提示:文章寫完后,目錄可以自動生成,如何生成可參考右邊的幫助文檔
文章目錄
- @[TOC](文章目錄)
- 一,ext2文件系統
- 1-1 宏觀認識
- 1-2 Block Group
- 1-3 塊組內部構成
- 1-3-1 超級塊(Super Block)
- 1-3-2 塊組描述符表GDT(Group Descriptor Table)
- 1-3-3 塊位圖(Block Bitmap)
- 1-3-4 inode位圖(Inode Bitmap)
- 1-3-5 i節點表(Inode Table)
- 1-3-6 Data Block
- 1-4 inode和datablock映射
- 1-4-1 作用
- 1-5 目錄與文件名
- 1-6 路徑解析
- 1-7 路徑緩存
- 1-8 掛載分區
- 二,軟硬鏈接
- 2-1 硬鏈接
- 2-2 軟鏈接
- 2-3 軟硬鏈接對比
文章目錄
- @[TOC](文章目錄)
- 一,ext2文件系統
- 1-1 宏觀認識
- 1-2 Block Group
- 1-3 塊組內部構成
- 1-3-1 超級塊(Super Block)
- 1-3-2 塊組描述符表GDT(Group Descriptor Table)
- 1-3-3 塊位圖(Block Bitmap)
- 1-3-4 inode位圖(Inode Bitmap)
- 1-3-5 i節點表(Inode Table)
- 1-3-6 Data Block
- 1-4 inode和datablock映射
- 1-4-1 作用
- 1-5 目錄與文件名
- 1-6 路徑解析
- 1-7 路徑緩存
- 1-8 掛載分區
- 二,軟硬鏈接
- 2-1 硬鏈接
- 2-2 軟鏈接
- 2-3 軟硬鏈接對比
前言
本文閱讀需要先掌握Ext系列文件系統(硬件篇)
一,ext2文件系統
1-1 宏觀認識
- 所有的準備工作已經完成,是時候認識一下
文件系統了。我們想要在硬盤上存儲文件,必須先將硬盤格式化為某種格式的文件系統,才能進行文件的讀寫操作。文件系統的作用就是組織和管理硬盤中的文件和數據。 - 在 Linux 系統中,最常見的是
ext 系列的文件系統。它的早期版本是ext2,后來發展出了ext3和ext4。雖然 ext3 和 ext4 對 ext2 做了許多增強和優化,但其核心設計并沒有發生根本性變化,因此我們仍然以較早的 ext2 作為講解對象。 - ext2 文件系統會將整個分區劃分成若干個大小相同的
塊組(Block Group),如下圖所示。只要能夠管理一個分區,就能夠管理所有分區,也就能實現對整個磁盤中文件的統一管理。
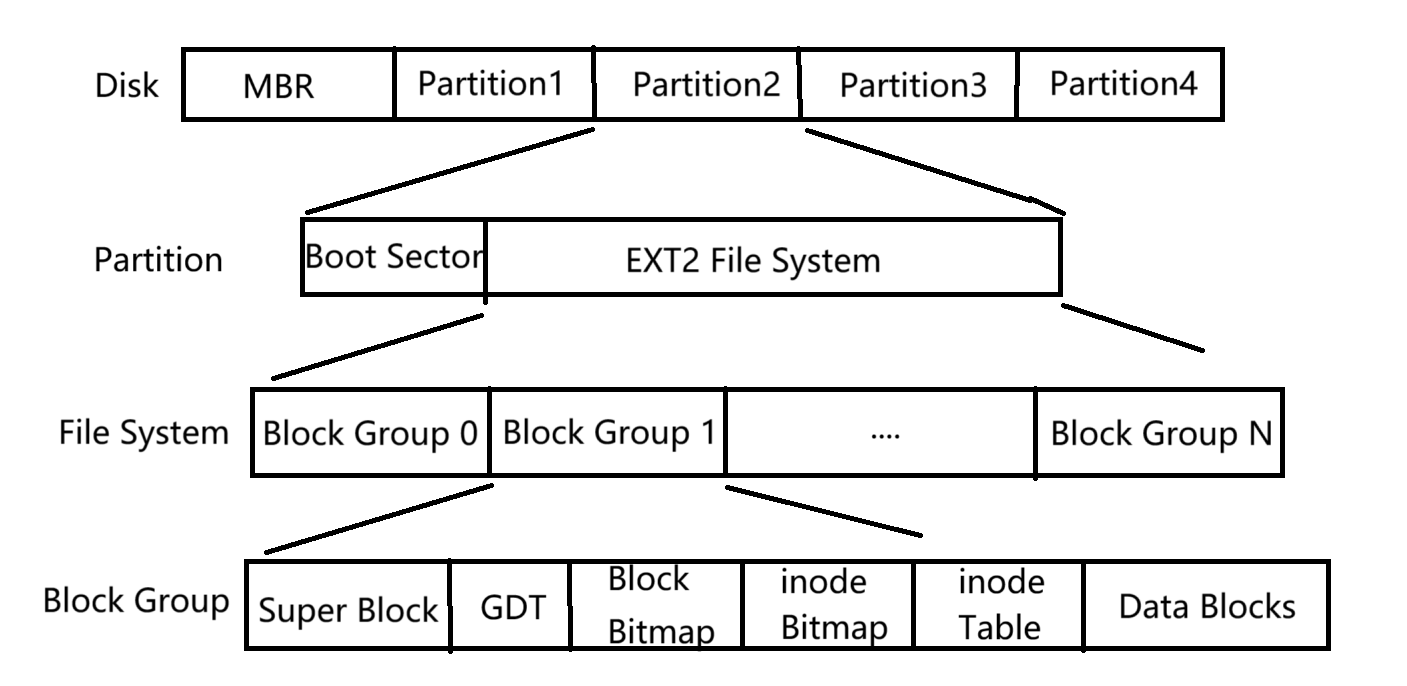
- 在硬盤結構中,最前面的
啟動塊(Boot Block 或 Boot Sector)大小是固定的,為1KB,這是由 PC 標準所規定的。啟動塊用于存儲磁盤的分區信息(如分區表)以及啟動引導程序(Bootloader),是整個系統啟動過程中的關鍵區域。 - 由于啟動塊的作用十分重要,任何文件系統都不能覆蓋或修改它。這也是文件系統在格式化分區時,都會從啟動塊之后的位置開始布局自身結構的原因。
- 因此,在啟動塊之后,才是 ext2 文件系統的起始區域,包括
超級塊(Super Block)、組描述符表(Group Descriptor Table)、塊位圖、inode 位圖、inode 表等核心結構。
1-2 Block Group
Block Group是 Ext 文件系統為了提升效率而設計的“磁盤管理單元”,類似把大倉庫分成多個小房間,每個房間獨立管理自己的物品。
1-3 塊組內部構成
一個塊組由超級塊副本、組描述符副本、塊位圖、inode位圖、inode表和數據塊組成,用于局部管理文件系統的元數據和文件數據。
1-3-1 超級塊(Super Block)
- 超級塊(Super Block)是一個結構體用于存放文件系統本身的結構信息,描述整個分區的文件系統狀態和配置。它記錄了大量關鍵數據,包括:
block和inode的總數、未使用的block和inode數量、每個block和inode的大小、文件系統創建和掛載的時間、上一次寫入數據的時間、上一次進行文件系統檢查(fsck)的時間等其他重要的文件系統元信息。 - 由于超級塊在整個文件系統中的地位至關重要,一旦其信息被破壞,就可能導致整個文件系統無法識別和使用,因此可以說超級塊的損壞等同于文件系統結構的損壞。
- 超級塊(Super Block)在每個塊組的開頭都會保存一份備份拷貝(第一個塊組必須包含,后續塊組則可以選擇是否備份)。為了確保文件系統在磁盤某些扇區出現物理損壞時依然能夠正常工作,文件系統會將超級塊的信息備份到多個塊組中。這些超級塊備份區域的數據會保持一致,從而提高文件系統的可靠性和容錯能力。
超級塊源代碼
struct ext2_super_block {__le32 s_blocks_count; /* 總的 block 數量 */__le32 s_inodes_count; /* 總的 inode 數量 */__le32 s_free_blocks_count; /* 未使用的 block 數量 */__le32 s_free_inodes_count; /* 未使用的 inode 數量 */__le32 s_log_block_size; /* 一個 block 的大小 */__le16 s_inode_size; /* 一個 inode 的大小 */__le32 s_mtime; /* 最近一次掛載時間 */__le32 s_wtime; /* 最近一次寫入數據的時間 */__le32 s_lastcheck; /* 最近一次檢驗磁盤的時間 */....
};
1-3-2 塊組描述符表GDT(Group Descriptor Table)
塊組描述符表是一個數組用于描述各個塊組的屬性信息。整個分區被劃分為多個塊組,因此塊組描述符的數量與塊組數相同。每個塊組描述符記錄該塊組的關鍵信息,比如 inode 表的起始位置、數據塊的起始位置,以及空閑的 inode 和數據塊數量等。為了提高文件系統的可靠性,塊組描述符表會在每個塊組的開頭保存一份備份拷貝。
struct ext2_group_desc {__le32 bg_block_bitmap; /* 塊位圖所在塊號 */__le32 bg_inode_bitmap; /* inode 位圖所在塊號 */__le32 bg_inode_table; /* inode 表起始塊號 */__le16 bg_free_blocks_count; /* 該塊組中空閑塊數 */__le16 bg_free_inodes_count; /* 該塊組中空閑 inode 數 */__le16 bg_used_dirs_count; /* 該塊組中已使用的目錄數量 */__le16 bg_flags; /* 標志位 */__le32 bg_exclude_bitmap_lo; /* 用于防止碎片的排除位圖(低32位) */__le16 bg_block_bitmap_csum_lo; /* 塊位圖校驗和低16位 */__le16 bg_inode_bitmap_csum_lo; /* inode 位圖校驗和低16位 */__le16 bg_itable_unused; /* 未使用的 inode 計數 */__le16 bg_checksum; /* 描述符校驗和 *//* ext4 擴展字段(高32位校驗和等)省略 */
};
1-3-3 塊位圖(Block Bitmap)
Block Bitmap 是位圖數組記錄了數據塊(Data Block)使用情況,用于標示哪個數據塊已經被占用,哪個數據塊仍然是空閑的。
1-3-4 inode位圖(Inode Bitmap)
inode位圖是一個數組每個bit表??個inode是否空閑可?。
1-3-5 i節點表(Inode Table)
Inode 表(Inode Table)是一個由結構體數組組成的表,每個 inode 結構體存儲一個文件或目錄的元數據信息(如大小、權限、時間戳、數據塊指針等)。
1-3-6 Data Block
數據塊(Data Block)是用于存放實際文件內容的區域,不同類型的文件,其數據在數據塊中的組織方式有所不同:
- 普通文件(Regular File):文件的實際內容直接保存在數據塊中。文件較大時,可能需要多個數據塊。
- 目錄文件(Directory):目錄下的所有子文件名和子目錄名保存在數據塊中。數據塊中保存的是目錄項(Directory Entry),每個目錄項包含文件名和對應的 inode 編號。至于 ls -l 等命令顯示的權限、大小、時間等信息,則存儲在對應文件的 inode 中。
- 符號鏈接、設備文件等特殊文件:其存儲結構可能不同,視具體實現而定。
1-4 inode和datablock映射
1-4-1 作用
-
在 inode 結構中,存在一個數組字段:
__le32 i_block[EXT2_N_BLOCKS],其中EXT2_N_BLOCKS = 15,該數組用于指向文件實際存儲的數據塊(block),實現 inode 到數據塊的映射關系。 -
因此,對于文件而言,“文件 = 內容 + 屬性” 的結構通過
inode得以完整表示,其中內容通過i_block定位到數據塊,屬性則直接保存在 inode 中。 -
一個文件的數據可能分布在多個數據塊(block)中
-
因為一個數據塊大小固定(通常是 1KB、2KB 或 4KB),如果文件很大,就必須使用多個塊
-
為了實現從 inode 到這些數據塊的映射,inode 中有一個字段:
__le32 i_block[15]; // EXT2_N_BLOCKS = 15
i_block[15] 的結構如下:
- 0 - 11:直接塊(Direct Blocks)共 12 個,直接指向數據塊
- 12:一級間接塊(Indirect Block),指向一個塊,這個塊中存放的是數據塊的地址
- 13:二級間接塊(Double Indirect),指向一個塊,該塊中是一級間接塊的地址
- 14:三級間接塊(Triple Indirect),原理類似,遞歸兩次,最終指向數據塊
例子:
- 如果一個塊是 1KB,一個文件大小是 20KB,那就需要 20 個塊。
- 前 12 個塊可以直接由 i_block[0] 到 i_block[11] 找到。
- 剩下的 8 個就要依賴 i_block[12]
(一級間接塊)來繼續定位。
創建一個文件:

上圖創建文件的流程如下圖

- 存儲屬性(分配 inode)
- 內核首先從
inode 位圖中尋找一個空閑 inode(例如編號為 263466),并將該文件的屬性信息(如權限、所有者、時間戳、文件大小等)記錄到這個inode中。
- 內核首先從
- 存儲數據(分配數據塊)
- 該文件需要占用 3 個數據塊,內核從數據塊位圖中找到了空閑的數據塊編號為:300、500 和 800。
內核將緩沖區中的文件數據依次寫入這些塊中:
第一個數據塊 → 300
第二個數據塊 → 500
第三個數據塊 → 800
- 該文件需要占用 3 個數據塊,內核從數據塊位圖中找到了空閑的數據塊編號為:300、500 和 800。
- 記錄分配情況(更新 i_block[])
- 文件內容按順序存放在塊號 300、500 和 800 中。
內核會將這 3 個數據塊的編號寫入inode的i_block[]數組中,作為該文件的塊映射信息。這樣,文件的數據位置就與inode建立了連接。
- 文件內容按順序存放在塊號 300、500 和 800 中。
- 添加文件名到目錄(建立文件名與 inode 的對應)
- 新文件命名為
"abc"。
內核會在當前目錄文件中添加一條目錄項(目錄項 = 文件名 + inode 號),即:
(abc, 263466)
這樣,用戶通過文件名 “abc” 就可以在目錄中查到對應的 inode 號,從而找到文件的屬性和數據內容。
- 新文件命名為
總結:
-
一個 inode 對應一個文件,而 i_block[15] 數組提供了從該 inode 到所有實際存儲文件數據的 block 的完整路徑。
-
分區完成后的格式化操作,本質上是對該分區進行文件系統的初始化。它會將分區劃分為若干個
Block Group(塊組),并在每個塊組中寫入關鍵的管理信息,如:Super Block(SB)、Group Descriptor Table(GDT)、Block Bitmap、Inode Bitmap、Inode Table等。這些管理信息的集合,統稱為文件系統結構。 -
只要知道一個文件的
inode 號,就能通過算法計算出該 inode 位于哪一個塊組,再根據該塊組中的 inode table 精確定位到這個 inode 的位置。 -
拿到 inode 后,就可以讀取該文件的
所有屬性(權限、大小、時間等),以及通過i_block[]數組定位到 實際存儲內容的數據塊,從而獲取或修改文件的全部信息。
1-5 目錄與文件名
目錄也是一種文件,但在磁盤層面,并不存在“目錄”這一獨立概念,只有“文件屬性”和“文件內容”這兩個基本構成。
對于目錄文件而言,其屬性部分與普通文件類似,不再贅述;而其內容部分則保存了文件名與對應 inode 編號的映射關系,用于標識該目錄下包含的文件或子目錄。
直接看代碼
readdir.c
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<dirent.h>
#include<sys/types.h>
#include<unistd.h>
int main(int argc,char *argv[])
{if(argc != 2){fprintf(stderr,"Usage:%s <directory>\n",argv[0]);exit(EXIT_FAILURE);}DIR *dir = opendir(argv[1]);//DIR 是表示目錄流的結構體,用于讀取目錄內容if(!dir){perror("opendir");exit(EXIT_FAILURE);}struct dirent *entry;//struct dirent 表示目錄中的單個文件項信息while((entry = readdir(dir))!=NULL){if(strcmp(entry->d_name,".")==0 || strcmp(entry->d_name,"..")==0)//d_name 是目錄項中文件或子目錄的名稱{continue;}printf("Filename:%s,Inode:%lu\n",entry->d_name,(unsigned long)entry->d_ino);//d_ino 是文件或目錄對應的 inode 編號,用于唯一標識文件}closedir(dir);return 0;
}
演示結果
[gch@hcss-ecs-f59a day7]$ gcc -o readdir readdir.c
[gch@hcss-ecs-f59a day7]$ ./readdir /
Filename:proc,Inode:131073
Filename:usr,Inode:393223
Filename:boot,Inode:131077
Filename:mnt,Inode:131084
Filename:sys,Inode:131074
Filename:opt,Inode:131085
Filename:root,Inode:524290
Filename:var,Inode:524291
Filename:tmp,Inode:131075
Filename:media,Inode:131083
Filename:working,Inode:1835009
Filename:sbin,Inode:16
Filename:home,Inode:131082
Filename:lib64,Inode:15
Filename:CloudrResetPwdAgent,Inode:264516
Filename:lib,Inode:13
Filename:dev,Inode:393217
Filename:lost+found,Inode:11
Filename:etc,Inode:393218
Filename:.autorelabel,Inode:14711
Filename:run,Inode:524289
Filename:srv,Inode:131086
Filename:bin,Inode:17
[gch@hcss-ecs-f59a day7]$ ls -li /total 6817 lrwxrwxrwx. 1 root root 7 Jul 26 2024 bin -> usr/bin131077 dr-xr-xr-x. 5 root root 4096 Jul 15 12:58 boot264516 drwxr-xr-x 7 root root 4096 Jul 26 2024 CloudrResetPwdAgent1026 drwxr-xr-x 19 root root 3020 Jul 15 13:03 dev393218 drwxr-xr-x. 78 root root 4096 Jul 25 08:55 etc131082 drwxr-xr-x. 3 root root 4096 Jul 15 13:05 home13 lrwxrwxrwx. 1 root root 7 Jul 26 2024 lib -> usr/lib15 lrwxrwxrwx. 1 root root 9 Jul 26 2024 lib64 -> usr/lib6411 drwx------. 2 root root 16384 Jul 26 2024 lost+found131083 drwxr-xr-x. 2 root root 4096 Apr 11 2018 media131084 drwxr-xr-x. 2 root root 4096 Apr 11 2018 mnt131085 drwxr-xr-x. 2 root root 4096 Apr 11 2018 opt1 dr-xr-xr-x 123 root root 0 Jul 15 13:03 proc524290 dr-xr-x---. 5 root root 4096 Jul 15 19:33 root1259 drwxr-xr-x 24 root root 640 Jul 25 09:12 run16 lrwxrwxrwx. 1 root root 8 Jul 26 2024 sbin -> usr/sbin131086 drwxr-xr-x. 2 root root 4096 Apr 11 2018 srv1 dr-xr-xr-x 13 root root 0 Jul 15 13:05 sys131075 drwxrwxrwt. 13 root root 4096 Aug 8 15:53 tmp393223 drwxr-xr-x. 13 root root 4096 Jul 26 2024 usr524291 drwxr-xr-x. 19 root root 4096 Jul 26 2024 var
1835009 drwxrwxrwx 3 root root 4096 Jul 15 14:59 working
所以在文件系統里,訪問一個文件需要經過以下步驟:
打開當前目錄
因為文件名只是存在目錄文件里的一個名字,目錄本身也是一種文件,保存著“文件名和對應inode號”的映射關系。根據文件名查找 inode 號
通過讀取當前目錄文件的內容,找到對應文件名所關聯的inode(文件索引節點)編號。通過 inode 訪問文件內容
inode 記錄了文件的元信息和數據存儲位置,系統根據inode可以定位到文件實際內容,從而實現文件訪問。
重點是:
-
文件系統訪問文件不是直接通過文件名,而是先打開包含該文件的目錄,讀取目錄內容找到文件對應的 inode。
-
因此,必須知道“當前工作目錄”(即當前所在的目錄),才能打開它,查找目標文件的 inode,才能訪問文件。
1-6 路徑解析
-
訪問文件時,必須先打開當前工作目錄文件,查看其內容,因為目錄文件保存著
文件名與 inode號的映射關系。當前工作目錄本身也是一個目錄文件,要訪問它,必須知道它的inode號。 -
因此,要訪問當前工作目錄,需要先打開它的上級目錄。上級目錄也是目錄文件,訪問它同樣需要知道其
inode,進而訪問其上級目錄。如此形成了一個遞歸過程,需要依次解析路徑中的所有目錄,直到根目錄/。 -
實際上,任何文件都有一個完整路徑,例如
/home/whb/code/test/test/test.c。訪問目標文件時,必須從根目錄開始,依次打開每一級目錄,根據目錄名找到對應目錄,逐級向下,直到定位到目標文件。這一過程稱為Linux 路徑解析。 -
由此可見,訪問文件必須提供目錄和文件名,即完整路徑。根目錄的文件名和
inode號是固定的,系統啟動后即已知,無需查找。 -
路徑信息由進程提供,進程維護當前工作目錄(CWD),用戶在訪問文件時通過指令或工具提供路徑。
-
Linux 設計根目錄以及眾多默認目錄,是為了構建完整的路徑體系。用戶也可以自行新建目錄,任何新建文件都依附于某個目錄,這樣天然形成了路徑結構。系統和用戶共同構建了 Linux 的路徑層級結構。
1-7 路徑緩存
-
Linux磁盤中不存在
真正的目錄,磁盤上只有文件,文件由文件屬性和文件內容組成。 -
訪問任何文件都需要從根目錄
/開始進行路徑解析。原則上路徑解析是逐層進行的,但為了提高效率,Linux 會緩存歷史路徑結構。 -
目錄的概念由操作系統產生,當打開的文件是目錄時,操作系統會在內存中維護路徑信息。
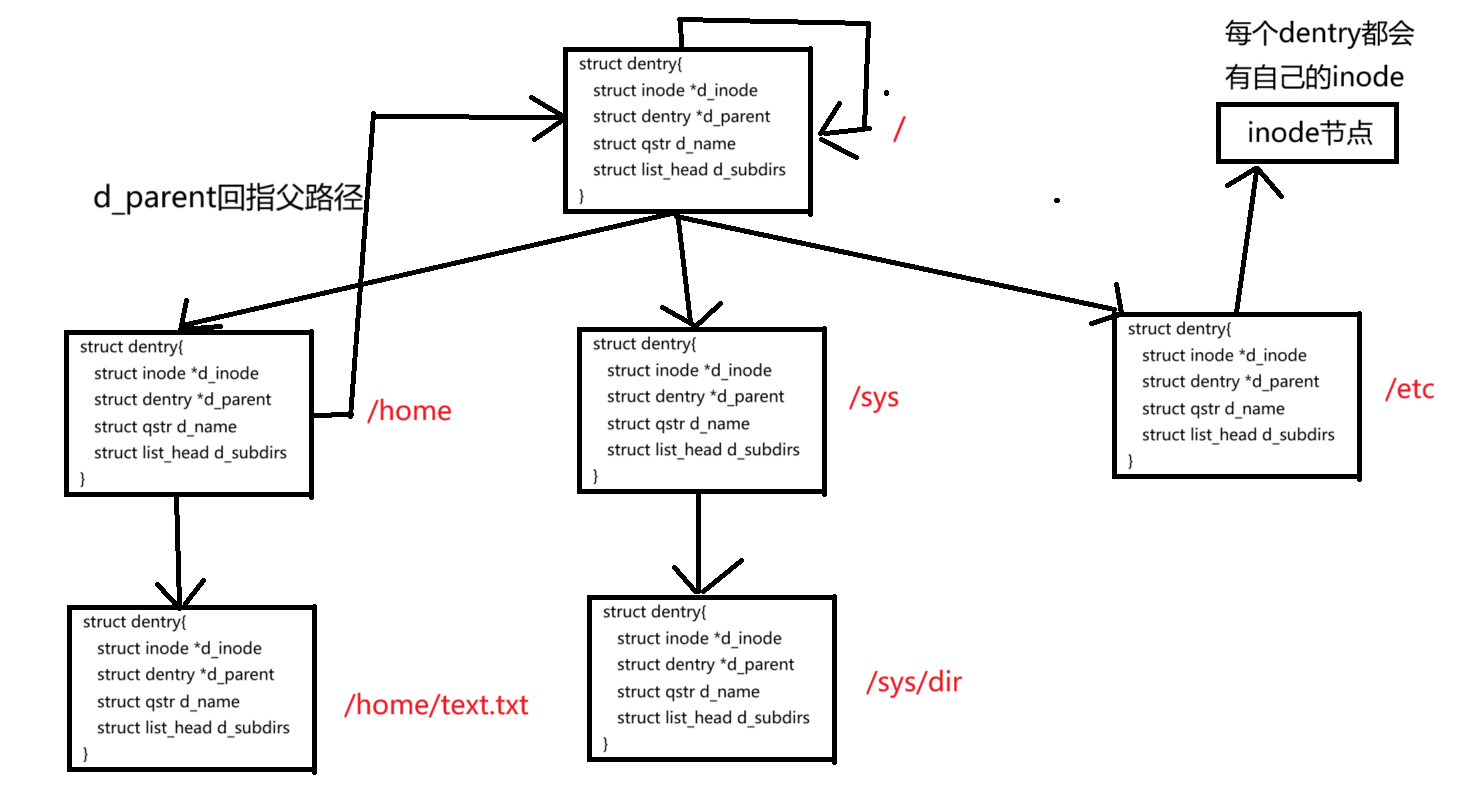
在 Linux 內核中,用于維護樹狀路徑結構的核心數據結構是 struct dentry
struct dentry {struct inode *d_inode; // 指向該目錄項對應的 inode,表示文件或目錄的元信息struct dentry *d_parent; // 指向父目錄的 dentry,形成目錄樹的層級結構struct qstr d_name; // 目錄項的名稱,包含名字字符串及其長度、哈希值struct list_head d_lru; // 用于管理 dentry 緩存的 LRU 鏈表節點struct list_head d_subdirs; // 鏈表頭,指向當前 dentry 的所有子目錄項,維護目錄的子節點鏈表// ... 結構體中還有其他成員
};-
每個文件其實都會對應一個
dentry 結構體,包括普通文件也是這樣。這樣一來,所有打開過的文件在內存里就能組成一棵完整的樹。 -
這棵樹的節點同時會被放進一個叫做
LRU(最近最少使用)的結構里,方便系統淘汰不常用的節點,節省內存。 -
另外,這些節點還會被放進
哈希表里,方便快速查找。 -
更重要的是,這整棵樹其實就是 Linux 的路徑緩存。每次訪問文件時,系統會先在這棵樹里根據路徑查找對應的節點,如果找到了,就直接返回文件的
inode和內容;找不到的話,就從磁盤加載對應路徑,創建新的dentry 結構,緩存起來。
1-8 掛載分區
-
我們已經可以根據
inode號在指定的分區中定位文件,也能夠通過目錄文件的內容找到對應的inode,因此在同一個分區內,文件訪問是沒有限制的,可以自由操作。 -
但是,inode 編號在不同分區之間并不通用,不能跨分區使用。而 Linux 系統通常會包含多個分區,這就帶來了一個問題:在訪問文件時,系統必須明確知道當前所處的是哪個分區。
-
為了解決這個問題,Linux 文件系統會為每個掛載的分區(也就是文件系統)維護一個掛載點,并記錄每個分區的
根 inode和掛載路徑。通過這些掛載信息,系統就可以確定路徑中每一級目錄屬于哪個分區,從而正確地解析每個目錄項和inode的對應關系,實現跨分區的路徑解析。
struct mount {struct mount *mnt_parent; // 指向父掛載點(如 /mnt/usb 的父是 /mnt)struct dentry *mnt_mountpoint; // 指向掛載點目錄的 dentry,比如 /mntstruct vfsmount *mnt; // 指向掛載的文件系統信息(早期叫 vfsmount)struct list_head mnt_children; // 所有掛載在此掛載點下的子掛載點struct list_head mnt_instance; // 用于將 mount 實例插入全局鏈表
};
二,軟硬鏈接
2-1 硬鏈接
我們可以看到,在 Linux 中真正用來定位磁盤上文件的,其實不是文件名,而是 inode。文件名只是一個“門牌號”,而 inode 才是找到文件內容的“鑰匙”。
實際上,Linux 允許多個不同的文件名指向同一個 inode,這意味著它們共享同一份文件內容。這種機制就叫做硬鏈接。換句話說,多個文件名可以像“別名”一樣,共同指向同一個文件實體。
[gch@hcss-ecs-f59a day7]$ touch adc
[gch@hcss-ecs-f59a day7]$ ln adc def
[gch@hcss-ecs-f59a day7]$ ls -li
total 16
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
比如 adc 和 def 兩個文件,它們其實指向的是同一個 inode,鏈接狀態完全一樣。這種情況被稱為硬鏈接,它們本質上是同一個文件,只是有兩個不同的文件名而已。
內核會記錄這個 inode 被多少個文件名引用,這個數字叫做硬鏈接數。比如 inode 編號為 263466 的文件,它的硬鏈接數是 2,就說明有兩個名字(比如 abc 和 def)指向它。
當我們刪除一個文件時,其實做了兩件事:
1.== 從目錄中把這個文件名的記錄刪掉==;
2. 把對應 inode 的硬鏈接數減 1。
如果減到0,說明沒有任何文件名再指向這個 inode,系統就會把它對應的磁盤空間釋放掉,文件內容才會真正消失。
2-2 軟鏈接
在 Linux 中,硬鏈接是通過共享 inode 來引用同一個文件;也就是說,多個文件名指向同一個 inode,文件內容完全相同,彼此是“平級”的,沒有主從關系。
而軟鏈接(符號鏈接)是通過路徑名來引用另一個文件,本質上是一個獨立的文件,它里面保存的是目標文件的路徑。軟鏈接的 inode 和原文件不同,可以看作是一個快捷方式。
[gch@hcss-ecs-f59a day7]$ ll
total 0
-rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
-rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
[gch@hcss-ecs-f59a day7]$ ln -s adc abc
[gch@hcss-ecs-f59a day7]$ ls -li
total 0
1835333 lrwxrwxrwx 1 gch gch 3 Aug 8 16:58 abc -> adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 adc
1835335 -rw-rw-r-- 2 gch gch 0 Aug 8 16:48 def
2-3 軟硬鏈接對比
硬連接(Hard Link)——同一個人多個名字
特點:
-
多個文件名 → 指向 同一個 inode(身份證)
-
內容完全一致,本質上是“同一個文件”
-
刪除任意一個文件名不會影響文件本身,除非所有名字都刪掉
-
只能用于同一個分區
比喻:
就像一個人叫“張三”,又被朋友叫“老三”。
無論你叫哪個名字,他還是同一個人(inode)。
軟連接(Symbolic Link)——指向地址的快捷方式
特點:
-
文件名中保存的是“
另一個文件的路徑” -
是一個獨立的文件,擁有自己的 inode
-
被鏈接的目標文件如果被刪除或移動,鏈接就失效(變成斷鏈)
-
可以跨分區
比喻:
就像你電腦桌面上的快捷方式(.lnk 文件)。
它指向某個程序的位置,但自己不是真正的程序。
如果程序被刪除,快捷方式就打不開了。



)


——Time、Vector3、位置位移、角度、旋轉、縮放、看向)

,KL散度)










Gemini Agent 使用指南)