文章目錄
- 一、認識PyTorch
- 1.1 PyTorch是什么
- 1.2 安裝PyTorch
- 二、認識Tensor
- 2.1 創建Tensor
- 2.1.1 基本方式
- 2.2.2 創建線性和隨機張量
- 2.2 Tensor屬性
- 2.2.1 切換設備
- 2.2.2 類型轉換
- 2.3 Tensor與Numpy的數據轉換
- 2.3.1 張量轉ndarray
- 2.3.2 Numpy轉張量
- 2.4 Tensor常見操作
- 2.4.1 取值
- 2.4.2 基礎運算
- 2.4.3 點積與叉積
- 2.4.4 形狀操作
- 2.4.5 升維和降維
- 總結
一、認識PyTorch
1.1 PyTorch是什么
PyTorch是一個基于Python的深度學習框架,它提供了一種靈活、高效、易于學習的方式來實現深度學習模型。PyTorch最初由Facebook開發,被廣泛應用于計算機視覺、自然語言處理、語音識別等領域。
? PyTorch使用張量(tensor)來表示數據,可以輕松地處理大規模數據集,且可以在GPU上加速。
? PyTorch提供了許多高級功能,如**自動微分(automatic differentiation)、自動求導(automatic gradients)**等,這些功能可以幫助我們更好地理解模型的訓練過程,并提高模型訓練效率。
除了PyTorch,還有很多其它常見的深度學習框架:
- TensorFlow: Google開發,廣泛應用于學術界和工業界。TensorFlow提供了靈活的構建、訓練和部署功能,并支持分布式計算。
- Keras: Keras是一個高級神經網絡API,已整合到TensorFlow中。
- PaddlePaddle: PaddlePaddle(飛槳)是百度推出的開源深度學習平臺,旨在為開發者提供一個易用、高效的深度學習開發框架。
- MXNet:由亞馬遜開發,具有高效的分布式訓練支持和靈活的混合編程模型。
- Caffe:具有速度快、易用性高的特點,主要用于圖像分類和卷積神經網絡的相關任務。
- CNTK :由微軟開發的深度學習框架,提供了高效的訓練和推理性能。CNTK支持多種語言的接口,包括Python、C++和C#等。
- Chainer:由Preferred Networks開發的開源深度學習框架,采用動態計算圖的方式。
PyTorch中有3種數據類型:浮點數、整數、布爾。其中,浮點數和整數又分為8位、16位、32位、64位,加起來共9種。
之所以分為8位、16位、32位、64位,是因為在不同場景中,對數據的精度和速度要求不同。通常,移動或嵌入式設備追求速度,對精度要求相對低一些。精度越高,往往效果也越好,自然硬件開銷就比較高。
1.2 安裝PyTorch
首先需要使用Anaconda創建一個虛擬環境,建議所使用的python版本不要低于3.8。
conda create -n 你的環境名 python=3.9
如果你是使用的電腦沒有獨立顯卡,或者使用的不是NVIDA的顯卡的話,那么只需要安裝CPU版本的PyTorch即可。在官方文檔里面找到適合你設備的PyTorch的CPU版本及對應的安裝指令執行即可。
具體安裝步驟可以參考這篇文檔:PyTorch安裝教程
二、認識Tensor
Tensor,也叫張量,是一個多維數組,通俗來說可以看作是擴展了標量、向量、矩陣的更高維度的數組。張量的維度決定了它的形狀(Shape),PyTorch會將數據封裝成張量(Tensor)進行計算,所謂張量就是元素為相同類型的多維矩陣。張量可以在 GPU 上加速運行。
張量有device(所屬設備)、dtype(數據類型)、shape(形狀)等常見屬性,知道這些屬性對我們認識Tensor很有幫助。
2.1 創建Tensor
2.1.1 基本方式
張量可以通過標量、numpy數組以及list進行創建。
- torch.tensor()
注意這里的tensor是小寫,該API是根據指定的數據創建張量。
import torch
import numpy as np# 通過標量創建
t = torch.tensor(1)
print(t)# 通過ndarray創建
t = torch.tensor(np.random.randn(3, 5))
print(t)# 使用Tensor創建
t = torch.Tensor([1,2,3])
print(t)
如果出現如下錯誤:
UserWarning: Failed to initialize NumPy: _ARRAY_API not found
一般是因為numpy和pytorch版本不兼容,可以降低numpy版本。
- torch.Tensor
注意這里的Tensor是大寫,該API根據形狀創建張量,其也可用來創建指定數據的張量。
# 1. 根據形狀創建張量
tensor1 = torch.Tensor(2, 3)
print(tensor1)
# 2. 也可以是具體的值
tensor2 = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(tensor2, tensor2.shape, tensor2.dtype)tensor3 = torch.Tensor([10])
print(tensor3, tensor3.shape, tensor3.dtype)# 指定tensor數據類型
tensor1 = torch.Tensor([1,2,3]).short()
print(tensor1)tensor1 = torch.Tensor([1,2,3]).int()
print(tensor1)tensor1 = torch.Tensor([1,2,3]).float()
print(tensor1)tensor1 = torch.Tensor([1,2,3]).double()
print(tensor1)
torch.Tensor與torch.tensor區別
| 特性 | torch.Tensor() | torch.tensor() |
|---|---|---|
| 數據類型推斷 | 強制轉為 torch.float32 | 根據輸入數據自動推斷(如整數→int64) |
顯式指定 dtype | 不支持 | 支持(如 dtype=torch.float64) |
| 設備指定 | 不支持 | 支持(如 device='cuda') |
| 輸入為張量時的行為 | 創建新副本(不繼承原屬性) | 默認共享數據(除非 copy=True) |
| 推薦使用場景 | 需要快速創建浮點張量 | 需要精確控制數據類型或設備 |
還有諸如torch.IntTensor()、torch.FloatTensor()、 torch.DoubleTensor()、
torch.LongTensor()…等用于創建指定類型的張量。如果數據類型不匹配,那么在創建的過程中會進行類型轉換,要盡可能避免,防止數據丟失。
2.2.2 創建線性和隨機張量
- 線性張量
使用torch.arange 和 torch.linspace 創建線性張量:
# 不用科學計數法打印
torch.set_printoptions(sci_mode=False)# 1. 創建線性張量
r1 = torch.arange(0, 10, 2)
print(r1)
# 2. 在指定空間按照元素個數生成張量:等差
r2 = torch.linspace(3, 10, 10)
print(r2)r2 = torch.linspace(3, 10000000, 10)
print(r2)
- 隨機張量
在 PyTorch 中,使用torch.randn 創建隨機張量。種子影響所有與隨機性相關的操作,包括張量的隨機初始化、數據的隨機打亂、模型的參數初始化等。通過設置隨機數種子,可以做到模型訓練和實驗結果在不同的運行中進行復現。也即是說,不設置隨機種子時,每次打印的結果不一樣。
# 設置隨機數種子
torch.manual_seed(123)# 獲取隨機數種子
print(torch.initial_seed())# 生成隨機張量,均勻分布(范圍 [0, 1))
# 創建2個樣本,每個樣本3個特征
print(torch.rand(2, 3))# 4. 生成隨機張量:標準正態分布(均值 0,標準差 1)
print(torch.randn(2, 3))# 5. 原生服從正態分布:均值為2, 方差為3,形狀為1*4的正態分布
print(torch.normal(mean=2, std=3, size=(1, 4)))
2.2 Tensor屬性
2.2.1 切換設備
默認在cpu上運行,可以顯式的切換到GPU:
# 獲取屬性
data = torch.tensor([1, 2, 3])
print(data.dtype, data.device, data.shape)# 把數據切換到GPU進行運算
device = "cuda" if torch.cuda.is_available() else "cpu"
data = data.to(device)
print(data.device)
不同設備上的數據是不能相互運算的。
或者使用cuda進行切換:
data = data.cuda()
當然也可以直接創建在GPU上:
# 直接在GPU上創建張量
data = torch.tensor([1, 2, 3], device='cuda')
print(data.device)
2.2.2 類型轉換
訓練模型或推理時,類型轉換也是張量的基本操作,是需要掌握的。
data = torch.tensor([1, 2, 3])
print(data.dtype) # torch.int64# 1. 使用type進行類型轉換
data = data.type(torch.float32)
print(data.dtype) # float32
data = data.type(torch.float16)
print(data.dtype) # float16# 2. 使用類型方法
data = data.float()
print(data.dtype) # float32
# 16 位浮點數,torch.float16,即半精度
data = data.half()
print(data.dtype) # float16
data = data.double()
print(data.dtype) # float64
data = data.long()
print(data.dtype) # int64
data = data.int()
print(data.dtype) # int32# 使用dtype屬性
data = torch.tensor([1, 2, 3], dtype=torch.half)
print(data.dtype)
2.3 Tensor與Numpy的數據轉換
2.3.1 張量轉ndarray
用于需要計算的情景,轉換后即脫離了計算圖。此時分淺拷貝(內存共享)和深拷貝(內存不共享)。
- 淺拷貝
調用numpy()方法可以把Tensor轉換為Numpy,此時內存是共享的。
# 1. 張量轉numpy
data_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
data_numpy = data_tensor.numpy()
print(type(data_tensor), type(data_numpy))
# 2. 他們內存是共享的
data_numpy[0, 0] = 100
print(data_tensor, data_numpy)
- 深拷貝
使用copy()方法可以避免內存共享:
# 1. 張量轉numpy
data_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 2. 使用copy()避免內存共享
data_numpy = data_tensor.numpy().copy()
print(type(data_tensor), type(data_numpy))# 3. 此時他們內存是不共享的
data_numpy[0, 0] = 100
print(data_tensor, data_numpy)
2.3.2 Numpy轉張量
也同樣分為淺拷貝和深拷貝。
- 淺拷貝
from_numpy方法轉Tensor默認是內存共享的
# 1. numpy轉張量
data_numpy = np.array([[1, 2, 3], [4, 5, 6]])
data_tensor = torch.from_numpy(data_numpy)
print(type(data_tensor), type(data_numpy))# 2. 他們內存是共享的
data_tensor[0, 0] = 100
print(data_tensor, data_numpy)
- 深拷貝
使用傳統的torch.tensor()則內存是不共享的
# 1. numpy轉張量
data_numpy = np.array([[1, 2, 3], [4, 5, 6]])
data_tensor = torch.tensor(data_numpy)
print(type(data_tensor), type(data_numpy))# 2. 內存是不共享的
data_tensor[0, 0] = 100
print(data_tensor, data_numpy)
2.4 Tensor常見操作
2.4.1 取值
我們可以把單個元素tensor轉換為Python數值,這是非常常用的操作。
data = torch.tensor([[18]])
print(data.item())
注意:
- 和Tensor的維度沒有關系,都可以取出來!
- 如果有多個元素則報錯;
- 僅適用于CPU張量,如果張量在GPU上,需先移動到CPU
2.4.2 基礎運算
常見的加減乘除次方取反開方等各種操作,帶有_的方法為原地操作。
# 生成范圍 [0, 10) 的 2x3 隨機整數張量
data = torch.randint(0, 10, (2, 3))
print(data)
# 元素級別的加減乘除:不修改原始值
print(data.add(1))
print(data.sub(1))
print(data.mul(2))
print(data.div(3))
print(data.pow(2))# 元素級別的加減乘除:修改原始值
data = data.float()
data.add_(1)
data.sub_(1)
data.mul_(2)
data.div_(3.0)
data.pow_(2)
print(data)
2.4.3 點積與叉積
- 點積
也叫矩陣乘法,是線性代數中的一種基本運算,用于將兩個矩陣相乘,生成一個新的矩陣。
假設有兩個矩陣:
- 矩陣 A的形狀為 m×n(m行 n列)。
- 矩陣 B的形狀為 n×p(n行 p列)。
矩陣 A和 B的乘積 C=A×B是一個形狀為 m×p的矩陣,其中 C的每個元素 Cij,計算 A的第 i行與 B的第 j列的點積。計算公式為:
Cij=∑k=1nAik×BkjC_{ij}=∑_{k=1}^nA_{ik}×B_{kj} Cij?=k=1∑n?Aik?×Bkj?
矩陣乘法運算要求如果第一個矩陣的shape是 (N, M),那么第二個矩陣 shape必須是 (M, P),即第一個矩陣的列數必須與第二個矩陣的行數相同,最后兩個矩陣點積運算的shape為 (N, P)。
在 PyTorch 中,使用@或者matmul完成Tensor的乘法。
data1 = torch.tensor([[1, 2, 3], [4, 5, 6]
])
data2 = torch.tensor([[3, 2], [2, 3], [5, 3]
])
print(data1 @ data2)
print(data1.matmul(data2))
- 叉積
也叫阿達瑪積,是指兩個形狀相同的矩陣或張量對應位置的元素相乘。它與矩陣乘法不同,矩陣乘法是線性代數中的標準乘法,而阿達瑪積是逐元素操作。假設有兩個形狀相同的矩陣 A和 B,它們的阿達瑪積 C=A°B定義為:
Cij=Aij×BijC_{ij}=A_{ij}×B_{ij} Cij?=Aij?×Bij?
其中:
- Cij 是結果矩陣 C的第 i行第 j列的元素。
- Aij和 Bij分別是矩陣 A和 B的第 i行第 j 列的元素。
在 PyTorch 中,可以使用mul函數或者*來實現;
data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])
data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])
print(data1 * data2)
print(data1.mul(data2))
2.4.4 形狀操作
- reshape
可以用于將張量轉換為不同的形狀,但要確保轉換后的形狀與原始形狀具有相同的元素數量。
data = torch.randint(0, 10, (4, 3))
print(data)
# 1. 使用reshape改變形狀
data = data.reshape(2, 2, 3)
print(data)# 2. 使用-1表示自動計算
data = data.reshape(2, -1)
print(data)
- view
view進行形狀變換的特征:
- 張量在內存中是連續的;
- 返回的是原始張量視圖,不重新分配內存,效率更高;
- 如果張量在內存中不連續,view 將無法執行,并拋出錯誤。
張量的內存布局決定了其元素在內存中的存儲順序。對于多維張量,內存布局通常按照最后一個維度優先的順序存儲,即先存列,后存行。例如,對于一個二維張量
A,其形狀為 (m, n),其內存布局是先存儲第 0 行的所有列元素,然后是第 1 行的所有列元素,依此類推。 如果張量的內存布局與形狀完全匹配,并且沒有被某些操作(如轉置、索引等)打亂,那么這個張量就是連續的。
PyTorch 的大多數操作都是基于 C 順序的,我們在進行變形或轉置操作時,很容易造成內存的不連續性。
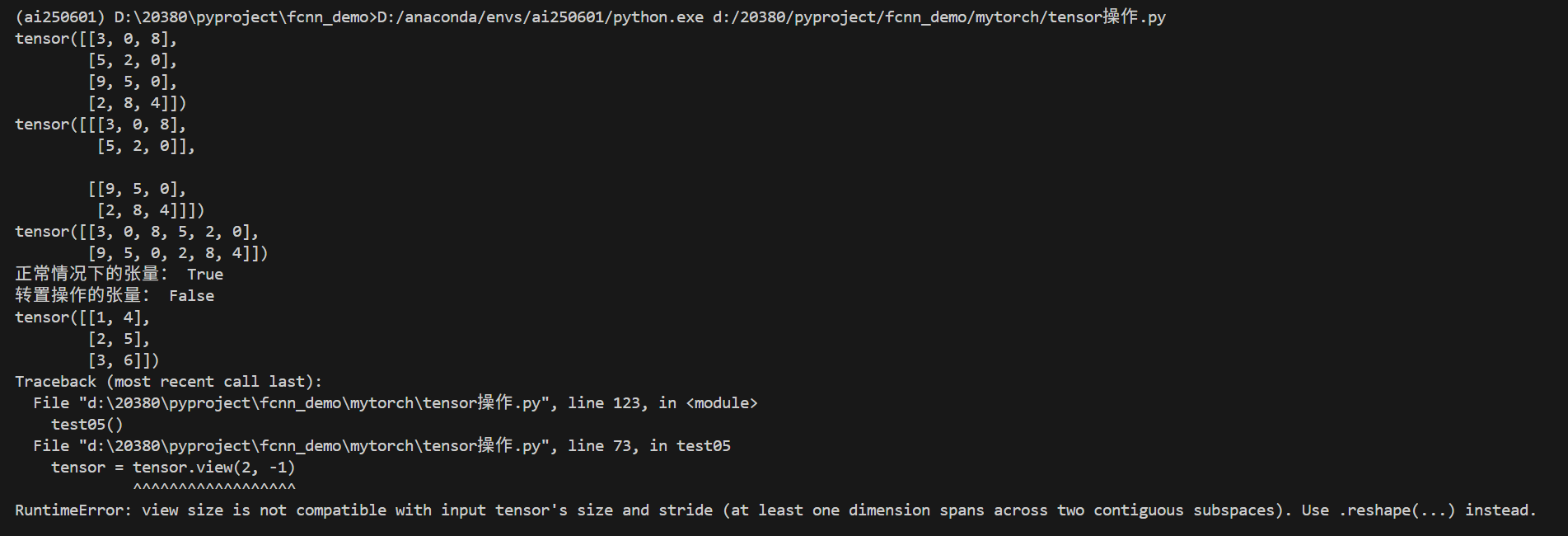
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
print("正常情況下的張量:", tensor.is_contiguous())# 對張量進行轉置操作
tensor = tensor.t()
print("轉置操作的張量:", tensor.is_contiguous())
print(tensor)
# 此時使用view進行變形操作,取值為-1表示自動推斷該維度
tensor = tensor.view(2, -1)
print(tensor)
運行結果如下:
- transpose
transpose 用于交換張量的兩個維度,注意,是2個維度,它返回的是新張量,原張量不變。
torch.transpose(input, dim0, dim1)
參數:
- input: 輸入的張量。
- dim0: 要交換的第一個維度。
- dim1: 要交換的第二個維度。
data = torch.randint(0, 10, (3, 4, 5))
print(data, data.shape)
# 使用transpose進行形狀變換
transpose_data = torch.transpose(data,0,1)
# transpose_data = data.transpose(0, 1)
print(transpose_data, transpose_data.shape)
轉置后的張量可能是非連續的(is_contiguous() 返回 False),如果需要連續內存(如某些操作要求),可調用 .contiguous():
y = x.transpose(0, 1).contiguous()
- permute
它通過重新排列張量的維度來返回一個新的張量,不改變張量的數據,只改變維度的順序。
torch.permute(input, dims)
參數
- input: 輸入的張量。
- dims: 一個整數元組,表示新的維度順序。
data = torch.randint(0, 10, (3, 4, 5))
print(data, data.shape)
# 使用permute進行多維度形狀變換
permute_data = data.permute(1, 2, 0)
print(permute_data, permute_data.shape)
和 transpose 一樣,permute 返回新張量,原張量不變。重排后的張量可能是非連續的(is_contiguous() 返回 False),必要時需調用 .contiguous()。
維度順序必須合法:dims 中的維度順序必須包含所有原始維度,且不能重復或遺漏。例如,對于一個形狀為 (2, 3, 4) 的張量,dims=(2, 0, 1) 是合法的,但 dims=(0, 1) 或 dims=(0, 1, 2, 3) 是非法的。
與 transpose() 的對比
| 特性 | permute() | transpose() |
|---|---|---|
| 功能 | 可以同時調整多個維度的順序 | 只能交換兩個維度的順序 |
| 靈活性 | 更靈活 | 較簡單 |
| 使用場景 | 適用于多維張量 | 適用于簡單的維度交換 |
2.4.5 升維和降維
- squeeze降維
用于移除所有大小為 1 的維度,或者移除指定維度的大小為 1 的維度。
torch.squeeze(input, dim=None)
參數
- input: 輸入的張量。
- dim (可選): 指定要移除的維度。如果指定了 dim,則只移除該維度(前提是該維度大小為 1);如果不指定,則移除所有大小為 1 的維度。
data = torch.randint(0, 10, (1, 4, 5, 1))
print(data, data.shape)# 進行降維操作
data1 = data.squeeze(0).squeeze(-1)
print(data.shape)# 移除所有大小為 1 的維度
data2 = torch.squeeze(data)# 嘗試移除第 1 維(大小為 3,不為 1,不會報錯,張量保持不變。)
data3 = torch.squeeze(data, dim=1)
print("嘗試移除第 1 維后的形狀:", data3.shape)
- unsqueeze升維
torch.unsqueeze(input, dim)
參數
- input: 輸入的張量。
- dim: 指定要增加維度的位置(從 0 開始索引)。
data = torch.randint(0, 10, (32, 32, 3))
print(data.shape)
# 升維操作
data = data.unsqueeze(0)
print(data.shape)
Tensor也有廣播機制,且與numpy數組基本一致,這里不再贅述。
總結
本文簡要介紹了PyTorch,以及Tensor的一部分常用基本操作。
:RecyclerView 多類型布局與數據刷新實戰)
)






)


ZipList的節點介紹)







