概述
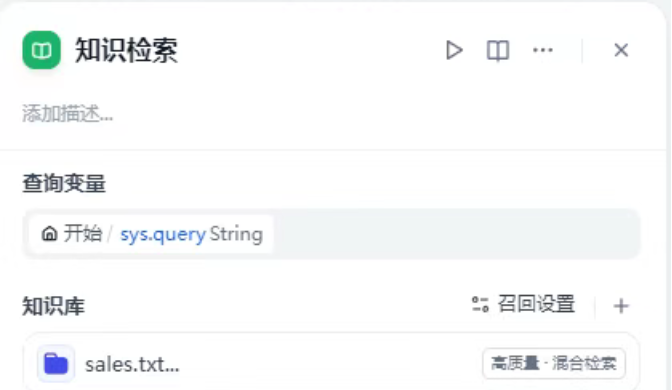
上一篇文章我們圍繞 Excel 文件展開數據可視化教學,逐步掌握了數據導入、圖表構建和 AI 智能分析。在實際業務環境中,很多數據并不是保存在表格中,而是存儲于數據庫系統中,尤其是最常見的 MySQL。本篇作為本系列的第五篇,將聚焦于如何在 Dify 中連接 MySQL 數據庫,動態獲取數據,并將其可視化展示。相比靜態的 Excel 文件,MySQL 的實時性和結構化特征將為可視化帶來更大價值。本篇將一步步帶你完成從數據庫接入到圖表生成,再到智能分析的完整流程。
構建工作流
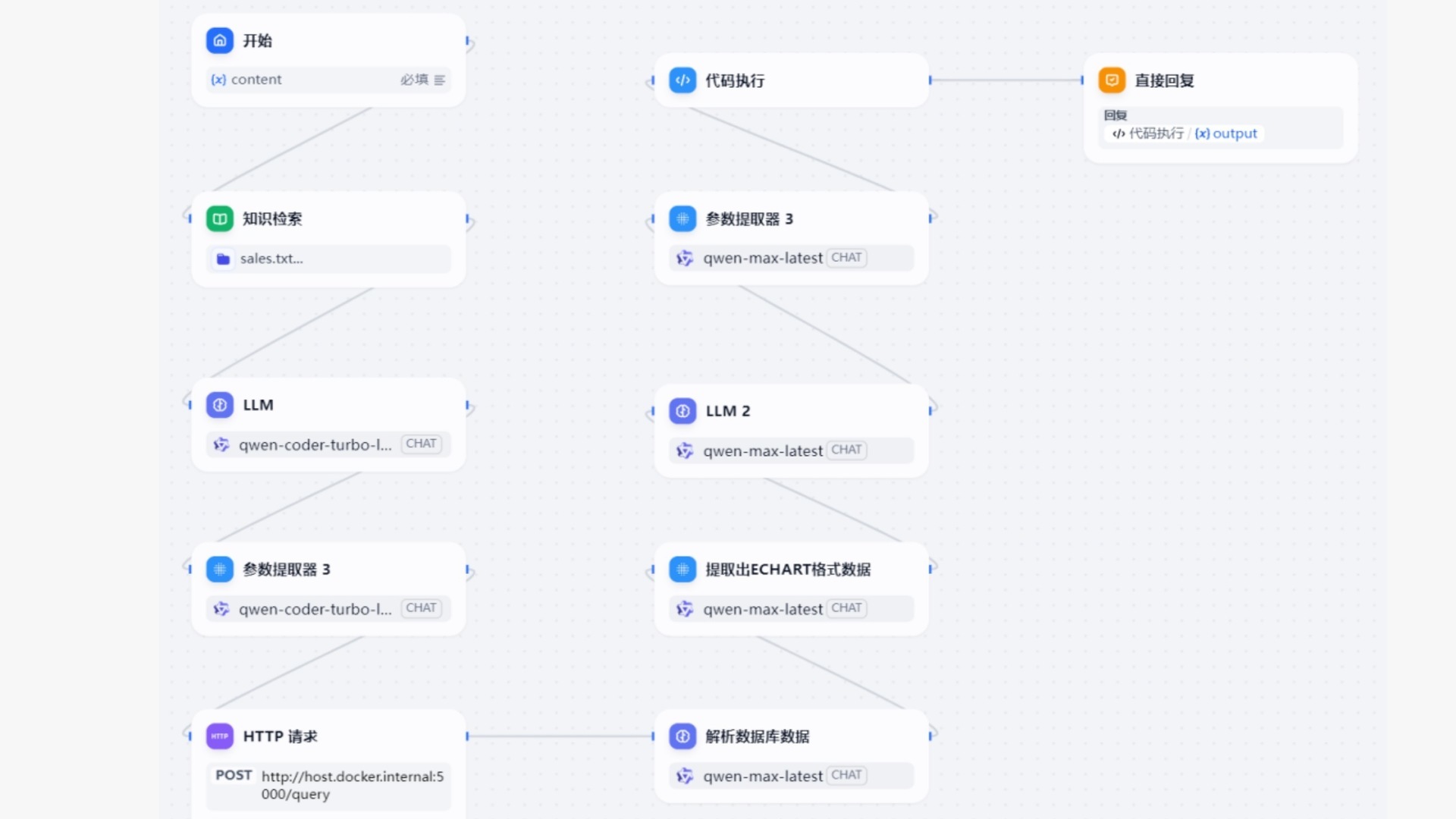
- 開始節點:就是一個輸入框,告訴AI我們要干什么,需求是什么。
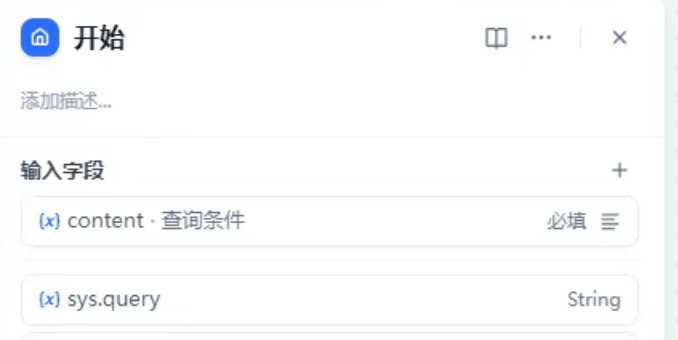
- 知識檢索:提供詳細的數據庫表的DDL,包含注釋等,這樣大模型才能正確理解我們的數據字段,才可以根據自然語言生成查詢數據的SQL,以便去數據庫查詢。
- LLM節點:這個節點負責把我們的自然語言轉換成SQL語句,可以選擇多家模型進行測試,看哪個效果好,我這里用的是qwen-coder-turbo-latest。
- promt如下:
你是一個數據分析師,擅長使用SQL查詢數據庫,根據用戶
數據庫的表結構 當 上下文 和用戶的查詢要求給出對應的
sq|語句。用戶的查間要求是:[變量]。
注意生成的SQL必須經過嚴格的校驗。你可以使用函數在用
戶輸入類似于”求和”或”總和”時,則在sq/語句中使用
SUM0。用戶輸入類似于”平均數”或”平均”時,在在sql語句
中使用AVG0。
要求
1.如果用戶輸入的內容無法生成為sq|語
句,請直接說“抱歉,該命令無法形成數據庫查詢操作”。
2.當可以生成sql語句時,請確保輸出的內容為完整正確的sql語句,除此以外不要輸出其他任何信息,不要注釋和說明,也不要格式化,不要用markdown格式來輸出,直接輸出純文本,也不要輸出 \n 這樣的回車換行符,確保你生成的sql
語句可以直接執行查詢操作。
3.對于字符串內容的查詢請使用LIKE操作而不是等于操作。
4.禁止中間過程輸出。- 參數提取器:節點的作用是從LLM節點的輸出里提取出合法SQL語句,上一個節點返回的數據可能會被包裝成md的格式,這里要根據實際的情況調整一下。上一個節點我使用qwen-coder-turbo-latest生成SQL的時候。
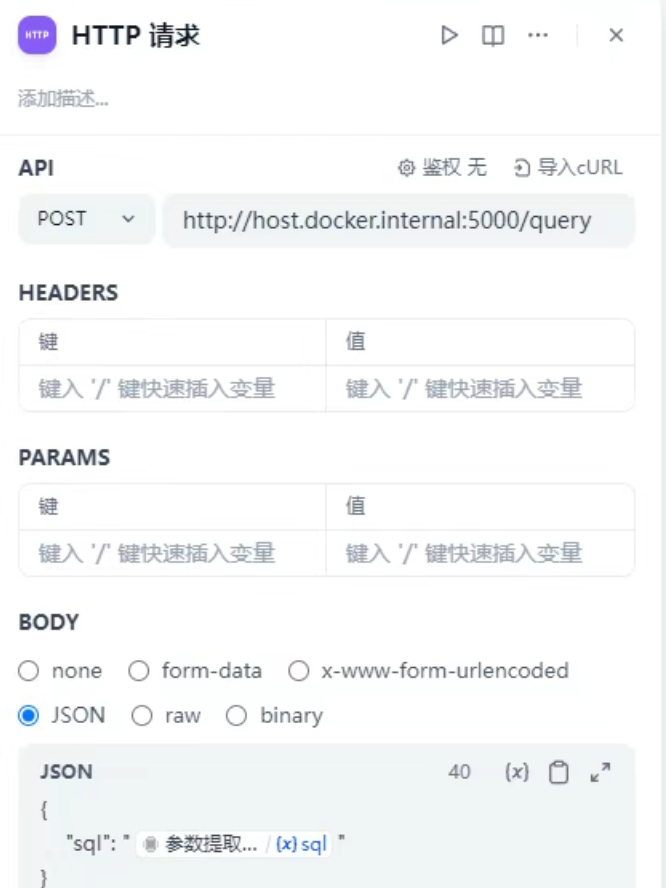
- HTTP請求節點:把上一個節點的SQL語句發給后臺,讓后臺執行這個SQL查詢數據庫,然后拿到數據。這里的參數要和后臺接口一致,包括接口url,方法,body的返回格式等。
- 解析數據庫數據:從上一個節點的輸出里解析出我們需要的,方便下一個節點處理的數據。
- Echarts 數據提取節點:該節點的作用是從前一個節點的輸出中提取出 Echarts 所需的數據,過濾掉無關內容,僅保留用于圖表渲染的核心信息。
- LLM 處理節點:此節點將上一步輸出的數據轉換為 Echarts 可識別的圖表數據結構。提示詞的設計可以參考上一期的內容。
- 參數提取器節點:負責從上一個節點的輸出中抓取 Echarts 執行所必需的參數,其他無關數據會被剔除。多個參數提取器節點的功能類似,都是從 Markdown 格式或其他結構化內容中提取出圖表渲染所需的關鍵數據。
- 代碼執行節點:在該節點中編寫代碼以接收前一節點的數據,并生成 Echarts 圖表的最終結構。
- 最終回復節點:將上一節點生成的 Echarts 圖表內容作為最終結果進行輸出和展示。
預覽結果
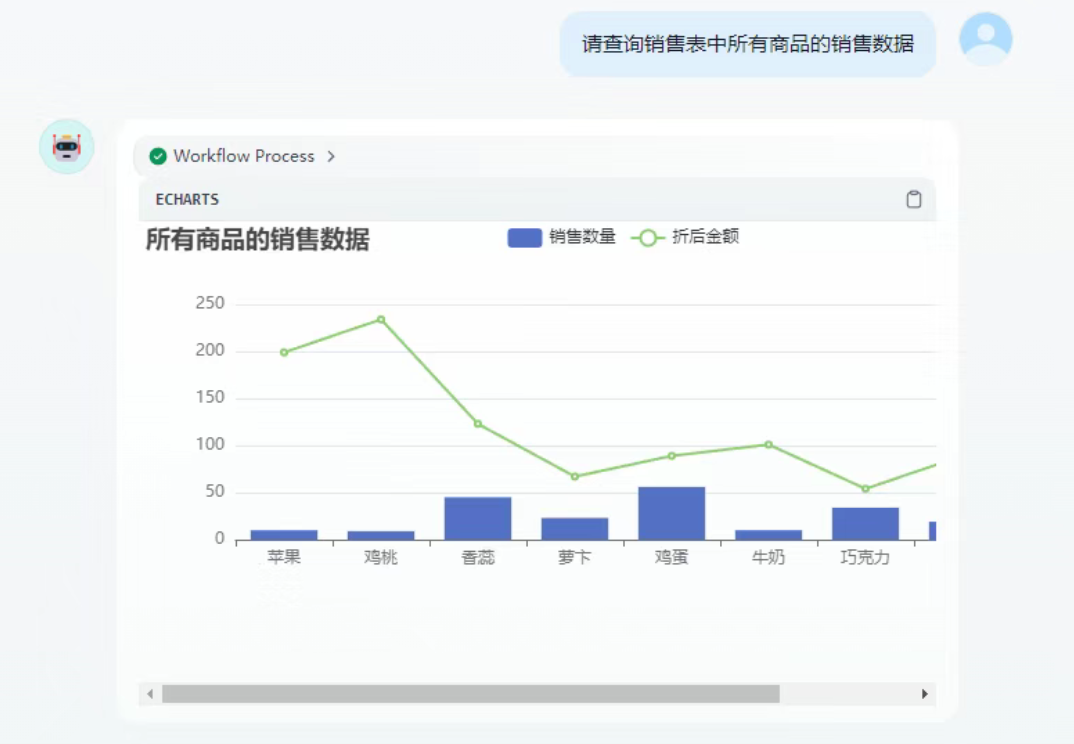
總結
通過本篇學習,我們掌握了如何將 MySQL 數據庫接入 Dify,實現實時圖表的構建與自動更新。相比 Excel 數據,MySQL 的動態性與結構化優勢讓數據可視化更具實用價值,特別適合銷售監控、訂單跟蹤、客戶分析等場景。Dify 強大的圖表引擎與 AI 問答系統,讓非技術人員也能輕松操作數據庫數據,快速洞察業務趨勢。下一篇我們將探索如何通過自動化工具(如 Webhook、API)讓 Dify 接收來自第三方系統的數據更新,進一步實現全流程自動化的數據分析體驗。


與沖突控制(Collision Control) 的機制說明)




)


——關于指針(逐漸清晰版))






教程)

)