文章目錄
- 一.容器適配器
- 1. 本質:
- 2. 接口:
- 3. 迭代器:
- 4. 功能:
- 二.deque的簡單介紹
- 1.概念與特性
- 2.結構與底層邏輯
- 2.1 雙端隊列(deque)結構:
- 2.2 deque的內部結構
- 2.3 deque的插入與刪除操作:
- 3.總結
- 3.1 deque和list,vector對比
- 3.2 常用vector或list,而不是deque
- 三.仿函數初步
- 1.仿函數的特點
- 2.仿函數的基本實現
- 3.仿函數,普通函數,函數指針
- 四.優先隊列(priority_queue)的簡單介紹
- 1.核心本質
- 2.核心操作特點
- 3.底層實現依賴
- 4.關鍵接口(以你的代碼+標準庫邏輯為例)
- 5.總結
- 五.priority_queue的模擬實現
- 1.頭文件"priority_queue.h"
- 2.測試文件"test.cpp"
一.容器適配器
容器適配器的核心就像交流電適配器:
- 核心作用:對底層容器(如
vector、deque)進行“包裝” - 關鍵效果:讓原本的容器以特定數據結構(棧、隊列等)形式呈現
- 核心價值:屏蔽底層復雜操作,只提供適配后結構的專屬接口,精準滿足特定場景的數據操作需求(如棧的“后進先出”、隊列的“先進先出”)。
1. 本質:
封裝底層容器,不直接存儲數據
- 容器適配器本身不實現數據存儲邏輯,而是通過封裝現有基礎容器(如
vector、deque、list等)來實現功能。 - 底層容器的選擇可手動指定(需滿足適配器的接口要求),若不指定則使用標準庫默認的底層容器(如
stack默認用deque)。
2. 接口:
受限且專注于適配后的數據結構邏輯
- 容器適配器僅提供適配后的數據結構的核心操作,屏蔽底層容器的復雜接口。
例如:stack僅提供push()(棧頂插入)、pop()(棧頂刪除)、top()(訪問棧頂)等符合「后進先出(LIFO)」邏輯的操作;queue僅提供push()(隊尾插入)、pop()(隊頭刪除)等符合「先進先出(FIFO)」邏輯的操作。
3. 迭代器:
不支持迭代器訪問,隱藏底層細節
- 容器適配器不對外暴露迭代器,用戶無法通過迭代器遍歷適配器中的元素。
- 這一設計的目的是嚴格限制數據操作方式,確保適配后的數據結構邏輯(如棧只能從棧頂操作)不被破壞。
4. 功能:
適配為特定數據結構
- 容器適配器的核心作用是將底層容器「適配」為常用的數據結構,標準庫提供三種典型適配器:
stack:適配為棧(LIFO 結構);queue:適配為隊列(FIFO 結構);priority_queue:適配為優先隊列(元素按優先級自動排序)。
二.deque的簡單介紹
1.概念與特性
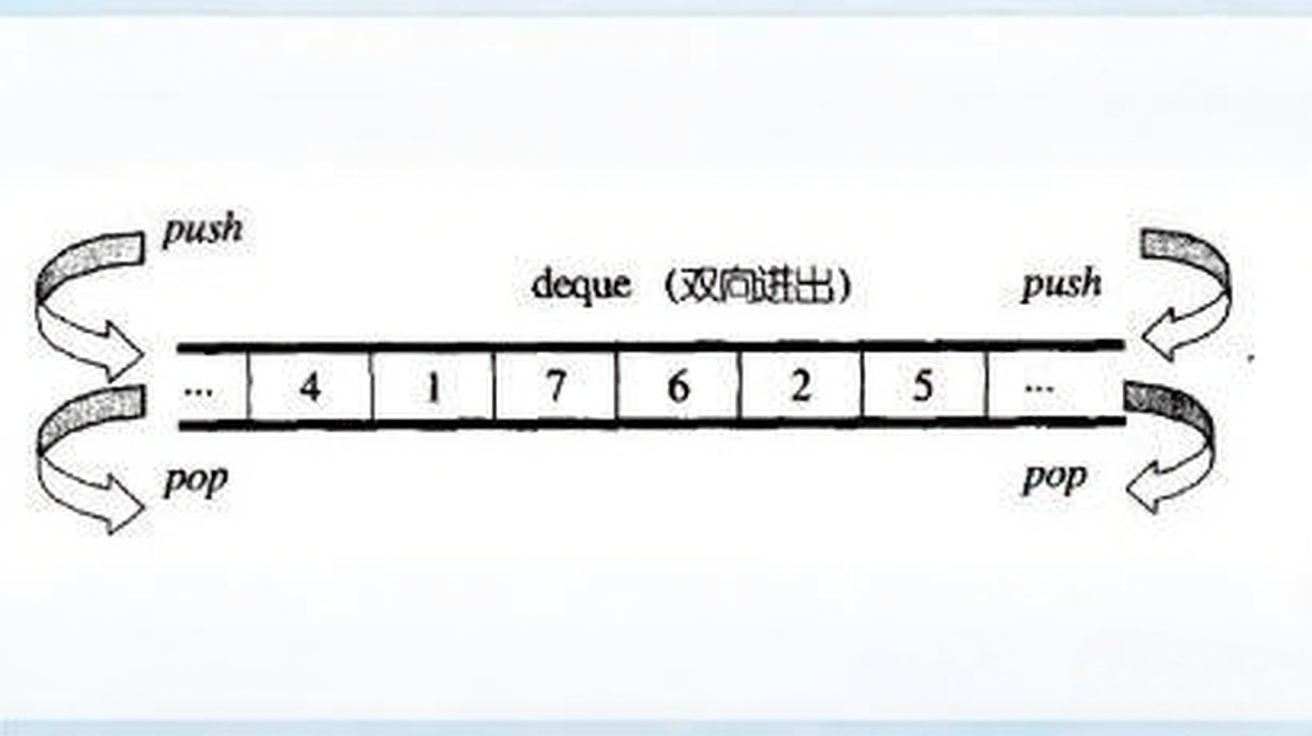
上圖中展示的是雙端隊列(deque,Double-Ended Queue)的結構和操作方式。
雙端隊列是一種允許在隊列兩端進行插入和刪除操作的線性數據結構,它結合了棧和隊列的特性,支持在隊列的前端(front)和后端(back)進行元素的添加(push)和移除(pop)操作。
在 C++ 標準庫中,std::deque 是雙端隊列的實現,它具有以下特點:
優點:
- 動態擴展:雙端隊列的大小可以動態變化,支持在運行時根據需要擴展或收縮。
- 隨機訪問:雖然雙端隊列主要用于兩端操作,但它也支持通過索引進行隨機訪問,這一點與
std::vector類似。 - 高效操作:在雙端隊列的兩端進行插入和刪除操作的時間復雜度是 O(1),而在中間進行操作的時間復雜度是 O(n)。
缺點:
- 中間操作低效:在非兩端位置進行插入/刪除,需移動大量元素,時間復雜度為 O(n)。
- 內存碎片風險:由多段不連續內存塊組成,頻繁操作易產生內存碎片。
- 內存開銷較高:需額外存儲內存塊管理信息,內存占用多于
vector。 - 迭代器穩定性差:擴容或結構變動時,迭代器、指針、引用可能全部失效。
2.結構與底層邏輯
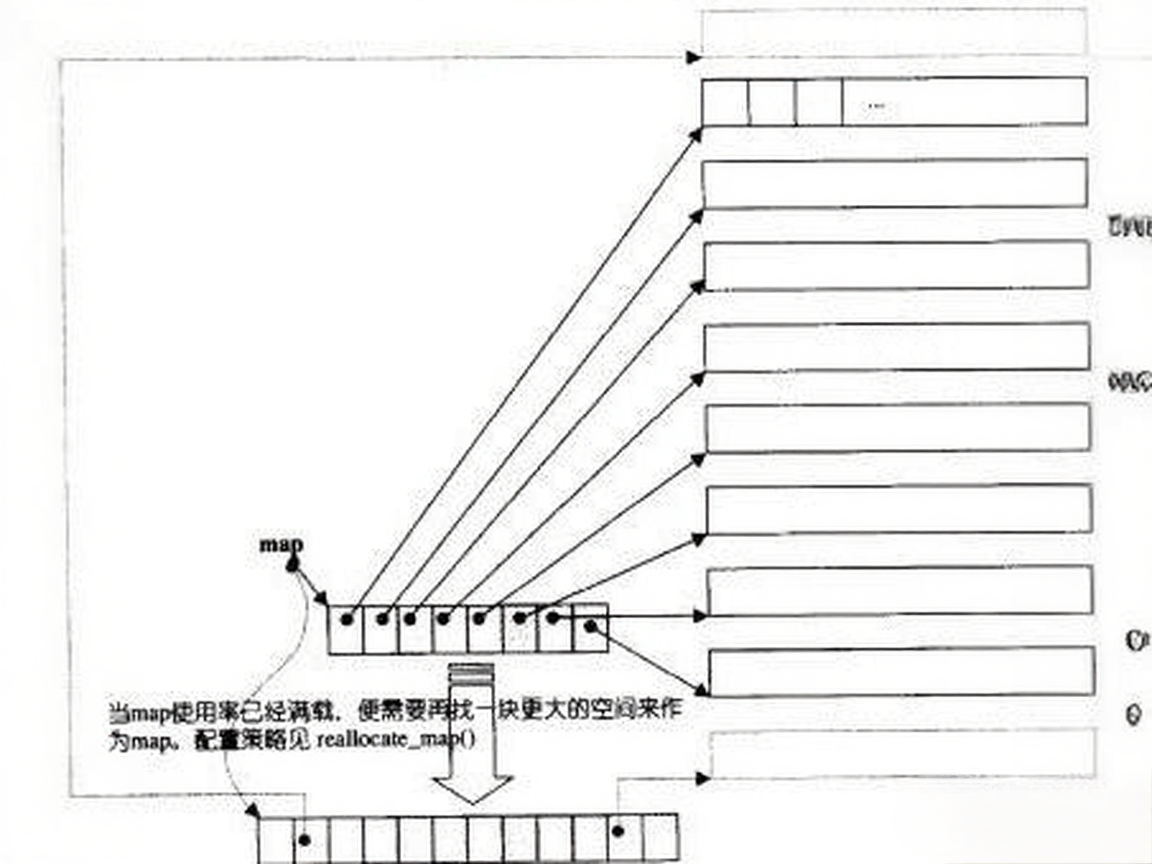
2.1 雙端隊列(deque)結構:
- 分段存儲:由多段連續內存塊組成,通過
map(指針數組)管理這些塊,實現邏輯上的連續。 - 雙向擴展:可從兩端快速插入/刪除(時間復雜度 O(1)),無需像
vector那樣整體擴容。 - map 管理:
map存儲內存塊指針,當map滿時需重新分配更大的map并復制指針(類似擴容)。 - 隨機訪問:通過
map定位內存塊,再通過偏移量訪問元素,時間復雜度 O(1),但緩存局部性弱于vector。 - 中間操作劣勢:在非兩端位置插入/刪除時,需移動元素,時間復雜度 O(n),效率低于鏈表。
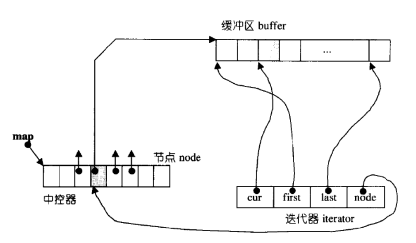
2.2 deque的內部結構
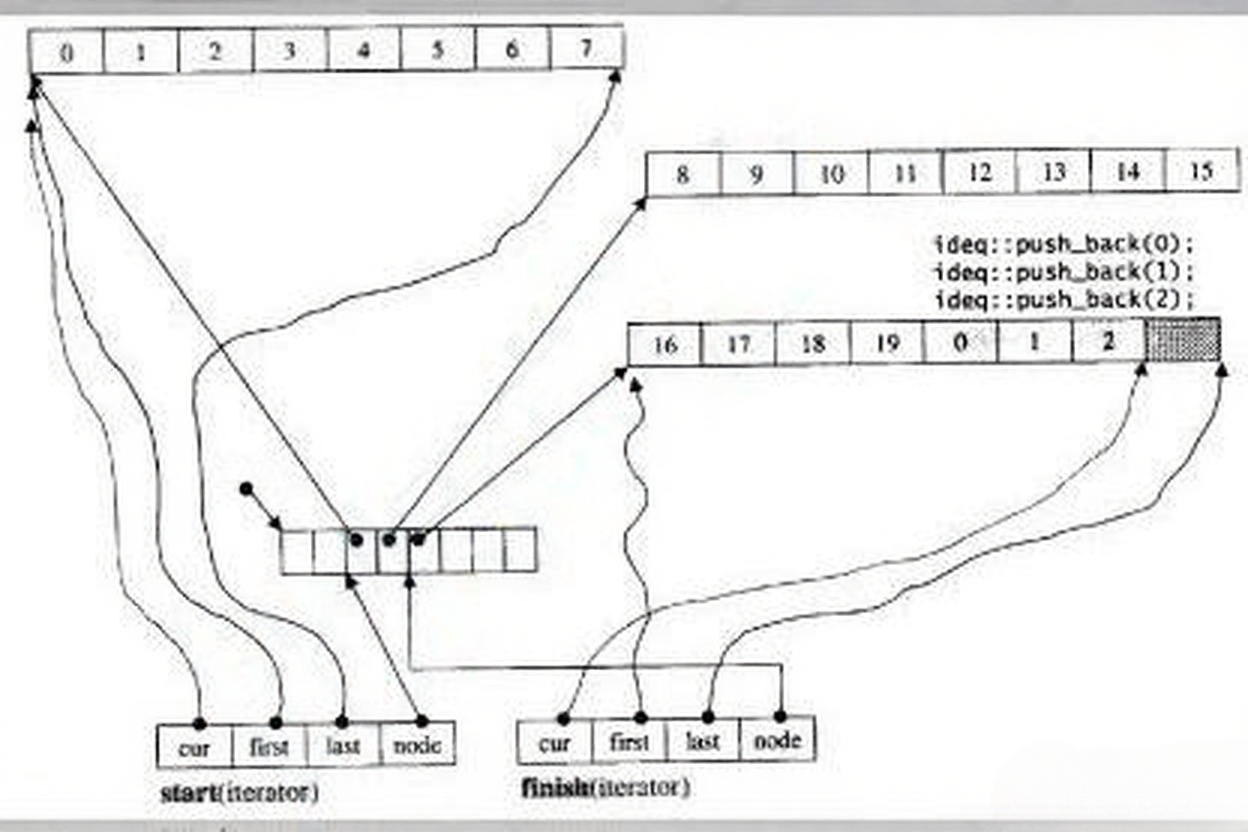
以上圖片展示的是C++標準庫中雙端隊列(deque)的內部結構。以下是圖中各部分的核心要點:
- 緩沖區(buffer):存儲實際數據的連續內存塊,多個緩沖區通過map管理。
- map:指針數組,每個指針指向一個緩沖區,實現邏輯上的連續。
- 迭代器(iterator):包含四個關鍵成員:
cur:指向當前元素的指針。first:指向當前緩沖區起始位置的指針。last:指向當前緩沖區末尾位置的指針。node:指向map中當前緩沖區指針的指針。
- 中控器:管理map的分配與擴容,確保deque動態擴展的穩定性。
- 節點(node):map中的元素,每個節點對應一個緩沖區的指針。
這種結構使得deque能夠高效地在兩端進行插入和刪除操作,同時支持隨機訪問。
2.3 deque的插入與刪除操作:
- 插入操作:
- 兩端插入:通過
push_back和push_front實現,時間復雜度為O(1)。在對應端的緩沖區末尾或起始位置直接添加元素,若緩沖區已滿則自動分配新緩沖區。 - 中間插入:通過
insert實現,時間復雜度為O(n)。需要移動插入位置之后的所有元素,效率較低。
- 兩端插入:通過
- 刪除操作:
- 兩端刪除:通過
pop_back和pop_front實現,時間復雜度為O(1)。直接移除對應端的元素,若緩沖區為空則釋放該緩沖區。 - 中間刪除:通過
erase實現,時間復雜度為O(n)。需要移動刪除位置之后的所有元素,效率較低。
- 兩端刪除:通過
- 內存管理:
- 插入時若緩沖區滿,會自動分配新緩沖區,并更新map中的指針。
- 刪除時若緩沖區為空,會自動釋放該緩沖區,并更新map中的指針。
3.總結
3.1 deque和list,vector對比
deque 像是 vector 和 list 的結合:
- 兼具
vector的隨機訪問能力(通過分段連續內存實現)和list的兩端高效操作特性(O(1) 時間復雜度)。 - 避免了
vector頭部操作低效和擴容成本高的問題,也緩解了list隨機訪問差、緩存友好性低的缺陷。 - 但中間操作效率不及
list,隨機訪問性能略遜于vector,是一種平衡型選擇。
3.2 常用vector或list,而不是deque
多數情況選 vector 或 list 而非 deque,因:
- 場景適配更精準:
vector強于隨機訪問,list強于中間操作,覆蓋多數需求; - 性能更穩定:
deque隨機訪問略遜于vector,中間操作遠不如list; - 更簡單直觀:
vector/list實現和特性更易理解,使用更穩妥。
三.仿函數初步
在C++中,仿函數(Functor) 是一種特殊的對象,它可以像函數一樣被調用。從技術上講,仿函數是實現了operator()重載的類或結構體的實例,這使得對象可以使用函數調用語法(如obj())來執行操作。
1.仿函數的特點
- 行為類似函數,但可以保存狀態(成員變量)
- 可以像函數一樣作為參數傳遞
- 比普通函數更靈活,因為可以攜帶額外數據
- 常用于STL算法中(如排序、查找等)
2.仿函數的基本實現
實現“小于比較”的仿函數功能
#include<iostream>
using namespace std;
namespace yl {// 定義模板類 less,用于實現“小于比較”的仿函數功能template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};
}int main(){yl::less<int> lessfunc;
cout << lessfunc(1, 2)<<endl;return 0;
}
仿函數優化冒泡排序
#include <iostream>
#include <vector>
using namespace std;// 仿函數:升序比較
template <typename T>
struct Less {bool operator()(const T& a, const T& b) const {return a < b; }
};// 仿函數:降序比較
template <typename T>
struct Greater {bool operator()(const T& a, const T& b) const {return a > b; }
};// 通用冒泡排序函數,通過仿函數定制比較規則
template <typename T, typename Compare>
void bubbleSort(vector<T>& arr, Compare comp) {int n = arr.size();for (int i = 0; i < n - 1; ++i) {for (int j = 0; j < n - i - 1; ++j) {// 調用仿函數的()運算符進行比較if (comp(arr[j], arr[j + 1])) { swap(arr[j], arr[j + 1]);}}}
}int main() {vector<int> arr = {64, 34, 25, 12, 22, 11, 90};// 用Less仿函數,升序排序bubbleSort(arr, Less<int>());cout << "升序排序結果:";for (int num : arr) {cout << num << " ";}cout << endl;// 重置數組arr = {64, 34, 25, 12, 22, 11, 90};// 用Greater仿函數,降序排序bubbleSort(arr, Greater<int>());cout << "降序排序結果:";for (int num : arr) {cout << num << " ";}cout << endl;return 0;
}
3.仿函數,普通函數,函數指針
| 對比維度 | 普通函數 | 函數指針 | 仿函數 |
|---|---|---|---|
| 本質 | 一段可執行代碼塊 | 指向函數的指針變量(內存地址) | 重載了()運算符的類/結構體實例 |
| 狀態管理 | 無狀態,依賴參數/全局變量 | 無狀態,依賴所指函數的狀態管理 | 通過成員變量保存狀態,每個實例獨立 |
| 調用方式 | 直接通過函數名調用 | 通過指針變量間接調用 | 像函數一樣調用對象(obj()) |
| 行為靈活性 | 邏輯固定,修改需重寫函數 | 可指向不同函數改變行為 | 可通過構造函數配置行為,同類型可有不同實例 |
| 作為參數傳遞 | 可直接傳遞函數名 | 傳遞指針變量 | 傳遞對象實例 |
| 類型信息 | 僅函數簽名 | 僅表示函數簽名 | 自身是類類型,攜帶完整類型信息 |
| 泛型編程適配性 | 適配性一般 | 模板中適配性差,難優化 | 易被模板推導,編譯器可內聯優化 |
| 擴展性 | 擴展需新增函數 | 擴展依賴新增函數并重新指向 | 可通過繼承等面向對象特性擴展 |
總結:
-
普通函數
- 核心價值:最基礎的可調用單元,語法簡單直接
- 關鍵局限:行為完全固定,無法動態調整或攜帶狀態
-
函數指針
- 核心價值:通過指向不同函數,實現行為動態切換(解耦調用者與具體實現)
- 關鍵局限:仍無狀態管理能力,本質是"函數地址的容器"
-
仿函數
- 核心突破:同時具備函數調用能力與對象狀態管理(通過成員變量保存上下文)
- 關鍵優勢:在泛型編程中表現最優——既能像函數一樣被調用,又能通過對象屬性定制行為,且易被編譯器優化
簡言之:普通函數是"固定行為",函數指針是"可變行為但無記憶",仿函數是"可變行為且有記憶"。
四.優先隊列(priority_queue)的簡單介紹
1.核心本質
- 是容器適配器,基于“嚴格弱排序”規則維護元素,默認保證隊首(堆頂)始終是當前隊列里“最大元素”(大根堆特性 ,也可通過仿函數改小根堆),邏輯類似堆結構
2.核心操作特點
- 支持插入元素(隨時往隊列里加元素),但只能訪問/刪除堆頂(最大/指定規則的優先級最高元素) ,類似堆的
top訪問、push插入、pop彈出邏輯
3.底層實現依賴
- 基于容器適配器封裝底層容器(如
vector/deque,默認用vector),需底層容器支持:- 基礎操作:
empty()(判空)、size()(元素個數)、push_back()(尾插)、pop_back()(尾刪 ,但優先隊列邏輯上是從“堆頂”刪,實際通過交換+尾刪實現) - 迭代器要求:需隨機訪問迭代器(像
vector/deque,list是雙向迭代器,不滿足默認priority_queue需求,你自定義queue用list是因為自己封裝邏輯沒嚴格限制迭代器 )
- 基礎操作:
4.關鍵接口(以你的代碼+標準庫邏輯為例)
| 接口 | 功能說明 |
|---|---|
priority_queue() | 構造空優先隊列 |
priority_queue(first, last) | 用迭代器區間 [first, last) 初始化,內部自動建堆 |
empty() | 判斷是否為空 |
top() | 返回堆頂元素(最大/自定義優先級最高) |
push(x) | 插入元素 x,插入后會調整堆結構維持優先級規則 |
pop() | 刪除堆頂元素(實際先交換堆頂和尾元素,刪尾元素,再調整堆結構) |
5.總結
簡單說,標準庫 priority_queue 就是“自動維護堆結構的適配器”,借助底層容器+堆調整函數,讓用戶方便用“堆”的特性(始終訪問優先級最高元素),你代碼里自己實現的 priority_queue 也復刻了這個思路,只是死循環問題導致運行異常,修復后就能正常體現優先隊列(大根堆)邏輯
五.priority_queue的模擬實現
1.頭文件"priority_queue.h"
#pragma once
#include<iostream>
#include<functional>
#include<vector>
#include<cassert>
using namespace std;namespace yl
{template<typename T,typename container=vector<T>>class priority_queue{private://子結點中有一個大于父結點就可以向下調整void adjust_down(size_t parent) {size_t child = parent * 2 + 1; // 左孩子初始位置while (child < _con.size()) {// 先找到左右孩子中值較大的那個if (child + 1 < _con.size() && _con[child + 1] > _con[child]) {child++; // 右孩子更大,指向右孩子}// 如果最大的孩子大于父節點,交換并繼續向下調整if (_con[child] > _con[parent]) {swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else {// 父節點大于等于子節點,堆性質已滿足,退出循環break;}}}// 向上調整函數:用于維護大根堆性質(當插入新元素時)// 從指定子節點開始,向上與父節點比較并交換,直到滿足堆條件void adjust_up(size_t child){// 計算父節點索引(堆的父節點計算公式)size_t parent = (child - 1) / 2;// 當子節點索引大于0時(未到達根節點),繼續調整while (child > 0){// 若子節點值大于父節點值,違反大根堆性質,需要交換if (_con[child] > _con[parent]){swap(_con[child], _con[parent]);// 更新子節點為原父節點位置,繼續向上調整child = parent;// 計算新的父節點索引parent = (parent - 1) / 2;}else{// 子節點值小于等于父節點,已滿足大根堆性質,退出調整break;}}}public:priority_queue() = default;//強制生成默認構造template<typename InputIterator>priority_queue(InputIterator first,InputIterator last):_con(first,last){//向下調整算法建堆for (size_t i = (_con.size() - 2) / 2; i < _con.size() && i >= 0; i--){//i < _con.size() && i >= 0 作為循環條件://i < _con.size() 防止 i 越界(理論上 i 從(size - 2) / 2 遞減到 0,不會越界,但加上更安全)。// i >= 0 利用 size_t 的無符號特性:// 當 i 減到 0 后,再執行 --i 會變成 SIZE_MAX(一個極大的無符號數),此時 i >= 0 會失效,循環終止。adjust_down(i);}}// 插入元素void push(const T& x){_con.push_back(x);// 對新插入的元素(位于末尾)進行向上調整,維護堆性質adjust_up(_con.size() - 1);}// 從堆中刪除頂部元素(堆頂為最大值)void pop(){// 交換堆頂元素與最后一個元素(便于后續刪除最后一個元素)swap(_con[0], _con[_con.size() - 1]); _con.pop_back();// 對新的堆頂元素進行向下調整,維護堆性質adjust_down(0);}// 獲取最大值(這里建的是大堆)const T& top()const{return _con[0];}// 獲取元素的個數size_t size(){return _con.size();}bool empty() const{return _con.empty();}private:container _con;};
}
2.測試文件"test.cpp"
#include"priority_queue.h"void test01()
{vector<int> v = { 1,23,14,51,66,73,29,30 };yl::priority_queue<int,vector<int>> pq(v.begin(),v.end());while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;
}
int main()
{test01();return 0;
}輸出結果如下:
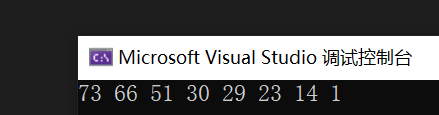









)









