PostgreSQL鎖詳解
————向逍xiangxiao@highgo.com
首先要講鎖的話,必須得先了解并發控制。數據庫中的對象都是共享的,如果同時間不同的用戶對同一個對象進行修改,就會出現數據不一致的情況。所以如果要實現并發訪問,就需要對這個過程加以控制。
PostgreSQL針對并發訪問控制有兩種方法,一是基于鎖的機制,也就是兩階段鎖機制(Two phase lock,2PL),二是基于時間戳的機制,即MVCC機制。而本文要提到的就是基于鎖的機制,兩階段鎖機制簡單來說就是把對鎖的操作分為兩階段:加鎖階段(增長階段)和解鎖階段(收縮階段),并且強制要求加鎖階段不能釋放鎖,在解鎖階段不能加鎖。
同時,在PostgreSQL中鎖分為一下3中層次。
-
自旋鎖(Spin Lock):是一種和硬件結合的互斥鎖。它借用了硬件提供的原子操作來對一些共享變量進行加鎖,通常適用于臨界資源比較小的情況。
-
輕量鎖(Lightweight Lock):負責保存PostgreSQL中的大量共享內存和數據結構。是一種讀寫鎖,具有共享和排他兩種模式。
-
常規鎖(Regular Lock):給數據庫對象進行加鎖,針對不同的數據庫對象,鎖的粒度也不一樣,例如分為表、頁面、元組和事務ID等等。常規鎖分為八個等級,不同的操作需要不同級別的鎖。
1、PostgreSQL自旋鎖
1.1、什么是自旋鎖
自旋鎖,顧名思義,就是不斷旋轉的鎖。如果一個進程需要訪問臨界區,則必須先獲取鎖資源,如果不能獲得鎖資源,就會一直在原地忙等,即旋轉,直到獲取鎖資源。
自旋鎖的這種忙等,也就是自旋非常浪費CPU資源,所以一般用于臨界資源非常小的情況,持有這個鎖的進程能夠很快的釋放鎖,在這個時候自旋對CPU資源的浪費小于釋放CPU資源帶來的上下文切換的資源消耗,那就是適合自旋鎖的情況。
但是需要注意的是這里的自旋鎖的實現必須依賴原子操作,也就是說這個操作可能在c語言是一條語句,但是轉換為匯編指令則可能是多條指令才能達到的效果,當進程在訪問的時候可能出現同時獲取資源的情況。比如*lock != 0這條語句轉換為匯編指令為movq -0x8(%rbq), %rax和cmpl $0x0, (%rax)這就不是原子操作。
PG采用了兩種方式去實現自旋鎖,一種是硬件提供的原子操作去實現,另一種是如果機器沒有TAS指令集,則通過自己定義的信號量PGSemaphore來仿真SpinLock,但是后者的效率不如前者,本文這里暫時只介紹通過硬件提供的原子操作實現。
1.2、自旋鎖的申請
打開spin.h文件可以發現,PG是通過宏定義HAVE_SPINLOCKS判斷機器是否由TAS指令集。
自旋鎖的申請使用的是SpinLockAcquire,但是這是一個宏定義,它最終調用的是tas函數,函數的定義如下:
static inline int
tas(volatile slock_t *lock)
{register slock_t _res = 1;asm _volatile_(" lock \n"" xchgb %0,%1 \n"
: "+q"(_res), "+m"(*lock)
: /* no inputs */
: "memory", "cc");return (int) _res;
}這里舉的例子是x86架構下的TAS實現方法,對于不同的架構,PostgreSQL提供不同的方法實現,具體可以查看src/include/storage/s_lock.h這個文件下的內容。
1.3、自旋鎖的釋放
自旋鎖的釋放就是將這里的*lock的值置為1,具體代碼實現如下:
#define S_UNLOCK(lock) \do { asm _volatile_("" : : : "memory"); *(lock) = 0; } while (0)2、PostgreSQL輕量鎖
2.1、什么是輕量鎖
自旋鎖是一個互斥鎖,對于臨界資源比較小的情況,能保證多個進程對臨界區的訪問是互斥的,但是在數據庫的實際使用過程中,會出現多個進程同時讀取共享內存,在這種情況下大量的讀操作是不沖突的,因為他們并不會修改數據,所以就需要輕量鎖來解決這個問題。
輕量級鎖有兩種模式,共享和排他,在讀操作的時候就加上共享鎖,這樣保證在其他進程讀的時候不沖突,而又杜絕了其他寫操作。在寫操作的時候就加上排他鎖,這樣保證在寫操作執行的過程中,其他進程既不可以讀也不可以寫。
輕量級鎖的相容性矩陣如下:
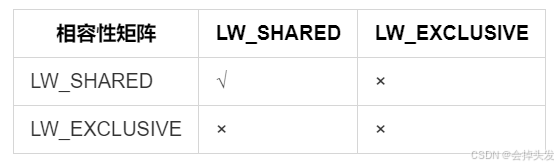
輕量級鎖類型定義在lwlocknames.h中,這個文件是在編譯的時候由lwlocknames.txt生成的,在這里面定義了PG的輕量級鎖的類型。
#define ShmemIndexLock (&MainLWLockArray[1].lock)
#define OidGenLock (&MainLWLockArray[2].lock)
#define XidGenLock (&MainLWLockArray[3].lock)
...
#define NotifyQueueTailLock (&MainLWLockArray[47].lock)#define NUM_INDIVIDUAL_LWLOCKS 48從這個宏定義可以看出,在這個文件中所有的輕量級鎖的類型都存儲在MainLWLockArray里面。在上面這種為individual lwlock,每個individual lwlock都有自己固定要保護的對象。individual lwlock的使用方法如下:
LWLockAcquire(ShmemIndexLock, LW_EXCLUSIVE);
//這里對需要保護的變量進行寫操作
LWLockRelease(ShmemIndexLock);在individual lwlock中,每個lwlock都對應一個tranche id,它具有全局唯一性,在MainLWLockArray中前NUM_INDIVIDUAL_LWLOCKS - 1都是individual lwlock。
除了individual lwlock之外,還有Builtin tranche,每一個builtin tranche可能對應多個lwlock,他代表的是一組lwlocks,這組lwlocks雖然各自封鎖各自的內容,但是他們的功能相同。builtin tranche包含如下類型,類型定義在lwlock.h文件的BuiltinTrancheIds枚舉類型中。
typedef enum BuiltinTrancheIds
{LWTRANCHE_XACT_BUFFER = NUM_INDIVIDUAL_LWLOCKS,LWTRANCHE_COMMITTS_BUFFER,LWTRANCHE_SUBTRANS_BUFFER,LWTRANCHE_MULTIXACTOFFSET_BUFFER,
...
}從這里可以看出來,對于Builtin tranche,他的計數是從NUM_INDIVIDUAL_LWLOCKS開始的,也就是individual lwlock的最后。
這些Builtin Tranche對應的鎖一部分保存在MainLWLockArray中,另一半部分被保存在使用他們的結構體中,如下所示:
//存儲在MainLWLockArray中
/* Register named extension LWLock tranches in the current process. */
for (int i = 0; i < NamedLWLockTrancheRequests; i++)LWLockRegisterTranche(NamedLWLockTrancheArray[i].trancheId,NamedLWLockTrancheArray[i].trancheName);
//存儲在自己的結構體中 xlog.c:4465 (pg15.8)
//這里初始化了NUM_XLOGINSERT_LOCKS個輕量鎖
//這些輕量鎖的tranche id都是lwtranche_wal_insert
//這些輕量鎖沒有保存在MainLWLockArray里面
for (i = 0; i < NUM_XLOGINSERT_LOCKS; i++)
{LWLockInitialize(&WALInsertLocks[i].l.lock, LWTRANCHE_WAL_INSERT);WALInsertLocks[i].l.insertingAt = InvalidXLogRecPtr;WALInsertLocks[i].l.lastImportantAt = InvalidXLogRecPtr;
}但是無論是individual lwlocks還是builtin tranches,他們都被保存在共享內存中,只是保存的方式不相同而已。
這里先給出輕量級鎖的結構體定義:
typedef struct LWLock{uint16 tranche; /* tranche ID *///這是一個原子變量,用于保存輕量級鎖的狀態pg_atomic_uint32 state; /* state of exclusive/nonexclusive lockers *///輕量級鎖的等待隊列proclist_head waiters; /* list of waiting PGPROCs */#ifdef LOCK_DEBUG pg_atomic_uint32 nwaiters; /* number of waiters 等待者的數量 *///最后一次獲取排他鎖的進程struct PGPROC *owner; /* last exclusive owner of the lock */#endif} LWLock;在早期輕量級鎖是通過自旋鎖實現的,但是隨著性能的提升,輕量級鎖的實現開始借助原子操作來實現,pg_atomic_uint32 state;關注這個狀態的變量,這是一個32位的無符號整型,其中他的低24位作為存儲共享鎖的計數器,因此一個輕量級鎖最多擁有2^24個共享鎖持有者。有1位作為排他鎖的標記,因為同一時刻最多只能擁有一個持鎖者。

2.2、輕量鎖的申請
接下來介紹輕量鎖的申請,主要分為兩種,一是申請共享鎖,二是申請排他鎖。
(1)當申請一個共享鎖的時候:
a如果里面是共享鎖或者無鎖 —-> 直接獲取
b如果里面排他鎖 —-> 進入等待隊列
(2)當申請一個排他鎖的時候:
a如果里面是共享鎖或者排他鎖 —-> 進入等待隊列
b如果里面沒有鎖 —-> 直接獲取
在比較極端的情況下,如果申請一個排他鎖,然后目前持有的是共享鎖,則進入等待隊列,在這個過程中不斷的申請共享鎖,那么這個排他鎖將持續等待,出現排他鎖饑餓的情況。
具體申請輕量鎖的詳細細節如下:
獲取鎖的調用LWLockAcquire方法,釋放調用LWLockRelease方法。 獲取的步驟大致為:
-
判斷鎖的持有數量是否超出能記錄的持有列表大小。
if (num_held_lwlocks >= MAX_SIMUL_LWLOCKS)elog(ERROR, "too many LWLocks taken");-
嘗試獲取,成功則返回。
mustwait = LWLockAttemptLock(lock, mode);if (!mustwait){LOG_LWDEBUG("LWLockAcquire", lock, "immediately acquired lock");break; /* got the lock 獲取成功則返回 */}-
失敗則進入等待隊列。
/* add to the queue */
LWLockQueueSelf(lock, mode);-
再次嘗試獲取,成功則出隊列,并返回。
mustwait = LWLockAttemptLock(lock, mode);/* ok, grabbed the lock the second time round, need to undoqueueing */
if (!mustwait){LOG_LWDEBUG("LWLockAcquire", lock, "acquired, undoing queue");LWLockDequeueSelf(lock);//從隊列中出來,獲取成功,直接返回break;}-
失敗則報告等待事件開始,并持續等待被喚醒,然后報告等待事件結束。
LWLockReportWaitStart(lock);if (TRACE_POSTGRESQL_LWLOCK_WAIT_START_ENABLED())TRACE_POSTGRESQL_LWLOCK_WAIT_START(T_NAME(lock), mode);for (;;){PGSemaphoreLock(proc->sem);if (proc->lwWaiting == LW_WS_NOT_WAITING)break;extraWaits++;}/* Retrying, allow LWLockRelease to release waiters again. 使用原子操作獲取更新鎖的狀態 */pg_atomic_fetch_or_u32(&lock->state, LW_FLAG_RELEASE_OK);if (TRACE_POSTGRESQL_LWLOCK_WAIT_DONE_ENABLED())TRACE_POSTGRESQL_LWLOCK_WAIT_DONE(T_NAME(lock), mode);LWLockReportWaitEnd();-
然后持續再次嘗試獲取鎖,回到1,直到獲取成功。
-
獲取成功之后將這個鎖增加到held_lwlocks中去。
held_lwlocks[num_held_lwlocks].lock = lock;
held_lwlocks[num_held_lwlocks++].mode = mode;2.3、輕量鎖的釋放
釋放輕量級鎖的步驟大致如下:
-
將這個鎖在held_lwlocks中定位,并將數組該位置之后的鎖前移。
for (i = num_held_lwlocks; --i >= 0;)if (lock == held_lwlocks[i].lock)break;if (i < 0)elog(ERROR, "lock %s is not held", T_NAME(lock));mode = held_lwlocks[i].mode;num_held_lwlocks--;//釋放之后數組前移for (; i < num_held_lwlocks; i++)held_lwlocks[i] = held_lwlocks[i + 1];PRINT_LWDEBUG("LWLockRelease", lock, mode);-
釋放鎖。
if (mode == LW_EXCLUSIVE)oldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_EXCLUSIVE);
elseoldstate = pg_atomic_sub_fetch_u32(&lock->state, LW_VAL_SHARED);-
獲取修改前的狀態,判斷是否需要喚醒等待隊列的進程。
//如果鎖未被持有并且等待隊列為空則不需要喚醒
if ((oldstate & (LW_FLAG_HAS_WAITERS | LW_FLAG_RELEASE_OK)) ==(LW_FLAG_HAS_WAITERS | LW_FLAG_RELEASE_OK) &&(oldstate & LW_LOCK_MASK) == 0)check_waiters = true;
elsecheck_waiters = false;-
如果需要喚醒,則喚醒。
if (check_waiters){/* XXX: remove before commit? */LOG_LWDEBUG("LWLockRelease", lock, "releasing waiters");LWLockWakeup(lock);}2.4、Extension拓展輕量級鎖
在插件中拓展輕量級鎖有兩種方法。
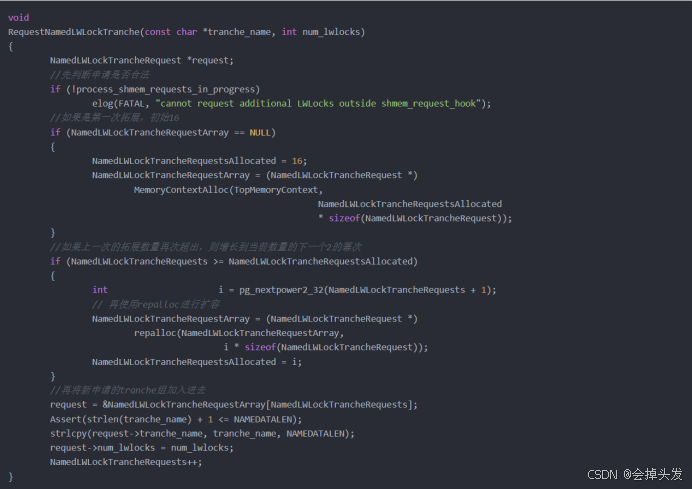
方法一、通過RequestNamedLWLockTranche函數和GetNamedLWLockTranche函數來實現。其中RequestNamedLWLockTranche函數負責注冊Tranche的名字以及自己所需要的輕量級鎖的數量,GetNamedLWLockTranche負責根據Tranche Name來獲得對應的鎖。每個tranche都有自己唯一的id,全局唯一,tranche id和tranche name一一對應。
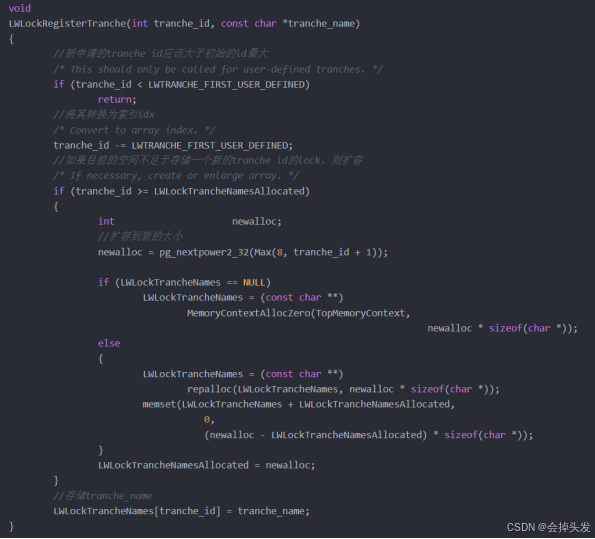
方法二、通過LWLockNewTrancheId函數獲取新的Tranche ID,然后將Tranche ID和Tranche Name通過LWLockRegisterTranche函數建立聯系,然后再由LWLockInitialize函數進行初始化。
3、PostgreSQL常規鎖
常規鎖是用于給數據庫對象,例如表,頁面,元組等加鎖的事務鎖,它也是一種讀寫鎖,但是和LWLock不同的在于它將鎖等級分為了八個等級,所以他的相容性矩陣就比較麻煩。后續也會接著介紹是怎么演變到八個等級鎖來的。
3.1、常規鎖的鎖模式
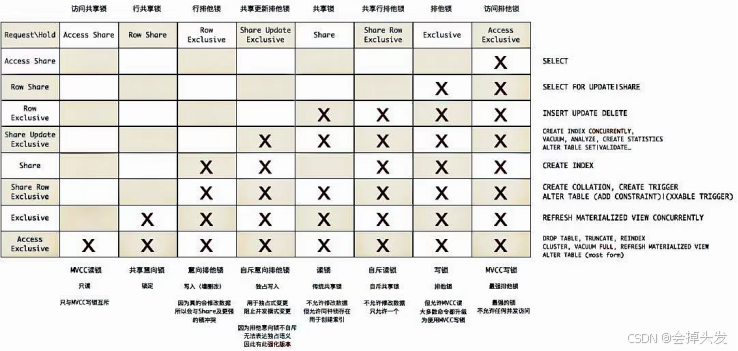
常規鎖的鎖模式分為八種,也就是八級鎖,前三種鎖稱為弱鎖,第四級既不是弱鎖也不是強鎖,后面四級為強鎖。具體劃分如下圖所示:

由最開始的輕量鎖的兩種鎖模式,共享和排他,到現在八級鎖,各種鎖之間的相容度也是隨之變化的,常規鎖的弱鎖之間是相容的,強鎖之前是不相容的,第四級鎖于弱鎖相容于強鎖不相容,且于自己不相容。具體各級鎖之前的沖突關系由下圖的沖突矩陣表示:
3.2、常規鎖的演變
最開始只有兩種鎖,就是讀鎖和寫鎖,即Share和Exclusive。
然后PG引入了多版本控制,多版本控制要求讀寫相互不阻塞,所以又引入了AccessShare和AccessExclusive鎖,引入MVCC之后insert\update\delete操作仍然使用原來的Exclusive鎖,但是普通的select操作則使用AccessShare鎖,這樣子就和原來的Exclusive不沖突了,這個時候讀寫之間互不阻塞,而之前的Share鎖的主要應用場景為創建索引,而AccessExclusive鎖就用于除了原來的增刪改之外的其他的排他性變更(drop/truncate/reindex/vacuum full),但是寫和寫之間還是會有沖突,根據相容性矩陣可以看出在并發寫入使用Exclusive鎖的時候,這是個表級鎖,粒度太大了,會影響并發操作。
所以就引入了意向鎖,即RowShare和RowExclusive,意向鎖之間都不沖突。 意向讀與讀鎖兼容,但是與寫鎖沖突,因為在寫的時候去讀是徒勞的,用于select for update/share操作 意向寫他與讀鎖和寫鎖都沖突,兩者都阻止并發修改,用于insert,update,delete。
意向鎖用于協調表鎖和行鎖之間的關系,比如說當某個進程想要修改某一行的時候,首先會在這個表上面加一把意向寫鎖,表示自己會在某一行上進行寫操作,然后再在某一行上面增加寫鎖。舉個例子,假設不存在意向鎖。假設進程A獲取了表上某行的行鎖,持有行上的排他鎖意味著進程A可以對這一行執行寫入;同時因為不存在意向鎖,進程B很順利地獲取了該表上的表級排他鎖,這意味著進程B可以對整個表,包括A鎖定對那一行進行修改,這就違背了常識邏輯。因此A需要在獲取行鎖前先獲取表上的意向鎖,這樣后來的B就意識到自己無法獲取整個表上的排他鎖了(但B依然可以加一個意向鎖,獲取其他行上的行鎖)。
RowShare就是行級共享鎖對應的表級意向鎖(SELECT FOR SHARE|UPDATE命令獲取),而RowExclusive(INSERT|UPDATE|DELETE獲取)則是行級排他鎖對應的表級意向鎖。
這個時候由有六把鎖了,但是后面為什么又引入了另外兩把鎖,即ShareUpdateExclusiveLock 和ShareRowExclusiveLock這兩把鎖。首先ShareUpdateExclusiveLock 鎖可以讓 VACUUM 操作不應該阻止數據寫入,但是又不能出現在一張表并發執行VACUUM操作,所以他又必須自斥。ShareRowExclusiveLock這種鎖級別是介于 SHARE 鎖和 EXCLUSIVE 鎖之間的一種平衡選擇,它比 SHARE 鎖更嚴格,因為它阻止了更新操作,但比 EXCLUSIVE 鎖更寬松,因為它允許并發讀取,比如說在創建觸發器的時候,應該阻止數據寫入,因為這個時候無法判斷是否需要觸發觸發器,但是又必須防止其他進程修改觸發器,所以他又需要互斥。所以又引入了兩把自斥鎖。
3.3、常規鎖的實現
3.3.1、常規鎖的數據結構
在數據庫啟動的階段,PostgreSQL通過InitLocks函數來初始化保存鎖對象的共享內存空間,在共享內存中,有兩個鎖表用于保存鎖對象,LockMethodLockHash主鎖表和LockMethodProcLockHash進程鎖表。
【共享內存】主鎖表:LockMethodLockHash(存儲所有鎖對象)
【共享內存】鎖進程關系表:LockMethodProcLockHash(查詢當前進程阻塞了哪些進程,死鎖檢測)
【本地內存】本地鎖表:對重復申請的鎖計數,避免頻繁訪問(本地快速加鎖,鎖緩存)
【共享內存】本地弱鎖fastpath(需要共享內存中查詢是否有強鎖FastPathStrongRelationLockData)
首先看一下主鎖表在內存中的存儲結構,具體如下:
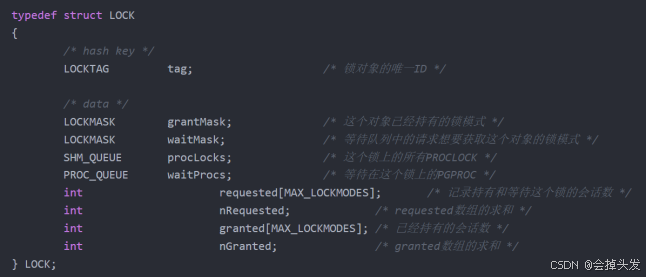
然后是進程鎖表,它用于保存當前進程的事務鎖狀態,保存的是PROCLOCK結構體,主要是為了建立鎖與申請鎖的會話之間的關系:
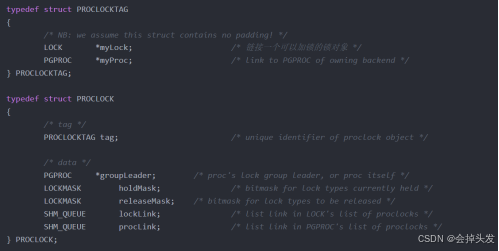
除此之外還有個結構,那就是本地鎖表LocalLock。
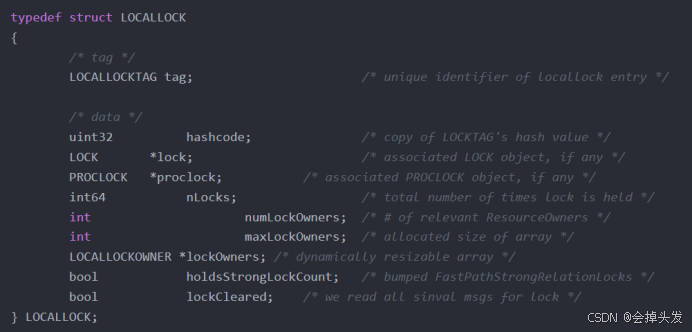
最后就是快速路徑(Fast Path),這個快速路徑分為強鎖和弱鎖,弱鎖的訪問保存到本進程,避免頻繁的訪問主鎖表和進程鎖表。 而對于強鎖是存儲在共享內存中的,這里的count數量是2(10)是1024,具體如下:
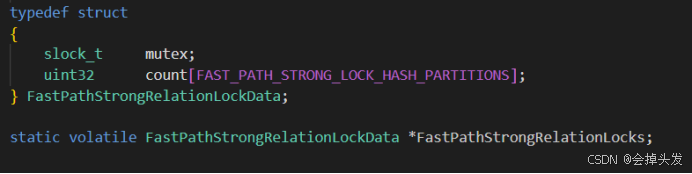
然后對于弱鎖,是存儲在進程的變量中的,即PGPROC結構體的fpLockBits和fpRelId。存儲的結構也就是存儲在fpLockBits這個64位的位圖中的,每三位一組,標識八級鎖對應的鎖級別,而根據fpRelId的大小可以看出來,其實最多只能存儲了16個鎖,fpRelId顧名思義就是表的oid,也就是鎖對象即鎖表的oid。
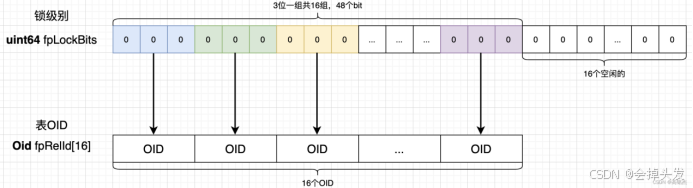
3.3.2、常規鎖的申請
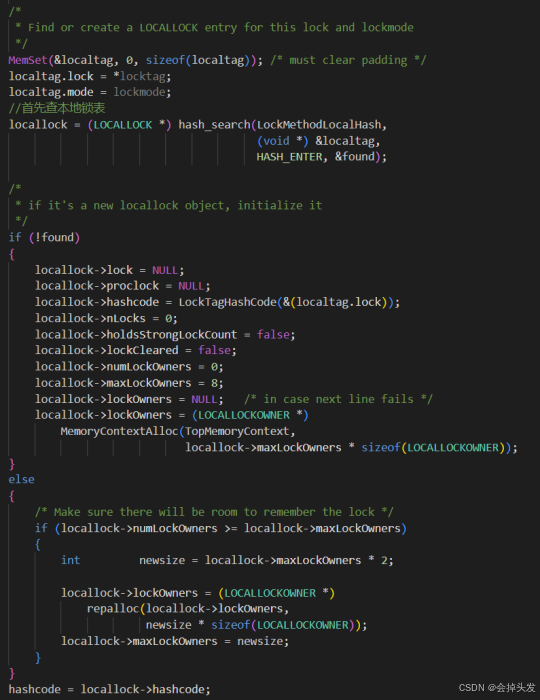
加鎖的API是LockAcquire,但是在里面還是調用的是LockAcquireExtended,這個函數接受四個參數:分別是鎖tag,申請鎖模式,會話鎖或事務鎖,是否等待。詳細的加鎖流程如下:
(1)查找本地鎖表
在Acquire Lock的時候首先查找的是本地鎖表LocalLock,通過hash_search函數搜索,locktag作為查找的key值,返回一個LOCALLOCK*。如果在本地鎖表沒有找到的話就構造一條放入本地鎖表。
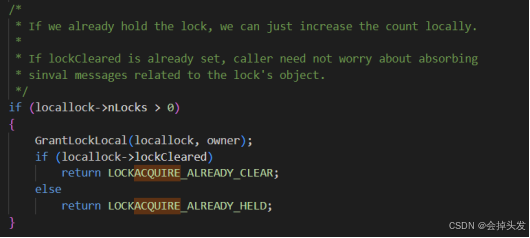
如果已經持有鎖的話直接將持有的數量加1。
(2)查找fast path,判斷弱鎖。
在查找本地鎖表之后,如果本地鎖表內沒有,則開始查找fast path,首先是通過EligibleForRelationFastPath宏定義進行判斷:要求必須是非咨詢鎖 locktag_lockmethodid == DEFAULT_LOCKMETHOD,要求鎖的對象為表 locktag_type == LOCKTAG_RELATION,要求必須是當前數據庫的鎖 locktag_field1 == MyDatabaseId,要求鎖的級別必須是弱鎖 (mode) < ShareUpdateExclusiveLock。
并且還有個條件需要判斷的是,當前fastpath里面已經使用的數量是否超過了最大數。FastPathLocalUseCount < FP_LOCK_SLOTS_PER_BACKEND
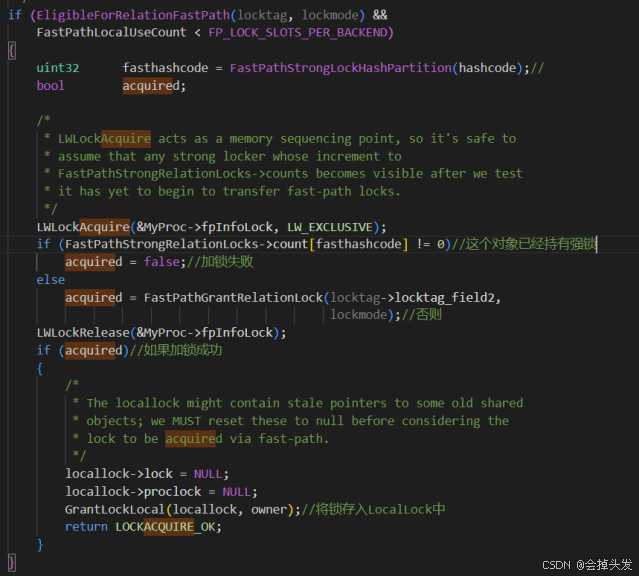
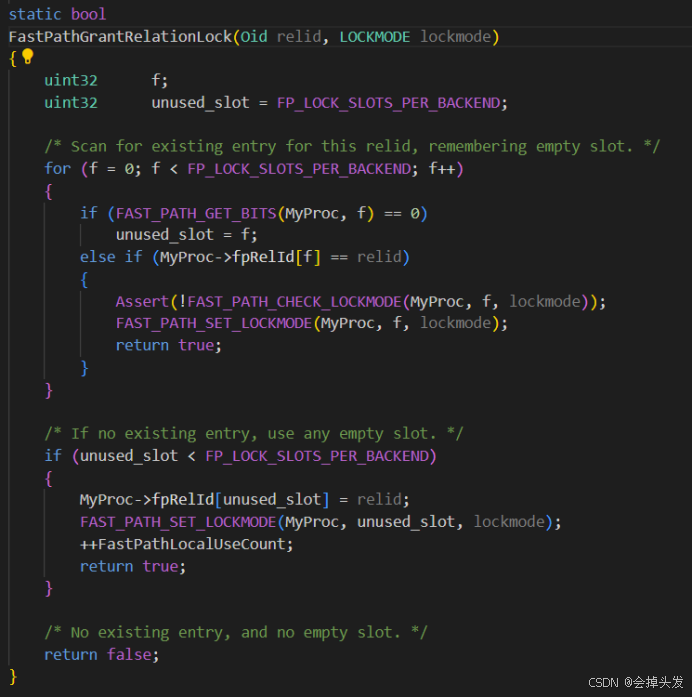
總的流程大致為用tag算的hashcode在%1024,落到1024數組FastPathStrongRelationLocks->count的某個位置上。這個位置上存儲的是這個對象所持有的強鎖,有強鎖的話則加鎖失敗,否則使用FastPathGrantRelationLock函數加鎖,這里傳進去的參數locktag->locktag_field2是表的id,還有鎖的模式。
FastPathGrantRelationLock邏輯:
-
3個bit一組按順序查位圖是不是空的,是空的就記錄下來位置,不是空的就看下oid里面記的是不是需要的,如果正好Oid也是需要的,把當前請求鎖模式或進去就可以返回了。
-
如果查了一遍位圖,所有Oid都不是需要的,那就找一個空的位置,把鎖級別記錄到位圖,OID記錄到數組,然后返回。
-
如果查了一遍位圖,沒有一個空余位置,就返回false了。
-
如果申請的是強鎖的情況。
強鎖的判斷和前面弱鎖的判斷比較相似,也是通過一個宏定義去判斷的,這里給出宏定義如下:
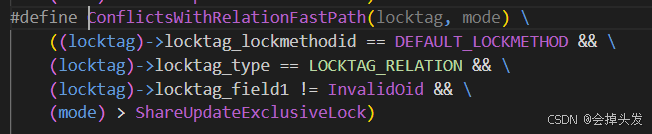
如果判斷出來是強鎖的話,那就開始處理強鎖,走強鎖的邏輯。首先就是通過BeginStrongLockAcquire函數去申請強鎖,之后就將強鎖對應的加鎖對象的OID鎖持有的弱鎖,存儲在fastpath中的,如果有的話就移動到主鎖表和進程鎖表中去,用于后期的鎖沖突判斷和死鎖檢測。
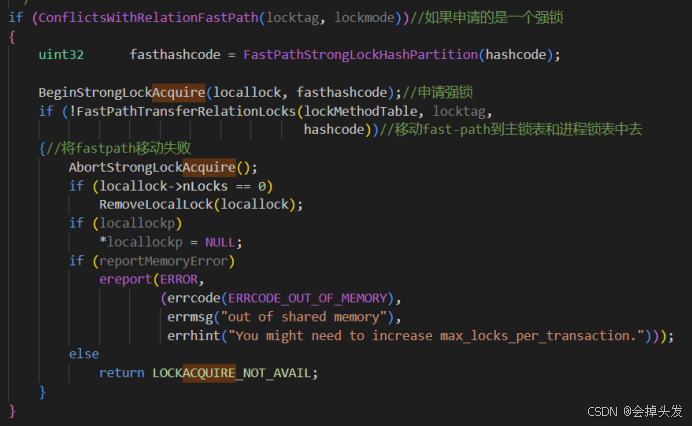
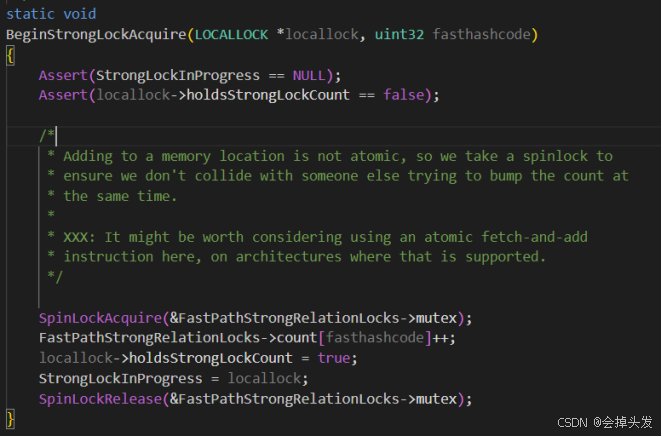
這里給出BeginStrongLockAcquire的實現邏輯:
-
共享內存強鎖表對應位置++,FastPathStrongRelationLocks->count[fasthashcode]++;(重要!相當于禁用了后面這個對象后來的所有fastpath)
-
本地鎖記錄強鎖存在locallock->holdsStrongLockCount = true
-
全局記錄本地強鎖StrongLockInProgress = locallock
然后給出將fastpath中對于弱鎖轉移到主鎖表和進程鎖表中去的代碼邏輯:
-
輪詢PGPROC,用表oid在fpRelId16數組中查詢,如果找到了,用找到的鎖級別去主鎖表中加鎖。
-
清理fastpath對應的位置。
-
完成轉換:PGPROC記錄的fastpath鎖換成主鎖表的鎖,便于死鎖檢查。
-
注意這里只是把fastpath中已經存在弱鎖換到主鎖表了,并沒有給當前請求LockAcquire的對象加鎖。
這一塊比較復雜,給出完整代碼注釋如下:
static bool
FastPathTransferRelationLocks(LockMethod lockMethodTable, const LOCKTAG *locktag,uint32 hashcode)
{LWLock *partitionLock = LockHashPartitionLock(hashcode);Oid relid = locktag->locktag_field2;uint32 i;/** Every PGPROC that can potentially hold a fast-path lock is present in* ProcGlobal->allProcs. Prepared transactions are not, but any* outstanding fast-path locks held by prepared transactions are* transferred to the main lock table.* 每個可能持有快速路徑鎖的PGPROC都存在于ProcGlobal->allProcs中。* 已準備事務不是,但由已準備事務持有的任何未完成的快速路徑鎖都會轉移到主鎖表。*/for (i = 0; i < ProcGlobal->allProcCount; i++)//遍歷所有進程{PGPROC *proc = &ProcGlobal->allProcs[i];uint32 f;LWLockAcquire(&proc->fpInfoLock, LW_EXCLUSIVE);/** If the target backend isn't referencing the same database as the* lock, then we needn't examine the individual relation IDs at all;* none of them can be relevant.** proc->databaseId is set at backend startup time and never changes* thereafter, so it might be safe to perform this test before* acquiring &proc->fpInfoLock. In particular, it's certainly safe to* assume that if the target backend holds any fast-path locks, it* must have performed a memory-fencing operation (in particular, an* LWLock acquisition) since setting proc->databaseId. However, it's* less clear that our backend is certain to have performed a memory* fencing operation since the other backend set proc->databaseId. So* for now, we test it after acquiring the LWLock just to be safe.* 如果目標后端沒有引用與鎖相同的數據庫,那么我們根本不需要檢查各個關系id;沒有一個是相關的。* proc->databaseId在后端啟動時設置,此后永遠不會改變,因此在獲取&proc->fpInfoLock之前執行此測試可能是安全的。* 特別是,可以肯定地假設,如果目標后端持有任何快速路徑鎖,那么它在設置proc->databaseId之后一定執行了內存隔離操作(特別是LWLock獲取)。* 然而,由于另一個后端設置了proc->databaseId,我們的后端是否確定執行了內存隔離操作就不太清楚了。* 所以現在,為了安全起見,我們在獲得LWLock后進行測試。*/if (proc->databaseId != locktag->locktag_field1)//如果進程數據庫id和當前數據庫id不一致則跳過{LWLockRelease(&proc->fpInfoLock);continue;}for (f = 0; f < FP_LOCK_SLOTS_PER_BACKEND; f++)//如果是當前數據庫id,則開始遍歷16個槽{uint32 lockmode;/* Look for an allocated slot matching the given relid. */if (relid != proc->fpRelId[f] || FAST_PATH_GET_BITS(proc, f) == 0)//表的id不正確或者未加鎖則跳過continue;/* Find or create lock object. 循環檢查三種弱鎖*/LWLockAcquire(partitionLock, LW_EXCLUSIVE);for (lockmode = FAST_PATH_LOCKNUMBER_OFFSET;lockmode < FAST_PATH_LOCKNUMBER_OFFSET + FAST_PATH_BITS_PER_SLOT;++lockmode){PROCLOCK *proclock;if (!FAST_PATH_CHECK_LOCKMODE(proc, f, lockmode))//檢查某個進程是否持有某種鎖,檢查是否有這個是否持有弱鎖continue;/* 如果持有弱鎖,則將這個弱鎖移動到主鎖表和進程鎖表中去 */proclock = SetupLockInTable(lockMethodTable, proc, locktag,hashcode, lockmode);if (!proclock)//如果失敗{LWLockRelease(partitionLock);LWLockRelease(&proc->fpInfoLock);return false;}GrantLock(proclock->tag.myLock, proclock, lockmode);//增加本地鎖表計數FAST_PATH_CLEAR_LOCKMODE(proc, f, lockmode);//清理fastpath,也就是pgproc里面}LWLockRelease(partitionLock);/* No need to examine remaining slots. */break;}LWLockRelease(&proc->fpInfoLock);}return true;
}如果前面都成功了,就可以申請強鎖了。
![]()
如果申請失敗則報錯,但是如果申請成功就可以開始檢測申請鎖與等待隊列中的鎖是否沖突,比如說這里的lockmode是1,那么對應的lockMethodTable->conflicTab[lockmode]=10000000,表示1級鎖與8級鎖沖突。如果等待隊列中不沖突的話,就要去檢查是否與當前的其他事務所持有的鎖模式是否存在沖突,這里是由LockCheckConflicts函數去實現的。
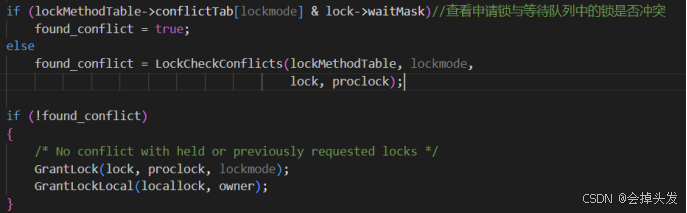
這里對LockCheckConflicts函數進行解釋:
首先先直接拿出與當前鎖模式沖突的鎖模式與當前對象已經持有的鎖模式進行比較,如果沒有沖突則直接獲取。

如果有沖突,則需要更進一步的檢測,統計持有的模式中,沖突的數量,并且還得減去當前會話持有的數量,自己和自己不沖突。
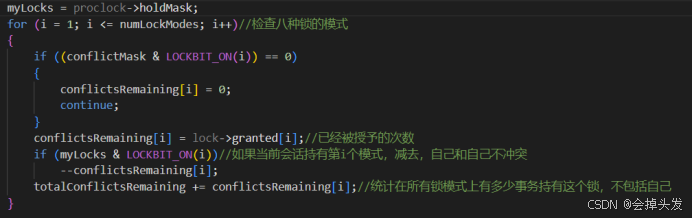
然后再檢查一遍,是否由沖突,沒有沖突則直接獲取。
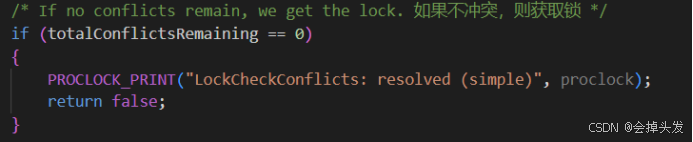
然后如果還是有沖突的話則需要再檢測是否可能是組鎖沖突,也就是可能這里面存在并行事務,同屬一個鎖組,不算沖突。
首先檢查一下是否是單進程事務,不存在組鎖,又存在沖突那么一定是存在沖突的。

如果是并行事務,且是針對表進行拓展操作,即鎖的LOCKTAG是LOCKTAG_RELATION_EXTEND則為沖突,因為如果組鎖的時候,一個進程要去拓展表的話,其他進程不能去拓展。
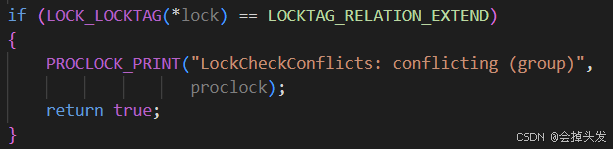
然后就是去檢測并行操作, 如果其他進程與當前進程具有相同的groupleader,則不沖突,需要減去沖突計數。
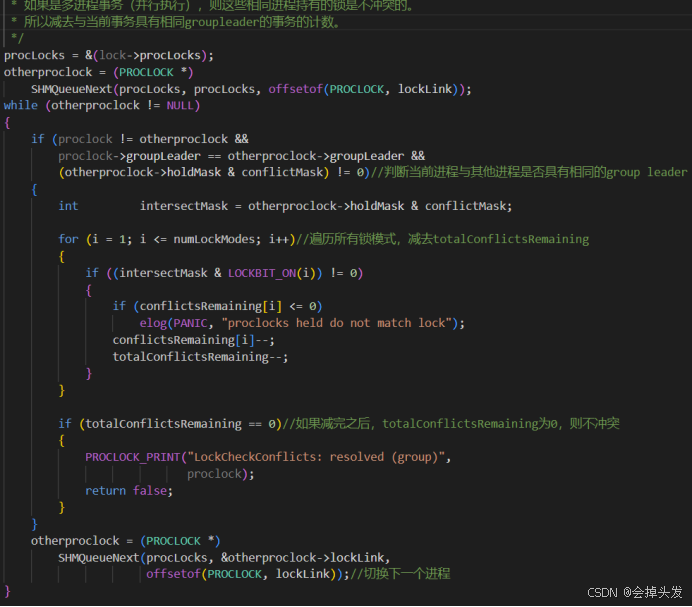
否則的話就意味著不能馬上拿到鎖,如果在申請的時候指明不等待的話,這個時候直接刪除前面的操作,返回失敗,如果指明等待的話則進入等待函數WaitOnLock(locallock, owner);。
在插入等待隊列的時候需要注意注意一點,通常來說,如當前事務應該插入等待隊列的末尾,但是如果本事務A除了當前申請的鎖模式之外,已經持有了這個對象的其他鎖模式,而且等待隊列中某個事務B所等待的鎖模式與當前事務A所持有的鎖模式沖突,這個時候如果把事務A插入到這個等待者B的后面,則容易出現死鎖,所以考慮將事務A插入到等待者的前面。
插入到等待隊列之后,就需要進行死鎖檢測,這里給出調用邏輯:waitOnLock->ProcSleep->CheckDeadLock,詳細的死鎖檢測在后面介紹。
3.3.3、常規鎖的釋放
相較于常規鎖的申請,常規鎖的釋放就比較簡單了。
-
從LockMethodLocalHash 查找LOCALLOCK,在它的owner數組里找到與當前進程對應的元素,解除LOCALLOCK與ResourceOwner之間的關聯,并減小相應計數值。
-
將LOCALLOCK的加鎖次數(nLocks)減1,如果減為0了,表示當前進程不再持有鎖,則后續有兩種解鎖途徑,分別是快速鎖和主鎖表。
-
對于快速鎖,調用FastPathUnGrantRelationLock清除快速鎖的加鎖標記。如果解鎖成功即可返回。
-
如果沒找到快速鎖,且LOCALLOCK.lock為空,說明被轉移到了主鎖表里(在加鎖邏輯中,當申請快速鎖成功時,會把LOCALLOCK.lock置空)。
-
查找主鎖表LockMethodLockHash 以及 LockMethodProcLockHash,如果沒有找到,則blog-error。找到了 調用UnGrantLock更新LOCK和PROCLOCK信息。
-
調用CleanUpLock:要么刪除主表項,要么調用ProcLockWakeup()喚醒等待者,這里會按照 WFG 中構建的 soft-edge 以及 hard-edge 依賴關系進行喚醒。
3.5、死鎖檢測
在postgresql數據庫中,對申請事務鎖的順序沒有嚴格的限制,在申請鎖時也沒有嚴格的檢查,因此不可避免的會發生死鎖。PG使用“樂觀鎖”來檢測死鎖,即鎖等待的時間超過了時間deadlock_timeout(postgresql.conf中配置,deadlock_timeout = 1s),那么開始進行死鎖檢測,如果沒有死鎖繼續等待。
如果有一個事務A已經持有某個鎖,這個時候事務B來申請這個鎖,但是和事務A持有的鎖沖突,需要等待A釋放之后才能獲取,這個時候就產生了等待,可以作為B->A,表示B等待事務A。而在數據庫內核中事務是有限的,每個事務都在等待另一個事務,在這個等待的集合中就會出現環,也就是死鎖,所以死鎖的檢測也就變成了環的檢測。
還有另一個概念就是實邊和虛邊,其中實邊定義為如果A持有某個對象的共享或者排他鎖,這個時候B申請排他鎖,就需要進入等待過程,即B——>A。而需邊則為,如果事務A持有共享鎖,B申請排他鎖,然后進入等待隊列,這個時候事務C又來申請共享鎖,但是雖然C與A不沖突,但是和等待隊列中B沖突,也需要進入等待過程。這個時候就產生了事務C等待事務B,即C--------->B。
所以如果產生死鎖即檢測到環的存在,如果這個環上全部都是實邊,則必須結束掉一個事務來接觸這個環,如果存在虛邊,則可以通過調整等待隊列實現解決死鎖,即可以調整等待隊列中C到B的前面,這個時候C和A不沖突,即可獲取鎖。
3.5.1、死鎖檢測中的數據結構
首先是死鎖的狀態定義:

其他方面的話用PGPROC作為節點,EDGE作為邊。

如果在換種存在虛邊,則調整等待隊列消除環,新的等待隊列保存在waitOrders數組中,每個數組都是一個等待隊列。
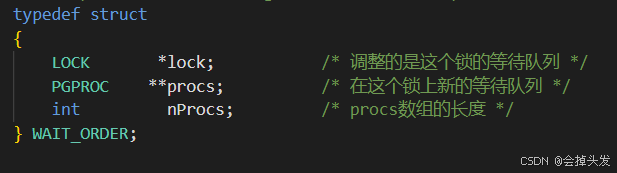
而在這個過程中,可以被調整的虛邊記錄在possibleConstraints中,每次都是從possibleConstraints找到一個虛邊進行探索,而被探索的虛邊則保存在curConstrains中,這兩個數組的長度必須足夠大,curConstrains的長度為MaxBackends,被調整的虛邊數量不能超過這個值。
3.5.2、死鎖的檢測過程
首先進入到的是CheckDeadLock函數,死鎖檢測的過程是互斥的,就是說在死鎖檢測開始的時候,鎖表就需要被保護起來,防止被其他人修改。

然后如果只有當前對話的話,就不會構成死鎖。
否則就開始檢測死鎖,即檢測是否有環的存在。進入DeadLockCheck函數,在從中進入DeadLockCheckRecurse進行檢測,接下來詳解該函數:
進入函數之后首先進行是否有環的判斷,通過TestConfiguration進行判斷,該函數沒有環則返回0,有實環則返回-1,其他情況則返回大于0的數。

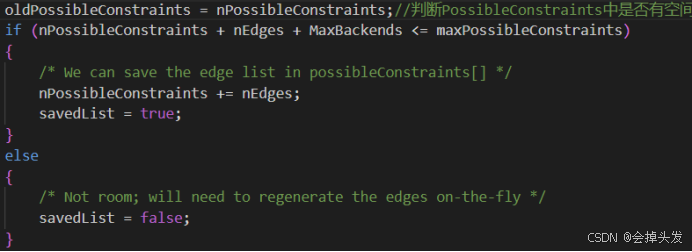
然后檢測對虛邊的調整是否達到了最大值,如果達到了最大值,則認為產生了死鎖。
![]()
而如果還有檢測的空間,則將檢測產生的虛邊加入到考慮的范圍。
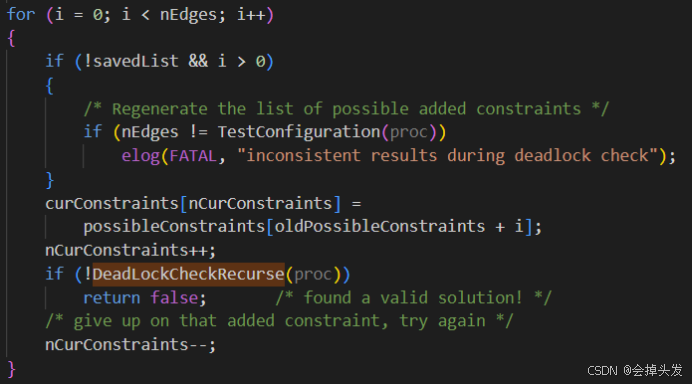
然后遞歸調用DeadLockCheckRecurse函數,判斷是否有死鎖。
在上面的TestConfiguration函數的作用就是調用FindLockCycle去檢測是否有環。

并調用ExpandConstraints函數嘗試對等待隊列進行重排來嘗試解除虛邊死鎖,如果存在環的話又將虛邊保存到possibleConstraints數組中。
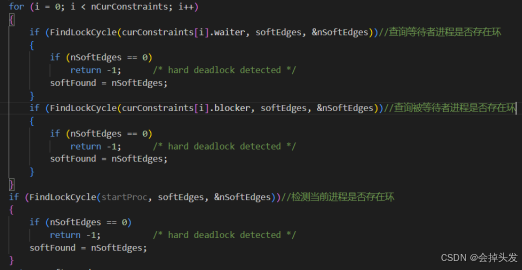
再接著對這里檢測死鎖所用到的函數FindLockCycle進行詳解,但是其實際調用的又是FindLockCycleRecurse函數,接下來對其進行詳解:
遞歸查找是否存在環,FindLockCycleRecurse函數查找的原理就是:在查找環時,先檢查待測進程是否在visitedProcs數組中出現過,如果沒出現過,就將待測進程存入到visitedProcs數組中,如果出現過,而且是在等待隊列的起始處,則表明出現了死鎖的環,返回死鎖信息。
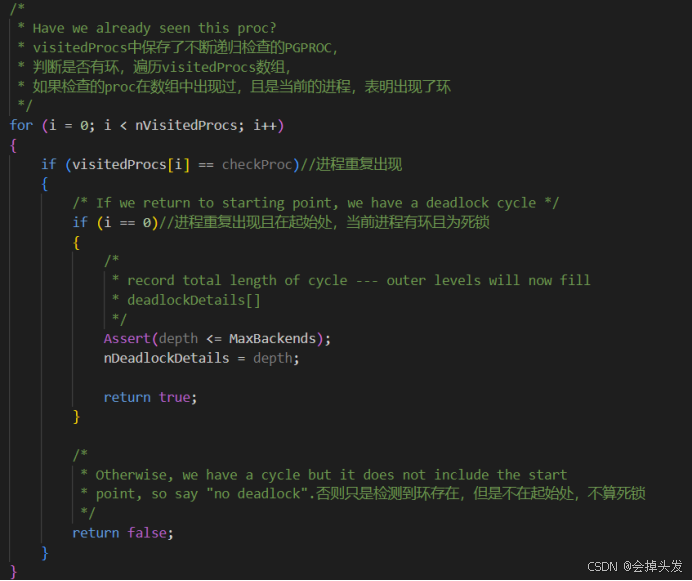
如果不存在環則將待檢測進程存入visitedProcs數組中。

如果要檢查的進程處于等待狀態,那么就遞歸檢測他的等待隊列。
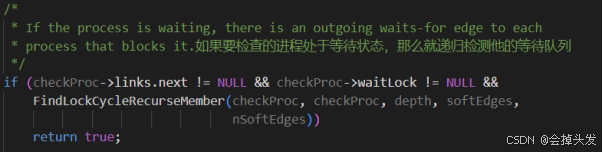
如果待測進程是鎖組中的一部分,遍歷鎖組的每個成員進程,檢查是否存在環。
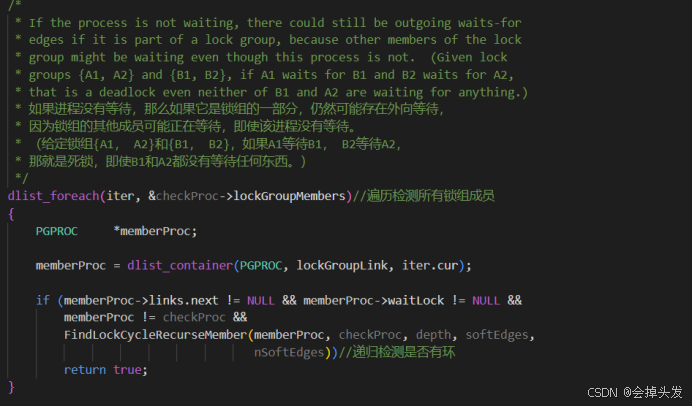
而在這里又提到了一個FindLockCycleRecurseMember函數,這個函數通過遞歸地檢查進程的鎖等待依賴關系來檢測死鎖循環。它區分了硬邊(直接阻塞關系)和軟邊(可調整的等待關系),并在檢測到死鎖時記錄相關信息。函數的設計確保了能夠準確地識別死鎖場景,并為可能的重排等待隊列提供支持,以嘗試解決死鎖問題。
參考連接或文獻
-
《PostgreSQL技術內幕 事務處理深度探索》,張樹杰
-
《PostgreSQL數據庫內核分析》,彭智勇
-
PostgreSQL · 內核特性 · 死鎖檢測與解決
-
PostgreSQL的全局死鎖檢測原理
-
11-pg內核之鎖管理器(六)死鎖檢測
-
PostgreSQL中的表鎖
-
PostgreSQL 并發控制 -- 鎖體系實現原理
-
[自學分享]Postgres數據庫鎖機制(部分)
-
37.1 經典知識庫:PostgreSQL中的鎖 - 張樹杰
-
postgresql源碼學習(九)—— 常規鎖②-強弱鎖與Fast Path
-
postgresql源碼學習(八)—— 常規鎖①-加鎖步驟與本地鎖表
-
Postgresql源碼(69)常規鎖細節分析
-
postgresql源碼學習(七)—— 自旋鎖與輕量鎖
)

)














)

)