目錄
三劍客支持擴展正則寫法
grep命令
sed命令
sed指定行查找:
sed模糊過濾文件內容
sed之刪除:
sed之替換:
sed追加插入替換:
sed后向引用:
awk命令
awk按照行查找
awk模糊過濾文件內容
awk取列
awk指定分隔符:
awk模式+動作
awk數字比較:
? Linux三劍客是指grep、sed和awk這三個強大的文本處理工具,它們在Linux系統中被廣泛用于處理和分析文本數據。
三劍客支持擴展正則寫法
grep? -E或者egrep
sed? -r
awk?? ?默認支持擴展正則
grep命令
作用:模糊過濾文件的內容
語法:
grep? [參數]? ?'過濾的內容'? ?文件
參數:
grep? -v? :取反,匹配不包含指定內容的行
grep? -r? ?:遞歸搜索,搜索指定的目錄以及目錄下的文件
grep? -i? ?:不區分大小寫
grep? -w? :精準匹配
grep? -o? ?:顯示匹配過程
grep? -E? :支持擴展正則,相當于egrep
grep??-A n? ?:顯示過濾到內容的后 n行
grep??-B n? ?:顯示過濾到內容的前 n行
grep??-C n? ?:顯示過濾到內容的前后各n行
grep??-n? ? : 顯示過濾內容的行號
grep? ?-c? ? :統計某個單詞出現的次數
sed命令
功能:用于對文本進行流式編輯,可以進行替換、刪除、插入等操作
語法:
sed? [參數]? ?'動作'? ? 文件
參數:
sed-i修改源文件
sed-r支持擴展正則
sed-n取消默認輸出
創建環境
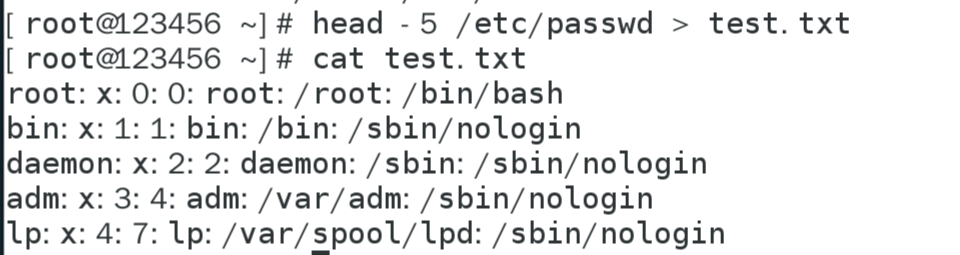
sed指定行查找:
sed? -n 只顯示被處理的行,通常配合p命令使用

過濾區間范圍:
sed? -n? '2,4p'? 文件
過濾2-4行

過濾2到最后一行
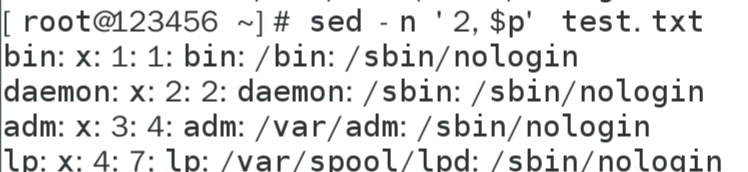
過濾屏幕上的內容

sed模糊過濾文件內容
 模糊過濾語法:
模糊過濾語法:
sed? -n? '/過濾內容/p'? 文件
sed? -n? '/^r/p'? 文件? ? ? ? ? ?:過濾r開頭的行
sed? -n? '/^[1-4]/p'? 文件? ? ? :過濾1-4開頭的行
sed? -n? '/n$/p'? 文件? ? ? ? :過濾n結尾的行
過濾區間范圍:
sed? -n? '//,//p'? ?文件
? ?sed? -n? '/8.00/,/12.00/p'? ?文件? ? ? ? ? :過濾8.00開始到12.00結束的內容
sed之刪除:
sed? '3d'? 1.txt? :刪除第三行
sed? -i?? '3d'? 1.txt? :刪除第三行(修改源文件)
sed? '2,4d'? 1.txt? :刪除二到四行
sed? '2,$d'? 1.txt? :刪除二到最后一行
sed? '/過濾的內容/d'? 1.txt? :刪除過濾的那一行
sed '/^b/d'? ?:刪除b開頭的行
-r? ?支持擴展正則:
sed? -r? '/^bin | ^lp /d'? 1.txt? ? :把bin開頭或者lp開頭的行刪除
sed? -r? '/^bin/,/^lp /d'? 1.txt? ? :把bin開頭到lp開頭的行刪除
擴展正則:
+? ? ?? ? |? ? ()? ?{}? ? \b? ? \s? ? \w
sed之替換:
sed? ?'s#? 將誰? ? #? ?替換成誰? ?#g'? ?1.txt? ?
sed? ?'s@? 將誰? ? @? ?替換成誰? ?@g'? ?1.txt? ?
sed? ?'s/? 將誰? ? /? ?替換成誰? ?/g'? ?1.txt? ?
g:整行替換 ,不加g默認值替換每行第一個單詞
sed? ?'s/root //g'? ?1.txt? ? :把所有root替換成空(刪除)
sed? ?'s/[0-9]//g'? ? 1.txt? ?:把所有數字替換成空(刪除)
邊界符:\b? 或? \<
sed? 's/\broot\b/lg/g'? ?1.txt? ?:
如果有sroot,只把root替換,結果是slg
撬棍 \
如果想把 /root/? 替換可以用撬棍或#
sed? 's/\/root\//bin/g' 1.txt
sed 's#/root/#bin#g'? 1.txt
替換指定行:
sed '3s/root/bin/' 1.txt? :替換第三行root為bin
sed '2,3s/root/bin/' 1.txt? :替換2-3行root為bin
sed? ?'/adm/s/bin/root/g'? 1.txt? ?:先過濾出adm那一行,再把那行bin替換成root
sed? ?'/adm/,/hg/s/bin/root/g'? 1.txt? ?:先過濾出adm到hg的行,再把那些行中bin替換成root
sed追加插入替換:
sed? '3i? aaa'? 1.txt? 在第三行插入aaa
sed? '3a aaa'? 1.txt? 在第三行下一行(第四行)插入aaa
sed? '3c? aaa'? 1.txt? 把第三行整行替換成aaa
sed? '3w? new'? 1.txt? 把第三行內容保存到new文件中
sed? '3,4w? new'? 1.txt? 把3-4行內容保存到new文件中
sed后向引用:
sed? -r? s#()()()#\1\2\3#g
\1對應第一個括號
\2對應第二個括號......
可以對指定內容進行修改增添
例:利用sed后向引用批量創建文件
seq 5|sed -r 's#(.*)#touch \1.txt#g'|bash
例:利用后向引用批量創建用戶
seq 5|sed -r 's#(.*)#useradd \1#g'|bash
awk命令
awk是一個強大的文本分析工具,相對于grep的查找,sed的編輯,awk在其對數據進行分析并產生報告時,顯得尤為強大。簡單的說就是把文件逐行的讀入,以空格為默認分隔符將每行切片,切開的部分在進行各種分析處理。
作用:
1.取行
2.取列
3.模糊過濾
4.數據統計 數據運算
5.支持for循環 if判斷 數組..? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 6.格式化輸出 sed后向引用
語法:
awk '模式'? file? ? ? :不加任何動作默認輸出
awk? '模式{print}'? ?file? ??
其他的命令輸出|awk '模式'
awk默認支持正則
awk按照行查找
awk? 'NR==3'? file? :輸出第三行
NR存放著文件中每行的行號
NR的表達式:
== 等于第幾行
> 大于第幾行
< 小于第幾行
>= 等于等于第幾行
<= 小于等于第幾行
!= 不等于
&& 并且? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? || 或者
awk? 'NR<3'? file? ? :輸出小于3的行
awk? 'NR>3&&NR<5'? file? ? :輸出大于3小于5的行
awk? 'NR<3|NR>5'? file? ? ?:輸出小于3或者大于5的行
awk模糊過濾文件內容
awk? '/內容/'? file
awk? '/123/,/456/'? file
awk? ?'/root/'? file? ? :匹配所有包含root的行
awk? ?'/^r/'? file? ? ?:匹配所有r開頭的行
awk? ?'/h$/'? file? ? :匹配所有h結尾的行
awk? ?'/^[1-3]/'? file? ? ?:匹配所有1-3開頭的行
awk? ?'/^2/,/^4/'? file? ? ?:匹配所有2開頭的行到4開頭的行之前的內容
awk取列
默認以空格和tab鍵為分隔符,如果文件中沒有空格和tab鍵則文件內容被當做第一列
awk? '{print $n}'? file? :取出每一行第n列的內容
awk? '{print $1}'? file? ?:取出第一列內容
awk? '{print $1,$3}'? ?file? ?:取出第一列和第三列
awk? '{print $1''----''$3}'? ?file? ?:取出1,3列,并在中間加上----
awk? '{print NF}'? ?file? ?:顯示最后一列列號
awk? '{print $NF}'? file? ? :顯示最后一列的內容
df? -h | awk '{print? $5}'? ?取出磁盤第五列信息
df? -h | awk '{print? $(NF-1)}? ?:取出磁盤倒數第二列信息'?
awk指定分隔符:
默認以tab鍵或空格分隔
指定分隔符:
awk? -F? :? 或??
awk? -F? "? :? "? ? ? ? ? ? ? : "? "中是指定分隔符
awk? -F? " :/ "? ? :指定多分隔符
awk -F: '{print $NF}' 1.txt
awk -F ":/"? '{print $2}' 2.txt
awk模式+動作
awk? ?'NR==3{print? $3}'? file? ? :取出第三行的第三列
df? -h| awk '/sda3/,/sr0/{print $3}'
df? -h|awk? 'NR >3 &&NR<5{print $4}'
awk? '$2 ~ /^o/'? file? ? :篩選輸出第二列內容以字母 o?開頭的所有行
awk數字比較:
awk? ?-F? :? '$3>90'? file? :篩選第三列內容大于90的行
awk? ?-F? :? '$3>80&&$3<90'? file? :篩選第三列內容大于80的且小于90的行
這是我的個人學習筆記,主要用于記錄自己對知識點的理解和梳理。由于目前仍在學習探索階段,內容中難免存在理解偏差或表述疏漏,懇請各位大佬不吝賜教,多提寶貴意見~ 若有不同看法,歡迎理性交流探討,感謝包容與指正!




)









)


![[echarts] 更新數據](http://pic.xiahunao.cn/[echarts] 更新數據)

)