文章目錄
- 一、直覺上重要的視覺特征
- 二、視覺神經網絡首層試圖自主學習 TGD 算子權重
- 2.1 AlexNet
- 2.2 Vision Transformer
- 2.3 MLPMixer
- 三、針對直覺的驗證試驗
- 3.1 小樣本集自然圖像分類任務
- 3.2 小樣本集醫學圖像分割任務
- 四、結語
早在 2012 年,卷積神經網絡 AlexNet 就已經開始自主學習 TGD 算子和 TGD 特征的雛形了!
TGD 是我們定義的一種新的“變化率表征”,對連續函數而言是一種新的“廣義導數”,對離散序列而言是一種新的差分。TGD 是一個名字,一個代號。所謂「 TGD 特征 」,實則為輸入序列卷積 TGD 算子得到的結果,輸入序列可以為圖像,也可以是視頻,也可以是連續 CT 掃描圖等等等等。在上一篇中,我們介紹了將「 TGD 特征 」引入神經網絡,提升了計算機視覺任務的性能。然而,在此之前我們就已經發現,“ 神經網絡本就在自主選擇學習 TGD 算子得到 TGD 特征 ”。感興趣的朋友歡迎閱讀前面的章節:
理論部分:
TGD 第一篇:初心——我想要為“階梯函數”求導。
TGD 第二篇:破局——去除導數計算中的無窮小極限。
TGD 第三篇:革新——卷積計算導數的高效之路。
TGD 第四篇:初瞰——抗噪有效的定性計算。
TGD 第五篇:飛升——給多元函數的導數計算加上全景雷達。
TGD 第六篇:落地——離散序列的 TGD 計算。
計算機視覺應用部分:
TGD 第七篇:一維應用——信號去噪和插值。
TGD 第八篇:二維應用——圖像邊緣檢測。
TGD 第九篇:三維應用——視頻邊緣檢測。
TGD 第十篇:當神經網絡遇到 TGD 特征。
一、直覺上重要的視覺特征
傳統計算機視覺認為, 顏色、紋理、邊緣 是最重要的三類視覺特征。前兩者都是區域特征,描述物體的表面物理特性;后者是輪廓特征,明確各區域之間的邊界。區域和輪廓的結合進一步可以幫助我們分割識別并理解物體。
有些簡單任務,單獨的某類特征足矣。如顏色是我們分類三色旗的重要特征,包括法國(藍、白、紅),俄羅斯(白、藍、紅),德國(黑、紅、金),意大利(綠、白、紅),荷蘭(紅、白、藍)等;紋理是我們分類純色絲綢、棉布、麻布等布料等的重要特征;邊緣是我們分類圓形、正方形、三角形等的重要特征。
但是對于更為復雜的視覺分類任務,通常需要他們協同配合,從這些視覺特征的組合中去理解和判斷更復雜的物體。
值得指出的是,無論是“顏色”、“紋理”、還是“邊緣”特征,它們需要 在包含多個像素點的區域中進行統計計算 。在傳統計算機視覺算法中已經論證,通過一次簡單的卷積計算,就可以提取出顏色、紋理、邊緣特征。紋理常用的是 Gabor 函數卷積核、邊緣(梯度)特征對應的則是 TGD 卷積核。
理論上,視覺神經網絡的第一層卷積層就是執行單次卷積,具備了提取的圖像中顏色、紋理、邊緣特征的能力。那么神經網絡會這么做嗎?
二、視覺神經網絡首層試圖自主學習 TGD 算子權重
說在前面,為力求保真,下面引用的視覺神經網絡的首層卷積核結果可視化圖均源自該網絡原始論文。
2.1 AlexNet
2012 年,深度卷積神經網絡 AlexNet 贏得 ImageNet 圖像分類任務競賽冠軍,標志著深度學習時代的開啟。AlexNet 網絡結構圖如下所示,首層便是一個 11×11×311 \times 11 \times 311×11×3 尺寸的卷積層。可以說,神經網絡從首層開始就在進行特征提取了。作為開山鼻祖, AlexNet 第一層在提取些什么?
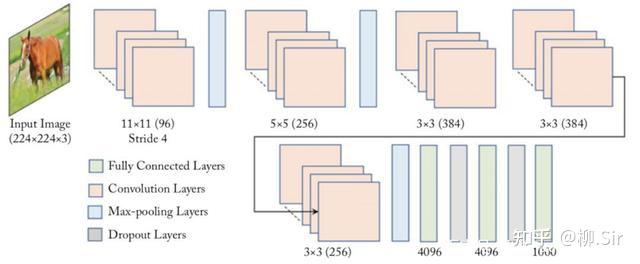
下圖展示了經過 ImageNet 訓練得到的,AlexNet 首層卷積層中的 969696 個 11×11×311\times11\times311×11×3 的卷積核可視化結果1,圖片源自 AlexNet 原始論文。作者誠然: 網絡學習到了各種頻率和方向選擇性的核,以及各種彩色斑點 (The network has learned a variety of frequency- and orientation-selective kernels, as well as various colored blobs. )。在我看來,色彩斑點卷積核即提取的是顏色特征;第二行很多黑白黑白間隔的卷積核實則為 Gabor 函數卷積核,提取的是紋理特征;而紅框中則標注出了很多類似 TGD 算子的卷積核,提取的是邊緣(圖像梯度)特征。即: 神經網絡在首層自主選擇學習“顏色”、“紋理”、“邊緣”,這些重要且易獲取的視覺特征 。

在 AlexNet 之后,VGGNet 指出,盡管大卷積核具有更強的擬合和表征能力,但是直接訓練大卷積核是存在難度的(數據量和算力帶來的歷史局限性),建議采用連續的 3×33 \times 33×3 小尺寸卷積核來等效大尺寸卷積核,并取得了更好的性能。使用連續小尺寸卷積核將導致網絡層數增多,并帶來訓練過程中梯度消失的風險。ResNet 提出的殘差結構很好地化解了網絡層數增多時面臨的訓練困境,使得網絡的層數可以向成百上千邁進。在隨后數年的發展中,用于圖像分類、醫學分割、目標檢測等任務的主流卷積神經網絡基本采用 1×11 \times 11×1 和 3×33 \times 33×3 小尺寸卷積核,尺寸在 7×77 \times 77×7 及以上的卷積核則很少出現。在這些神經網絡中,首層中的 3×33 \times 33×3 等小卷積核的結構屬性和可解釋性較差,可視化也看不出什么來,難以分辨直接提取什么特征。
2.2 Vision Transformer
邁入 2020 年,算力和數據集規模已經取得了極大的發展,研究者不滿足于簡單地使卷積神經網絡維度上升、層數增加。視覺研究人員注意到 Transformer 在自然語言處理中的應用和成功 ,其使用的自注意力機制將整個輸入序列納入考量。此時視覺研究者意識到在更大的圖片塊上提取特征的時機已經成熟,并基于此提出了新的視覺范式 Vision Transformer(ViT)2,作為其核心的自注意力機制等效于在 CNN 卷積層中引入一個超大的卷積核,但是卷積核權重與輸入相關。ViT 首層采用等效于 14×1414 \times 1414×14 和 16×1616 \times 1616×16 尺寸的卷積核,然而實踐表明其需要使用億級乃至十億級數據量進行預訓練,才能獲得優質的模型權重。
下圖展示了經過 JFT300M 訓練得到的,ViT-L/32 首層 282828 個線性編碼層卷積核可視化結果,圖片源自 ViT 原始論文。作者同樣認為: 網絡首層學習到的這些卷積核旨在獲取每個 Patch 內精細結構的特征表示。 (Figure 7 (left) shows the top principal components of the the learned embedding filters. The components resemble plausible basis functions for a low-dimensional representation of the fine structure within each patch. )。在我看來,下圖中有略微幾個訓練的比較好的 Gabor 函數算子用于提取紋理特征,還有少數提取顏色的卷積核,提取圖像邊緣(梯度)特征的算子訓練得不夠理想, 這可能與自注意力機制 Self-Attention 本身就具備區域關注能力有關 ,使得邊緣特征可能在注意力分布圖中而非首層中體現了。

2.3 MLPMixer
短短一年之后,即 2021 年,視覺社區進一步思考:“能否放棄自注意機制,讓模型從原始數據中自主地學習輸入無關的超大卷積核”?研究人員將 Vision Transformer 中的注意力層直接替換為單層全連接層,并提出了視覺新范式:深度 MLP 模型 3。MLPMixer 中的單層全連接層(Token-mixing MLP)依然等效于使用一個 14×1414 \times 1414×14 或 16×1616 \times 1616×16 的超大尺寸卷積核。然而在當下的數據量基礎上,采用超大尺寸稠密卷積核的 MLPMixer 性能要弱于基于人為設計自注意力機制的 ViT,延續了“數據不夠,先驗來湊”的歷史周期律,這表明直接訓練優質的超大尺寸卷積核或許需要更多的數據作為支撐。
下圖展示了經過 JFT300M 訓練得到的,MLPMixer-B/32 首層 192192192 個線性編碼層卷積核可視化結果,圖片源自 MLPMixer 原始論文。作者認為: 網絡首層學習到了非常具有結構化的卷積核。 (Mixer-B/32 model that uses patches of higher resolution 32×3232 \times 3232×32 learns very structured low frequency projection units, …, using patches of higher resolution 32×3232 \times 3232×32 leads to Gabor-like low-frequency linear projection units)。從下圖中我們同樣看到了顏色、紋理、邊緣特征的提取算子。作者在圖中找到了一些 Gabor 函數卷積核,事實上其中絕大部分是 TGD 算子(紅框框出的部分),用于計算圖像的邊緣(梯度)特征。結果符合我的直覺, MLPMixer 沒有自注意力機制,為此需要把 TGD 算子嵌入網絡首層權重中 。

從 AlexNet,到 ViT,再到 MLPMixer,三種不同范式的視覺神經網絡都告訴我們:從海量數據中自主學習后, 顏色、紋理、邊緣是首層需要提取的三類重要視覺特征 。傳統計算機視覺的人類實踐,與 AI 的抉擇,保持高度一致。此外,大約統計可發現,邊緣特征約占輸入層提取通用特征的 20%20\%20% 至 30%30\%30% 。
為了提取圖像的邊緣(梯度)特征,模型在首層試圖學習 TGD 算子的雛形。可以說,早在 2012 年,我剛小學畢業,TGD 算子的雛形就已經被眾多研究者從 AlexNet 的論文中看到過了。但是卻沒人知道罷了,就像 Dosovitskiy 大佬只認為其是 Gabor-like。
注意到,這是純靠數據驅動訓練出來的算子,和數學理論推導出來的算子有些許差別。如數學理論上為了保證常函數的 TGD 值為 000 ,這要求 TGD 算子的權重和為 000 ,僅此一條,數據驅動的學習方法就很難完美地學習出來,更勿論 TGD 數學理論中的 “單減約束” 了。
三、針對直覺的驗證試驗
你要這江湖,我便給你這江湖!
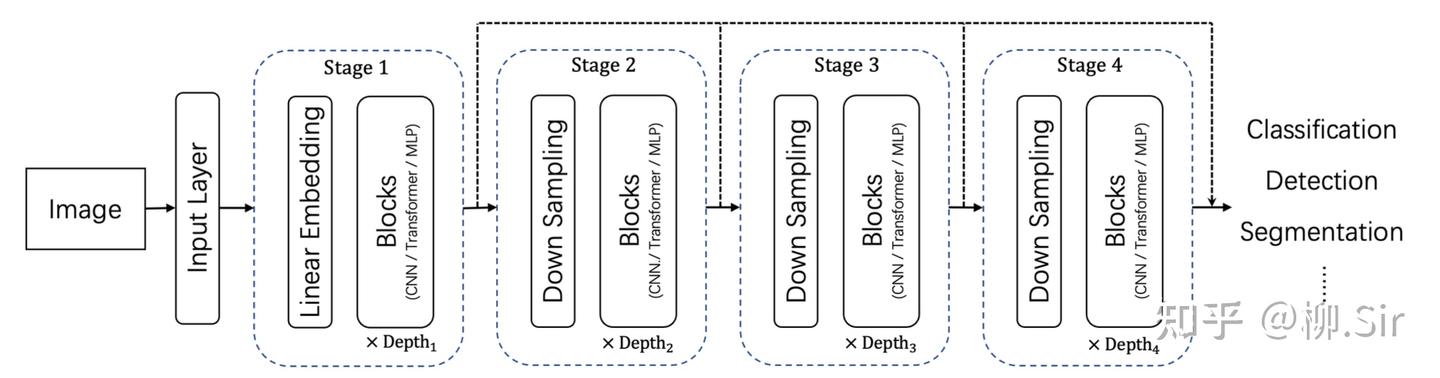
在上一篇中,我們是手動計算「 TGD 特征 」,并作為輸入引入神經網絡,當時我就埋了一個伏筆,TGD 計算其實是用 TGD 算子卷積輸入序列。為此,TGD 算子的權重其實可以作為首個卷積層的初始化卷積核參數,構造的卷積層能直接作為神經網絡的一部分。因為 TGD 算子是滿足各種理論約束的,為此這部分權重無需再訓練,只需訓練其他的權重就行了。下圖展示了傳統的通用視覺神經網絡架構,以及首層嵌入 TGD 算子后的通用視覺神經網絡架構。
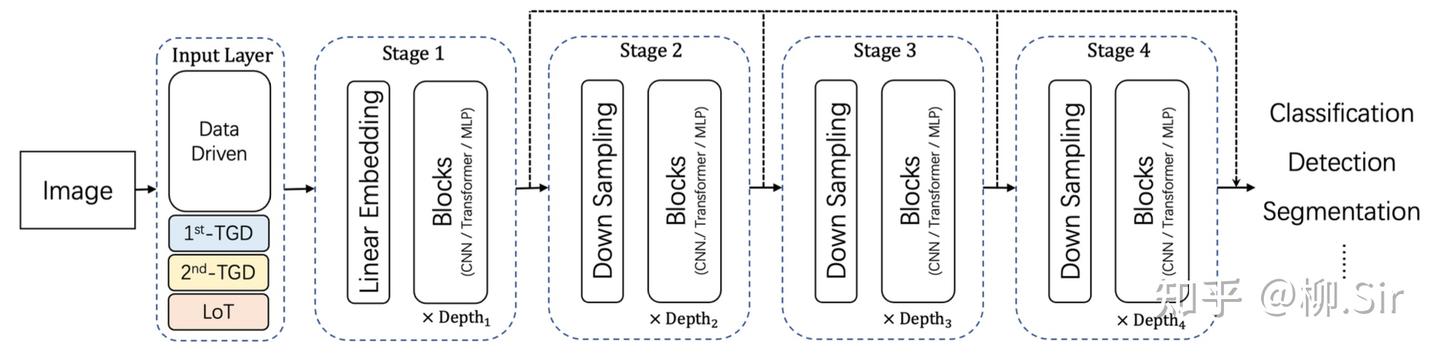
直覺上,嵌入 TGD 算子后會帶來 三個結果 :
- 如果 TGD 特征數量夠,神經網絡無需再學習圖像邊緣(梯度)特征,進而在數據驅動學習權重的部分專注其他類型特征;
- 初始階段就有優質的 TGD 特征,模型學習難度降低,訓練收斂速度會加快;
- 訓練數據量越少,效果提升越明顯。
為了驗證上述直覺,我進行了兩個小樣本環境下的小實驗(實驗不是按照發 paper 那樣嚴謹設置,當初就是想試試而已,看看就行)
3.1 小樣本集自然圖像分類任務
圖像分類實驗,選用 Oxford-102 花分類數據集4。作為經典小樣本數據集,其中每個類別僅有 101010 張圖片用于訓練, 101010 張圖片用于驗證,共計 614961496149 張圖片用作測試。下展示了 Oxford-102 數據集部分實例,可見各種花朵之間存在顏色和形狀區別。穩定的圖像梯度特征將有助于對于花朵的形狀進行識別,從而提升分類的精度。

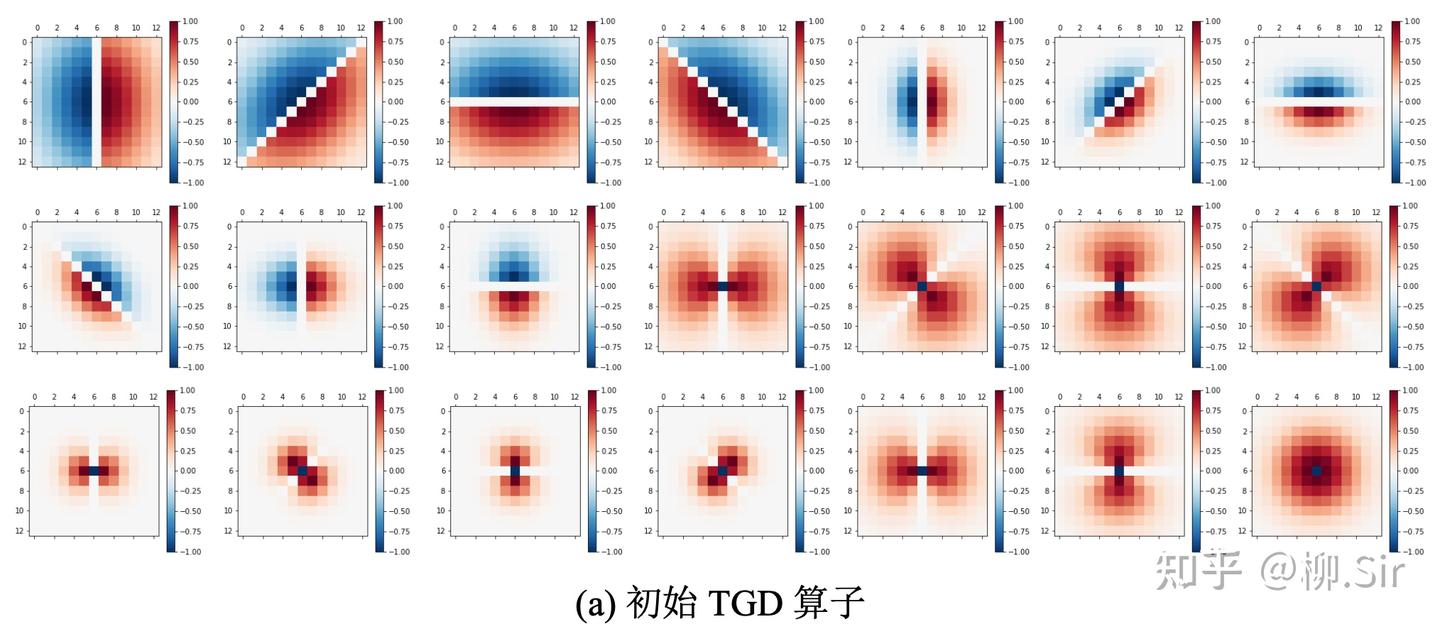
在實驗中選用了三個著名的視覺神經網絡:ResNet、VAN 以及 Swin。實驗源自 2022 年春,當時 Swin 很火,且隔壁實驗室的 VAN 剛提出,就用他們了。分別下載了基于 ImageNet 預訓練的開源模型權重用于后續實驗。在輸入層方面,注意到 ResNet 和 VAN 的輸入層輸出為 646464 個通道, Swin 則為 969696 個通道。為此,統一設定 212121 個尺寸為 13×1313 \times 1313×13 的 TGD 算子,約占輸入層提取特征的 20%20\%20% 至 30%30\%30% ,符合梯度特征約占輸入特征 30%30\%30% 的統計結果。首層卷積層 TGD 算子權重可視化如下圖所示,共包含 101010 個一階 TGD 算子、 101010 個二階 TGD 算子, 111 個 LoT 算子,為了更好展示其結構,算子權重經過歸一化處理,紅色值為正,藍色值為負,顏色越深,權重絕對值越大:
實驗分別在不含預訓練權重和含有預訓練權重兩種配置下進行。針對無預訓練情形,訓練輪次設定為 300 輪,使用 Adam 優化器以及交叉熵損失。初始學習率為 3×10?33 \times10^{?3}3×10?3 ,使用 MultiStepLR 策略,分別于第 40、 80、 160 和 240 輪將學習率衰減為當前的 20%20\%20% 。針對含 ImageNet 預訓練權重的模型,保留了非首層預訓練權重,訓練輪次設定為 100 輪,依然使用 Adam 優化器以及交叉熵損失,整個模型除 TGD 算子權重外均可訓練。初始學習率為 1×10?41 \times 10^{?4}1×10?4 ,使用 MultiStepLR 策略,分別于第 15 和 30 輪將學習率衰減為當前的 20%20\%20% 。batch 大小為 161616 。此外,結合了數據增強技術,包括隨機中心裁剪(RandomCrop)、隨機水平翻轉(RandomHorizontalFlip)和隨機垂直翻轉(RandomVerticalFlip)。最終選用驗證集性能最高的模型用于測試。
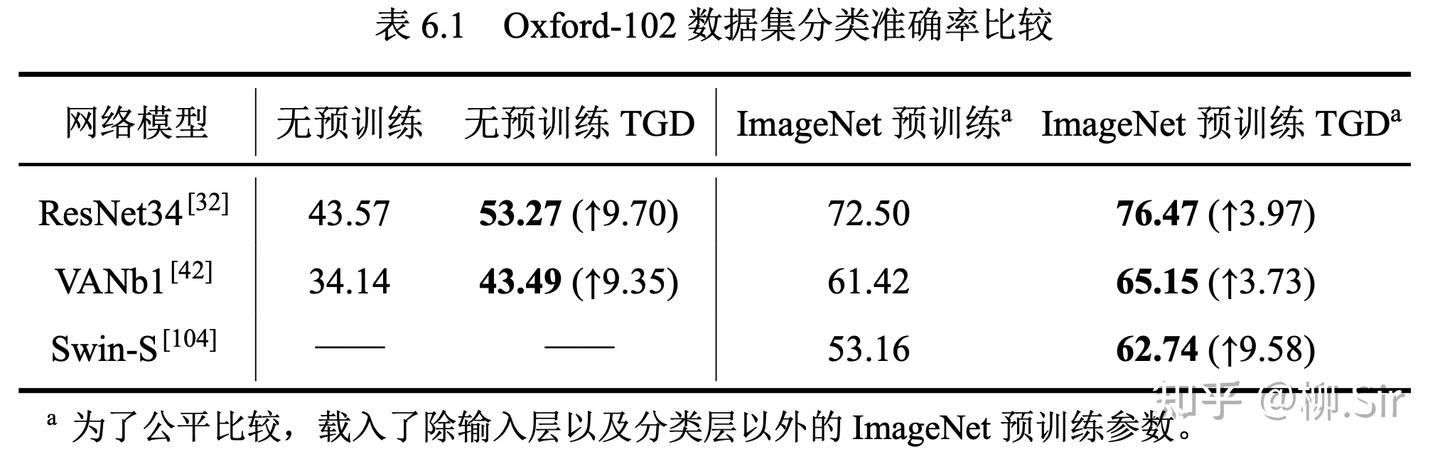
上表的結果表明,在小數據集規模下,無預訓練的神經網絡性能普遍較低,但 TGD 的引入帶來了近 10%10\%10% 的分類準確率提升。Swin 作為 Transformer 變種,其需要大量的數據進行訓練,在無預訓練權重加持下, Swin 在小數據集上并未收斂,為此不展示相關結果。當載入 ImageNet 預訓練參數后,網絡的性能大幅提升,然而小數據集依然不足以支撐網絡在輸入層學習到優質的特征提取模式。TGD 數學模型的引入依然能再次提升網絡的性能。
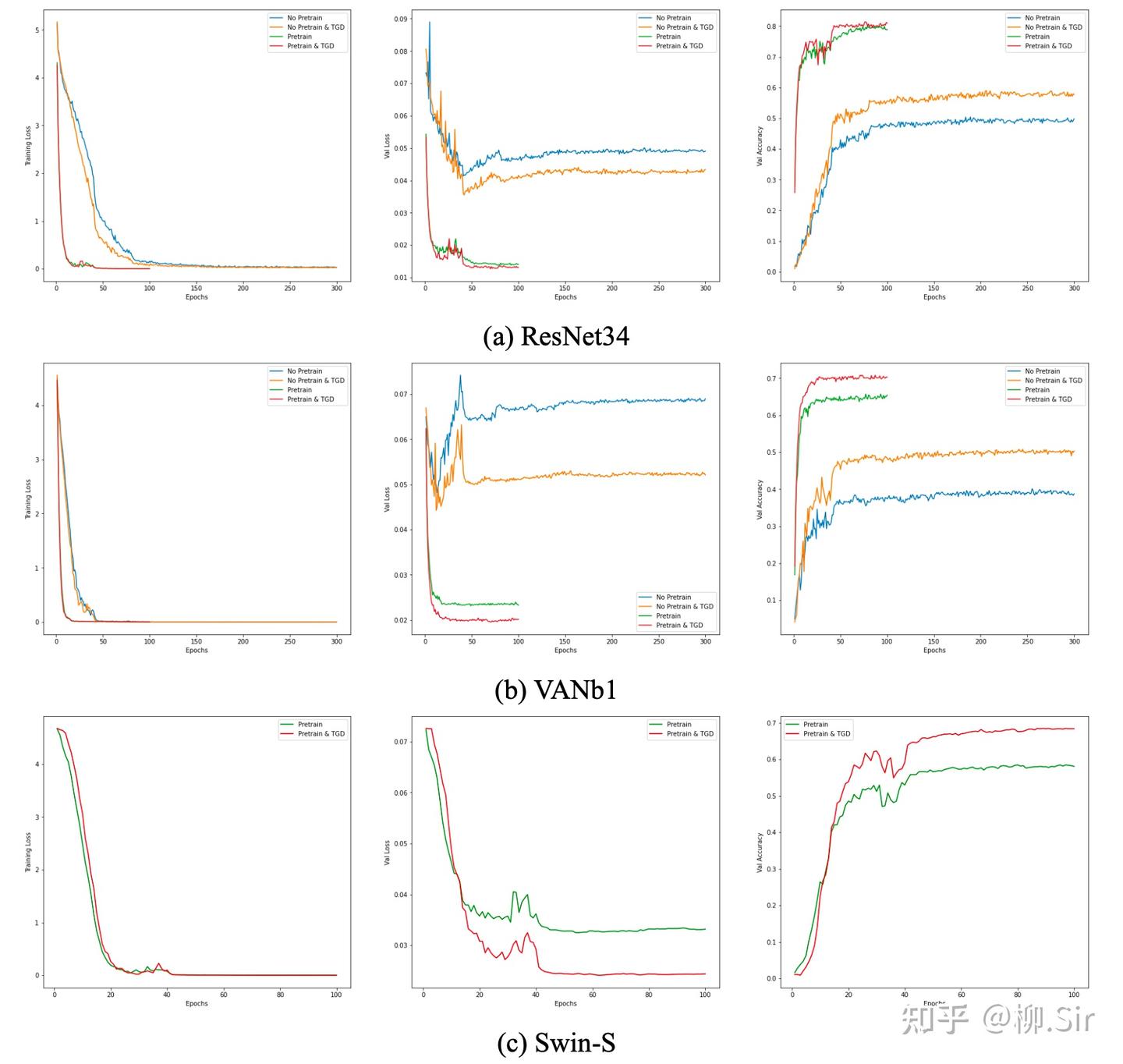
下圖展示了三個神經網絡在訓練過程中損失以及驗證集正確率的變化情況。首先可見,大家的訓練損失都很低,完全自主學習的神經網絡在小數據集上則非常容易出現過擬合,TGD 對模型收斂速度帶來的提升暫不明顯。當網絡的訓練損失很低且模型已經收斂時,嵌入 TGD 算子的網絡在驗證集上具有更小的損失以及更高的準確率。
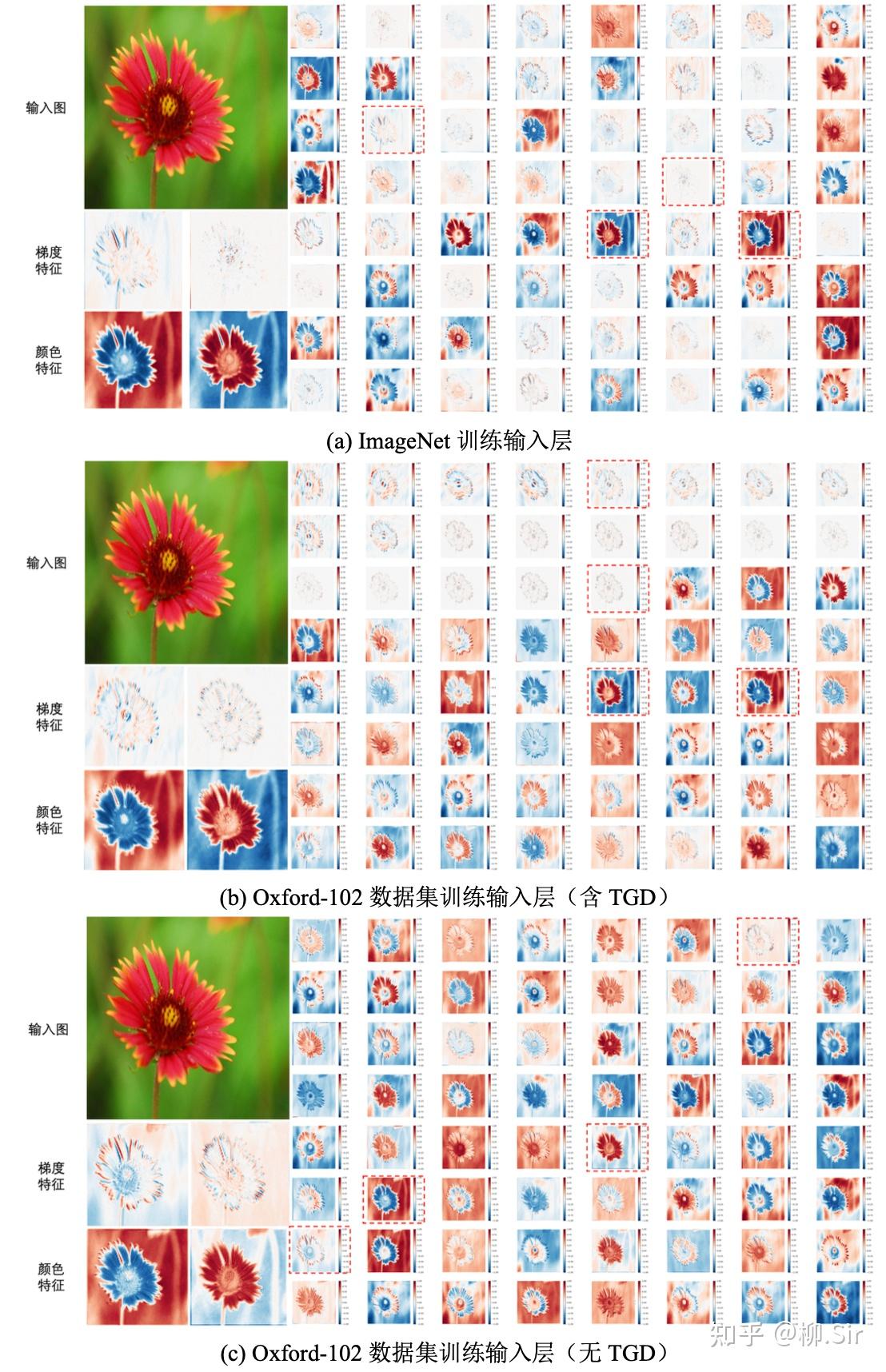
下圖進一步對 ResNet 輸入層特征圖進行比較,為了更好可視化,對特征圖進行了歸一化處理。在可視化結果中,紅色值為正,藍色值為負,顏色越深,特征絕對值越大。子圖(a)顯示,經過包含 130 萬張圖片的 ImageNet 數據集訓練得到的 ResNet,在其輸入層會自主選擇提取圖像梯度和顏色特征,盡管采用了百萬量級數據進行訓練,輸入層中用于圖像二階梯度計算的卷積核仍不夠理想。子圖(b)展示了在 Oxford-102 數據集上訓練得到的 ResNet 輸入層特征圖。結果顯示,在其 646464 個輸出通道中,前 212121 個通道采用了 TGD 數學模型提取更為精確魯棒的圖像梯度特征,而剩余的 434343 個通道則自發地學習如何提取包括顏色在內的非梯度特征,可見,TGD 的引入可以減輕網絡的學習負擔,在減少可學習參數的同時, 讓網絡自主學習部分更專注于非邊緣(梯度)特征的挖掘 。并且其針對部分顏色特征的提取能力與 ImageNet 數據集訓練得到的輸入層結果基本相近。當不設定任何數學模型并使用小數據集進行訓練,子圖? 的結果表明,在 646464 個輸出通道中, ResNet 僅有約 222 個通道在試圖學習邊緣(梯度)特征的提取方法且不夠理想,其余部分均在學習提取顏色等非梯度特征,說明邊緣(梯度)特征學習比顏色更難。
3.2 小樣本集醫學圖像分割任務
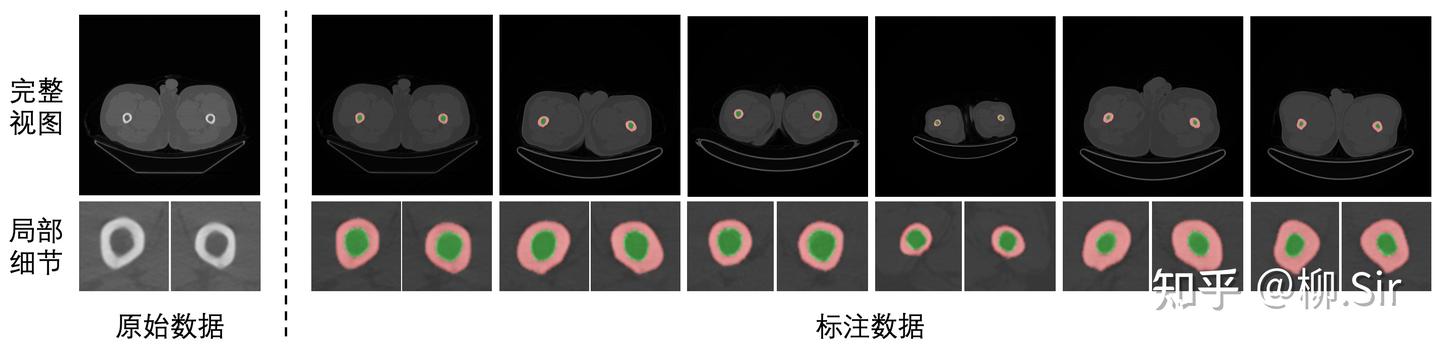
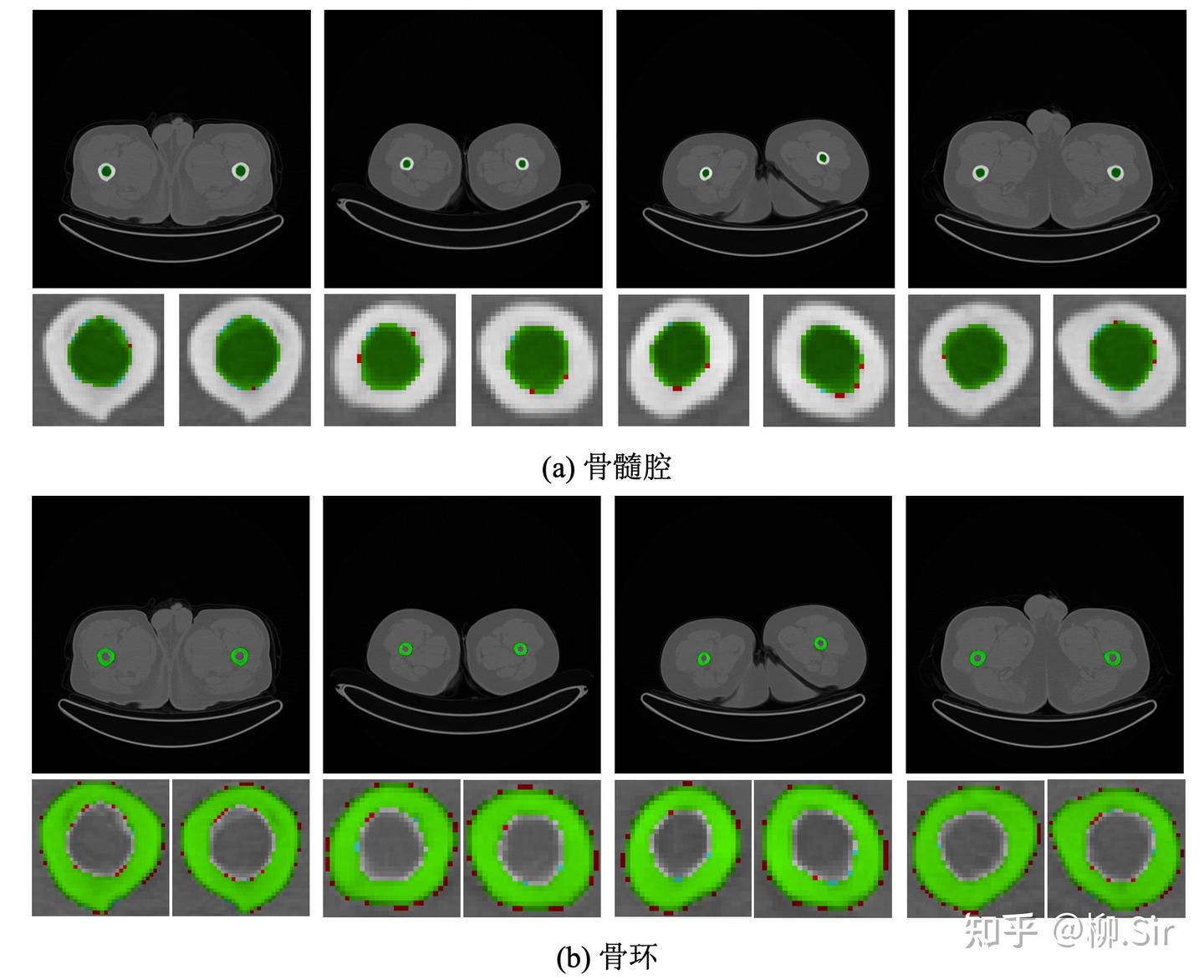
針對醫學圖像分割實驗,我們自行采集標注并構建了醫學腿骨分割數據集,實現對于人體大腿骨骨環以及骨髓腔的分割。數據集具體劃分結果為:訓練集含 110110110 張 CT 圖,驗證集含 737373 張 CT 圖,測試集含 286528652865 張 CT 圖。下圖展示了醫學腿骨分割數據集中的部分實例,第一行為完整視圖,第二行為局部細節放大圖,紅色部分標注了骨環,綠色部分標注了骨髓腔。大腿腿骨的骨環以及骨髓腔具有明確的邊緣,為此,將抗噪魯棒的 TGD 特征引入該任務將會有助于更精確的骨環以及骨髓腔的分割。
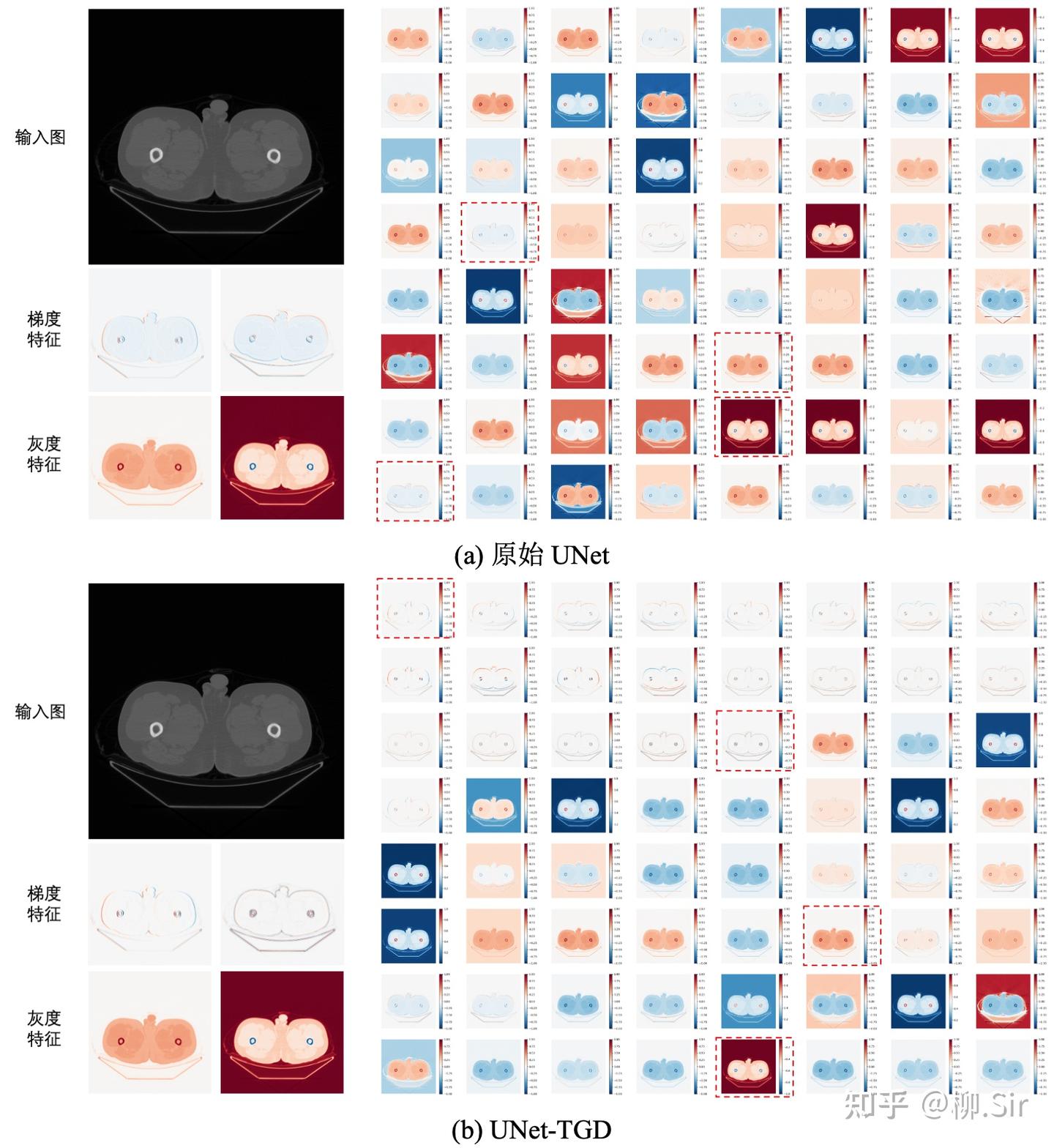
在實驗中選用了兩個主流的醫學圖像分割神經網絡: UNet 以及 UNeXt。注意到 UNet 的輸入層輸出為 64 個通道,UNeXt 則為 16 個通道,初始卷積核尺寸均采用 3×33 \times 33×3 。實驗中,針對 UNet 設定 212121 個尺寸為 13×1313 \times 1313×13 的 TGD 算子(含 121212 個一階 TGD 算子、 444 個二階 TGD 算子以及 555 個 LoT 算子),針對 UNeXt 設定 777 個尺寸為 13×1313 \times 1313×13 的 TGD 算子(含 444 個一階 TGD 算子、以及 333 個 LoT 算子)。初始化 TGD 算子有效尺寸囊括 3×33 \times 33×3 到 13×1313 \times 1313×13 (圖 6.10)。由于梯度特征中的正負值均有具體物理含義,表示灰度值增加或減少,所以在使用 TGD 算子時刪除了 UNet 和 UNeXt 中輸入層后緊連的 ReLU 激活函數,否則將會直接抹除負梯度特征。
訓練基于 UNeXt 官方開源代碼倉庫 5進行實現。UNet 訓練輪次設定為 100100100 輪;因 UNeXt 含全連接層且更難收斂,其訓練輪次設定為 400400400 輪。使用 Adam 優化器以及 BCEDiceLoss。初始學習率為 1×10?41 \times 10^{?4}1×10?4 , momentum 為 0.90.90.9 , weight_decay 為 1×10?41 \times 10^{?4}1×10?4 。使用 CosineAnnealingLR 策略,設定最小學習率為 1×10?51 \times 10^{?5}1×10?5 。訓練過程中 batch 大小為 444 。此外,結合了數據增強技術,包括隨機旋轉 90 度(RandomRotate90)以及隨機翻轉(RandomFlip)。最終選用驗證集 IoU 最高的模型用于測試。
實驗結果如下表所示,評價指標選用 IoU 和 Dice,以及像素分類的準確率(Precision)和召回率(Recall),指標越高,分割越準確。
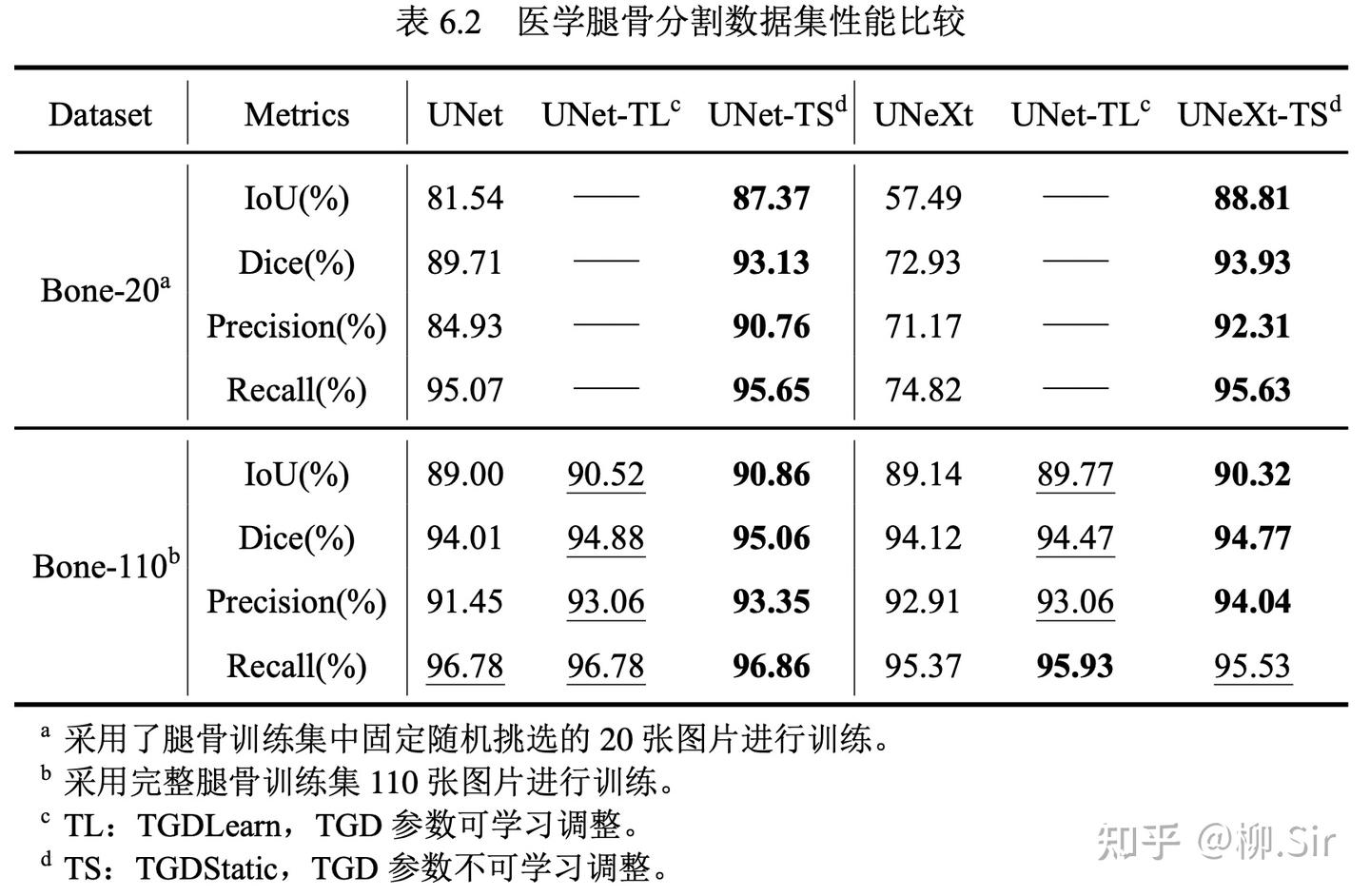
我一共進行了兩組對比實驗,分別在僅含 20 張訓練圖像的腿骨數據集子集 Bone-20,以及在含完整 110 張訓練圖像的腿骨數據集 Bone-110 上進行訓練。最優的指標加粗表示,次優的指標以下劃線形式展示。由于腿骨分割任務較為簡單,當在 Bone-110 數據集上訓練時,原始 UNet 和 UNeXt 都取得了不錯的結果。在引入 TGD 之后,模型的性能進一步提升。在本次實驗中,我新增 TGD 權重可訓練作為對比,實驗結果中 TGD 參數可訓練比僅采用初始參數的性能略低,其可能的成因是數據集規模太小,TGD 的參數未能很好訓練,參數的細微擾動會帶來特征噪聲,從而使模型性能降低。盡管如此,相較于不含 TGD 的樸素模型而言,可學習的 TGD 參數依然帶來了性能提升。Bone-20 數據集的結果則進一步展示了 TGD 特征在小數據集上的優勢。 當訓練數據減少,UNet 的性能大幅降低, UNeXt 甚至出現了欠擬合 。而 TGD 的引入為模型提供了穩定可靠的邊緣(梯度)特征,并使得模型取得了接近 5 倍數據量訓練的性能。
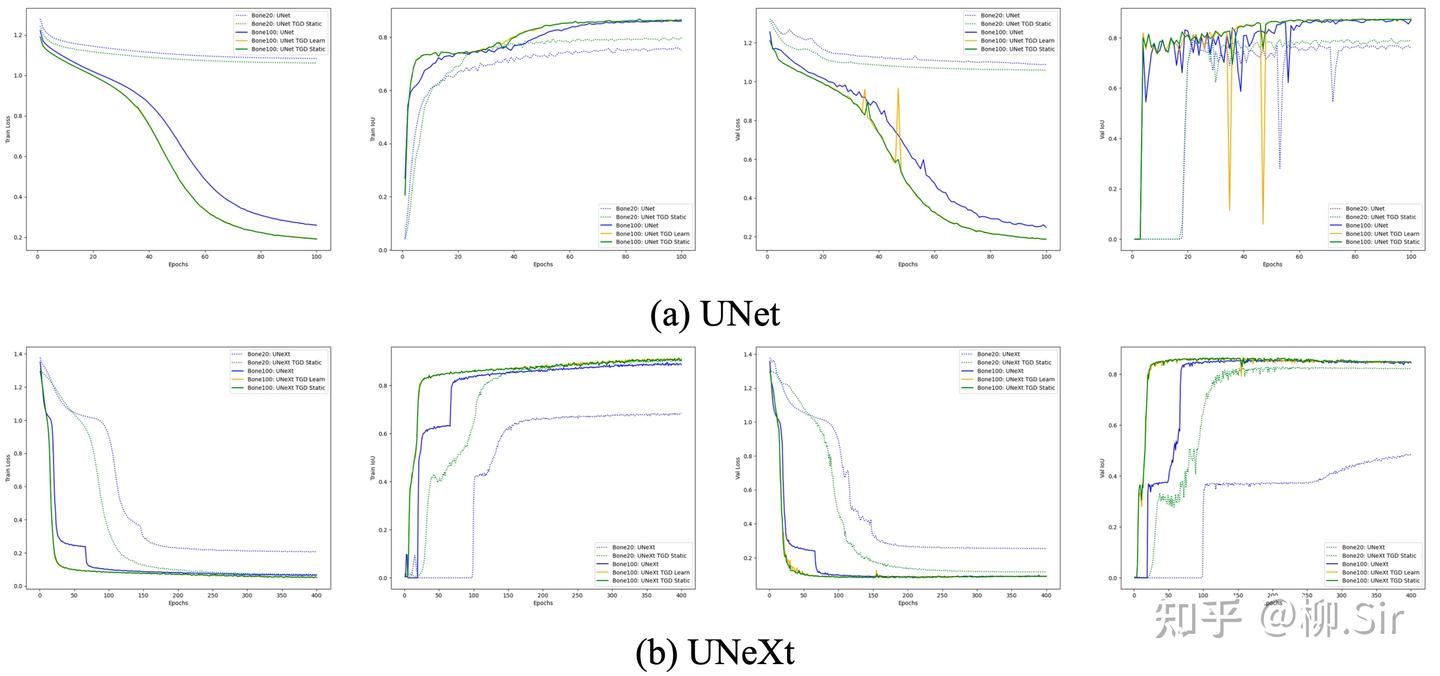
上圖展示了 UNet 和 UNeXt 在訓練過程中性能指標的變化,從左至右分別為訓練損失、訓練集 IoU、驗證集損失和驗證集 IoU。從訓練集指標變化可見,向模型中嵌入 TGD 算子后能夠幫助模型更快地收斂。驗證集指標變化則表明,TGD 算子計算得到的梯度特征具有更具泛化性,能夠幫助模型在驗證集上取得更好的效果。
下圖展示了使用不可訓練 TGD 參數在 Bone-110 數據集上訓練的 UNet 的分割結果,其中綠色像素表示分割結果與 Ground Truth 一致,紅色像素表示模型多分割的部分,藍色像素則表示模型少分割的部分。除骨環最外圈灰度漸變的數個像素本就模棱兩可外,模型實現了精確的像素級分割。
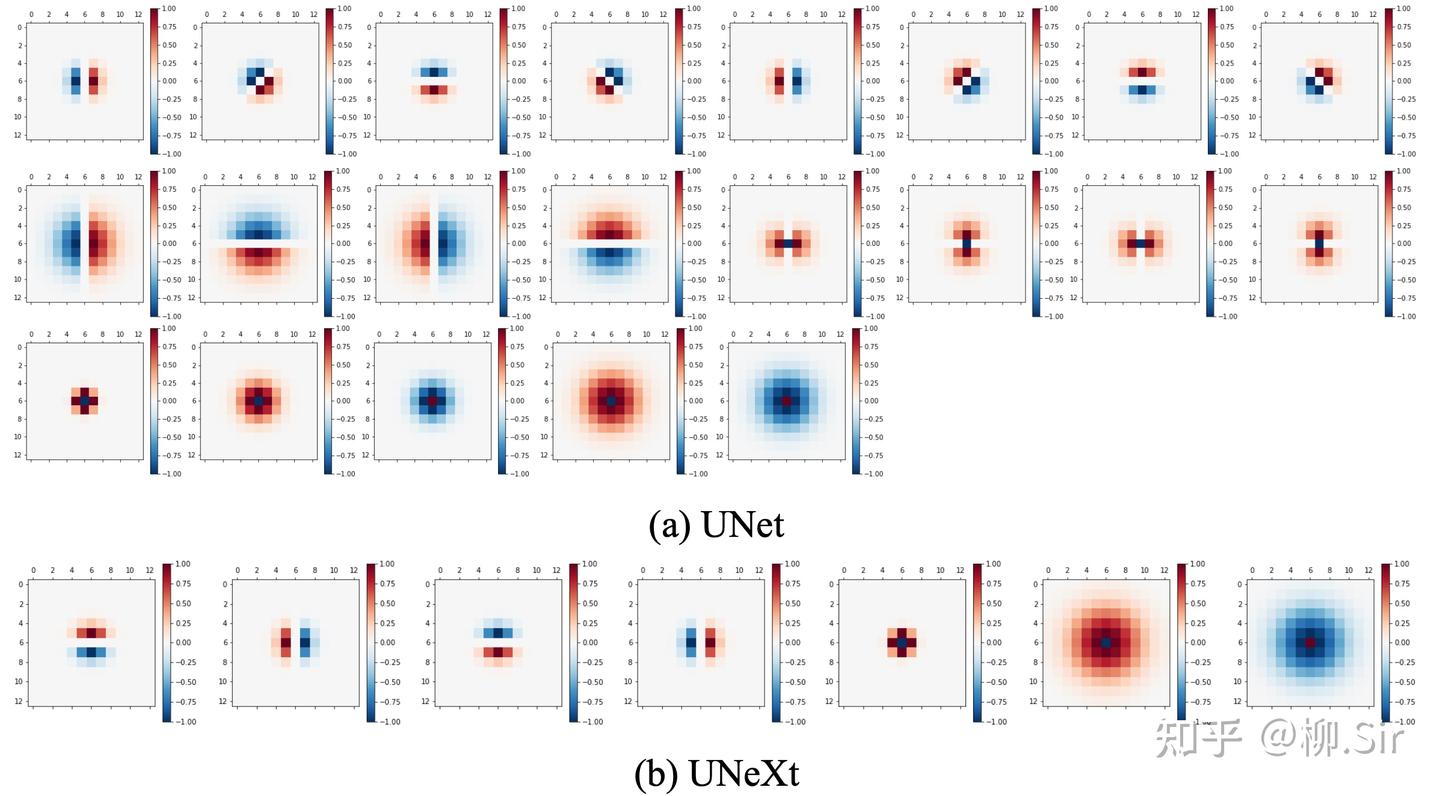
最后,展示在 Bone-110 數據集上訓練的 UNet 輸入層特征圖。當 UNet 對輸入層進行完全自主地進行數據驅動學習時,其會學習到數個(不完美的)一階梯度特征,更多的則是灰度值特征(類似自然圖像中的顏色特征),如灰度值越大,響應越大或越小等。當向 UNet 輸入層嵌入 TGD 算子之后,UNet 將在輸入層提取到各個方向的一階和二階梯度特征,并促使剩余通道主要關注灰度等非梯度特征。與數據驅動相比,基于數學模型計算的梯度特征更穩定可靠,它們為模型帶來了更好的分割性能以及更強的泛化能力。
在上面的小實驗中,有人可能會說,我對比實驗消融實驗不全,訓練設置得不夠好,會出現欠擬合啥的,準確率還不夠高啥的。
我想說,這不是為了發 paper 做的實驗,不是為了刷榜,不是為了煉丹,不是為了實用, 只是當時為了驗證我們對于 TGD 和神經網絡結合的直覺而已 。并且,前面談到的三大直覺都已經被實驗驗證了!
四、結語
本篇實則是拋開 TGD 的理論,依靠視覺特征的直覺和過去深度學習的實踐中,去理解 TGD 算子的正確性。TGD 算子的長相,早就在 2012 年的 AlexNet 論文中有所體現,只是數據驅動的學習方法很難完美地學習到數學理論的各種約束,更不論存在數據量和算力兩大歷史局限性。時至今日,數據量和算力這兩大歷史局限性或許仍未打破。后面的實驗,則是幫助神經網絡跳過學習 TGD 算子的步驟,直接賦予它想要的東西,帶來的“加速收斂”、“性能提升”和“關注非邊緣(梯度)特征”結果完全在意料之中,論證了 視覺神經網絡確實需要 TGD 特征 。
2023 年是大模型元年 ,今天不再是 2022 年及以前了。在視覺大語言模型(vLLM)、大視覺模型(LVM)中,那一兩個小小的卷積核似乎看起來已經不重要了。幾百個參數能對數千億參數模型帶來多大影響喃。換言之, 視覺大模型確實還需要 TGD 特征嗎?
我認為,Deepseek 和 ChatGPT 的不同,給了我編寫本篇的信心。 有錢,有數據,有算力,有人力,大力出奇跡,可以靠堆積 GPU 數量訓練最樸素的 Transformer 得到 ChatGPT;但是, 更注重細節,會繡花針功夫,通過 工程化優化, 以更低成本帶來了 Deepseek。
所以,視覺大模型確實還需要 TGD 特征嗎?
我的答案是: 需要,但是并非找我要 。就像我才小學畢業的時候,AlexNet 已經嘗試提取 TGD 特征了。
不管黑貓白貓,捉住老鼠就是好貓。
知乎原文地址:TGD第十一篇:卷積神經網絡中的TGD特征
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. ??
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[A]. 2020. ??
Tolstikhin I O, Houlsby N, Kolesnikov A, et al. Mlp-mixer: An all-mlp architecture for vision [C/OL]//Ranzato M, Beygelzimer A, Dauphin Y N, et al. Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual. 2021: 24261-24272. ??
Oxford-102 數據集下載鏈接:https://www.robots.ox.ac.uk/~vgg/data/flowers/102/ ??
UNeXt 官方代碼倉庫 ??







)



——graph進階)
:模數轉換)



)


![[spring-cloud: 負載均衡]-源碼分析](http://pic.xiahunao.cn/[spring-cloud: 負載均衡]-源碼分析)