在大數據和分布式系統飛速發展的今天,消息隊列作為高效的通信工具,在系統解耦、異步通信、流量削峰等方面作用顯著。
而 Kafka 這款高性能、高吞吐量的分布式消息隊列,在日志收集、數據傳輸、實時計算等場景中應用廣泛。
接下來,我就帶大家深入了解 Kafka 的概念、架構設計和底層原理。
一、Kafka 的核心概念
Kafka 是 Apache 軟件基金會開發的開源流處理平臺,本質上是個分布式、分區化、多副本的日志提交服務。簡單說,它就像個大消息容器,能接收多個生產者的消息,再分發給多個消費者。
下面這幾個核心概念得搞清楚:
-
生產者(Producer):負責把消息發送到 Kafka 集群,還能按策略將消息發到指定分區,實現負載均衡或按業務分類存儲。
-
消費者(Consumer):從 Kafka 集群讀取消息,可組成消費者組一起消費某個主題的消息,提高處理效率。
-
主題(Topic):消息的分類標識,生產者往特定主題發消息,消費者從特定主題讀消息,相當于消息的集合。
-
分區(Partition):為提升吞吐量和并行處理能力,一個主題可分成多個分區。每個分區是有序且不可變的消息序列,消息按發送順序存儲。
-
副本(Replica):為保證數據可靠,每個分區可有多個副本。一個是領導者(Leader),處理生產者和消費者的請求;其他是追隨者(Follower),通過復制領導者數據保持同步,領導者故障后,追隨者會被選為新領導者。
-
Broker:Kafka 集群的服務器節點,每個 Broker 存儲部分主題的分區和副本,它們相互通信協調,維持集群穩定運行。
二、Kafka 的架構設計
Kafka 采用分布式架構,由生產者、消費者、主題、分區、副本和 Broker 等組件構成,各組件協同工作,實現高效消息傳遞。
(一)整體架構
Kafka 集群由多個 Broker 組成,每個都有唯一標識。主題分成多個分區,分布在不同 Broker 上,每個分區有多個副本,一個是領導者,其余是追隨者。生產者把消息發到指定主題的分區領導者,追隨者復制領導者數據保持一致。消費者從分區領導者讀消息,還能組成消費者組,組內消費者分別消費不同分區消息,實現并行處理。ZooKeeper 和各個 Broker 通信,管理集群元數據。
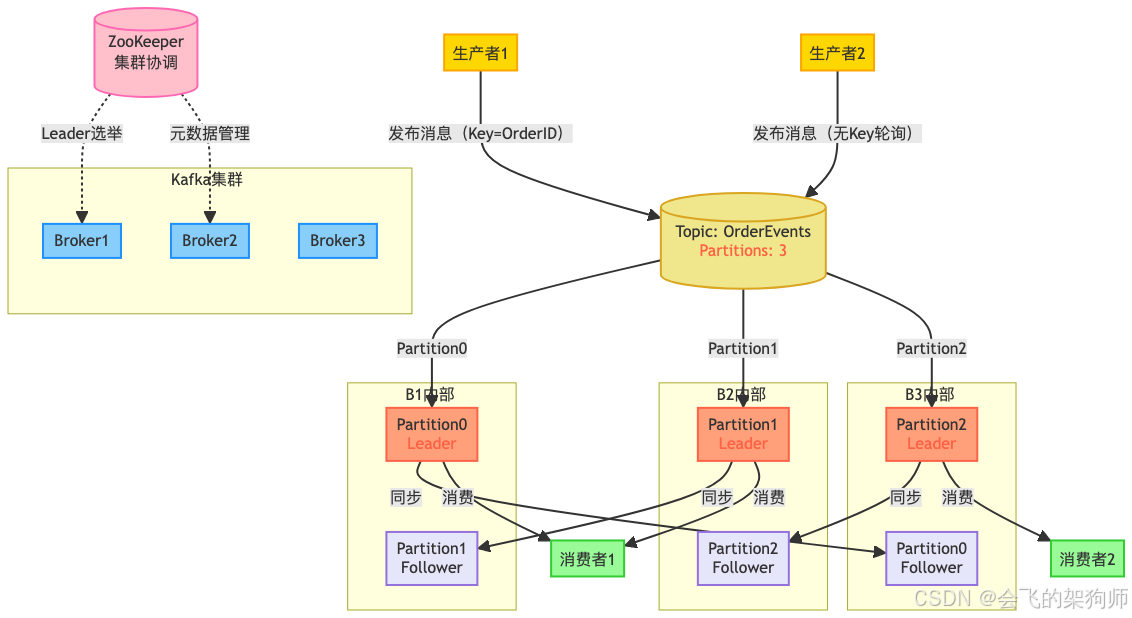
(二)ZooKeeper 在傳統架構中的作用
早期 Kafka 架構里,ZooKeeper 作用關鍵:
-
元數據存儲:存著集群的各類元數據,像 Topic 的分區數量、副本分布,Broker 的 IP、端口等。不過從 Kafka 0.9.0.0 版本起,消費者組的偏移量就存在 Kafka 內部的__consumer_offsets 主題,不再存在 ZooKeeper 了。這些元數據很重要,生產者、消費者和 Broker 都要經常讀,來決定消息發往哪個分區、從哪開始消費等。
-
控制器選舉:集群的 Controller 負責分區創建、刪除、副本分配遷移等操作。它的選舉靠 ZooKeeper 的臨時節點和 Watcher 機制。所有 Broker 都嘗試在 ZooKeeper 創建特定臨時節點,第一個成功的就是 Controller。其他 Broker 監聽這個節點,一旦當前 Controller 所在 Broker 故障,節點消失,其他 Broker 就重新競爭,選出新 Controller。
-
服務發現與集群拓撲管理:新加入的 Broker 能通過 ZooKeeper 快速找到其他節點并注冊。ZooKeeper 還監控 Broker 狀態,上線或下線時及時更新信息,通過 Watcher 機制通知其他組件,讓它們調整狀態。比如某個 Broker 下線,ZooKeeper 告訴 Controller,Controller 就重新分配該 Broker 上的分區副本。
(三)核心組件的作用
-
生產者:按分區策略把消息發到對應分區領導者,策略可以是哈希、輪詢或自定義的。還能配置消息確認機制,確保消息可靠發送。
-
消費者與消費者組:消費者訂閱主題獲取消息,組內每個消費者消費一個或多個分區,且每個分區只被組內一個消費者消費,避免重復消費。消費者通過提交偏移量記錄消費位置,重啟或重新加入組時,能從上次位置繼續消費。
-
主題與分區:主題是消息的邏輯分類,分區是物理存儲單元。有了分區,Kafka 能并行讀寫,提高吞吐量。每個分區的消息都有唯一偏移量,標識其位置。
-
副本機制:這是保證數據可靠的關鍵。分區副本分布在不同 Broker,領導者故障后,從追隨者中選新領導者。追隨者定期復制領導者消息,保持數據一致。
-
Broker:負責存儲分區和副本,處理生產者和消費者的請求。傳統模式下,Broker 之間靠 ZooKeeper 協調,ZooKeeper 管理著主題分區、副本分布等元數據。
(四)Kafka 對 ZooKeeper 的依賴移除與 KRaft 模式
隨著 Kafka 的廣泛應用,ZooKeeper 的問題逐漸顯現。運維 ZooKeeper 集群復雜,要額外投入資源,而且它和 Kafka 運維方式不同,對運維人員要求高。大規模集群中,ZooKeeper 處理大量元數據操作可能出現性能瓶頸,影響整個集群。
為解決這些問題,從 Kafka 2.8.0 版本開始,引入了 KRaft(Kafka Raft)模式,逐步移除對 ZooKeeper 的依賴,實現自管理元數據共識。KRaft 用新的仲裁控制器服務取代依賴 ZooKeeper 的控制器,采用基于事件的 Raft 共識協議變體達成元數據一致。
-
架構變化:KRaft 模式下,集群不依賴外部 ZooKeeper,引入專門的 Controller 節點(通過
process.roles配置角色)。這些節點靠 Raft 協議組成仲裁集合,管理元數據。元數據存在 Kafka 內部的__cluster_metadata主題,通過 Raft 協議在 Controller 節點間復制,保證一致性和高可用性。 -
Controller 選舉機制:傳統模式靠 ZooKeeper 的臨時節點和競爭創建機制選舉 Controller。KRaft 模式下,配置為
controller角色的節點參與 Raft 選舉。候選節點等隨機時間后發起選舉,獲超過半數投票的成為主 Controller,處理元數據寫入和同步,其他節點作為追隨者同步日志。這種方式更直接高效,減少了外部依賴帶來的復雜和故障點。 -
對集群的影響:用了 KRaft 模式,不用單獨部署管理 ZooKeeper 集群,簡化運維,降低成本。元數據管理集成在 Kafka 內部,避免了和 ZooKeeper 頻繁交互的性能瓶頸,處理大規模元數據操作時性能提升,分區創建、刪除等操作響應更快,集群擴展性也更好。到 Kafka 4.0 版本,KRaft 模式成為默認設置,標志著 Kafka 在擺脫 ZooKeeper 依賴上邁出重要一步。
三、Kafka 的底層原理
(一)消息存儲原理
Kafka 的消息以日志文件存在 Broker 磁盤上。每個分區對應一個目錄,里面有多個日志段(Log Segment)文件,由數據文件(.log)和索引文件(.index)組成,分別用于存儲消息和快速定位消息。
生產者發消息到分區,會追加到當前活躍的日志段文件末尾。當文件達到一定大小,就創建新的日志段文件。這種分段存儲方便消息查找和過期消息刪除。
(二)消息傳遞機制
Kafka 用推拉結合的方式傳遞消息。生產者主動把消息推到分區領導者,消費者主動從分區領導者拉取消息。這樣能根據消費者處理能力調整拉取速度,避免消息積壓。
傳遞過程中,還用了批量發送和壓縮技術提高效率。生產者把多個消息打包發送,減少網絡傳輸次數;壓縮消息能減小大小,降低帶寬消耗。
(三)副本同步機制
Kafka 的副本同步用 ISR(In-Sync Replicas)機制,ISR 是和領導者保持同步的追隨者集合。判斷追隨者是否在 ISR 中,主要看是否在規定時間(replica.lag.time.max.ms)內和領導者通信,以及消息偏移量差距是否在規定范圍(新版本更多看時間)。不符合就會被移出 ISR,只有 ISR 中的副本能被選為新領導者,保證數據最新。
生產者發消息到領導者后,領導者寫入本地日志,等待 ISR 中的追隨者復制成功。達到一定數量(通過 acks 參數配置,比如 acks=all 要求所有 ISR 中的追隨者都復制成功)后,領導者才向生產者確認消息發送成功。這種機制在保證可靠性的同時,也提高了效率。
(四)消費者組重平衡機制
當消費者組的消費者數量變化,或者主題分區數量變化時,Kafka 會觸發重平衡(Rebalance),重新分配消費者和分區的對應關系,確保每個分區都有消費者消費。
重平衡時,消費者組會暫停消費,直到完成。為減少影響,Kafka 引入消費者組協調器(Coordinator)管理這個過程,還優化算法縮短時間。協調器收集組內消費者信息,按范圍分配、輪詢分配等策略把分區分給消費者。
總的來說,Kafka 憑借合理的架構設計和底層原理,實現了高性能、高吞吐量、高可靠性的消息傳遞。深入理解這些,對用好和優化 Kafka 很有幫助。





:windows安裝使用node.js 安裝express,suquelize,mysql,nodemon)




 的效果)


)



 安裝與使用介紹)

