地址:Mobile Edge Intelligence for Large Language Models: A Contemporary Survey
 摘要
摘要
設備端大型語言模型(LLMs)指在邊緣設備上運行 LLMs,與云端模式相比,其成本效益更高、延遲更低且更能保護隱私,因此引發了廣泛關注。然而,設備端 LLMs 的性能本質上受限于邊緣設備的資源約束。移動邊緣智能(MEI)介于云端 AI 和設備端 AI 之間,通過在移動網絡邊緣提供 AI 能力,允許終端用戶將繁重的 AI 計算卸載到附近的邊緣服務器,為這一問題提供了可行解決方案。本文對利用 MEI 支持 LLMs 的研究進行了最新綜述:首先,通過若干典型應用場景說明在網絡邊緣部署 LLMs 的迫切需求;其次,介紹 LLMs 和 MEI 的基礎知識,以及資源高效的 LLM 技術;隨后,概述面向 LLMs 的 MEI 架構(MEI4LLM),闡述其核心組件及對 LLMs 部署的支持方式;接著,深入探討 MEI4LLM 的各個方面,包括邊緣 LLM 緩存與分發、邊緣 LLM 訓練和邊緣 LLM 推理;最后,指出未來的研究方向。希望本文能啟發研究者利用移動邊緣計算推動 LLMs 部署,從而在各類隱私敏感和延遲敏感型應用中釋放 LLMs 的潛力。
概述
-
背景與動機
- 云端 LLMs 存在隱私泄露、帶寬成本高、延遲長等問題;設備端 LLMs 受限于資源,難以支持大規模模型和復雜任務。
- MEI 作為折中方案,通過邊緣服務器提供 AI 能力,平衡計算資源、延遲和隱私需求,成為 6G 時代 LLMs 部署的關鍵方向。
-
核心應用場景
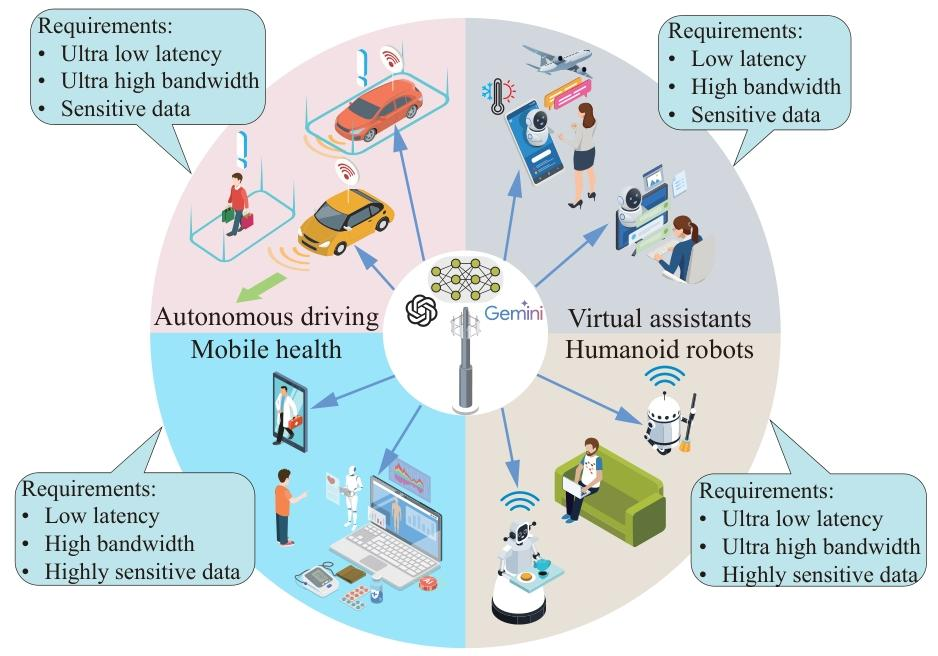
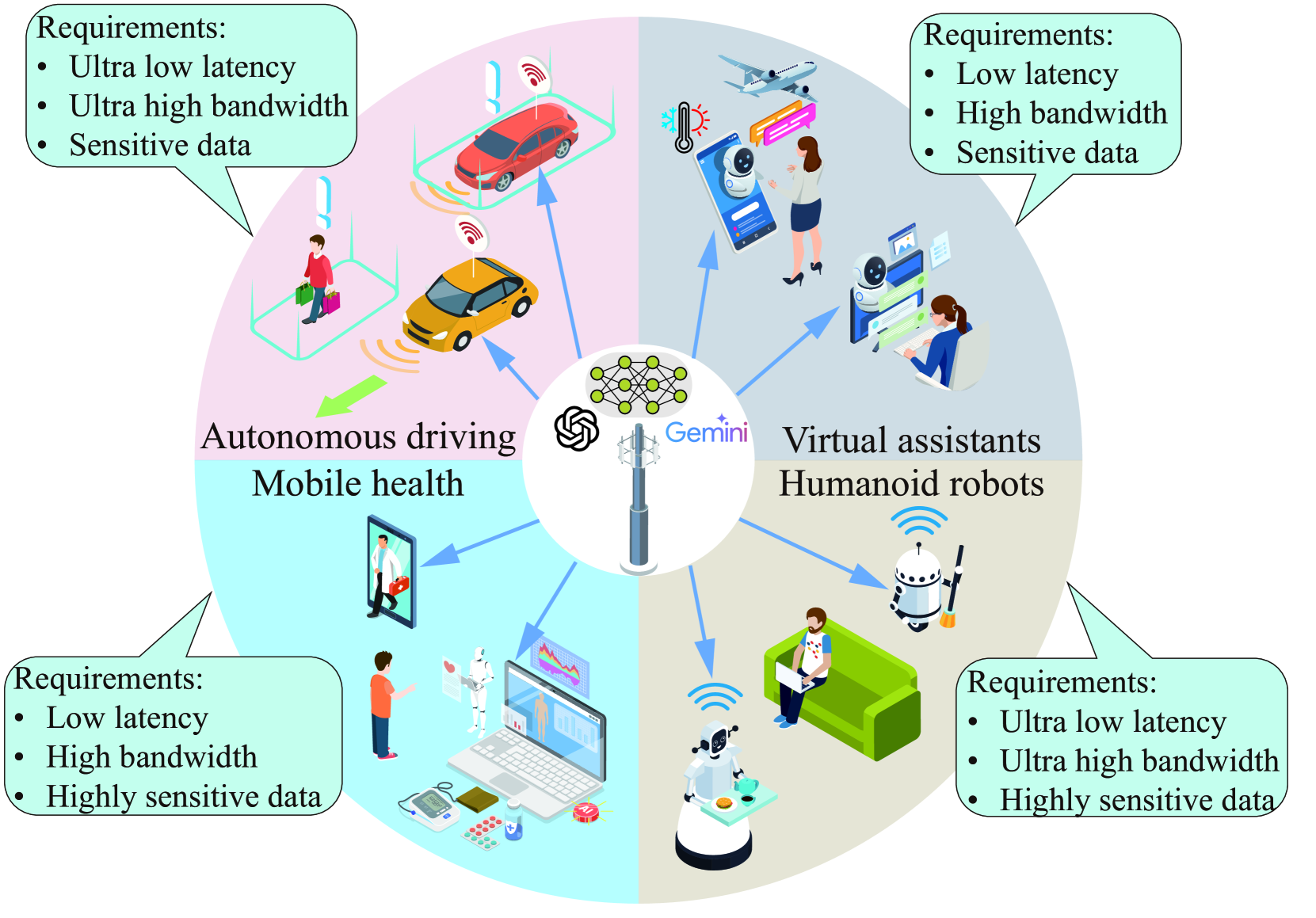
聚焦四個對邊緣部署 LLMs 需求迫切的場景:- 移動醫療:需低延遲處理敏感健康數據,符合隱私法規(如 GDPR);
- 類人機器人:依賴實時響應(10-100ms 延遲)和本地化數據處理;
- 虛擬助手:要求低延遲交互(<200ms)和用戶數據隱私保護;
- 自動駕駛:需超低延遲(10ms 級)和處理海量多模態傳感器數據。
-
基礎技術
- LLMs 基礎:基于 Transformer 架構,分為編碼器僅用、解碼器僅用、編碼器 - 解碼器三類,支持文本、圖像等多模態輸入,存在自回歸生成等特性。
- MEI 基礎:融合移動邊緣計算與 AI,通過邊緣服務器實現分布式訓練和推理,支持聯邦學習、拆分學習等框架。
- 資源高效技術:包括模型壓縮(量化、剪枝、知識蒸餾)、快速解碼(投機解碼、早期退出)、參數高效微調(LoRA、前綴調優)等。
-
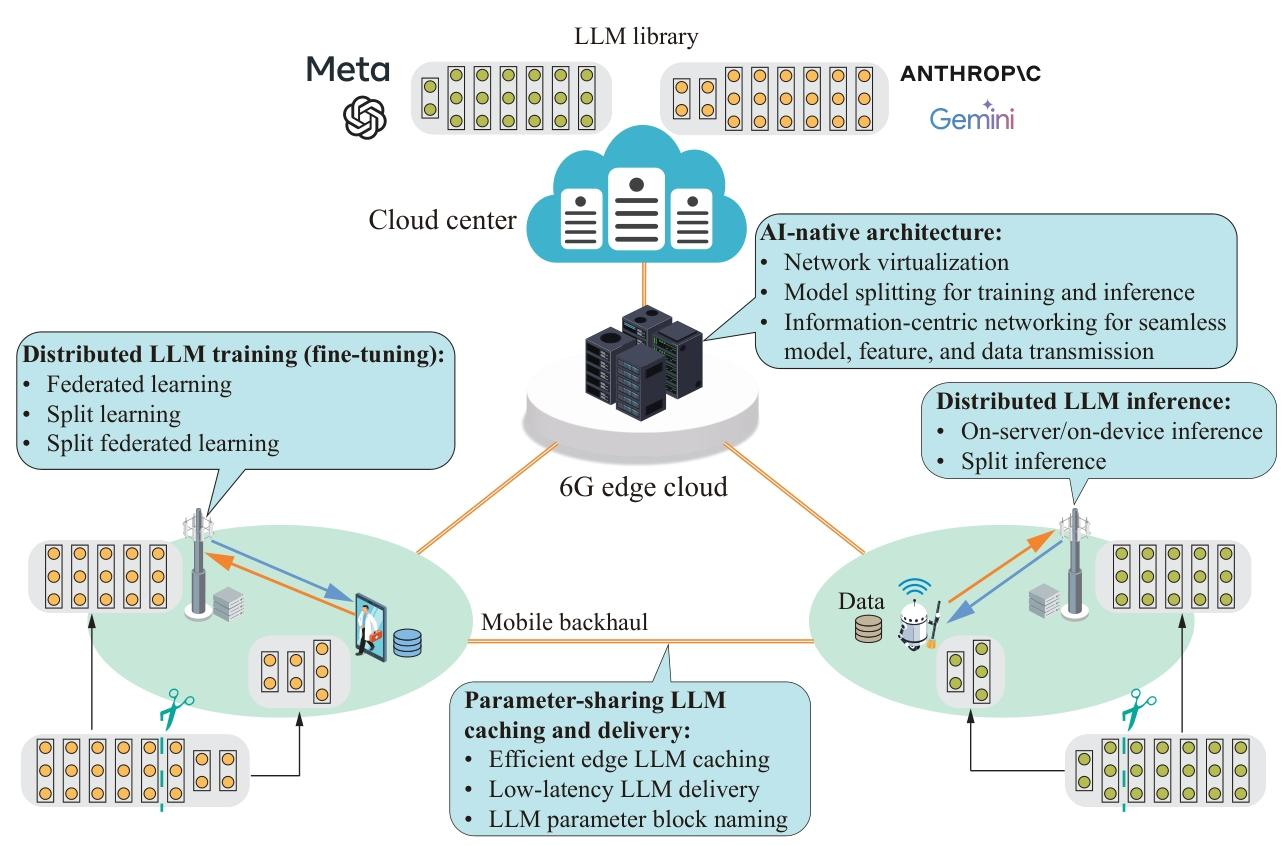
MEI4LLM 架構
- 核心組件:AI 原生網絡架構、參數共享的 LLM 緩存與分發、分布式 LLM 訓練、分布式 LLM 推理。
- 關鍵技術:
- 緩存與分發:利用參數共享特性優化邊緣緩存(如 TrimCaching),通過多播和量化減少傳輸成本;
- 訓練:支持集中式邊緣學習、聯邦學習、拆分學習和分層協同學習,結合參數高效微調降低資源消耗;
- 推理:包括集中式推理(邊緣服務器統一處理)、拆分推理(設備與服務器分工)、協同推理(設備生成初步結果,服務器驗證)。
-
未來方向
- 綠色邊緣 LLM(降低能耗)、安全邊緣 LLM(防御隱私攻擊)、質量感知的邊緣 LLM 訓練(數據質量控制)。
一、相關技術總結
-
資源高效的 LLM 技術
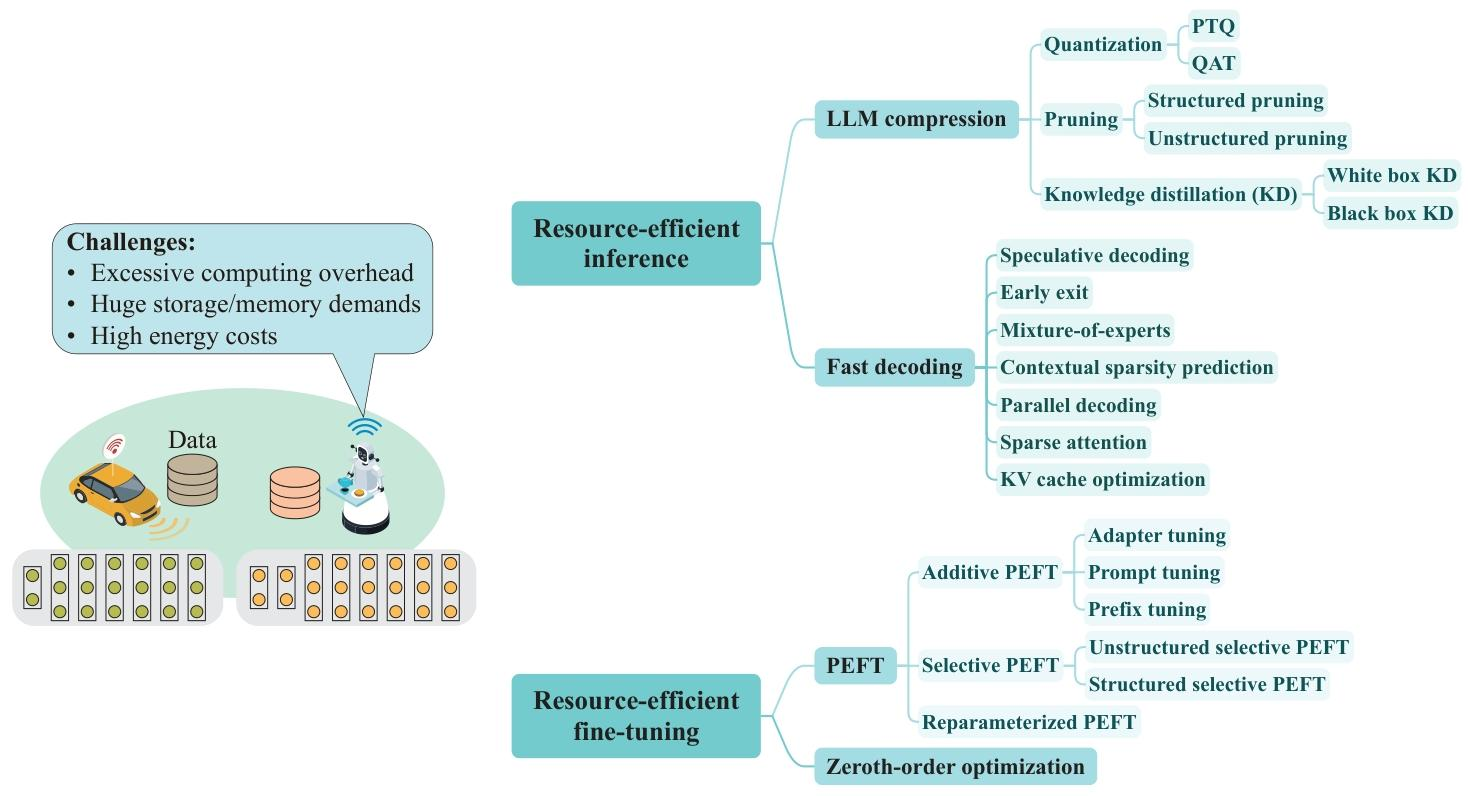
技術類別 具體方法 核心原理 優點 缺點 性能表現(典型案例) 模型壓縮 量化(PTQ/QAT) 將高精度參數(如 FP16)轉為低精度(如 INT4/INT8) 減少存儲和計算量,適配邊緣設備內存 可能導致精度損失,QAT 需額外訓練資源 Llama2-7B 經 4-bit 量化后內存從 28GB 降至 3.5GB,精度損失 <1% [8,131] 剪枝(結構化 / 非結構化) 移除冗余參數(如注意力頭、權重) 降低模型復雜度,加速推理 非結構化剪枝需專用硬件支持 GPT-3 經 60% 非結構化剪枝后,精度無顯著損失 [133] 知識蒸餾 用小模型(學生)學習大模型(教師)的輸出分布 保留核心能力,模型體積大幅縮減(如 10 倍) 蒸餾過程需大量標注數據,可能丟失細粒度知識 MiniLLM 在文本生成任務上性能接近教師模型,體積縮減 90% [134] 快速解碼 投機解碼 輕量模型生成候選 token,大模型驗證修正 減少自回歸迭代次數,延遲降低 50% 以上 需維護輕量模型,驗證錯誤可能引入額外成本 llama.cpp 中投機解碼使生成速度提升 2 倍,能耗降低 50% [129] 早期退出 在中間層設置出口,滿足置信度時終止推理 動態平衡速度與精度,短文本任務加速顯著 長文本生成中需保留 KV 緩存,增加內存占用 BERT 經早期退出優化后,推理速度提升 40%,精度損失 <2% [137] 參數高效微調 LoRA 凍結預訓練權重,僅訓練低秩矩陣 微調參數減少 99%,適配邊緣設備計算能力 推理時需合并低秩矩陣,可能增加延遲 LLaMA-7B 經 LoRA 微調后,下游任務性能接近全量微調,參數僅增加 0.1% [153] 前綴調優 在輸入前添加可訓練的軟提示(Soft Prompt) 無需修改模型結構,適配多任務場景 提示設計依賴人工經驗,復雜任務性能有限 GPT-2 通過前綴調優在機器翻譯任務上 BLEU 值達 69,接近全量微調 [149] - 模型壓縮:
- 量化:將高精度參數轉為低精度(如 INT4),減少存儲和計算量(如 GPTQ、AWQ);
- 剪枝:移除冗余參數,分結構化(剪枝注意力頭)和非結構化(稀疏化權重)兩類;
- 知識蒸餾:通過 “教師 - 學生” 模型傳遞知識,適配邊緣設備(如 MiniLLM)。
- 快速解碼:
- 投機解碼:用輕量模型生成候選 tokens,由大模型驗證,減少迭代次數;
- 早期退出:在中間層終止推理,平衡速度與精度;
- KV 緩存優化:壓縮或動態管理緩存,減少內存占用(如 MiniCache)。
- 參數高效微調:
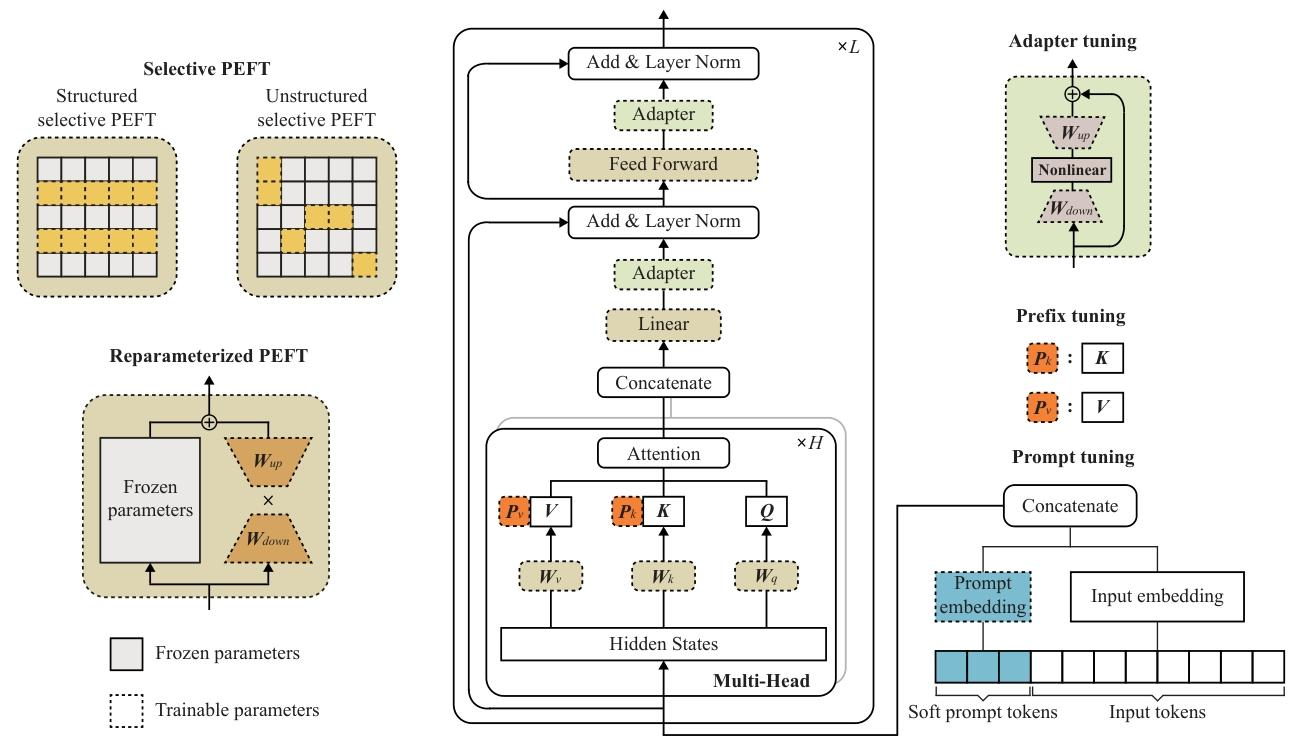
- 適配器調優(Adapter Tuning)、前綴調優(Prefix Tuning)等,僅更新少量參數即可適配下游任務;
- LoRA 通過低秩矩陣分解減少微調參數,兼容邊緣設備。
- 模型壓縮:
-
邊緣 LLM 緩存與分發
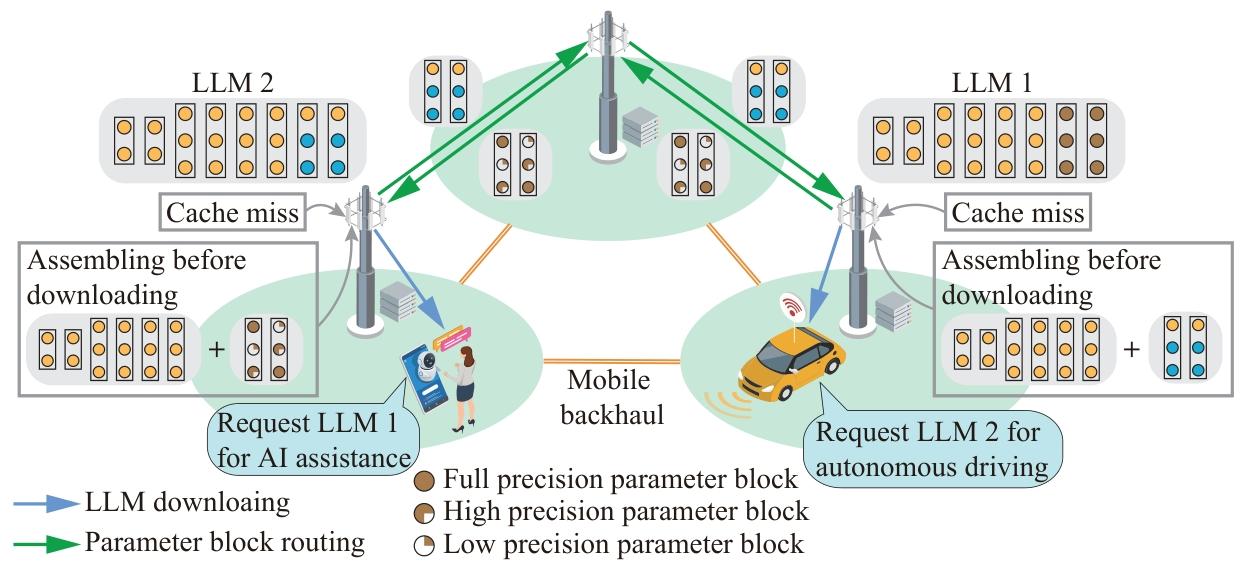
技術方法 核心原理 優點 缺點 性能表現(典型案例) 參數共享緩存 緩存共享參數塊(如預訓練權重),僅存儲任務特定參數(如 LoRA 適配器) 存儲效率提升 5-10 倍,支持多模型并發 緩存替換策略復雜,依賴參數共享度 TrimCaching 在 12 個邊緣服務器部署 100 個微調模型,緩存命中率提升至 80% [197] 多播分發 對共享參數塊多播,任務特定參數單播 傳輸效率提升 3-5 倍,減少帶寬消耗 多播組管理復雜,適用于密集用戶場景 多播分發 Llama2-7B,下載延遲從 5s 降至 1.2s [198] 量化傳輸 模型參數量化后傳輸,邊緣設備解壓使用 傳輸量減少 4-8 倍,適配低帶寬邊緣網絡 解壓增加設備計算負擔,可能損失精度 4-bit 量化傳輸 GPT-3,傳輸時間減少 75%,精度損失 <2% [199] - 緩存策略:利用 LLM 參數共享特性(如 LoRA 微調模型共享預訓練權重),采用 TrimCaching 等方法減少存儲冗余;
- 分發優化:通過參數塊多播、量化傳輸、聯合緩存與路由優化,降低傳輸延遲和帶寬消耗。
-
邊緣 LLM 訓練與推理
- 訓練框架:
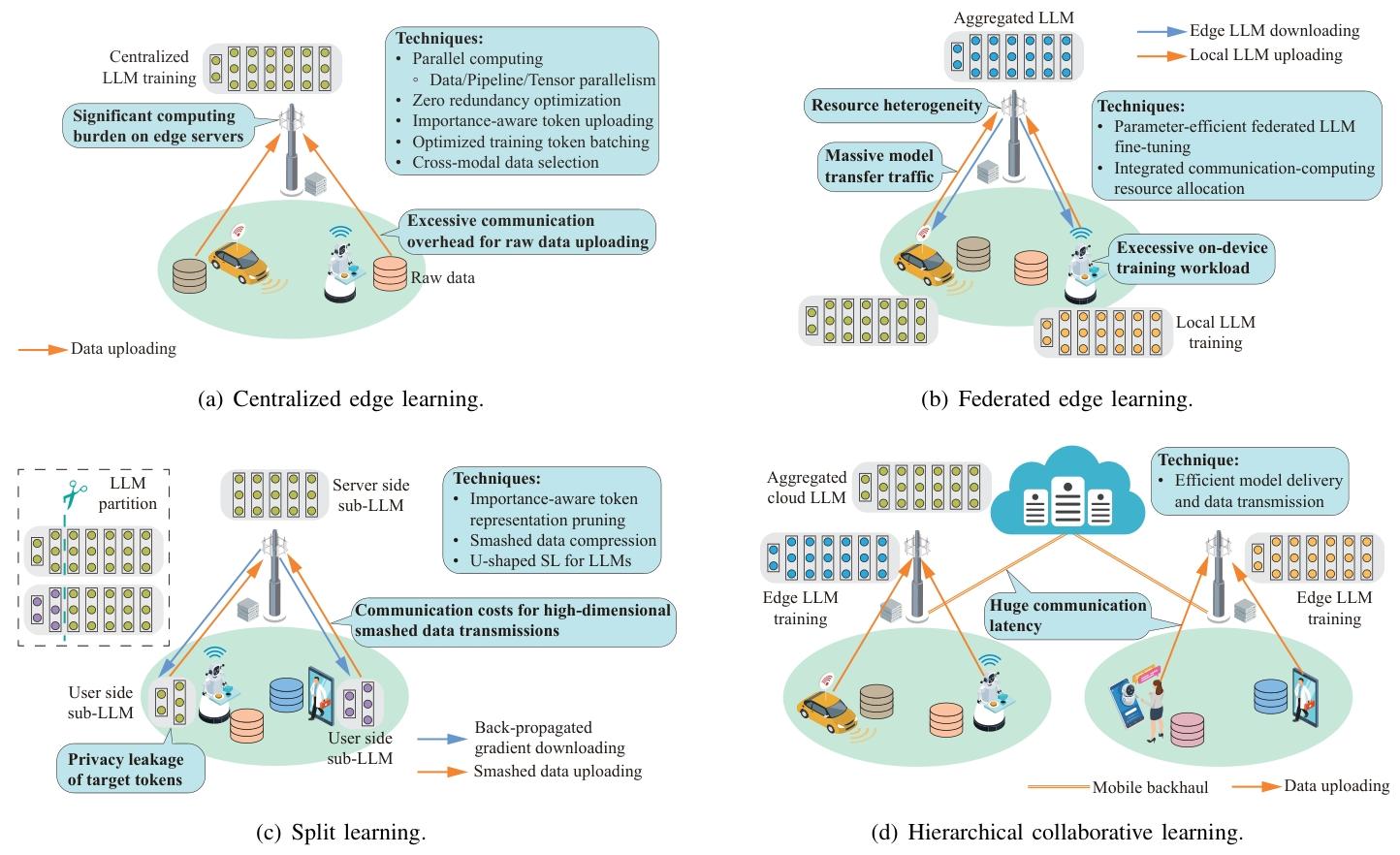
訓練框架 核心原理 優點 缺點 性能表現(典型案例) 集中式邊緣學習 邊緣設備上傳數據至服務器,統一訓練 訓練效率高,適合數據非敏感場景 隱私風險高,上傳海量多模態數據消耗帶寬 用 12 個邊緣服務器并行訓練 LLaMA-2 7B,每輪迭代 latency 降低至 80s [216] ?聯邦學習(FL) 設備本地訓練,僅上傳模型更新,服務器聚合 保護數據隱私,適配分布式數據場景 通信成本高,設備異構性導致訓練不穩定 聯邦 LoRA 微調 LLaMA-13B,通信量減少 99%,精度損失 <3% [218] 拆分學習(SL) 模型拆分為設備端和服務器端子模型,通過中間特征交互訓練 避免原始數據上傳,平衡隱私與計算效率 中間特征傳輸仍可能泄露隱私,拆分點選擇影響性能 拆分 GPT-3 在醫療數據上訓練,隱私泄露風險降低 70%,精度保持 95% [225] 分層協同學習 云 - 邊緣 - 設備三級協同,邊緣聚合本地模型,云端聚合全局知識 兼顧全局泛化與本地適配,支持大規模部署 架構復雜,跨層通信延遲高 自動駕駛場景中,分層訓練使模型適配不同區域路況,精度提升 15% [228] - 聯邦學習:邊緣設備本地訓練,僅上傳模型更新,保護數據隱私(如 FedLoRA);
- 拆分學習:將模型拆分為設備端和服務器端子模型,通過中間特征交互協同訓練,減少原始數據傳輸;
- 分層協同學習:結合云、邊緣、設備三級資源,平衡全局知識與本地適配。
- 推理框架:
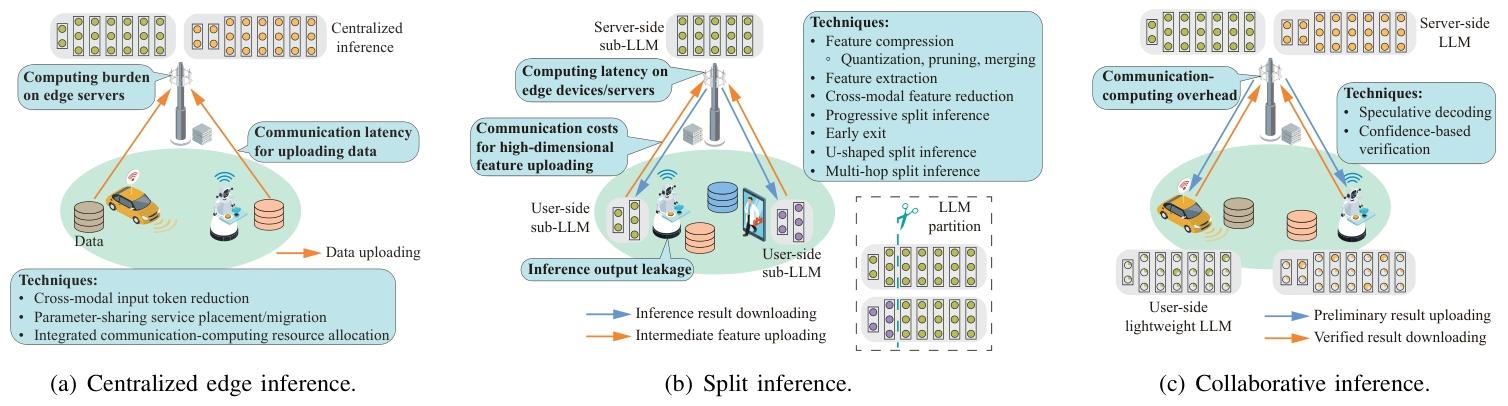
推理框架 核心原理 優點 缺點 性能表現(典型案例) ** 集中式推理 設備上傳數據至邊緣服務器,由服務器執行完整推理 利用服務器強算力,支持大模型 隱私風險高,上傳多模態數據帶寬消耗大 邊緣服務器部署 Llama2-70B,推理延遲比云端低 60% [24] ** 拆分推理 設備處理底層網絡,服務器處理高層網絡,通過中間特征交互 減少原始數據傳輸,平衡隱私與延遲 特征傳輸仍占帶寬,拆分點需優化 拆分 GPT-4 在自動駕駛場景中,延遲降至 50ms,帶寬消耗減少 40% [277] ** 協同推理 設備用輕量模型生成初步結果,服務器用大模型驗證修正 設備端快速響應,服務器保證精度 驗證錯誤可能導致返工,需協調設備與服務器模型 虛擬助手場景中,協同推理使響應延遲 <100ms,準確率達 92% [278] - 集中式推理:邊緣服務器統一處理,適用于非敏感數據;
- 拆分推理:設備處理部分層并上傳中間特征,服務器完成剩余計算,平衡隱私與延遲;
- 協同推理:設備用輕量模型生成初步結果,服務器用大模型驗證,提升效率(如投機解碼)。
- 訓練框架:
二、未來研究方向
-
綠色邊緣 LLM:聚焦降低邊緣 LLM 訓練和推理的能耗,通過優化算法(如基于零階優化器減少內存消耗)、硬件創新(如三星的 PIM 和 PNM 技術提升內存帶寬與容量同時降低能耗),適配電池供電的邊緣設備,滿足可持續發展需求 。
-
安全邊緣 LLM:抵御隱私攻擊(如防止通過中間特征恢復原始數據)、對抗攻擊(如數據投毒),保障 LLM 在邊緣安全運行。研究安全聚合協議、加密機制,確保聯邦學習中模型更新安全傳輸;開發魯棒訓練算法,提升模型抗攻擊能力 。
-
質量感知的邊緣 LLM 訓練:在邊緣數據質量參差不齊的情況下,實現數據質量控制。研究數據篩選、增強技術,結合邊緣設備數據特性優化訓練過程,如利用分層協同學習框架,在不同層次對數據質量進行評估與處理,提升模型泛化性和準確性 。
三、難點
-
通信瓶頸:現有研究多關注計算效率,忽視通信對 LLM 訓練、推理、緩存及分發的影響。在移動邊緣網絡中,多模態數據上傳下載、中間特征傳輸消耗大量帶寬,制約 LLM 性能,需設計通信高效的邊緣架構與協議 。
-
模型與網絡協同優化:當前 LLM 資源高效技術與無線邊緣網絡相互作用研究不足。如參數高效微調、分割推理等技術在復雜網絡環境下性能不穩定,需聯合優化模型部署與網絡資源分配 。
-
邊緣設備異構性:邊緣設備在計算、內存、存儲能力上差異大,難以統一適配 LLM。需開發自適應技術,根據設備能力動態調整模型配置、訓練推理策略,保障不同設備上 LLM 的可用性與性能 。
--學習筆記17(Websocket))

,外加安裝兩個常用插件)




與 JDK、Maven、MyBatis-Plus、Tomcat 的版本對應關系及關鍵注意事項)







超詳細總結)

)

