函數計算出的位置沖突了,則按照某種規則找到一個沒有存儲數據的位置進行存儲,開放定址法中負載因子一定是小于1的,所以不存在沒有位置的可能。這里的規則有三種:線性探測、二次探測、雙重探測。
- (注意:以下方法中,M表示容量,h是哈希函數,hc是探測函數)
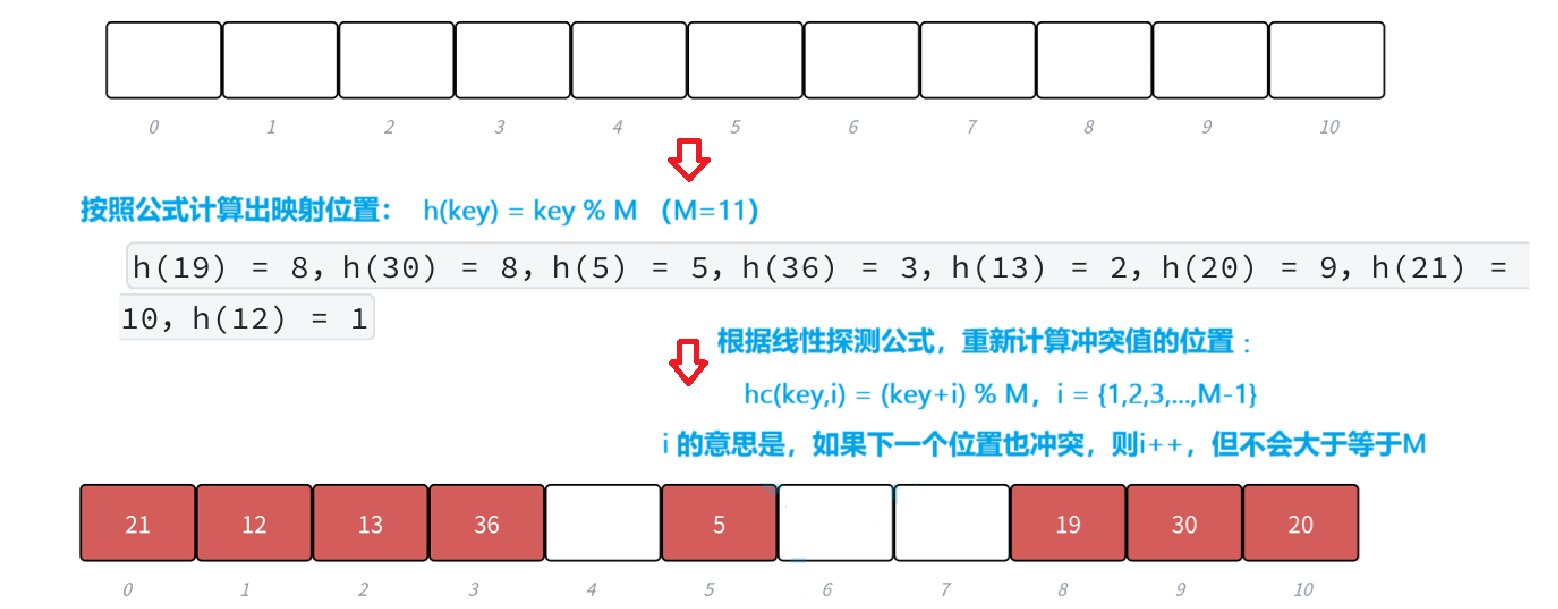
(1)線性探測
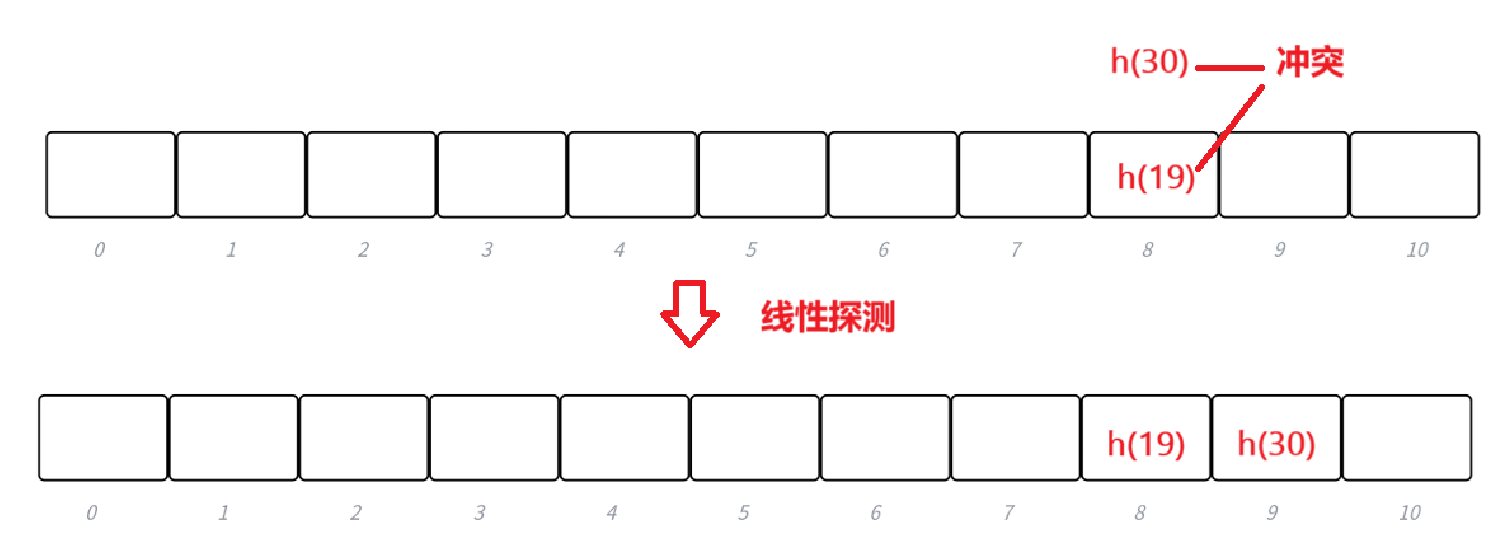
- 線性探測是我們后續代碼中解決哈希沖突的方法,比較常見。具體規則:從發生沖突的位置開始,依次線性向后探測,直到尋找到下一個沒有存儲數據的位置為止,如果走到哈希表尾,則回繞到哈希表頭的位置。因為哈希因子的存在,所以不存在沒位置的情況。
- 見上圖,假如 h(19) 和 h(30) 計算的映射位置沖突,則?h(30)依次向后探測,直到找到一個空位置即可。這里面具體的計算公式參考下一點:
,這是哈希函數中的除留余數法,計算映射位置的公式。如果 hash0 位置沖突了,則線性探測公式為:
,因為負載因子小于1, 則最多探測M-1次,一定能找到一個存儲key的位置,如果繼續沖突則i++。
- 下面演示:{19,30,5,36,13,20,21,12}?這?組值映射到M=11的表中的位置。
- 解釋:上圖中,19,30哈希都等于8,發生哈希沖突,19先來就在位置8,30則在后一位9。因為9位置被30占住了,所以哈希等于9的20就繼續順延到10的位置。21同理。
- 線性探測的比較簡單且容易實現,但缺點也明顯(如上),線性探測的問題:假設 hash0 位置連續沖突,hash0,hash1, hash2位置已經存儲數據了,后續映射到hash0,hash1,hash2,hash3的值都會爭奪hash3位置,這種現象叫做群集/堆積。下面的二次探測可以一定程度改善這個問題。
?(2)二次探測
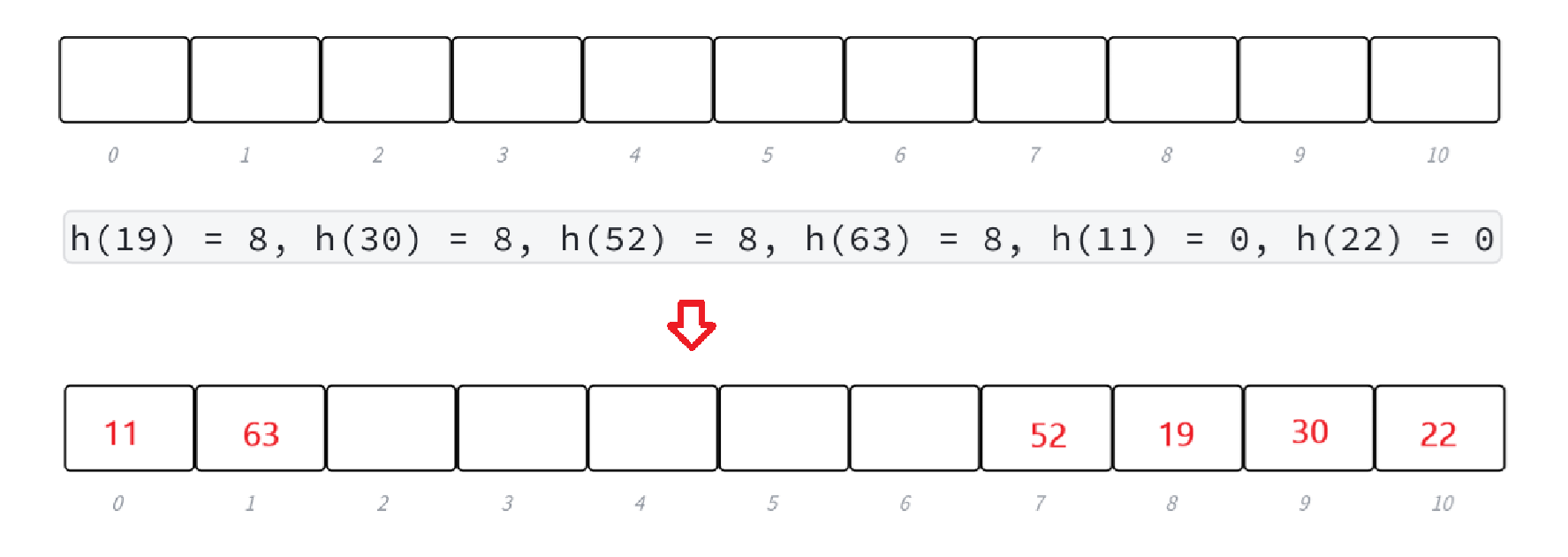
- 從發生沖突的位置開始,依次左右按二次方跳躍式探測,直到尋找到下一個沒有存儲數據的位置為止,如果往右走到哈希表尾,則回繞到哈希表頭的位置;如果往左走到哈希表頭,則回繞到哈希表尾的位置;具體公式如下:
- 哈希函數:
,hash0位置沖突了,則二次探測公式為:
,i = {1,2,3,...,2/M}。如果繼續沖突則i++。
- 二次探測當
時,當hashi<0時,需要hashi+=M,避免越界。
- 上面二次探測公式中是加減 i 的平方,一般按照先加 i 的平方,再減 i 的平方的順序。當減 i 的平方等于負數時,就是上一條中需要加上M避免越界。
- 下面演示,{19,30,52,63,11,22}這一組值,映射到M=11的表中。
- 解釋:首先19先占據位置8,30通過二次探測加上i=1的平方計算最后在位置9。52則是因為9的位置被占,根據先加后減,因此52是減去i=1的平方最后在位置7。63也是哈希沖突,此時i=1的位置都被占了,因此i=2,加上i=2的平方再取模,計算的位置就是1了。11沒啥說的,注意22,22因為1的位置被占,所以減去i=1的平方,因為0-1=-1<0越界了,此時需要 + M,M=11加上就是10,取模后22就在位置10了。
- 二次探測利用 i 平方的落差,使得堆積不容易發生,但難免有些極端情況會導致堆積。
(3)雙重散列
- 第一個哈希函數計算出的值發生沖突,使用第二個哈希函數計算出一個跟key相關的偏移量值,不斷往后探測,直到尋找到下一個沒有存儲數據的位置為址。
- 雙重散列從名字上就能看出,它是會進行兩次哈希函數計算的,它的一般公式如下:
- 哈希函數依舊是除留余數法:
,hash0位置沖突了,則雙重探測公式為:
,i = {1,2,3,...,M},其中h2是第二個哈希函數。如果繼續沖突則i++。
- 雙重散列的要求:
,關于h2這里有兩種簡單的取值方法:1. 當M為2整數冪時,h2(key)從[0,M-1]任選一個奇數;2. 當M為質數時,
,也就是第二個哈希函數。
- 保證h2(key)和M互質是因為根據固定的偏移量所尋址的所有位置將形成?個群,若最大公約數
,那么所能尋址的位置的個數為 M?/?P < M,使得對于?個關鍵字來說無法充分利用整個散列表。舉例來說,若初始探查位置為1,偏移量為3,整個散列表大小為12, 那么所能尋址的位置為{1,4,7,10},尋址個數為 12/gcd(12,3) = 4。
- 下面演示 {19,30,52,74}這?組值映射到M=11的表中,設
- 解釋:h1(19) = 8,h1(30) = 8,h1(52) = 8,h1(74) = 8,也就是這一組值都是沖突的,首先19占據位置8,30的位置:hc(30,1) = (8+1*(30 % 10+1)) % 11 = 9,52的位置:hc(52,1) = (8+1*(52 % 10 +1)) % 11 = 0,hc(74,1) = (8+1*(74 % 10+1)) % 11 = 2。
- 雙重散列利用第二個哈希函數,使得堆積發生的概率更低。

2.鏈地址法
- 鏈地址法解決哈希沖突是我們重點掌握的辦法。
- 鏈地址法與開放定址法最大的不同就是:在開放定址法中,如果遇到沖突就占據另一個位置,因為會占據另一個位置,所以沖突概率會越來越大,而在鏈地址法中,每一個位置都能存下多個值,就不存在發生沖突去占據其他位置的情況。
解決沖突的思路:
- 開放定址法中所有的元素都放到哈希表里,鏈地址法中所有的數據不再直接存儲在哈希表中,哈希表中存儲一個指針,沒有數據映射這個位置時,這個指針為空,有多個數據映射到這個位置時,我們把這些沖突的數據鏈接成一個鏈表,掛在哈希表這個位置下面,鏈地址法也叫做拉鏈法或者哈希桶。
思路演示:
- 下面演示 {19,30,5,36,13,20,21,12,24,96} 這一組值映射到M=11的表中:
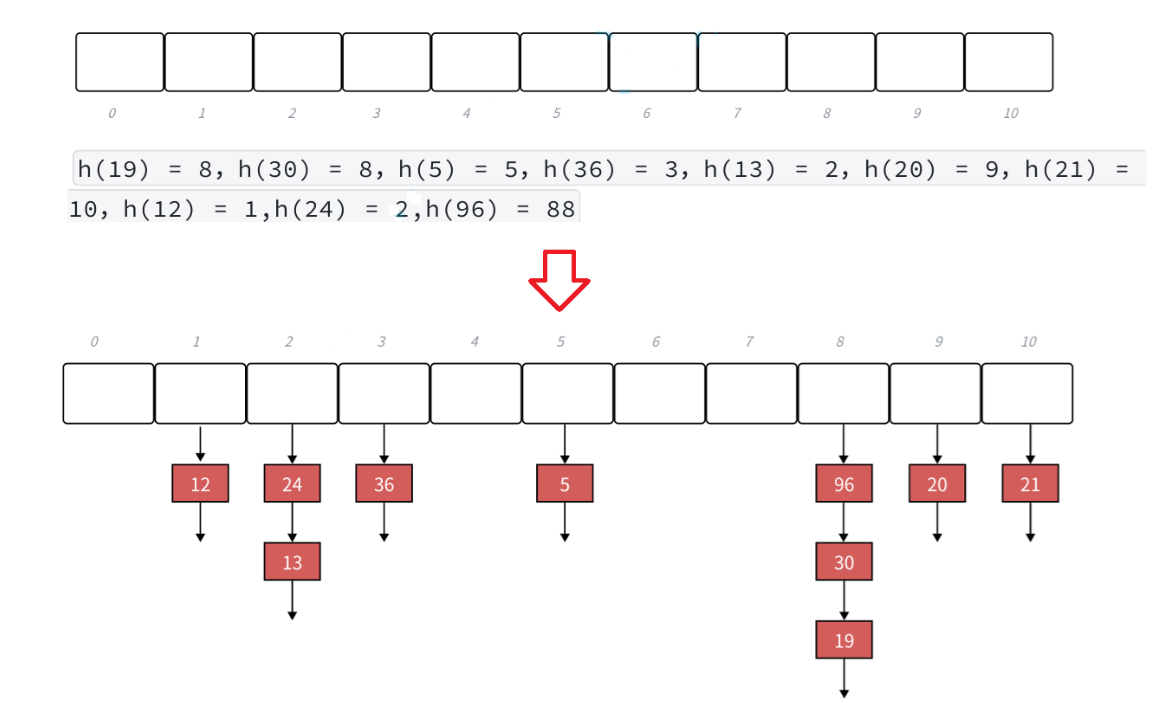
- 很明顯,鏈地址法解決哈希沖突的方法就是將沖突值串在一起形成一個鏈表,也可以看成一個個桶(哈希桶)。
關于鏈地址法的擴容:
- 開放定址法負載因子必須小于1,鏈地址法的負載因子就沒有限制了,可以大于1。負載因子越大,哈希沖突的概率越高,空間利用率越高;負載因子越小,哈希沖突的概率越低,空間利用率越低;stl中 unordered_xxx 的最大負載因子基本控制在1,大于1就擴容,我們下面實現也使用這個方式。
關于極端場景:
- 如果極端場景下,某個桶特別長怎么辦?其實我們可以考慮使用全域散列法,這樣就不容易被針對 了。但是假設不是被針對了,用了全域散列法,但是偶然情況下,某個桶很長,查找效率很低怎么辦?這里在Java8的HashMap中當桶的長度超過一定閥值時就把鏈表轉換成紅黑樹。一般情況下, 不斷擴容,單個桶很長的場景還是比較少的,下面我們實現就不搞這么復雜了,這個解決極端場景的思路,了解?下。
四、兩種哈希表代碼實現
- 開放定址法
- 鏈地址法
(哈希函數都默認選擇除留余數法)
1.開放定址法:
在開放定址法實現前需要補充一個知識點:
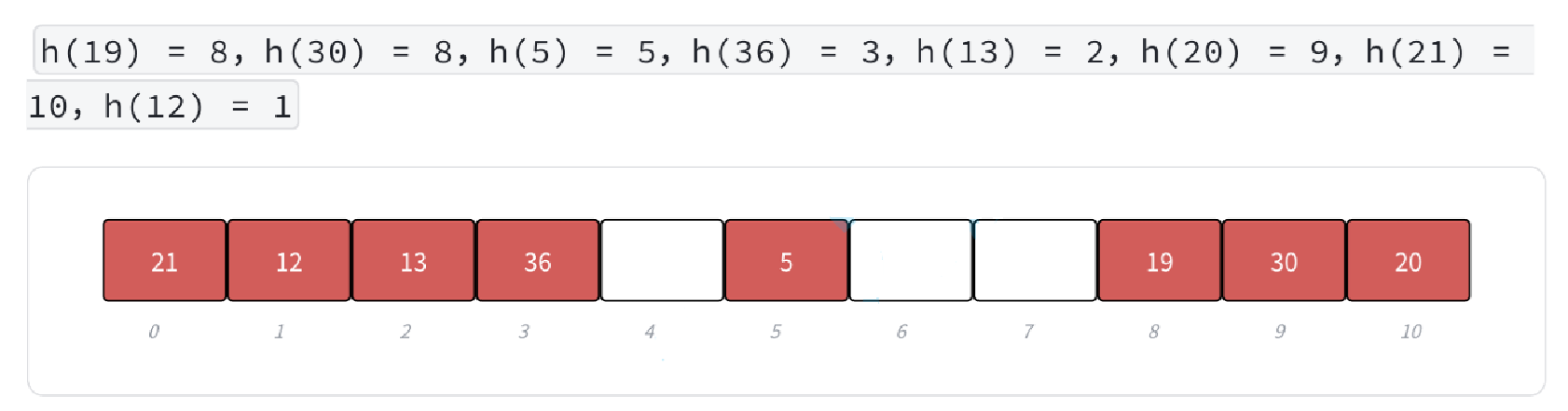
- 我們假設下面這個場景(線性探測中的例圖):哈希函數是除留余數法,解決沖突是線性探測
- 以上是已經插好值的哈希表,現在有什么問題呢?當我們刪除19,此時可以直接刪除8位置上的值,但是當我們繼續刪除30時,由于刪除值也是按照除留余數法進行查找,此時由于8位置上的19已經被刪除了,所以8位置上為空,為空就無法確認30是否存在。假如19沒被刪除,我們查到8位置不為空并且不為30時,可以繼續進行線性探測進一步查找。
- 問題總結:直接刪除哈希表中的一個值,可能會引起后續無法查到相同哈希值的其他數據或者被哈希沖突影響位置的數據。
- 解決方法:為每一個哈希表中的位置設定一個狀態,這些狀態有:EXIST(存在)、EMPTY(為空)、DELETE(刪除)。這三種狀態前兩個很好理解,有值就設定存在,沒值就默認為空,而刪除則是刪除一個值后將其位置標記為DELETE,這樣做就是在查找一個值時,如果遇見刪除標記,則表示需要進一步使用線性探測等方式查找。
(1)基本框架
#pragma once
#include <vector>
#include <algorithm>
using namespace std;//開放定址法的命名空間
namespace open_address
{//定義狀態標志enum State{EXIST,//存在EMPTY,//為空DELETE //刪除};//定義哈希數據template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};//定義哈希表template<class K, class V>class HashTable{public:private:vector<HashData<K, V>> _tables;//底層數據結構使用vectorsize_t _n = 0;//表中存儲數據個數};
}框架簡介:?
- State 枚舉結構用來定義哈希表中數據的三種狀態。
- HashData 類定義哈希表中數據類型。底層數據默認為pair類型,因此模板參數都需要有K,V。每個數據都有一個狀態值,默認為 EMPTY(空)。
- HashTable 類就是哈希表本體了,底層數據結構選擇vector,vector用來存儲管理連續性空間是很高效和方便的。vector中存放的數據就是 HashData。
- n 用來記錄哈希表中有效值個數,方便負載因子計算,用于擴容判斷。
(2)Insert 框架
//插入
bool Insert(const pair<K, V>& kv)
{//擴容if ((double)_n / (double)_tables.size() > 0.7){//...}//哈希函數:除留余數法size_t hash0 = kv.first % _tables.size();size_t hashi = hash0;size_t i = 1;//沖突探測(線性探測)while (_tables[hashi]._state == EXIST){hashi = (hash0 + i) % _tables.size();++i;}//插入_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;
}
- 我們先不看擴容,先了解值是具體怎么插入的。
- 首先使用除留余數法計算出插入值的映射位置hash0,然后hashi用于接下來的線性探測使用。注意取模的除數都是 _tables.size() 而不是 tables.capacity(),這是因為capacity()的返回值是vector的容量大小,而我們因為對除數有質數的要求,因此這里使用capacity是一個坑,size()返回的是質數有效空間,稍后我們實現構造時會有初始空間大小。
- 如果hashi位置的狀態為EMPTY或者DELETE就可以直接插入,而只有當狀態值為EXIST時才需要進行線性探測進一步確認映射位置,線性探測的公式參考:
- 直到線性探測找到的位置為EMPTY或者DELETE時才停止循環。
- 最后插入需要注意的就是改變狀態指為EXIST,另外_n需要++。
(3)Insert 擴容和構造函數實現
- 結合前面內容,我們知道無論是哈希函數,還是探測函數,為了減少哈希沖突的概率,我們除數需要滿足質數的性質。那么怎么獲取這些質數呢?
- 誒,下面這個接口就能滿足我們的需求:
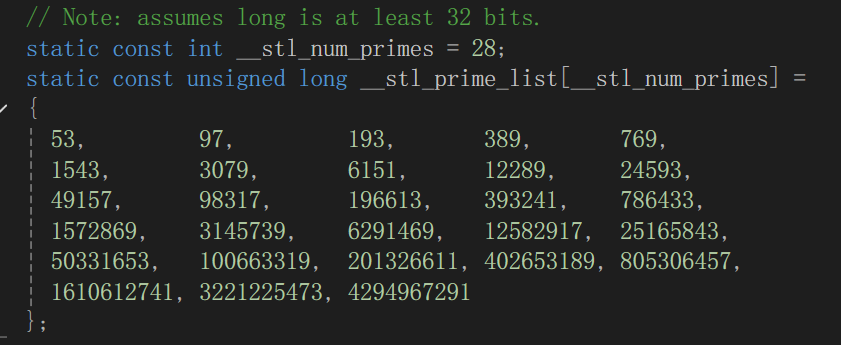
__stl_next_prime 接口:
//獲取下一個質數
inline unsigned long __stl_next_prime(unsigned long n)
{static const int __stl_num_primes = 28;//定義質數列表大小static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);//返回大于等于n的質數return pos == last ? *(last - 1) : *pos;
}
- 首先參數n是我們需要的空間大小。
- __stl_num_primes 是數組大小,__stl_prime_list[__stl_num_primes]是我們創建的質數數組,里面存儲的都是質數。這兩個變量都設置為 static 靜態變量,因為這兩被訪問的頻率很高,設置為靜態能提高效率。
- first 是數組的頭指針,last 是數組的尾指針,lower_bound是庫函數,返回迭代區間內大于等于n的數的指針,并將其存儲在 pos。這樣 *pos 就是我們需要的空間大小。
- 但是,數組中的最后一個值是過大的,所以如果pos是最后一個值則需要后退一步。
哈希表的構造函數:
//構造
HashTable()
{_tables.resize(__stl_next_prime(0));
}
- 只需要將 vector 的size通過resize接口設置成質數數組中的最小值即可。其中的數據 HashData 的狀態值都默認為空(EMPTY),這些都算是有效空間。除數不使用capacity就體現在這里,因為擴容的特殊性,capacity實際大小并不能精準的被我們控制,因此除數使用size。
insert 的擴容實現:
//插入
bool Insert(const pair<K, V>& kv)
{//擴容if ((double)_n / (double)_tables.size() > 0.7)//計算負載因子,大于0.7就擴容{//創建一個新哈希表,重新建立映射HashTable<K, V> newHT;newHT._tables.resize(__stl_next_prime((unsigned long)(_tables.size() + 1)));//利用已有的Insert進行開放定址和沖突探測for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}//交換_tables.swap(newHT._tables);}//哈希函數:除留余數法size_t hash0 = kv.first % _tables.size();size_t hashi = hash0;size_t i = 1;//沖突探測(線性探測)while (_tables[hashi]._state == EXIST){hashi = (hash0 + i) % _tables.size();++i;}//插入_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;
}
- 說到擴容的數據調整,這是因為擴容導致size()大小變化,因此舊哈希表中的數據都需要重新映射。新size大小依舊由__stl_next_prime接口獲取,參數傳遞舊size+1即可,因為會返回下一個質數。
- 這里的擴容代碼實現的很巧妙,我們不是新建一個vector,而是直接新建一個哈希表newHT。這里直接復用已經實現的insert代碼進行插入。因為新空間的負載因此肯定小于0.7,所以不會再進一步擴容導致遞歸。
- 這里的復用很巧妙的節省了代碼量,減少重復代碼,newHT插入完成后,將其底層vector與原哈希表底層vector進行swap交換即可。newHT出了擴容的作用域就會自行析構。
(4)Find 和 Erase 接口實現
Find:
//查找
HashData<K, V>* Find(const K& key)
{//哈希函數:除留余數法size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];//找到了}//線性探測hashi = (hash0 + i) % _tables.size();++i;}return nullptr;//找不到
}
- Find實現并不復雜,先使用哈希函數找到映射位置hash0,再判斷對應位置是否為空,不為空則進入循環,循環中使用線性探測進行查找,因為hash0的位置還沒有判斷,因此++i放在線性探測后面,當且僅當hashi的位置標記為存在EXIST并且對于值為key時,查找成功返回對應指針,反之,hashi位置為空則說明找不到,返回空指針。
- 注意,查找成功的條件中,必須有判斷標記是否為存在,具體原因我們先看Erase的實現:
Erase:
//刪除
bool Erase(const K& key)
{HashData<K, V>* ret = Find(key);if (ret == nullptr){return false;}else{ret->_state = DELETE;//偽刪除--_n;return true;}
}
- Erase 的實現非常簡單,先查找需刪除的值Key,只要Key不為空,就只需要將其狀態標記為刪除,然后--_n即可。
- 這是典型的偽刪除法,因為是偽刪除,原數據并沒有真正清除,所以前面Find查找值時需要進一步確認其狀態標記是否為EXIST。
Insert補充:
//插入
bool Insert(const pair<K, V>& kv)
{//不允許冗余if (Find(kv.first)){return false;}//...省略}
- 因為我們實現的哈希表是不支持冗余值的,所以插入值如果已經存在就返回false。
(5)仿函數實現
- 前面提到過,哈希表要求:1.數據Key支持轉換為整形的;2.數據Key支持==比較。
- 要求Key支持轉換為整形是因為取模運算,要求Key支持相等比較是因為Find接口中查找數據的需要。所以這些要求我們結合底層來看是很好理解的。
- 詳細思路:當key是string/Date等類型時,key不能取模,那么我們需要給HashTable增加?個仿函數,這個仿函數支持把key轉換成?個可以取模的整形,如果key可以轉換為整形并且不容易沖突,那么這個仿函數就用默認參數即可,如果這個Key不能轉換為整形,我們就需要自己實現?個仿函數傳給這個參數,實現這個仿函數的要求就是盡量key的每值都參與到計算中,讓不同的key轉換出的整形值不同。string 做哈希表的key非常常見,所以我們可以考慮把string特化一下。
仿函數的實現:
//定義默認仿函數(即一些實數數據)
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//string版的特化仿函數
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash += e;hash *= 131;}return hash;}
};//定義哈希表,將實現的仿函數作為默認參數傳給模板參數Hash
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{//獲取下一個質數//省略... public://構造//省略...//插入bool Insert(const pair<K, V>& kv){//省略... //哈希函數:除留余數法Hash hash;//實例化仿函數類size_t hash0 = hash(kv.first) % _tables.size();//將key的first數據進行轉換//省略...}//查找HashData<K, V>* Find(const K& key){//哈希函數:除留余數法Hash hash;size_t hash0 = hash(key) % _tables.size();//省略...}//刪除//省略...private:vector<HashData<K, V>> _tables;size_t _n = 0;
};
- 首先實現默認的仿函數,是因為作為模板參數,我們需要統一格式,一律使用Hash轉換數據類型,包括整形、浮點型等這類常見數學數據,這類數據我們之間強制轉換為size_t即可。
- 然后是特化的仿函數,也就是string,為什么要特化,因為我們平時使用unordered_map/unordered_set時,傳遞string模板參數后我們就可以直接使用,不需要進一步傳遞string類的對應仿函數,原因就是stl已經實現了string的特化仿函數,所以我們這里實現string的仿函數時也使用模板的特化。關于特化可以參考主頁文章,簡單點說特化可以讓編譯器根據數據類型自動選擇生成對應的仿函數。
- 然后重點就是特化的仿函數HashFunc<string>的實現過程,這里轉換為整形采用的是BKDR哈希算法,它的核心思路就是在字符串轉整形時每個字符的每一次運算都乘以一個素數P,P一般取131即可。為了確保字符串中的每一個字符都參與運算并且降低哈希沖突,所以我們依次相加每個字符的ASCII碼值,如果只是相加每個字符的ASCII碼值,那么就會出現擁有相同字符但是順序不同的字符串,轉換為整形后數值相同,這樣大大增加了哈希沖突的概率已經不利于Find接口準確查找數據。因此這里BKDR哈希算法就是在每一次相加字符后,進行一次乘等運算,這樣計算字符相同但是只要順序不同的字符串時,那么計算的結果就一定不同。
- 最后加入Hash轉換只有兩個地方會受到影響,一個是inset中的哈希函數,一個是Find中的哈希函數。
(6)完整代碼
#pragma once
#include <vector>
#include <algorithm>
using namespace std;//開放定址法的命名空間
namespace open_address
{//定義狀態標志enum State{EXIST,//存在EMPTY,//為空DELETE //刪除};//定義哈希數據template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};//定義默認仿函數(即一些實數數據)template<class K>struct HashFunc{size_t operator()(const K& key){return (size_t)key;//強轉為無符號整形即可}};//string版的特化仿函數template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash += e;hash *= 131;}return hash;}};//定義哈希表template<class K, class V, class Hash = HashFunc<K>>class HashTable{//獲取下一個質數inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;//定義質數列表大小static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);//返回大于等于n的質數return pos == last ? *(last - 1) : *pos;}public://構造HashTable(){_tables.resize(__stl_next_prime(0));}//插入bool Insert(const pair<K, V>& kv){//不允許冗余if (Find(kv.first)){return false;}//擴容if ((double)_n / (double)_tables.size() > 0.7)//計算負載因子,大于0.7就擴容{//創建一個新哈希表,重新建立映射HashTable<K, V> newHT;newHT._tables.resize(__stl_next_prime((unsigned long)(_tables.size() + 1)));//利用已有的Insert進行開放定址和沖突探測for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}}//交換_tables.swap(newHT._tables);}//哈希函數:除留余數法Hash hash;size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;//沖突探測(線性探測)while (_tables[hashi]._state == EXIST){hashi = (hash0 + i) % _tables.size();++i;}//插入_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}//查找HashData<K, V>* Find(const K& key){//哈希函數:除留余數法Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST && _tables[hashi]._kv.first == key){return &_tables[hashi];//找到了}//線性探測hashi = (hash0 + i) % _tables.size();++i;}return nullptr;//找不到}//刪除bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret == nullptr){return false;}else{ret->_state = DELETE;//偽刪除--_n;return true;}}private:vector<HashData<K, V>> _tables;//底層數據結構使用vectorsize_t _n = 0;//表中存儲數據個數};
}簡單運行測試:
#include <iostream>
#include "HashTable.h"
using namespace std;int main()
{open_address::HashTable<int, int> h1;h1.Insert({ 1,1 });h1.Insert({ 54,54 });//這兩值會產生哈希沖突cout << h1.Find(1) << endl;cout << h1.Find(54) << endl;h1.Erase(1);//刪除{1,1}只要對{54,54}沒影響就說明刪除沒問題cout << h1.Find(1) << endl;cout << h1.Find(54) << endl;return 0;
}運行結果:
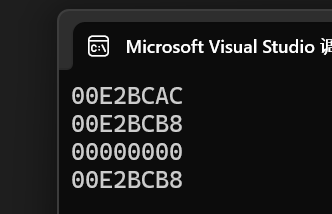
- 觀察前后地址變化,1的刪除沒有影響54的地址,可以說明程序無明顯問題
- 如果想觀察詳細的存儲信息,可在調試的監視窗口查看。
2.鏈地址法:
(1)基本框架
//鏈地址法的命名空間
namespace hash_bucket
{//定義哈希數據節點template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};//定義默認仿函數template<class K>struct HashFunc{};//string版的特化仿函數template<>struct HashFunc<string>{};//定義哈希表template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:private:vector<Node*> _tables;//指針數組size_t _n = 0;//有效數據個數};
}
- 因為鏈地址法解決哈希沖突是將沖突值串起來,形成一個鏈表(單鏈表),所以鏈地址法中就不需要定義每個值的狀態,但因為需要用到鏈表,所以HashNode中除了記錄數據_kv,還需要記錄當前映射位置的下一個節點_next。
- 有了開放定址法的經驗,這里就先把仿函數的框架搭出來,這里仿函數的作用和開放地址法是一樣的,都是將數據轉為可以進行取模計算的整形。
- 哈希表的大框架和開放定址法一樣,這里先加上第三個模板參數。
(2)Insert實現,構造函數實現
框架:
//插入
bool Insert(const pair<K, V>& kv)
{Hash hs;//擴容if (_n == _tables.size()){}//除留余數法計算映射位置size_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//創建新節點//頭插到哈希桶newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;
}
- 先說基本的插入,先計算映射位置hashi,并創建新節點newnode,然后需要注意的是,鏈地址法中鏈表的插入是采用頭插的方式,對于單鏈表來說,頭插也是最簡單的插入方法,我們先將newnode的下一個節點指針指向當前映射位置的鏈表頭節點,然后將鏈表的頭節點位置改為newnode,最后++_n即可。
擴容實現:
//獲取下一個質數inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;//定義質數列表大小static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);//返回大于等于n的質數return pos == last ? *(last - 1) : *pos;}
public://構造HashTable(){_tables.resize(__stl_next_prime(0), nullptr);}//插入bool Insert(const pair<K, V>& kv){Hash hs;//擴容if (_n == _tables.size()){size_t newSize = __stl_next_prime((unsigned long)(_tables.size() + 1));//新空間大小vector<Node*> newTables(newSize, nullptr);//新空間//遍歷舊表,把舊把數據重新裝到新表for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];//循環遍歷桶while (cur){Node* next = cur->_next;//先保存一份下一個節點//計算新位置size_t hashi = hs(cur->_kv.first) % newSize;//將cur頭插到新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;//接著遍歷當前桶(如果還有節點)}_tables[i] = nullptr;//將舊表置空}_tables.swap(newTables);//交換}//除留余數法計算映射位置size_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//創建新節點//頭插到哈希桶newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}
- 首先,我們依舊需要用到__stl_next_prime函數獲取下一個質數。
- 然后構造函數,使用vector的resize接口初始化基礎空間,大小為第一個質數,然后將其中每個鏈表初始化為nullptr。
- 接著是關鍵的insert擴容,前面提到過,鏈地址法中,負載因子可以大于1,但我們還是將負載因子設定為1,也就是當_n == _tables.size()時進行擴容操作。
- 擴容過程:依舊先計算新空間大小newSize,但與開放定址法不同的是,開放定址法是新建一個哈希表,復用insert然后swap交換,為什么鏈地址法不行呢,關鍵就是其中的鏈表,因為如果將舊鏈表復制拷貝一份再插入,最后再刪掉,這樣效率會很低而且鏈表的析構很麻煩。這里我們采用的方法是:將舊鏈表中的數據摘下來放到新鏈表中。我們新建一個vector就行,循環遍歷舊表,外循環遍歷vector中的每個鏈表,內循環遍歷每個鏈表具體內容并進行拷貝操作,首先cur先初始化為鏈表的頭節點_tables[i],然后需要next先保存一份cur的下一個節點,方便單鏈表遍歷,接著計算cur對應值的新映射位置hashi,再將其頭插到新vector,注意雖然這樣會導致新鏈表中的數據會顛倒,但是不影響查找。然后每遍歷完一個舊鏈表,我們需將其設置為空,斷開其與節點的聯系,最后全部轉移完成,就使用swap交換新舊表中的vector即可,空vector會隨著擴容結束自動析構。
(3)Find
//查找
Node* Find(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];//遍歷桶查找while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;
}
- 查找就很簡單了,先計算映射位置,然后遍歷對應的哈希桶即可。
- 實現Find后,insert就可以補充一個條件,避免冗余值插入:
//插入
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;//省略...
}(4)Erase
//刪除
bool Erase(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();//先計算映射位置Node* prev = nullptr;//用于記錄cur的上一個節點Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){//頭刪if (prev == nullptr){_tables[hashi] = cur->_next;}else//不是頭刪{prev->_next = cur->_next;}//刪除curdelete cur;--_n;return true;}//如果沒找到,繼續遍歷下一個節點prev = cur;cur = cur->_next;}return false;
}
- 這里刪除需要注意一下,因為是單鏈表元素的刪除,因此要考慮刪除節點對上一個節點的影響。
- 這里定義一個prev用于記錄cur的上一個節點,cur遍歷哈希桶,當我們找到對應節點時,需要先判斷是不是鏈表的第一個節點,如果prev==nullptr,那么就是,此時需要更改頭結點為cur的下一個節點,在刪除cur,如果不是頭刪,則需要將prev指向的節點的_next指針更改為cur的下一個節點,然后再刪除cur。記得--_n。如果沒找到,則繼續遍歷下個節點。
(5)析構函數
//析構
~HashTable()
{for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}
}
- 因為涉及自己實現的單鏈表,所以需要自己實現析構,析構就是遍歷釋放每一個節點。
- 當然,假如你想實現一個純粹的這樣的哈希表,那么可以使用直接使用 list 容器,也就是將vector中的指針元素用list替代,那么就不用寫析構,我們這里自己控制實現單鏈表是方便后續進一步封裝使用。
(6)仿函數
//定義默認仿函數
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//string版的特化仿函數
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash += e;hash *= 131;}return hash;}
};
- 這里仿函數和上面開放定址法一樣,就不再贅述了。
(6)完整代碼
#pragma once
#include <vector>
#include <algorithm>
using namespace std;//鏈地址法的命名空間
namespace hash_bucket
{//定義哈希數據節點template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};//定義默認仿函數template<class K>struct HashFunc{size_t operator()(const K& key){return (size_t)key;}};//string版的特化仿函數template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash += e;hash *= 131;}return hash;}};//定義哈希表template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;//獲取下一個質數inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;//定義質數列表大小static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);//返回大于等于n的質數return pos == last ? *(last - 1) : *pos;}public://構造HashTable(){_tables.resize(__stl_next_prime(0), nullptr);}//析構~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}//插入bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;Hash hs;//擴容if (_n == _tables.size()){size_t newSize = __stl_next_prime((unsigned long)(_tables.size() + 1));//新空間大小vector<Node*> newTables(newSize, nullptr);//新空間//遍歷舊表,把舊把數據重新裝到新表for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];//循環遍歷桶while (cur){Node* next = cur->_next;//先保存一份下一個節點//計算新位置size_t hashi = hs(cur->_kv.first) % newSize;//將cur頭插到新表cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;//接著遍歷當前桶(如果還有節點)}_tables[i] = nullptr;//將舊表置空}_tables.swap(newTables);//交換}//除留余數法計算映射位置size_t hashi = hs(kv.first) % _tables.size();Node* newnode = new Node(kv);//創建新節點//頭插到哈希桶newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}//查找Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];//遍歷桶查找while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}//刪除bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();//先計算映射位置Node* prev = nullptr;//用于記錄cur的上一個節點Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){//頭刪if (prev == nullptr){_tables[hashi] = cur->_next;}else//不是頭刪{prev->_next = cur->_next;}//刪除curdelete cur;--_n;return true;}//沒找到,繼續遍歷下一個節點prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;//指針數組size_t _n = 0;//有效數據個數};
}測試:
#include <iostream>
#include "HashTable.h"
using namespace std;int main()
{hash_bucket::HashTable<int, int> h1;h1.Insert({ 1,1 });h1.Insert({ 54,54 });//這兩值會產生哈希沖突cout << h1.Find(1) << endl;cout << h1.Find(54) << endl;h1.Erase(1);//刪除{1,1}只要對{54,54}沒影響就說明刪除沒問題cout << h1.Find(1) << endl;cout << h1.Find(54) << endl;return 0;
}運行結果:
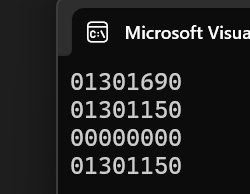
- 總體上來說,鏈地址法是比開放定址法更優的,因為它不存在搶占位置的情況,即便在一些極端情況下,比如數據全掛在某一個串上時,此時也有解決方法,比如前面提到的將鏈表轉換為一棵紅黑樹,那么查找效率就不會很低。
總結
以上就是本文的全部內容了,感謝支持!


實現底層)









)






